文章目录
- 1. 写在前面
- 2. 参数分析
- 2.1. x-s、x-t、x-s-common
1. 写在前面
最近花时间分析了一下xhs,研究的不深,也参考了网上许多开源出来的案例。简单记录一下,感兴趣的将就看一下吧!
之前也研究过一段时间的某音,下面接口aweme相关的都能够拿到,过一下防抓包,这个的话很多大佬有成熟的方案,lsp跟xp的模块
xhs的话Web还是相对比较简单的!一样sns相关的接口基本都能拿到,那几个x系列加密参数解决了,就容易了
真正的难点就是风控,各种限制的话确实很容易搞人心态的
2. 参数分析
2.1. x-s、x-t、x-s-common

先全局搜索,上面的x-s、x-t,然后断点断住以后就可以开始分析调试了,上面的三个参数在应对后续的请求缺一不可!a1是cookies里面的,它将参与x-s-common签名
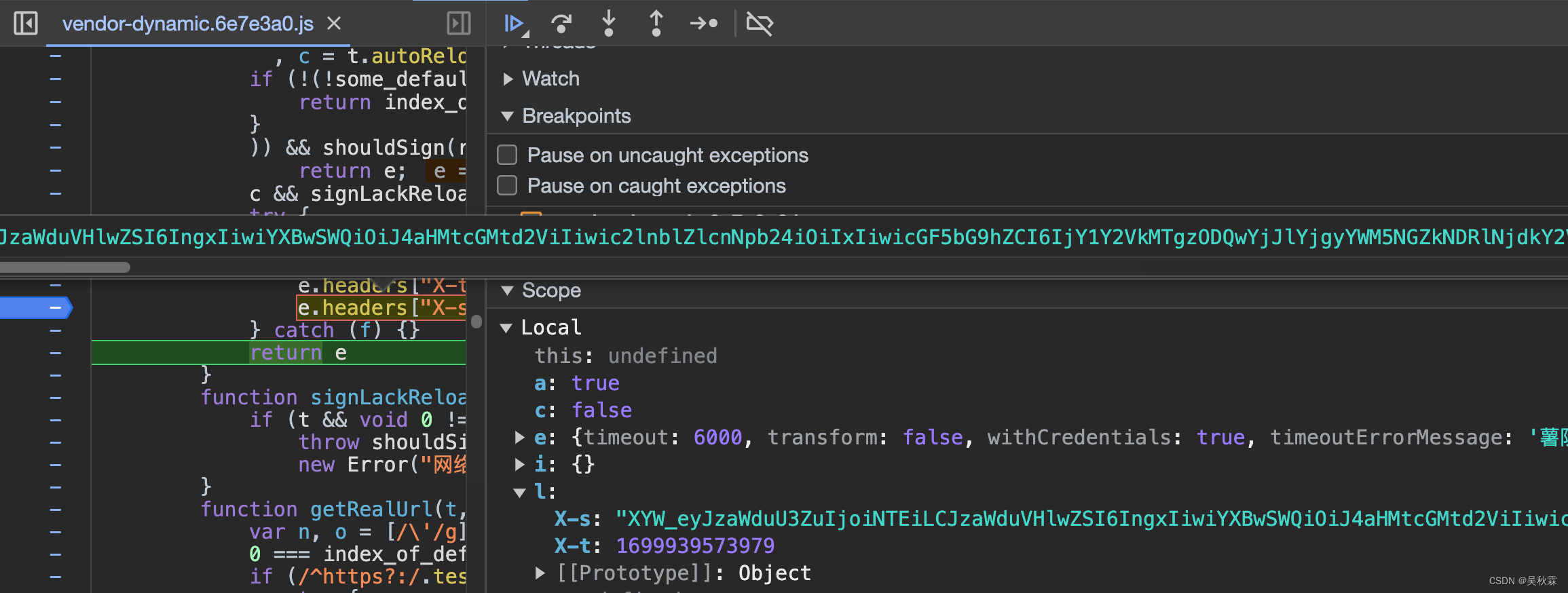
x-s-common必须带,之前网上一些公开的资源,都是没带的!不带的话接口请求能够成功,但是没有数据!继续断点分析可以看到x-s-common签名的生成,如下所示:
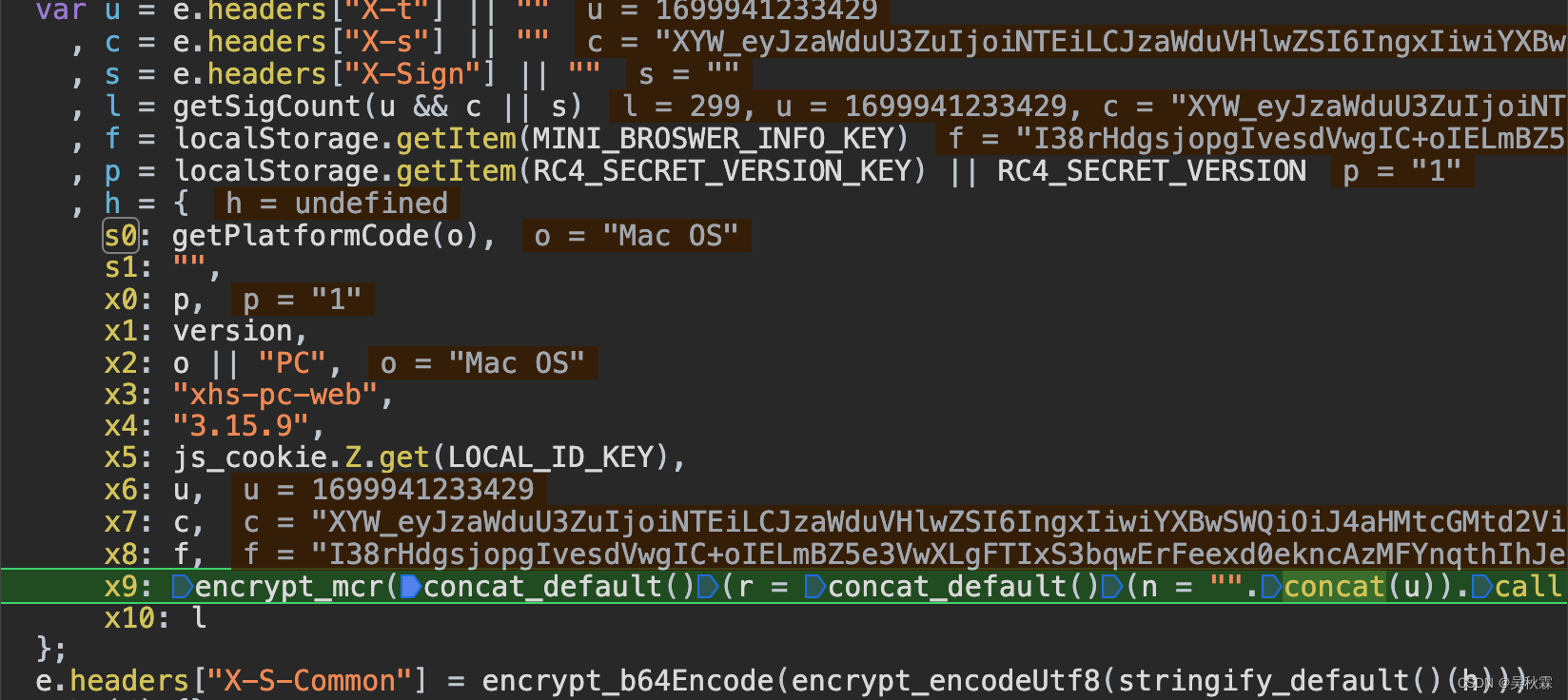
上面x-s-common参数可以根据断点,分析出传的值,分析如下:
common = {
"s0": 5, # 固定值
"s1": "", # 固定值
"x0": "1", # 固定值
"x1": '', # 版本
"x2": "Windows", # 固定值
"x3": "xhs-pc-web", # 固定值
"x4": "3.15.9", # 固定值
"x5": a1, # cookies里面的a1,用来做校验的
"x6": x_t,
"x7": x_s,
"x8": b1, # window.localStorage(客户端浏览器信息标识)
"x9": mrc(x_t + x_s + b1), #x6,x7,x8签名产生
"x10": 1,
}
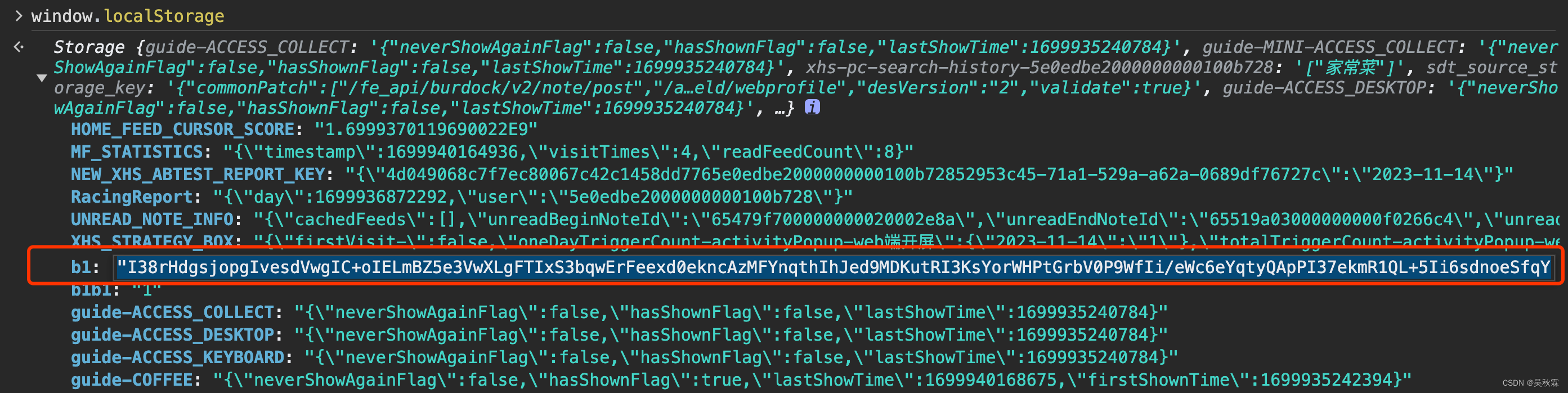
x8参数b1值获取示例:
另外就是签名参数不对,算法没到位的话,接口基本请求都是无效的
{'code': -1, 'success': False}
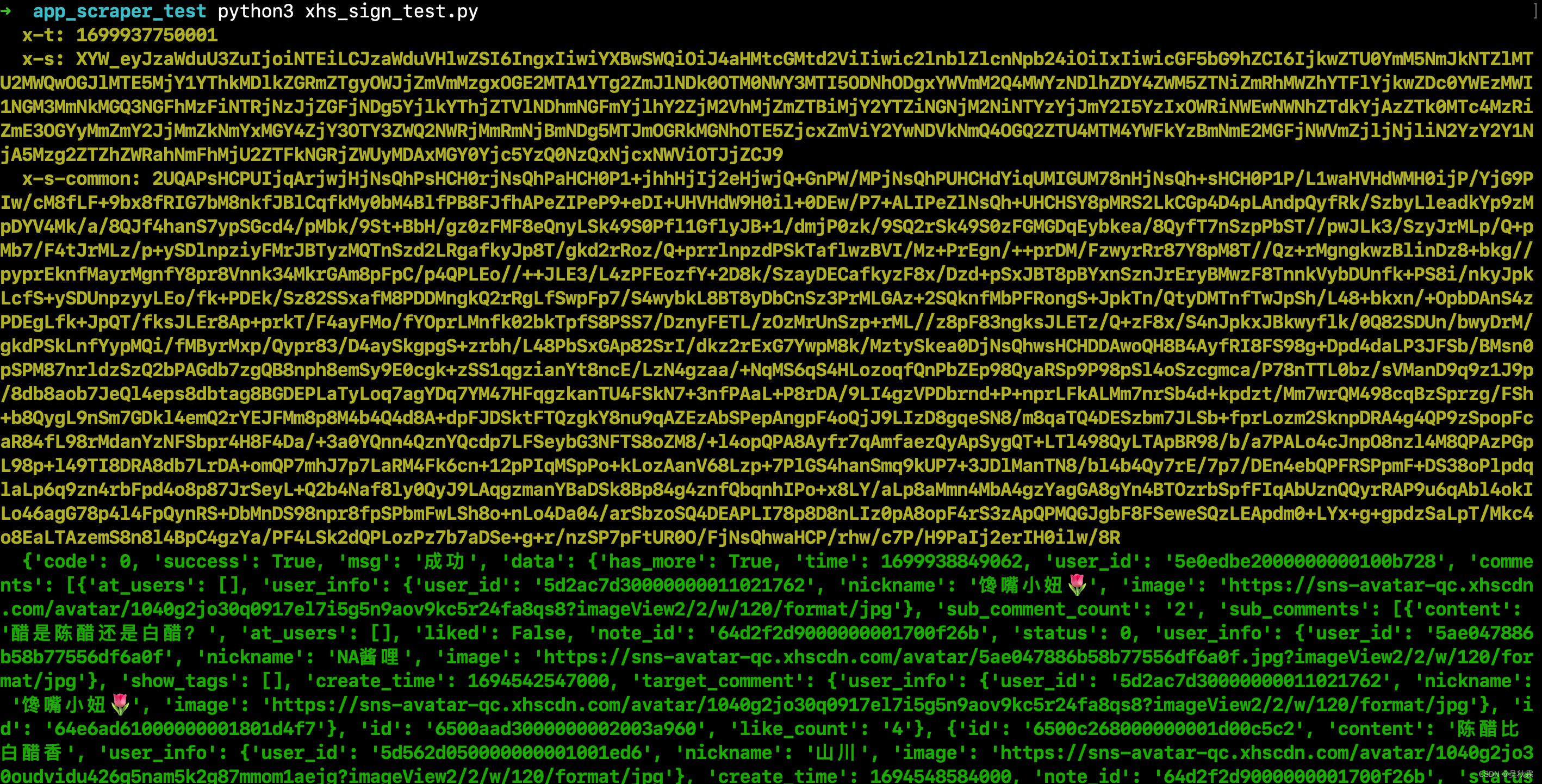
最终签名算法参数生成以后测试,接口数据正常响应:
部分签名算法,自己可以根据实际调式来补缺失的环境:
import binascii
import ctypes
import hashlib
import json
import random
import re
import string
import time
import urllib.parse
import requests
def sign(uri, data=None, ctime=None, a1="", b1=""):
def h(n):
m = ""
d = "A4NjFqYu5wPHsO0XTdDgMa2r1ZQocVte9UJBvk6/7=yRnhISGKblCWi+LpfE8xzm3"
for i in range(0, 32, 3):
o = ord(n[i])
g = ord(n[i + 1]) if i + 1 < 32 else 0
h = ord(n[i + 2]) if i + 2 < 32 else 0
x = ((o & 3) << 4) | (g >> 4)
p = ((15 & g) << 2) | (h >> 6)
v = o >> 2
b = h & 63 if h else 64
if not g:
p = b = 64
m += d[v] + d[x] + d[p] + d[b]
return m
v = int(round(time.time() * 1000) if not ctime else ctime)
raw_str = f"{v}test{uri}{json.dumps(data, separators=(',', ':'), ensure_ascii=False) if isinstance(data, dict) else ''}"
md5_str = hashlib.md5(raw_str.encode('utf-8')).hexdigest()
x_s = h(md5_str)
x_t = str(v)
common = {
"s0": 5,
"s1": "",
"x0": "1",
"x1": "",
"x2": "Windows",
"x3": "xhs-pc-web",
"x4": "",
"x5": a1,
"x6": x_t,
"x7": x_s,
"x8": b1,
"x9": mrc(x_t + x_s),
"x10": 1,
}
encodeStr = encodeUtf8(json.dumps(common, separators=(',', ':')))
x_s_common = b64Encode(encodeStr)
return {
"x-s": x_s,
"x-t": x_t,
"x-s-common": x_s_common,
}
def get_a1_and_web_id():
def random_str(length):
alphabet = string.ascii_letters + string.digits
return ''.join(random.choice(alphabet) for _ in range(length))
d = hex(int(time.time() * 1000))[2:] + random_str(30) + "5" + "0" + "000"
g = (d + str(binascii.crc32(str(d).encode('utf-8'))))[:52]
return g, hashlib.md5(g.encode('utf-8')).hexdigest()
img_cdns = [
"https://sns-img-qc.xhscdn.com",
"https://sns-img-hw.xhscdn.com",
"https://sns-img-bd.xhscdn.com",
"https://sns-img-qn.xhscdn.com",
]
def get_img_url_by_trace_id(trace_id: str, format: str = "png"):
return f"{random.choice(img_cdns)}/{trace_id}?imageView2/format/{format}"
def get_img_urls_by_trace_id(trace_id: str, format: str = "png"):
return [f"{cdn}/{trace_id}?imageView2/format/{format}" for cdn in img_cdns]
def get_trace_id(img_url: str):
return img_url.split("/")[-1].split("!")[0]
def get_imgs_url_from_note(note) -> list:
"""the return type is [img1_url, img2_url, ...]"""
imgs = note["image_list"]
if not len(imgs):
return []
return [get_img_url_by_trace_id(get_trace_id(img["info_list"][0]["url"])) for img in imgs]
def get_imgs_urls_from_note(note) -> list:
"""the return type is [[img1_url1, img1_url2, img1_url3], [img2_url, img2_url2, img2_url3], ...]"""
imgs = note["image_list"]
if not len(imgs):
return []
return [get_img_urls_by_trace_id(img["trace_id"]) for img in imgs]
video_cdns = [
"https://sns-video-qc.xhscdn.com",
"https://sns-video-hw.xhscdn.com",
"https://sns-video-bd.xhscdn.com",
"https://sns-video-qn.xhscdn.com",
]
def get_video_url_from_note(note) -> str:
if not note.get("video"):
return ""
origin_video_key = note['video']['consumer']['origin_video_key']
return f"{random.choice(video_cdns)}/{origin_video_key}"
def get_video_urls_from_note(note) -> list:
if not note.get("video"):
return []
origin_video_key = note['video']['consumer']['origin_video_key']
return [f"{cdn}/{origin_video_key}" for cdn in video_cdns]
def download_file(url: str, filename: str):
with requests.get(url, stream=True) as r:
r.raise_for_status()
with open(filename, 'wb') as f:
for chunk in r.iter_content(chunk_size=8192):
f.write(chunk)
def get_valid_path_name(text):
invalid_chars = '<>:"/\\|?*'
return re.sub('[{}]'.format(re.escape(invalid_chars)), '_', text)
def mrc(e):
ie = [
0, 1996959894, 3993919788, 2567524794, 124634137, 1886057615, 3915621685,
2657392035, 249268274, 2044508324, 3772115230, 2547177864, 162941995,
2125561021, 3887607047, 2428444049, 498536548, 1789927666, 4089016648,
2227061214, 450548861, 1843258603, 4107580753, 2211677639, 325883990,
1684777152, 4251122042, 2321926636, 335633487, 1661365465, 4195302755,
2366115317, 997073096, 1281953886, 3579855332, 2724688242, 1006888145,
1258607687, 3524101629, 2768942443, 901097722, 1119000684, 3686517206,
2898065728, 853044451, 1172266101, 3705015759, 2882616665, 651767980,
1373503546, 3369554304, 3218104598, 565507253, 1454621731, 3485111705,
3099436303, 671266974, 1594198024, 3322730930, 2970347812, 795835527,
1483230225, 3244367275, 3060149565, 1994146192, 31158534, 2563907772,
4023717930, 1907459465, 112637215, 2680153253, 3904427059, 2013776290,
251722036, 2517215374, 3775830040, 2137656763, 141376813, 2439277719,
3865271297, 1802195444, 476864866, 2238001368, 4066508878, 1812370925,
453092731, 2181625025, 4111451223, 1706088902, 314042704, 2344532202,
4240017532, 1658658271, 366619977, 2362670323, 4224994405, 1303535960,
984961486, 2747007092, 3569037538, 1256170817, 1037604311, 2765210733,
3554079995, 1131014506, 879679996, 2909243462, 3663771856, 1141124467,
855842277, 2852801631, 3708648649, 1342533948, 654459306, 3188396048,
3373015174, 1466479909, 544179635, 3110523913, 3462522015, 1591671054,
702138776, 2966460450, 3352799412, 1504918807, 783551873, 3082640443,
3233442989, 3988292384, 2596254646, 62317068, 1957810842, 3939845945,
2647816111, 81470997, 1943803523, 3814918930, 2489596804, 225274430,
2053790376, 3826175755, 2466906013, 167816743, 2097651377, 4027552580,
2265490386, 503444072, 1762050814, 4150417245, 2154129355, 426522225,
1852507879, 4275313526, 2312317920, 282753626, 1742555852, 4189708143,
2394877945, 397917763, 1622183637, 3604390888, 2714866558, 953729732,
1340076626, 3518719985, 2797360999, 1068828381, 1219638859, 3624741850,
2936675148, 906185462, 1090812512, 3747672003, 2825379669, 829329135,
1181335161, 3412177804, 3160834842, 628085408, 1382605366, 3423369109,
3138078467, 570562233, 1426400815, 3317316542, 2998733608, 733239954,
1555261956, 3268935591, 3050360625, 752459403, 1541320221, 2607071920,
3965973030, 1969922972, 40735498, 2617837225, 3943577151, 1913087877,
83908371, 2512341634, 3803740692, 2075208622, 213261112, 2463272603,
3855990285, 2094854071, 198958881, 2262029012, 4057260610, 1759359992,
534414190, 2176718541, 4139329115, 1873836001, 414664567, 2282248934,
4279200368, 1711684554, 285281116, 2405801727, 4167216745, 1634467795,
376229701, 2685067896, 3608007406, 1308918612, 956543938, 2808555105,
3495958263, 1231636301, 1047427035, 2932959818, 3654703836, 1088359270,
936918000, 2847714899, 3736837829, 1202900863, 817233897, 3183342108,
3401237130, 1404277552, 615818150, 3134207493, 3453421203, 1423857449,
601450431, 3009837614, 3294710456, 1567103746, 711928724, 3020668471,
3272380065, 1510334235, 755167117,
]
o = -1
def right_without_sign(num, bit=0) -> int:
val = ctypes.c_uint32(num).value >> bit
MAX32INT = 4294967295
return (val + (MAX32INT + 1)) % (2 * (MAX32INT + 1)) - MAX32INT - 1
for n in range(57):
o = ie[(o & 255) ^ ord(e[n])] ^ right_without_sign(o, 8)
return o ^ -1 ^ 3988292384
lookup = [
"Z",
"m",
"s",
"e",
"r",
"b",
"B",
"o",
"H",
"Q",
"t",
"N",
"P",
"+",
"w",
"O",
"c",
"z",
"a",
"/",
"L",
"p",
"n",
"g",
"G",
"8",
"y",
"J",
"q",
"4",
"2",
"K",
"W",
"Y",
"j",
"0",
"D",
"S",
"f",
"d",
"i",
"k",
"x",
"3",
"V",
"T",
"1",
"6",
"I",
"l",
"U",
"A",
"F",
"M",
"9",
"7",
"h",
"E",
"C",
"v",
"u",
"R",
"X",
"5",
]
def tripletToBase64(e):
return (
lookup[63 & (e >> 18)] +
lookup[63 & (e >> 12)] +
lookup[(e >> 6) & 63] +
lookup[e & 63]
)
def encodeChunk(e, t, r):
m = []
for b in range(t, r, 3):
n = (16711680 & (e[b] << 16)) + \
((e[b + 1] << 8) & 65280) + (e[b + 2] & 255)
m.append(tripletToBase64(n))
return ''.join(m)
def b64Encode(e):
P = len(e)
W = P % 3
U = []
z = 16383
H = 0
Z = P - W
while H < Z:
U.append(encodeChunk(e, H, Z if H + z > Z else H + z))
H += z
if 1 == W:
F = e[P - 1]
U.append(lookup[F >> 2] + lookup[(F << 4) & 63] + "==")
elif 2 == W:
F = (e[P - 2] << 8) + e[P - 1]
U.append(lookup[F >> 10] + lookup[63 & (F >> 4)] +
lookup[(F << 2) & 63] + "=")
return "".join(U)
def encodeUtf8(e):
b = []
m = urllib.parse.quote(e, safe='~()*!.\'')
w = 0
while w < len(m):
T = m[w]
if T == "%":
E = m[w + 1] + m[w + 2]
S = int(E, 16)
b.append(S)
w += 2
else:
b.append(ord(T[0]))
w += 1
return b
def base36encode(number, alphabet='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'):
"""Converts an integer to a base36 string."""
if not isinstance(number, int):
raise TypeError('number must be an integer')
base36 = ''
sign = ''
if number < 0:
sign = '-'
number = -number
if 0 <= number < len(alphabet):
return sign + alphabet[number]
while number != 0:
number, i = divmod(number, len(alphabet))
base36 = alphabet[i] + base36
return sign + base36
def base36decode(number):
return int(number, 36)
def get_search_id():
e = int(time.time() * 1000) << 64
t = int(random.uniform(0, 2147483646))
return base36encode((e + t))
def cookie_str_to_cookie_dict(cookie_str: str):
cookie_blocks = [cookie_block.split("=")
for cookie_block in cookie_str.split(";") if cookie_block]
return {cookie[0].strip(): cookie[1].strip() for cookie in cookie_blocks}
def cookie_jar_to_cookie_str(cookie_jar):
cookie_dict = requests.utils.dict_from_cookiejar(cookie_jar)
return ";".join([f"{key}={value}" for key, value in cookie_dict.items()])
def update_session_cookies_from_cookie(session: requests.Session, cookie: str):
cookie_dict = cookie_str_to_cookie_dict(cookie) if cookie else {}
if "a1" not in cookie_dict or "webId" not in cookie_dict:
# a1, web_id = get_a1_and_web_id()
cookie_dict |= {"a1": "187d2defea8dz1fgwydnci40kw265ikh9fsxn66qs50000726043",
"webId": "ba57f42593b9e55840a289fa0b755374"}
if "gid" not in cookie_dict:
cookie_dict |= {
"gid.sign": "PSF1M3U6EBC/Jv6eGddPbmsWzLI=",
"gid": "yYWfJfi820jSyYWfJfdidiKK0YfuyikEvfISMAM348TEJC28K23TxI888WJK84q8S4WfY2Sy"
}
new_cookies = requests.utils.cookiejar_from_dict(cookie_dict)
session.cookies = new_cookies
关键词搜索测试如下:

用户笔记列表测试如下:

话题笔记测试如下:

笔记评论测试如下:

好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章