阿尔法狗(AlphaGo)是谷歌旗下DeepMind开发的一个著名的增强学习算法,它在围棋领域取得了显著的成就。本文主要探讨其中两个重要的算法:增强学习算法和蒙特卡洛树搜索算法。
AlphaGo涉及的算法
AlphaGo是DeepMind团队开发的一个由多种算法和技术组合而成的系统,其包括以下主要组件和算法:
1. 深度神经网络
AlphaGo使用了深度神经网络来估计棋局的局势和价值,并进行策略推断。这些神经网络使用了卷积神经网络(Convolutional Neural Networks, CNN)和残差神经网络(Residual Neural Networks, ResNet)等先进结构,用于处理围棋棋盘上的状态和动作。
2. 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)
MCTS是一种搜索算法,用于在决策树中模拟大量的随机样本以评估每个动作的潜在价值。AlphaGo结合了MCTS和神经网络,利用神经网络指导搜索,并评估每个动作的概率和潜在价值,以决定最佳的下一步行动。
3. 强化学习算法
AlphaGo使用了强化学习来训练神经网络,优化策略,并提高系统在围棋中的表现。特别是,它使用了策略梯度(Policy Gradient)方法和价值迭代(Value Iteration)方法来更新和优化策略。
4. 人机协作训练
AlphaGo进行了大量的自我对弈和人机对弈,不断提升自身的水平。它通过与围棋职业选手对弈,学习并改进其策略。
5. 策略梯度方法(Policy Gradient)
AlphaGo中的神经网络也使用了策略梯度方法来进行优化,以改进在特定状态下采取动作的策略。
6. 预测和探索(Prediction and Exploration)
在训练过程中,AlphaGo使用策略网络的预测结果来引导MCTS的探索,并在搜索树的每一步中根据策略网络的输出进行动作选择。这样,它可以通过利用策略网络的先验知识来探索更加有希望的动作。
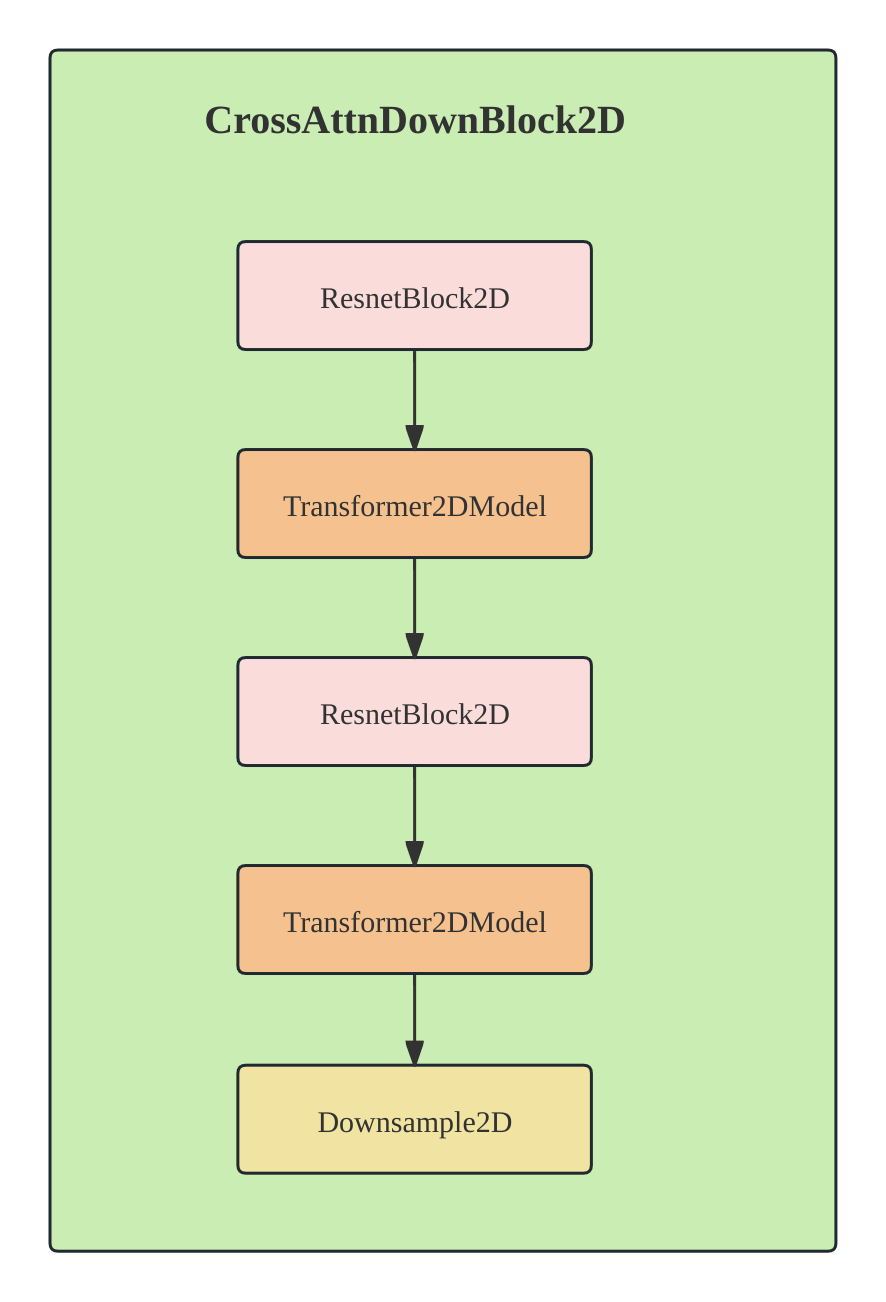
增强学习
增强学习是一种通过与环境交互来学习最优行为策略的机器学习方法。在增强学习中,智能体(agent)通过观察环境状态(state)、执行动作(action)并获得奖励(reward)来学习最佳策略,以使未来的累积奖励最大化。
1. 马尔可夫决策过程(Markov Decision Process, MDP)
马尔可夫性质(Markov Property)
马尔可夫决策过程基于马尔可夫性质,即当前状态的未来演变只与当前状态和当前所采取的动作有关,而与过去的状态序列无关。这个性质对于建模和求解MDP非常重要。
马尔可夫决策过程
马尔可夫决策过程(Markov Decision Process, MDP)是增强学习中的数学框架,用于建模这种交互过程。MDP用一组状态、一组动作、状态转移概率、奖励函数等元素来描述一个智能体在环境中的决策过程。MDP由五个主要要素组成:
- 状态空间(State Space)
状态空间表示所有可能的环境状态,智能体可以观察到的特定状态的集合。在每个时间步,智能体处于一个状态。 - 动作空间(Action Space)
动作空间表示智能体可以采取的所有可能动作的集合。在每个状态下,智能体可以执行的动作是有限的。 - 转移概率(Transition Probability)
转移概率描述了在某个状态下执行某个动作后转移到另一状态的概率。即在当前状态下采取某个动作后,智能体将以一定概率转移到下一个状态。 - 奖励函数(Reward Function)
奖励函数定义了智能体在某个状态下执行某个动作所获得的即时奖励。奖励可以是正值、负值或零,用于激励智能体朝着更优的策略前进。 - 折扣因子(Discount Factor)
折扣因子用于衡量未来奖励的重要性。它决定了智能体对未来奖励的重视程度。较高的折扣因子意味着更重视长期回报。
在MDP框架中,智能体根据当前状态和奖励,采取行动,并在下一个状态中获取新的奖励。通过这个过程,智能体尝试不同的策略,并通过学习来找到能够最大化长期奖励的最优策略。
MDP的数学表示
 基于这些要素,可以使用不同的增强学习算法来寻找最优策略,例如:
基于这些要素,可以使用不同的增强学习算法来寻找最优策略,例如:
- 值迭代(Value Iteration): 通过迭代更新状态的值函数来找到最优策略。
- 策略迭代(Policy Iteration): 通过迭代更新策略来找到最优策略。
- Q-Learning: 基于Q值函数来学习最优策略。
- 深度强化学习(Deep Reinforcement Learning): 使用神经网络来近似值函数或策略函数,以处理高维、复杂的状态空间和动作空间。
核心数学公式
 策略
策略
 这个方程表达了最优值函数在每个状态-动作对上的递归关系。根据最优值函数,可以得到最优策略。最优策略通常是在每个状态选择最大化值函数的动作。
这个方程表达了最优值函数在每个状态-动作对上的递归关系。根据最优值函数,可以得到最优策略。最优策略通常是在每个状态选择最大化值函数的动作。
2. Q-Learning
Q-Learning是一种基于价值迭代的增强学习算法,其核心思想是通过迭代更新Q值函数来优化策略。Q值函数(Q-function)用于估计在状态s下采取动作a的长期回报。
 策略选择
策略选择

Q-Learning 算法步骤:
- 初始化 Q 函数: 将 Q 函数初始化为一些初始值。
- 与环境交互: 智能体在环境中以某种策略进行动作选择,并观察环境的反馈(奖励和下一个状态)。
- 更新 Q 函数: 根据上述更新规则,利用新的奖励和状态更新 Q 函数。
- 重复步骤2和3: 智能体不断地与环境交互,更新 Q 函数,直到达到一定的停止条件(例如达到最大迭代次数、收敛等)。
Q-Learning的收敛性:
在满足一些条件的情况下,Q-Learning算法被证明会收敛到最优Q值函数。这些条件包括:状态和动作空间是有限的、每个状态-动作对被访问无限次数、学习率逐渐减小(例如满足 Robbins-Monro