C++和C语言函数之间最大的的不同是C++支持缺省参数,而C语言不支持,这里我使用的编译器为VS2022,创建项目时是依据文件后缀判断该文件为C文件还是C++。(编译环境VS2022)
文章目录
- 缺省参数
- 函数重载
- 引用
- 引用特性模拟
- 效率比较
- 引用和指针的不同
- 内联函数
缺省参数
C::
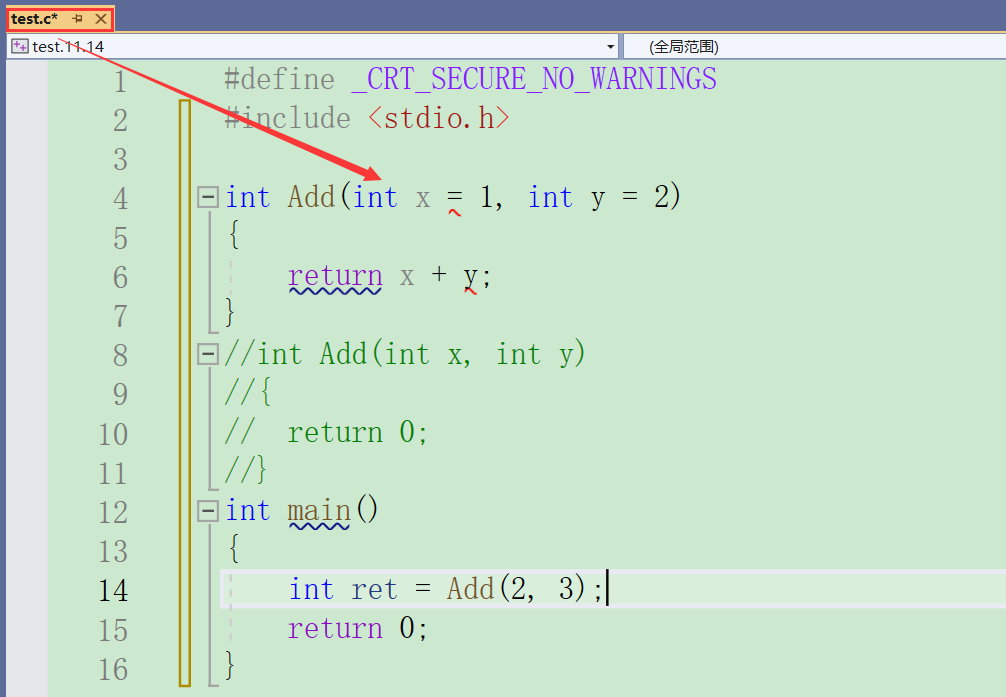
C++::

可以发现在C++文件下并没有报错,这里输出的结果是多少呢?
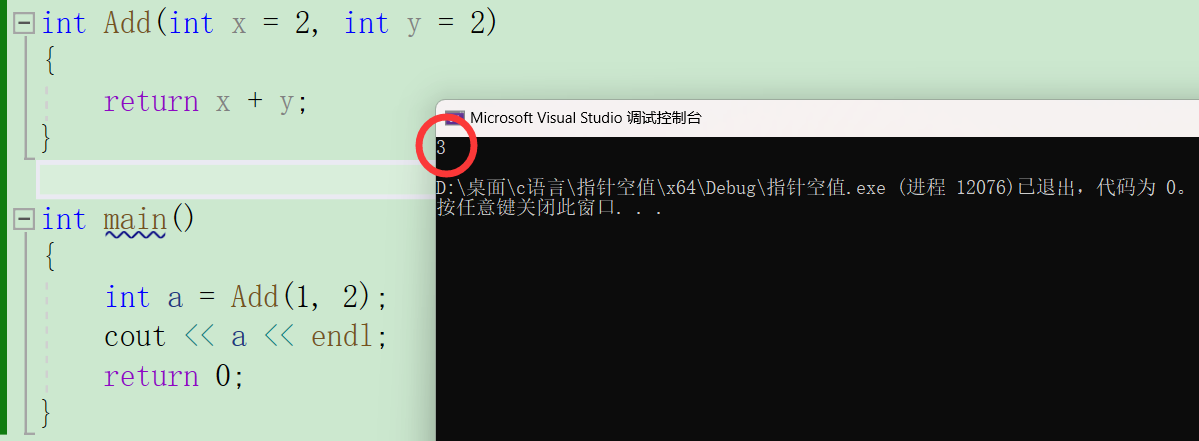
如果没有传入参数呢?
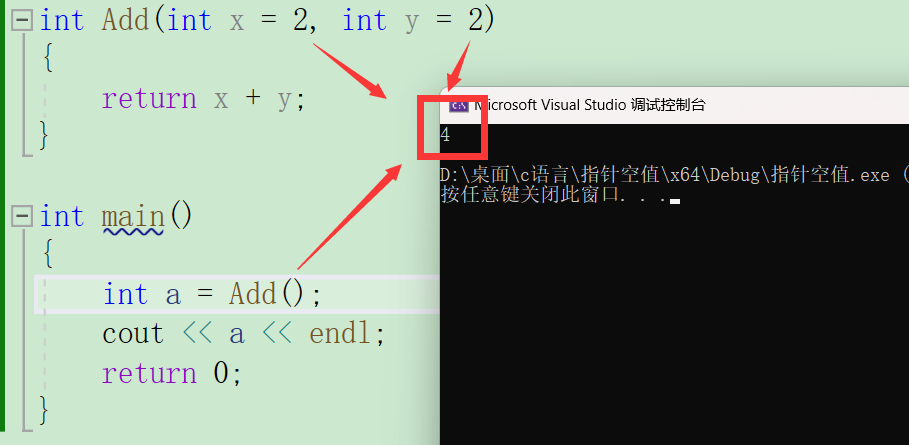
正式介绍一下
缺省参数:在声明或定义时为函数的参数设置一个缺省值,在调用该函数时,如果没有指定实参择采用该形参的缺省值,负责使用指定的实参。
缺省参数也有分类
- 全缺省参数
就像上边的一样,每个形参都有一个设置的缺省值。
void Perform(int x=1, double d=2.5, char c='d')
{
cout << x << endl;
cout << d << endl;
cout << c << endl;
}
- 半缺省参数
void Perform(int x, double d=2.5, char c='d')
{
cout << x << endl;
cout << d << endl;
cout << c << endl;
}
半缺省参数只能从右往左给,第一个可以不给,第一个第二个都可以不给,但是不能单独第二个不给,不然就会报错。
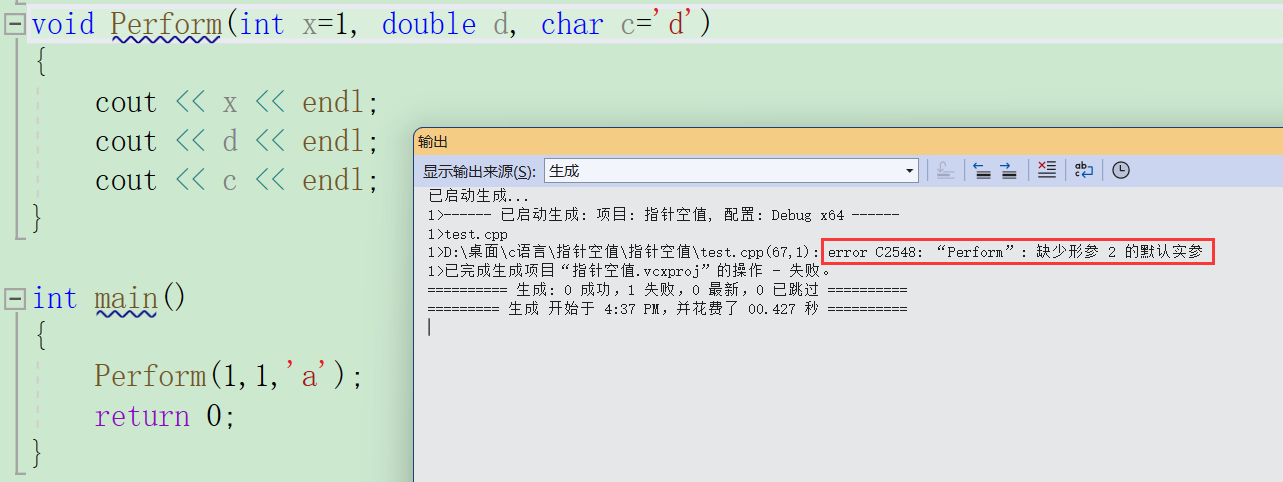
如果第一个第二个都不给就可以运行。
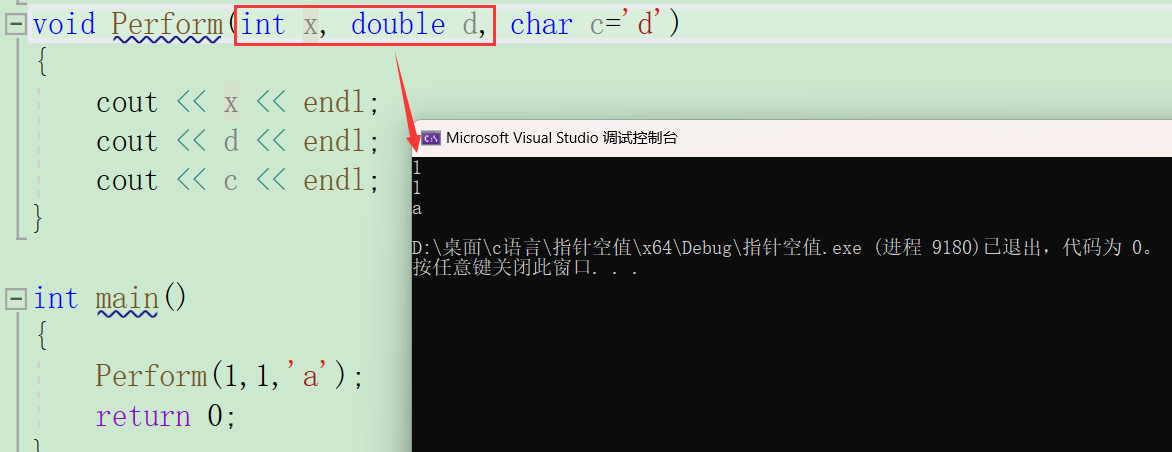
在设置缺省值时不可以声明和定义时一起给。

这里推荐在声明时给出缺省值,因为如果声明和定义都出现了缺省参数,有一些小马虎给定义和声明的缺省参数不一样,这时编译器就难过了,不知道到底该用哪个作为真实值,为了杜绝这个问题的发生,编译器就只允许在声明和定义时只有其中一个给缺省参数,至于为什么推荐在声明时定义,是为了更好地寻找并了解我们缺省参数的信息。
OK,成功引出了函数重载
函数重载
函数重载是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数或类型或类型顺序)不同,常常用来处理实现功能相同但数据类型不同的问题。
- 数据类型不同
int Add(int x, int y)
{
return x + y;
}
double Add(double x, double y)
{
return x + y;
}
- 个数不同
int Add(int x, int y)
{
return x + y;
}
int Add(int x)
{
cout << x << endl;
}
- 参数类型排序不同
double Add(double x, int y)
{
return x + y;
}
double Add(int x,double y)
{
return x + y;
}
一定要注意:
返回值不同不能作为重载条件!!!
引用
引用的概念:引用不是新定义一个变量,而是给已经存在的变量取一个别名,就类似于现实生活中给小明起外号叫鸡哥,鸡哥是他,小明也是他。编译器不会为引用变量开辟内存空间,他和他引用的变量占用同样的空间。
是不是刹那间觉得好生熟悉,其实引用就是替代某些情况下指针的作用,而且它的底层实现其实就是指针,同一个变量可以有多个指针,当然,同一个变量可以有很多引用。
引用格式:
类型& 引用变量名(对象名)=引用实体;
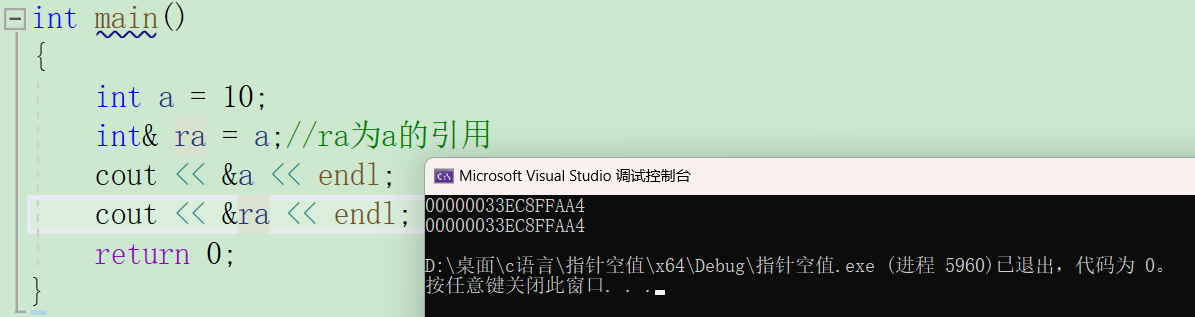
要注意:引用类型必须和引用实体的类型相同。
引用特性
- 使用引用定义时必须初始化。
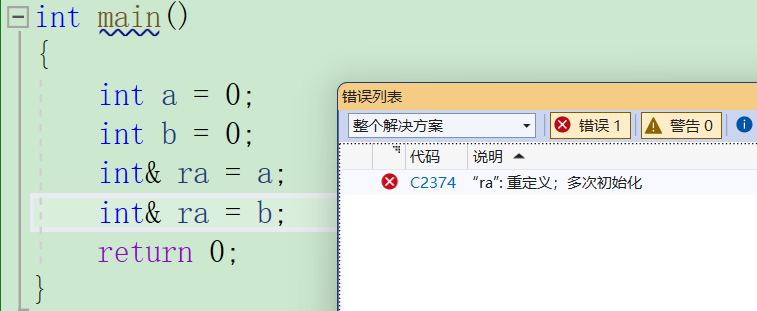
- 一个变量可以有多个引用。
- 引用一旦引用一个实体,就不能再引用其他实体,就像在班级里,一个boy的外号叫黑旋风,黑旋风这个外号就属于他了,如果还有人叫黑旋风,当你在班级里喊一声黑旋风,他们就不知道到底喊得那个黑旋风了。
但是一个小伙可以有多个引用,就比如小明,有了鸡哥的外号后,又被赋予坤坤的外号,那么坤坤是他,鸡哥也是他,所以一个变量可以有多个引用,每个引用其实还是他自己。
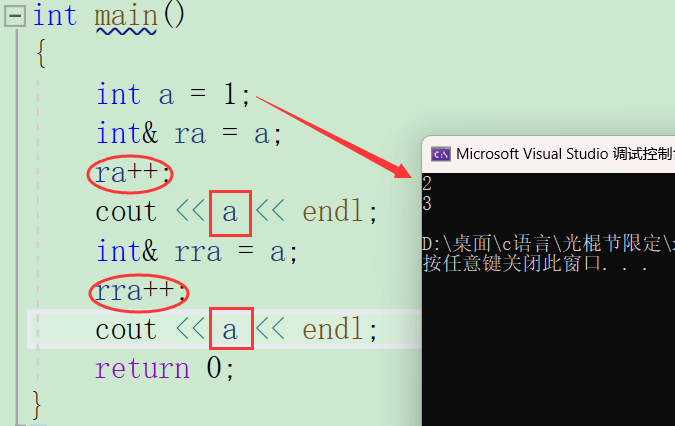
这里还有一点要注意
引用的类型要和变量的类型一致,如果变量是常性的,那么引用就也要用const修饰。

因为const修饰a之后,a变量不可以被修改,此时引用变量不加const的话,局可以通过引用修改a的值,这不就矛盾了。所以在引用常变量时,也要用const修饰。
如果变量a没有用const修饰,引用用const修饰,这样是可以的,一句话来讲就是不可以扩大权限,但可以缩小权限。
引用特性模拟
相信大家都知道,函数传参并不是真的把变量传过去,而是生成相应的形参,然而形参改变不影响实参,在C语言时,我们利用指针传参,将数据的地址传过去,从而改变实参,现在,有了引用,就可以不必这么麻烦了。
我们直接引用接收,此时形参就是实参的引用,引用改变就会改变实参。
举一个最直观的例子。
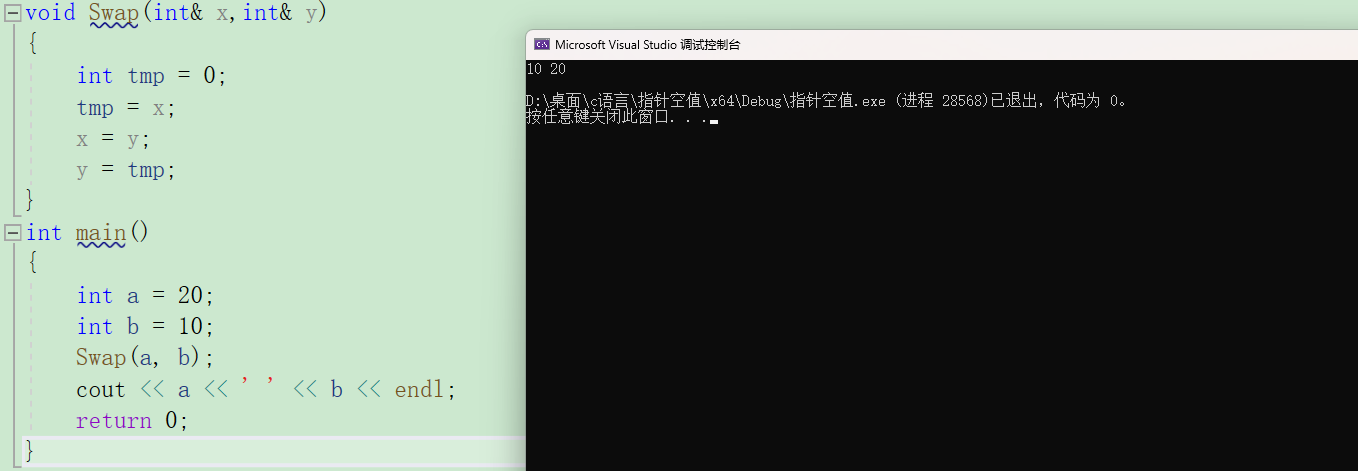
是不是十分方便。
引用还可以用作返回值。
例如
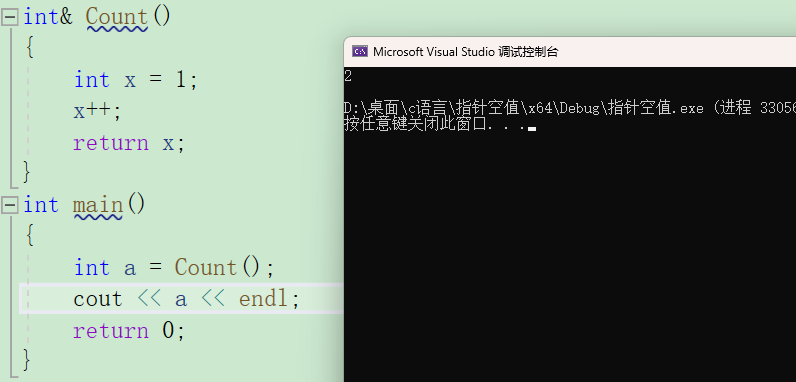
是不是觉得有点不对,我们传回来的值是一个临时变量,所以需要传回来的值用static修饰,延长其作用周期。防止退栈后这块内存还给操作系统从而得到的数为随机数值。
效率比较
传值传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身传过去,而是生成一份实参或返回值的一份临时的拷贝,用这个临时拷贝的值作为参数或者返回值,这样效率是十分低下的,尤其是当参数或者返回值很大时,创建临时变量也会花费不少的时间,效率就会更加低下。
验证:
#include <time.h>
#include <iostream>
using namespace std;
struct A
{
int a[100000];
};
void TestFunc1(A a){}
void TestFunc2(A& a){}
void Test()
{
A a;
size_t begin1 = clock();
for (size_t i = 0; i < 100000; i++)
{
TestFunc1(a);
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < 100000; i++)
{
TestFunc2(a);
}
size_t end2 = clock();
cout << "(A):" << end1 - begin1 << endl;
cout << "(A&):" << end2 - begin2 << endl;
}
int main()
{
Test();
return 0;
}
clock会捕获当前程序运行的时间(单位为毫秒),创建了一个结构体,内部有一个大小为1000000的数组,传参时,若要创建出相应的形参,就要花费更多的时间,而引用作为参数,传过去的就是实参的引用,就略去了相应的形参的建造过程。
运行后效果如图
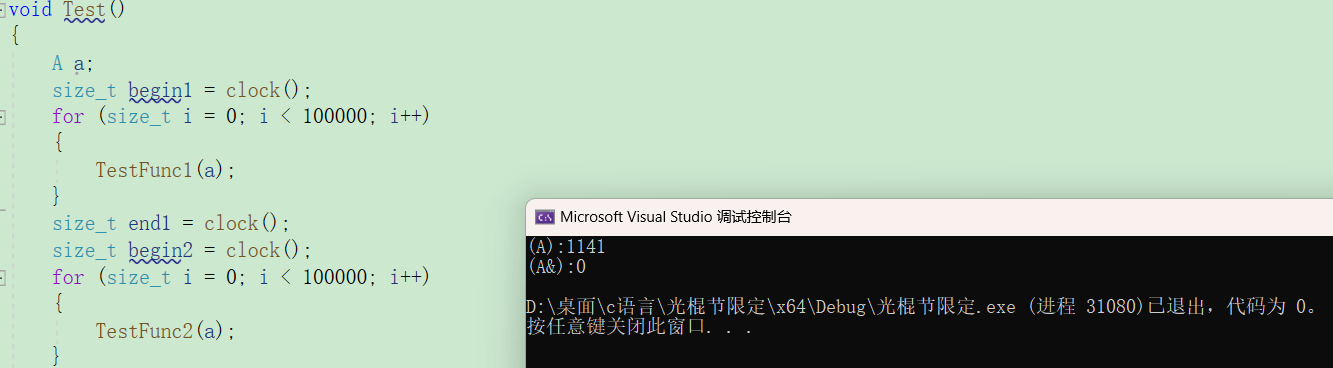
上边是作为参数,如果作为返回值呢?
using namespace std;
struct A
{
int a[10000];
};
A a;//设置为全局变量
A TestFunc1() { return a; }
A& TestFunc2() { return a; }
void Test()
{
size_t begin1 = clock();
for (size_t i = 0; i < 100000; i++)
{
TestFunc1();
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < 100000; i++)
{
TestFunc2();
}
size_t end2 = clock();
cout << "(A):" << end1 - begin1 << endl;
cout << "(A&):" << end2 - begin2 << endl;
}
int main()
{
Test();
return 0;
}
运行结果如图
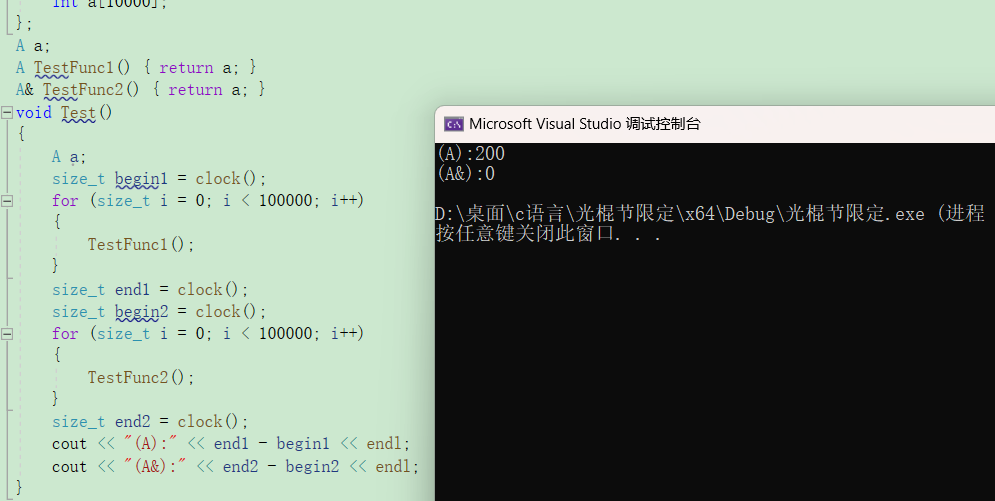
这里结构体中数组不要太大,形参太大有可能会爆栈,就会执行错误,所以这里将循环次数增使效果更加明显。
引用和指针的区别
引用在语法概念上就是一个别名,没有独立的空间,和其引用实体共用一块区域。
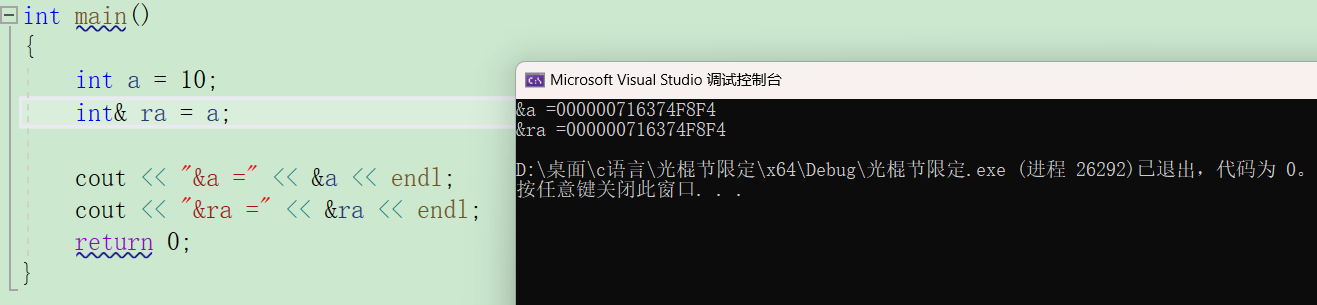
然而,在底层实现上引用其实是按照指针的方式来实现的。

汇编代码对比实现方式和指针一模一样,所以可以说C++引用就是按照指针方式实现的。
引用和指针的不同
- 引用概念上给变量定义一个别名,指针存储一个变量的地址。
- 引用在定义时必须初始化,指针没有要求。
- 引用在初始化时引用一个实体后,就不能在引用其他实体,指针不同,指针只要不加const限定指针变量,就可以在任何时候指向任何实体。
- 没有NULL引用,但有空(NULL)指针。
- 在sizeof中含义不同,引用的结果为引用类型的大小,如果引用的变量是char类型,那结果就为1,但是指针变量始终都是4/8个字节。
- 引用自加就是引用实体+1,指针自加,就是向后偏移一个类型的大小。
- 有多级指针,但没有多级引用。
- 访问实体方式不同,指针需要解引用,引用的话编译器自己会处理,可以直接使用。
- 引用使用起来比指针相对安全。
内联函数
概念
以inline修饰的函数叫做内联函数,编译时编译器会在调用该函数的地方将该函数展开,没有函数调用时建立栈帧的开销,提升程序的运行效率。
举一个Add的例子,在不展开的情况下,主函数通过调用该函数从而达到效果
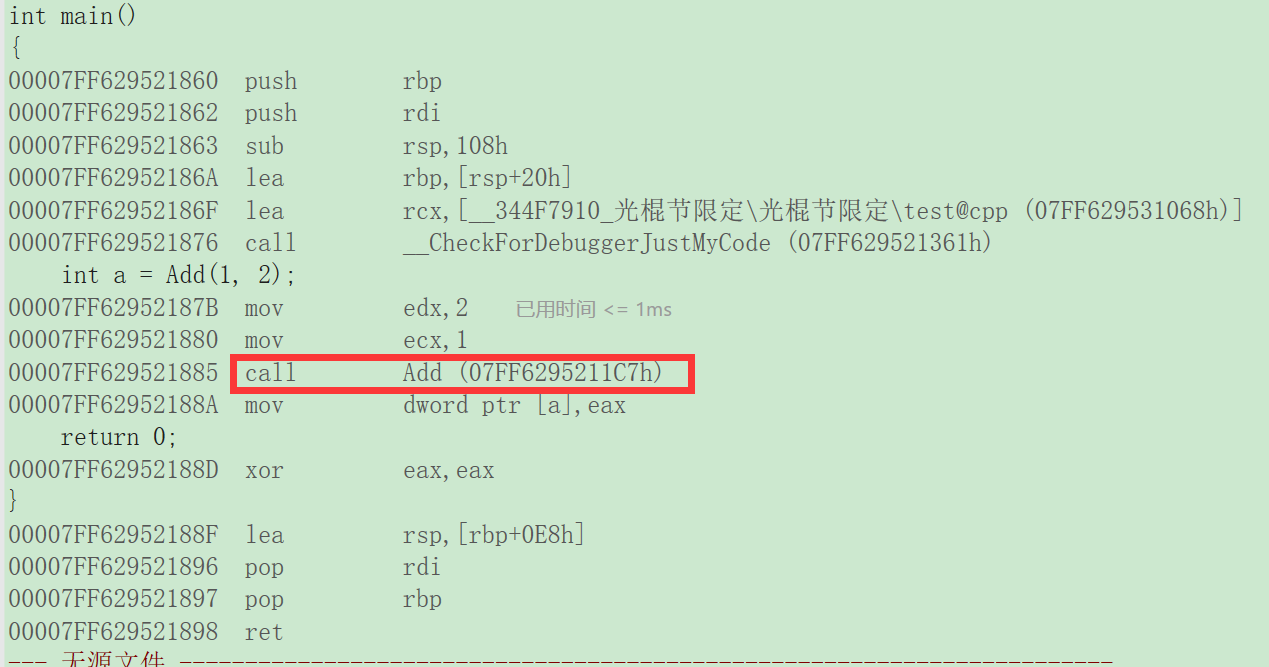
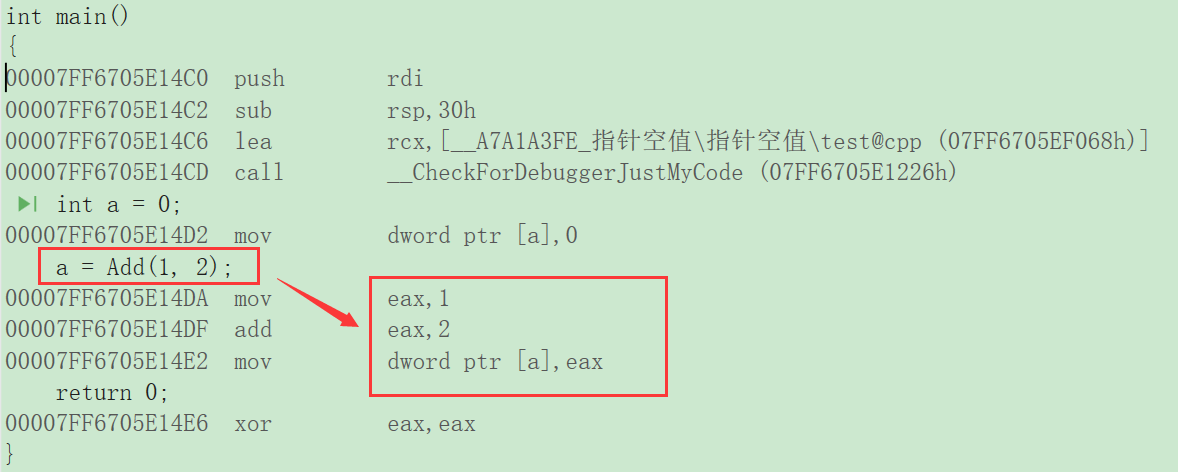
在Add函数前加上inline关键字将其修改成内联函数,在编译期间编译器会将函数体替换为函数的展开。
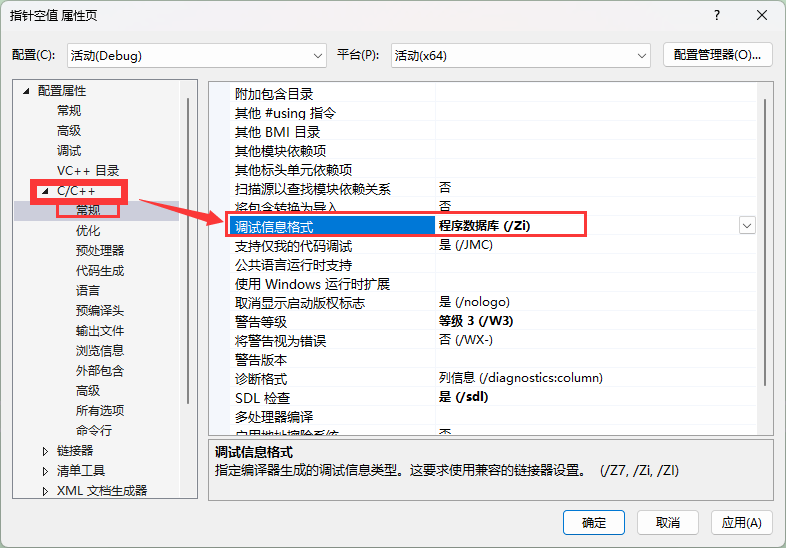
演示之前要更改一下编译器的默认设置,否则还是不会展开(dubug模式下,编译器默认不会对代码进行优化)下边是设置方式
打开属性后
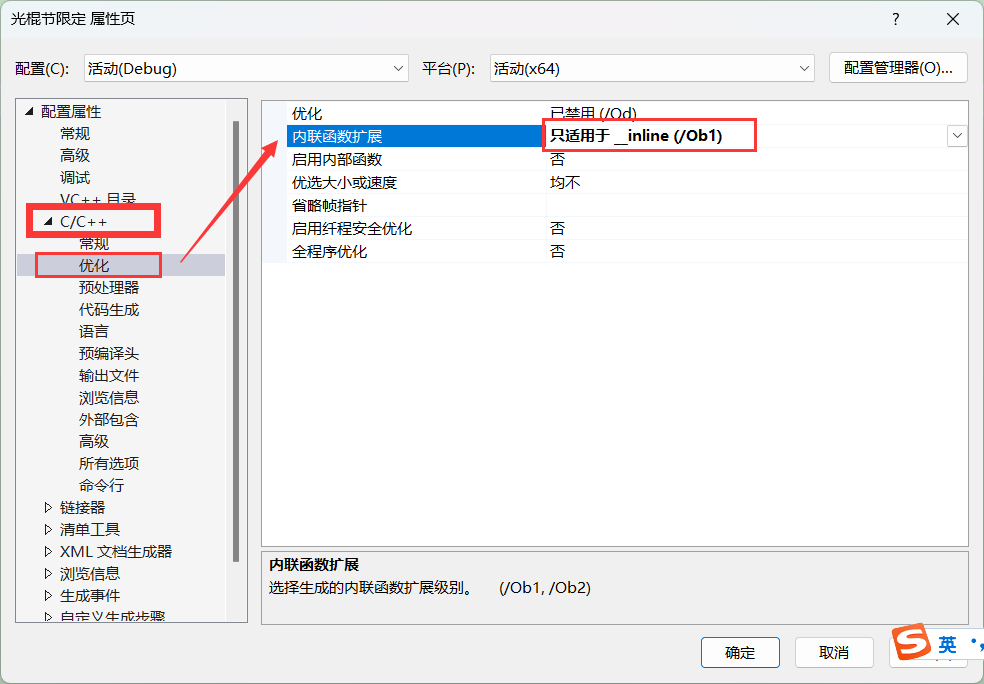
加上inline再次转到反汇编进行查看,确实已经展开了。
特性
- inline是一种以空间换时间的做法,如果编译器将函数作为内联函数处理,在编译期间就会用函数体替换函数调用。
- 缺陷:会使目标文件变大,如果用很多内联函数,相当于程序要进行的步骤变多,本来的call变为函数体内部步骤。
- 优势:少了函数栈帧调用开销,提高程序的运行效率。
inline对于编译器而言只是一个建议,不同编译器对inline的态度不同,一般建议当函数体很小时,并且不是递归且频繁调用的函数采用inline修饰,否则编译器会直接无视。
注意:
inline不建议声明定义分离,因为inline被展开后,就没有函数地址可言了,链接就会找不到。
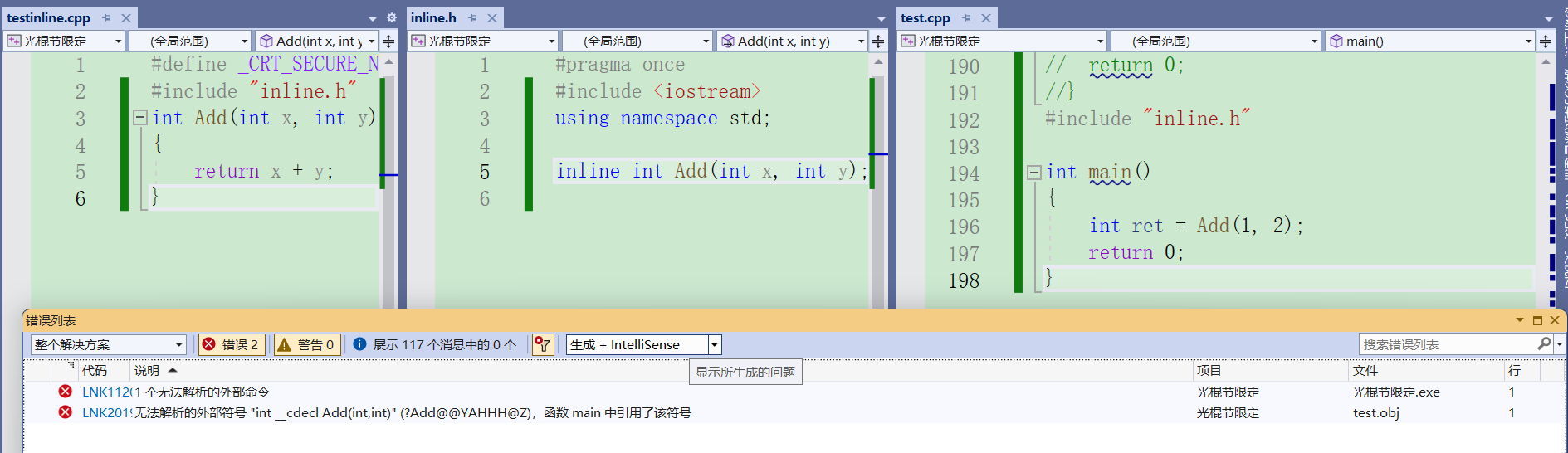
内联函数优点有很多,相比宏可以进行调试代码可读性好,可维护形也更强。
今天的内容到此结束,欢迎大家指导。