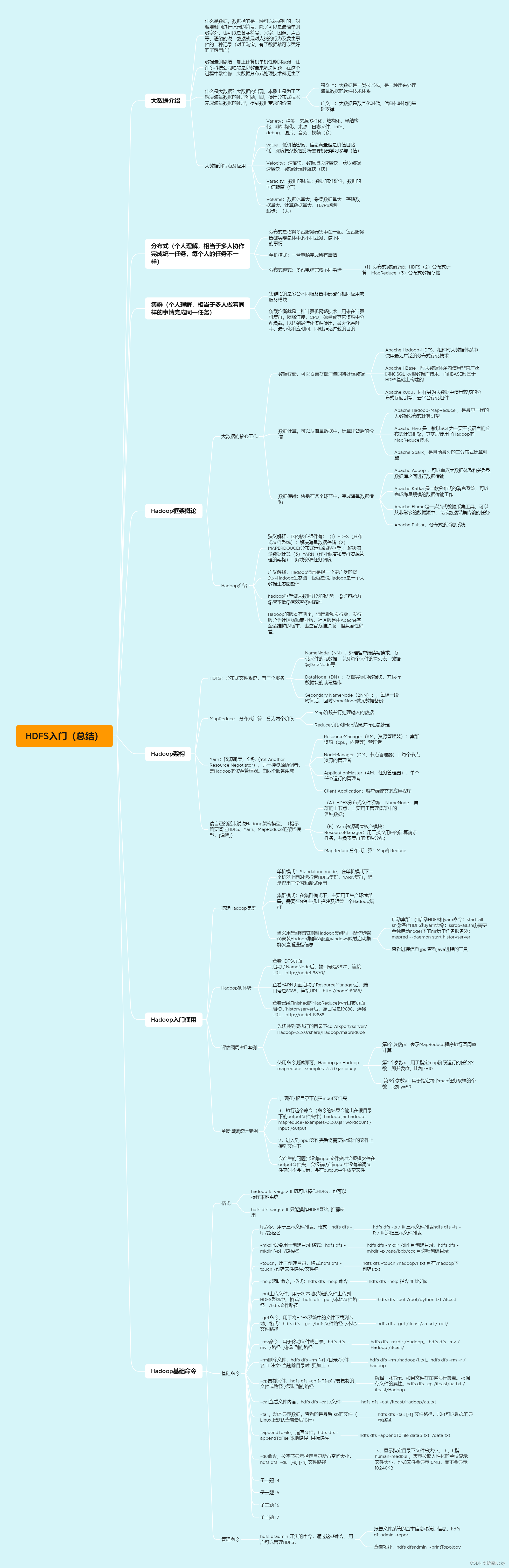
1,大数据介绍
定义
数据指的是:一种可以被鉴别的、对客观事件进行记录的符号,除了可以是最简单的
数字外,也可以是各类符号、文字、图像、声音等。
通俗地说,数据就是对人类的行为及发生事件的一种记录。
存在的价值
数据的背后都会隐藏着巨大的商业价值,而有了丰富的数据支撑,也可以让我们更好
的了解:事物在现实世界的运行规律。
当下时代已经是数据的时代,数据非常重要并且蕴含巨大的价值。
大数据技术栈是对超大规模的海量数据,进行处理并挖掘出数据背后价值的技术体系。
什么是大数据
①大数据的出现,本质上是为了解决海量数据的处
理难题。 即:使用分布式技术完成海量数据的处理,得到数据背后蕴含的价值。 狭义的(技术思维的)
②(1)海量的数据
数字时代人人联网,日常活动产生的数据记录是海量的,背后蕴含的价值也是巨大
的。
(2)基础设施
大数据在技术上,是数字化时代的基础设施。数字化时代的发展离不开大数据技术的
支撑。
(3)生活
警务、政务、工业、电商、金融、能源、物流、通讯、科研、教育等等,大数据甚至已经渗入了生活的方方面面。
狭义上:大数据是一类技术栈,是一种用来处理海量数据的软件技术体系。
广义上:大数据是数字化时代、信息化时代的基础(技术)支撑,以数据为基础,为生活赋能
③大数据的特点及应用
Volume:数据体量大;采集数据量大、存储数据量大、计算数据量大、TB/PB级别起步;
Variety:种类、来源多样化;结构化、半结构化、非结构化、来源:日志文本、图片、音频、视频;
Value:低价值密度;信息海量但是价值密度低、深度复杂挖掘分析需要机器学习参与;
Velocity:速度快;数据增长速度快、获取数据速度快、数据处理速度快;
Veracity:数据的质量;数据的准确性、数据的可信赖度。
大数据的应用场景
(1)电商方面
精准广告位,通过对用户的浏览行为、点击行为等进行大数据采集,分析,挖掘用户的二层三层喜欢,扩大产出。
(2)传媒方面
猜你喜欢,通过对受众人群进行大数据分析,结合对应算法,对受众喜欢度进行交互推荐。
(3)金融方面
在投资理财中,通过对个人的信用评估、风险承担能力评估,集合众多理财产品、推荐相应的投资理财产品。
(4)交通方面
目前,交通的大数据应用主要在两个方面:预测车流量,并进行路线规划;利用大数据来实现即时信号灯调度,提高已有线路通行能力。
(5)电信方面
在智慧营业厅里,通过对用户当前的行为习惯、偏好,节假日的相应数据变化,调整自身业务结构,做到按需分配。
(6)安防方面
通过人脸识别,匹配,存储用户数据,结合人工智能,分析及甄别用户行为,预防犯罪行为的发生。
2,分布式
定义:分布式是指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情
理解:单机模式:一台计算机完成所有事。可理解为:一个餐厅的厨房只有一个人,这个人既要买菜、又要切菜、还要炒菜,效率很低!
分布式模式:多台电脑完成不同事。可理解为:一个餐厅的厨房有三个人,一个人买菜、一个人切菜、一个人炒菜,效率提高了!
1,分布式存储
大型网站常常需要处理海量数据,单台计算机往往无法提供足够的内存空间。此时,可以对这些数据进行分布式存储,比如Apache Hadoop HDFS。
2,分布式计算
(b)分布式计算
随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费相当长的时间来完成。
分布式计算将该应用分解成各个小部分,并分配给多台计算机进行处理。
这样可以节约整体计算时间,大大提高计算效率,比如 Apache Hadoop MapReduce。
3,集群
定义:集群指的是多台不同的服务器中部署有相同应用或服务模块。当在多台不同的服务器中,部署有相同应用或服务模块时,就构成了一个集群。集群往往需要通过负载均衡,来对外提供服务。
【负载均衡就是一种计算机网络技术,用来在计算机集群、网络连接、CPU、磁盘或其他资源中分配负载,以达到最佳化资源使用、最大化吞吐率、最小化响应时间,同时避免过载的目的。】
1,思考:比如,要让众多的服务器一起工作,该如何保证高效且不出问题呢?
答:在大数据体系中,分布式的调度主要有两类架构模式:去中心化模式、中心化模式。
(1)去中心化模式:没有明确的中心服务器,而它们之间基于特定规则进行同步协
调。
(2)中心化模式:以某个服务器为中心,协调调度其他服务器一起工作。
我们学习的Hadoop框架,就是一个典型的主从模式(中心化模式)架构的大数据技
术框架。
2,分布式和集群的区别
分布式:多台服务器做着不同的任务合力完成一件事情;
集群:多台服务器做着相同的任务完成一件事。
3,Hadoop框架概论
存在的意义:大数据的核心工作,其实就是:从海量的高增长、多类别、低信息密度的数据中,挖
掘出高质量的结果。
工作分类
(1)数据存储:可以妥善存储海量的待处理数据;
(2)数据计算:可以从海量数据中,计算出背后的价值;
(3)数据传输:协助在各个环节中,完成海量数据的传输。
1,数据存储
[A] Apache Hadoop - HDFS
Apache Hadoop框架内的组件HDFS是大数据体系中使用最为广泛的分布式存储技
术。
[B]Apache Hbase
Apache HBase是大数据体系内使用非常广泛的NoSQL KV型数据库技术,而HBase
是基于HDFS基础上构建的。
[C] Apache Kudu
Apache Kudu同样为大数据体系中使用较多的分布式存储引擎。
[D] 云平台存储组件
除此以外,各大云平台厂商也有相应的大数据存储组件,比如阿里云的OSS、
UCloud的US3、AWS的S3、金山云的KS3等等。
2,数据计算
[A] Apache Hadoop - MapReduce
Apache Hadoop的MapReduce组件是最早一代的大数据分布式计算引擎,对大数据的发展做出了卓越的贡献。
[B] Apache Hive
Apache Hive是一款以SQL为主要开发语言的分布式计算框架。其底层使用了Hadoop的MapReduce技术。Apache Hive至今仍活跃在大数据一线,被许多公司使用。
[C] Apache Spark
Apache Spark是目前全球范围内最火热的分布式内存计算引擎,目前,Spark也是大数据体系中的明星计算产品。
[D] Apache Flink
Apache Flink同样也是一款明星级的大数据分布式内存计算引擎,侧重于流批一体化处理。特别是在实时计算(流计算)领域占据了大多数的国内市场。
3,数据传输
[A] Apache Sqoop
Apache Sqoop是一款ETL工具,可以协助大数据体系和关系型数据库之间进行数据传输
[B] Apache Flume
Apache Flume是一款流式数据采集工具,可以从非常多的数据源中,完成数据采集传输的任务。
[C] Apache Kafka
Apache Kafka是一款分布式的消息系统,可以完成海量规模的数据传输工作。目前,Kafka在大数据领域也是明星产品。
[D] Apache Pulsar
Apache Pulsar同样是一款分布式的消息系统。在大数据领域同样有非常多的使用者。
3.1Hadoop 介绍
背景:Hadoop是一个用Java语言实现存储、计算大规模数据的开源软件框架,目前,属于
Apache旗下。Hadoop是Apache Lucene创始人Doug Cutting(道·卡廷)创建的,最早起源一个
Nutch项目。
1,Hadoop解释
Hadoop也分狭义与广义解释。
(1)狭义解释,Hadoop指Apache这款开源框架,它的核心组件有:
a)HDFS(分布式文件系统):解决海量数据存储;
b)MAPREDUCE(分布式运算编程框架):解决海量数据计算;
c)YARN(作业调度和集群资源管理的框架):解决资源任务调度。
Hadoop是一个集合了:存储、计算、资源调度为一体的大数据分布式框架。
(2)广义解释
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈,也就是说Hadoop是一个大数据生态圈整体。
使用Hadoop框架做大数据开发,优势
(1)扩容能力:Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中;
(2)成本低:Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低;
(3)高效率:通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快;
(4)可靠性:能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
3.2Hadoop架构
(1)HDFS:分布式文件系统
(2)MapReduce:分布式计算
(3)Yarn:资源调度
(1)HDFS:分布式文件系统
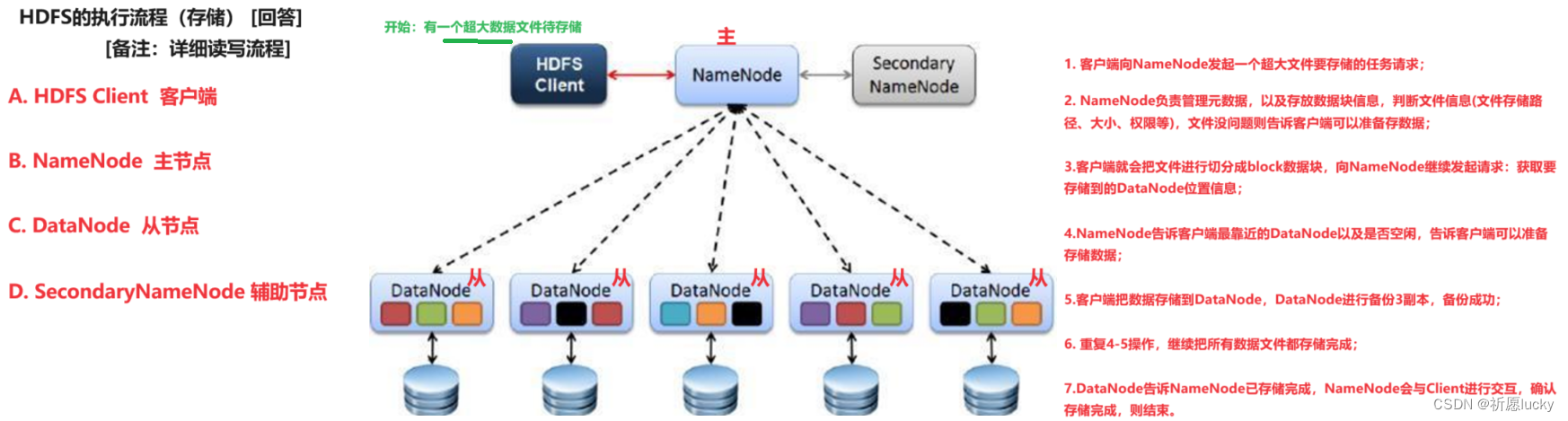
HDFS全称是:Hadoop Distributed File System,是一个分布式文件系统。
HDFS有三个服务:
a) NameNode(NN):处理客户端读写请求,存储文件的元数据,以及每个文件
的块列表、数据块DataNode等;
b)DataNode(DN):存储实际的数据块,并执行数据块的读写操作;
c)Secondary NameNode(2NN):每隔一段时间后,会对NameNode做元数据
备份
NameNode:集群的主节点,主要用于管理集群中的各种数据;
SecondaryNameNode:主要能用于Hadoop元数据信息的辅助管理;
DataNode:集群的从节点,主要用于存储集群当中的各种数据。
(2)MapReduce:分布式计算
MapReduce将计算过程分为两个阶段,分别是Map和Reduce:
a)Map阶段并行处理输入的数据;
b)Reduce阶段对Map结果进行汇总处理。
(3)Yarn:资源调度
YARN的全称是Yet Another Resource Negotiator,另一种资源协调者,是Hadoop的资源管理器。 由四个服务组成,分别是:
a)ResourceManager(RM,资源管理器):集群资源(cpu,内存等)管理者;
b)NodeManager(DM,节点管理器):单个节点资源的管理者;
c)ApplicationMaster(AM,任务管理器):单个任务运行的管理者;
d)Client Application:客户端提交的应用程序。
存在意义:用于接收用户的计算请求任务,并负责集群的资源分配;
4,Hadoop入门使用
集群负责海量数据的存储,集群中的角色主要有:
a)NameNode:主节点
b)DataNode:从节点
c)SecondaryNameNode:辅助节点
YARN集群负责海量数据运算的资源调度,集群中的角色主要有:
a)ResourceManager:接收请求任务,负责资源调度
b)NodeManager:负责处理主节点分配的任务
1,当要搭建集群时的常见方式
(1)单机模式
在单机模式下,一个机器上同时运行着HDFS集群、YARN集群,通常仅用于学习和调试使用。
(2)集群模式
在集群模式下,主要用于生产环境部署,需要在N台主机上搭建及组成一个Hadoop集群。
集群模式中的主节点和从节点会分开部署在不同的机器上。
启动集群
a)启动HDFS和yarn命令: start-all.sh
b)停止HDFS和yarn命令: stop-all.sh
c)需要单独启动node1下的mr历史任务服务器: mapred --daemon start historyserver
D)查看进程信息 jps
(a)查看HDFS页面
启动了NameNode后,端口号是9870,连接URL:http://node1:9870/
(b)查看YARN页面
启动了ResourceManager后,端口号是8088,连接URL:http://node1:8088/
(c)查看已经Finished的MapReduce运行日志页面
启动了historyserver后,端口号是19888,连接URL:http://node1:19888
评估圆周率π案例
在Hadoop框架的安装包中,官方提供了MapReduce程序的examples示例,以便开发者快速体验分布式计算,比如计算圆周率、统计词频结果等。
操作步骤:
1,先通过cd命令切换当前目录到指定文件夹
命令cd /export/server/Hadoop-3.3.0/share/Hadoop/mapreduce
2,直接运行命令Hadoop jar Hadoop-mapreduce-examples-3.3.0.jar pi x y
参数解释:#第1个参数pi:表示MapReduce程序执行圆周率计算
第2个参数x:用于指定map阶段运行的任务次数,即并发度,比如x=10
第3个参数y:用于指定每个map任务取样的个数,比如y=50
单词词频统计案例
在词频统计文本数据过程中,统计相同单词出现的总次数。
步骤1,一样先通过cd命令切换当前目录到指定文件夹
命令cd /export/server/Hadoop-3.3.0/share/Hadoop/mapreduce
2,运行命令前准备 ,在HDFS界面新建一个input文件夹,并上传一个txt文件到文件夹下(用于被统计词频)
并且要保证output文件夹下没有文件,不然会报错
3,运行命令:hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
HDFS文件系统
HDFS(Hadoop Distribute File System)指的是:Hadoop分布式文件系统,是Hadoop核心组件之一,用于提供分布式存储服务。
HDFS解决的问题是:大数据存储,它们是横跨在多台计算机上的存储系统,为存储和处理超大规模数据提供扩展能力。
使用场景:非常适于存储大型数据(比如TB 和 PB),HDFS可以使用多台计算机存储文件,并提供统一的访问接口,像是访问一个普通文件系统来使用。
1,HDFS通常也具有如下特性:
(1)HDFS文件系统可存储超大文件,时效性稍差;
(2)HDFS具有硬件故障检测和自动快速恢复功能;
(3)HDFS为数据存储提供很强的扩展能力;
(4)HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改;
(5)HDFS可在普通廉价的机器上运行。
HDFS架构
1,HDFS特性有:
(1)HDFS是一个文件系统,用于存储文件,可以通过统一的目录来定位文件;
(2)HDFS是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的
角色;
(3)HDFS内部采用了Master/Slave架构[即主从架构]。
2,HDFS有四个基本组件
(1)HDFS Client
(2)NameNode
(3)DataNode
(4)Secondary NameNode
1,HDFS Client:客户端
客户端主要负责文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的
block,然后进行存储。
a)与NameNode交互,获取文件的位置信息;
b)与DataNode交互,读取或者写入数据;
c)Client 提供一些命令来管理和访问HDFS,比如启动或者关闭HDFS。
2,NameNode:主节点Master,管理者
NameNode用于管理HDFS元数据(文件路径,文件的大小,文件的名字,文件权限,文
件的block切片信息….)。
a)配置副本策略;
b)处理客户端读写请求。
3,DataNode:从节点Slave
当NameNode下达命令后,DataNode来执行实际的操作。
a)存储实际的数据块;
b)执行数据块的读/写操作;
c)定时向NameNode汇报block信息。
4,Secondary NameNode:辅助节点
Secondary NameNode用于辅助NameNode,并分担其工作量。在紧急情况下,可辅
助恢复NameNode。
注意:Secondary NameNode并非NameNode的备份。当NameNode挂掉的时候,它也
并不能马上替换NameNode并提供服务。
HDFS的Shell命令入门
1,两种方式
hadoop fs # 既可以操作HDFS,也可以操作本地系统
hdfs dfs # 只能操作HDFS系统, 推荐使用
2,应用示例
应用例子:
hdfs dfs -ls / # 显示文件列表
hdfs dfs –ls -R / # 递归显示文件列表
hdfs dfs -mkdir /dir1 # 创建目录
hdfs dfs -mkdir -p /aaa/bbb/ccc # 递归创建目录
hdfs dfs -touch /hadoop/1.txt # 在/hadoop下创建1.txt
hdfs dfs -help 指令 # 比如ls 查看帮助信息
3,常用命令
(1)-put 上传文件
hdfs dfs -put /本地文件路径 /hdfs文件路径
hdfs dfs -put /root/python.txt /itcast
(2)-get 下载文件
hdfs dfs -get /hdfs文件路径 /本地文件路径
hdfs dfs -get /itcast/aa.txt /root/
(3)-mv 移动文件或目录(移动到空文件或文件夹下等于重命名)
hdfs dfs -mv /路径 /移动到的路径
hdfs dfs -mv /Hadoop /itcast/
(4)-rm 删除目录
hdfs dfs -rm [-r] /目录/文件名 # 注意: 当删除目录时, 要加上-r
hdfs dfs -rm /hadoop/1.txt
(5)-cp 复制文件
hdfs dfs -cp /要复制的文件或路径 /复制到的路径
hdfs dfs -cp /itcast/aa.txt /itcast/Hadoop
(6)-cat 查看文件内容
hdfs dfs -cat /文件
hdfs dfs -cat /itcast/Hadoop/aa.txt