一、说明
在项目中使用Elasticsearch的聚合与分组查询后,对于返回结果一脸懵逼,查阅各资料后,自己总结了一下参数取值的含义,不一定全面,只含常见参数
二、分组查询
2.1 参数解释
SearchResponse<Map> searchResponse = null;
try {
searchResponse = client.search(s -> s.index("tbanalyzelist").query(
q -> q.bool(
t -> {
t.must(m -> m.match(b -> b.field("machineType.keyword").query(FieldValue.of(machineType))));
if (ToolUtil.isNotEmpty(bizCodes))
t.must(m -> m.terms(b -> b.field("bizCode.keyword").terms(f -> f.value(values))));
t.must(a -> a.range(r -> r.field("duration").gt(JsonData.of(0))));
t.must(a -> a.range(r -> r.field("open_time").gt(JsonData.of(startTime)).lte(JsonData.of(endTime1))));
return t;
}
)
)
//.size(2000000) 数据太多暂且注释
.from(1) //分页查询 起始位置
.size(2) // 每页两条数据
.aggregations("byOpenTime", aggregationBuilder ->
aggregationBuilder.terms(termsAggregationBuilder ->
termsAggregationBuilder.field("openTime")
)),
Map.class);
} catch (IOException e) {
e.printStackTrace();
}
//查询结果
System.out.println(searchResponse);
System.out.println("耗时:" + searchResponse.took());
HitsMetadata<Map> hits = searchResponse.hits();
System.out.println(hits.total());
System.out.println("符合条件的总文档数量:" + hits.total().value());
//注意:第一个hits() 与 第二个hits()含义不一样
List<Hit<Map>> hitList = searchResponse.hits().hits();
//获取分组结果
Map<String, Aggregate> aggregations = searchResponse.aggregations();
System.out.println("aggregations:" + aggregations);
Aggregate aggregate = aggregations.get("byOpenTime");
System.out.println("byOpenTime分组结果 = " + aggregate);
LongTermsAggregate lterms = aggregate.lterms();
Buckets<LongTermsBucket> buckets = lterms.buckets();
for (LongTermsBucket b : buckets.array()) {
System.out.println(b.key() + " : " + b.docCount());
}- searchResponse输出结果转JSON
{
"took":190, //执行整个搜索请求耗费了多少毫秒
"timed_out":false,//查询是否超时。默认情况下,搜索请求不会超时。
"_shards":{ // 在查询中参与分片情况
"failed":0, //失败分片数量
"successful":1,//成功
"total":1,//总计
"skipped":0//跳过
},
"hits":{ //结果命中数据
"total":{ //匹配到的文档总数
"relation":"gte",//是否是我们的实际的满足条件的所有文档数
"value":10000 //文档总数
},
"hits":[//每一个命中数据
{
"_index":"tbanalyzelist", //索引名相当于数据库的表名
"_id":"QF2THIQBzxpesqmRtMpw",
"_score":3.0470734,//分数
"_type":"_doc",//类型
//资源,这里才是存储的我们想要的数据
"_source":"{
duration=317.0, //每个字段的值相当于mysql中的字段
machineId=ZFB007422,
bizName=wangyf,
bizCode=221026172721ZBTQ,
open_time=1664296386000,
openTime=2022-09-27,
machineType=DEV-HL
}"
},
{
"_index":"tbanalyzelist",
"_id":"QV2THIQBzxpesqmRtMpw",
"_score":3.0470734,
"_type":"_doc",
"_source":"{
duration=313.0,
machineId=ZFB007422,
bizName=wangyf,
bizCode=221026172721ZBTQ,
open_time=1664383009000,
openTime=2022-09-28,
machineType=DEV-HL
}"
}
],
"max_score":3.0470734 //查询所匹配文档的 _score 的最大值
},
"aggregations":{//聚合结果
"lterms#byOpenTime":{//分组的桶名称
"buckets":[ //分组桶结果
{
"doc_count":20144,//
"key":"1664150400000",
"key_as_string":"2022-09-26T00:00:00.000Z"
},
{
"doc_count":19724,
"key":"1664409600000",
"key_as_string":"2022-09-29T00:00:00.000Z"
},
{
"doc_count":19715,
"key":"1664236800000",
"key_as_string":"2022-09-27T00:00:00.000Z"
},
{
"doc_count":19653,
"key":"1664323200000",
"key_as_string":"2022-09-28T00:00:00.000Z"
},
{
"doc_count":19376,
"key":"1664496000000",
"key_as_string":"2022-09-30T00:00:00.000Z"
},
{
"doc_count":331,
"key":"1664064000000",
"key_as_string":"2022-09-25T00:00:00.000Z"
}
],
"doc_count_error_upper_bound":0,
"sum_other_doc_count":0
}
}
}
- doc_count_error_upper_bound:表示没有在这次聚合中返回、但是可能存在的潜在聚合结果,
- sum_other_doc_count:表示这次聚合中没有统计到的文档数。因为ES为分布式部署,不同文档分散于多个分片,这样当聚合时,会在每个分片上分别聚合,然后由协调节点汇总结果后返回。
- doc_count:每个桶的文档数量。
- key: 分组后的key值
2.2 获取桶数据方式
Buckets<LongTermsBucket> longBuckets = aggregate.lterms().buckets();
Buckets<StringTermsBucket> stringBuckets = aggregate.sterms().buckets();
Buckets<DoubleTermsBucket> doubleBuckets = aggregate.dterms().buckets();三、聚合查询
查询条件先忽略,这里聚合后的条件可以直接取到max,count,min,avg,sum等值
String cinemaId = "15989";
SearchResponse<Map> searchResponse = null;
try {
searchResponse = client.search(
s -> s.index("tbmaoyan")
.query(q -> q.bool(t -> {
t.must(m -> m.match(f -> f.field("cinemaId.keyword").query(FieldValue.of(cinemaId))));
//t.must(m -> m.term(f -> f.field("cinemaId.keyword").value(cinemaId)));
//t.must(m -> m.match(f -> f.field("cinemaId").query("36924")));
// t.must(m -> m.match(f -> f.field("bizCode").query(FieldValue.of("220104182434IIZF"))));//220104182434IIZF 220120143442CB4C
return t;
}
)
)
// .sort(o -> o.field(f -> f.field("openTime").order(SortOrder.Asc)))
//对viewInfo进行统计
.aggregations("sumViewInfo", aggregationBuilder -> aggregationBuilder
.stats(statsAggregationBuilder -> statsAggregationBuilder
.field("viewInfo")))
//对showInfo进行统计
.aggregations("aggregateShowInfo", aggregationBuilder -> aggregationBuilder
.stats(statsAggregationBuilder -> statsAggregationBuilder
.field("showInfo")))
.from(0)
.size(10000)
, Map.class
);
} catch (IOException e) {
e.printStackTrace();
}
//查询结果
System.out.println(searchResponse);
System.out.println("耗时:" + searchResponse.took());
HitsMetadata<Map> hits = searchResponse.hits();
System.out.println(hits.total());
System.out.println("符合条件的总文档数量:" + hits.total().value());
//注意:第一个hits() 与 第二个hits()的区别
List<Hit<Map>> hitList = searchResponse.hits().hits();
List<Map> hitListCopy = new ArrayList<>();
for (Hit<Map> mapHit : hitList) {
String source = mapHit.source().toString();
System.out.println("文档原生信息:" + source);
Map map = mapHit.source();
hitListCopy.add(map);
}
//获取聚合结果
Map<String, Aggregate> aggregations = searchResponse.aggregations();
System.out.println("aggregations:" + aggregations);
Aggregate aggregateViewInfo = aggregations.get("sumViewInfo");
Aggregate aggregateShowInfo = aggregations.get("aggregateShowInfo");
System.out.println("viewInfo:" + aggregateViewInfo);
System.out.println("showInfo:" + aggregateShowInfo);
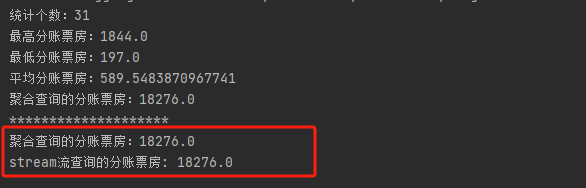
System.out.println("统计个数:" + aggregateViewInfo.stats().count());
System.out.println("最高分账票房:" + aggregateViewInfo.stats().max());
System.out.println("最低分账票房:" + aggregateViewInfo.stats().min());
System.out.println("平均分账票房:" + aggregateViewInfo.stats().avg());
System.out.println("聚合查询的分账票房:" + aggregateViewInfo.stats().sum());
Double sumViewInfoCopy = hitListCopy.stream().mapToDouble(h -> Double.parseDouble(h.get("viewInfo").toString())).sum();
System.out.println("********************");
System.out.println("聚合查询的分账票房:" + aggregateViewInfo.stats().sum());
System.out.println("stream流查询的分账票房: " + sumViewInfoCopy);- searchResponse.aggregations()的结果跟上面分组查询类似,不过赘述了
- aggregations.get("sumViewInfo")的取值
![]()
- aggregations.get("aggregateShowInfo")的取值
![]()
- 比对一下聚合查询跟我们自己算的数据是否一致