声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请在公众号【K哥爬虫】联系作者立即删除!
目标
目标:百 X 网数字九宫格验证码逆向分析
网址:aHR0cHM6Ly9iZWlqaW5nLmJhaXhpbmcuY29tL296L3M5dmVyaWZ5X2h0bWw=

抓包分析
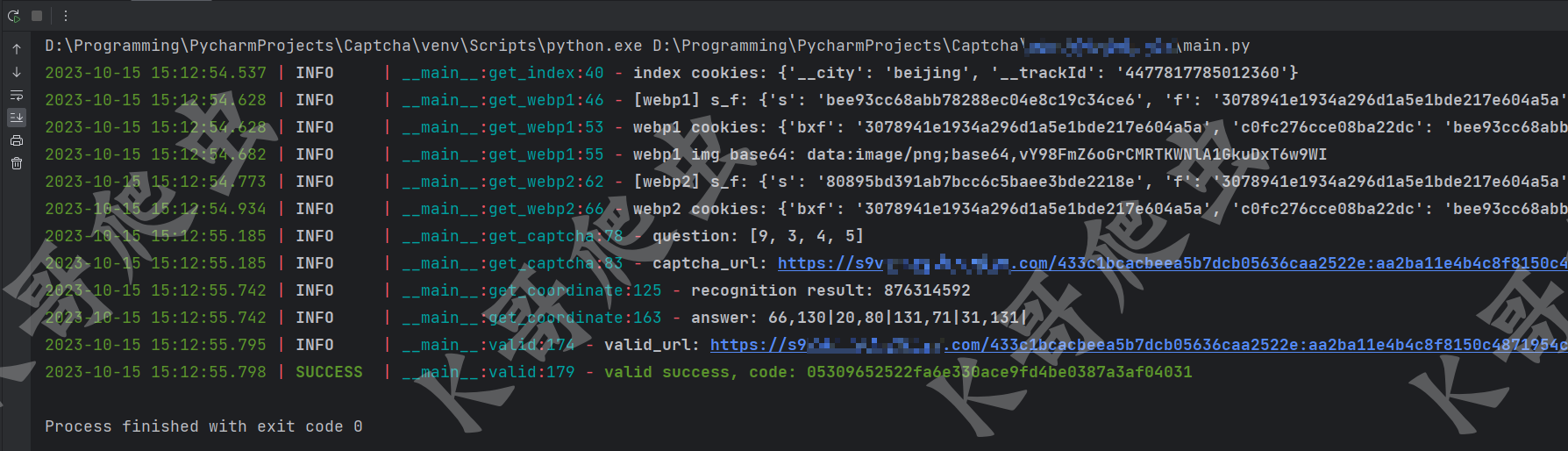
本例中的验证码不是很难,但网站埋了点儿坑,容易出现识别正确、参数也正确,但仍然请求不成功的情况。访问主页响应码为 307,接着请求了一个 bf.js 和两个 s.webp 的图片,然后又跳转到首页出现验证码。如果你没有以上步骤,请求主页直接就是 200 出现验证码,则需要清除 cookie 后再访问,因为第一次 307 到请求 bf.js 再到两次 s.webp 都是在设置 cookie。
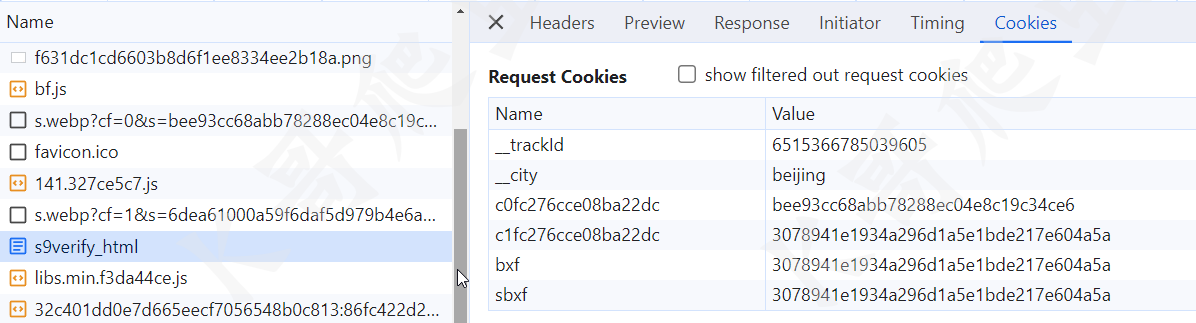
第一次请求主页,response headers 会设置一个名为 _trackId 和 __city 的 cookie,如下图所示:

然后带着这两个 cookie 请求了一个 bf.js,这个 js 用于后续两个 s.webp 请求参数的加密,这里注意,第一个坑,虽然可以直接调试 js 扣算法下来后面直接用就行了,但是这个 js 必须得请求一遍,不然后面请求主页的时候一直是 307。

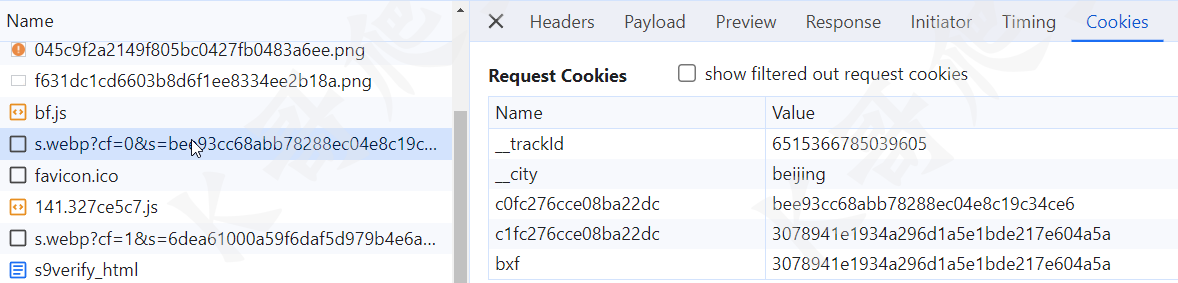
然后请求第一个 s.webp,get 请求,有三个参数:cf、s 和 f,明显是加密得来的,同时请求的 cookie 也多了三个值:c0fc276cce08ba22dc、c1fc276cce08ba22dc 和 bxf,如下图所示:

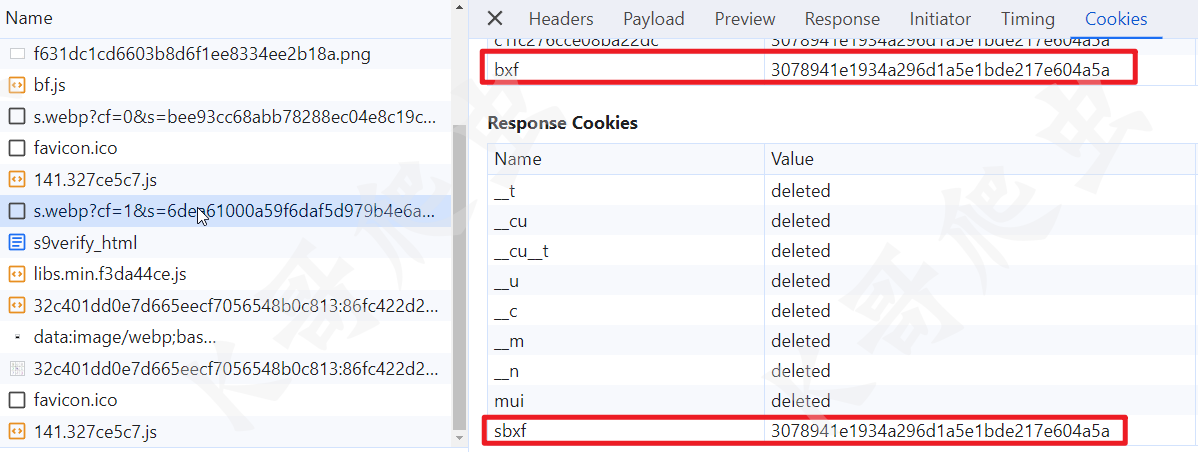
然后请求第二个 s.webp,和第一个类似,get 请求也有三个参数:cf、s 和 f,cookie 和第一个一样,但第二次请求返回了一个名为 sbxf 的新 cookie,其值和 bxf、c1fc276cce08ba22dc 其实是一样的,如下图所示:
然后带上 __trackId、__city、c0fc276cce08ba22dc、c1fc276cce08ba22dc、bxf 和 sbxf 这六个 cookie 再次访问主页,就是验证码页面了,返回的 html 里有个新的 js,很长一串,如下图所示:

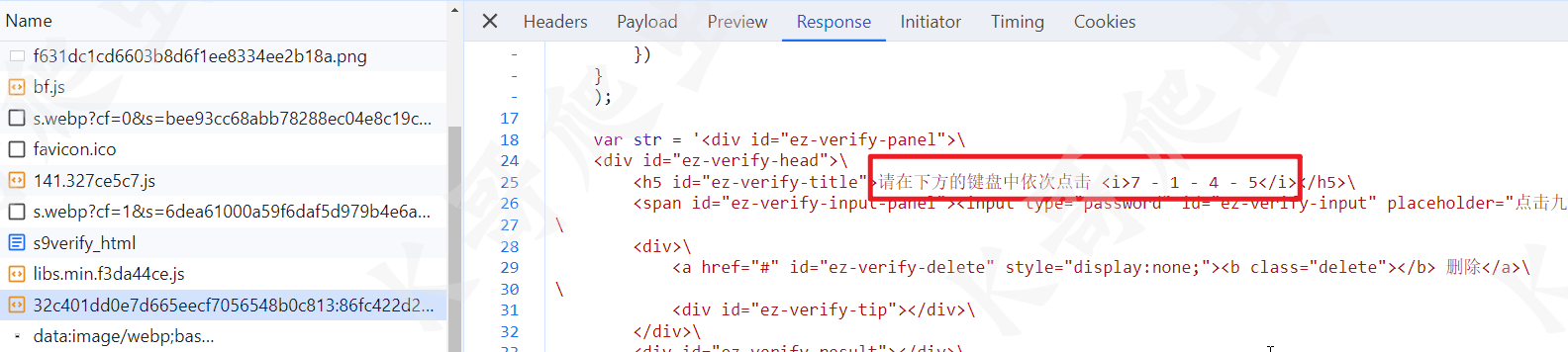
然后观察这个 js,里面包含了验证码图片的 URL,以及需要点击的数字,如下图所示:

点击验证后,会给 verify_url 发一个 get 请求,请求参数主要有一个 data,即点击坐标(这个坐标也有讲究,有可能你的值是对的,但有时候也不成功,这个后文再细说),cookie 和前面的请求一样,如果验证成功,会返回 ret 为 0,且有一个 code 供后续请求使用,如下图所示:


获取 cookie
这里再注意一点,所有的请求,header 只需要 Referer 和 User-Agent 就行了,不要乱加,比如多了个 Host 也有可能导致后续请求不成功。
想要拿验证码,得先搞定 cookie,总体流程如下:
- 请求首页
s9verify_html获取__trackId和__city,主要是__trackId,__city要不要都行; - 请求
bf.js,这一步不干啥,但必须得请求,不然 cookie 不能用; - 第一次请求
s.webp,cookie 里多了c0fc276cce08ba22dc、c1fc276cce08ba22dc和bxf,均为 js 生成; - 第二次请求
s.webp,返回的 cookie 里多了sbxf,其值和bxf一样,这一步可以理解为激活 cookie,使其有效。
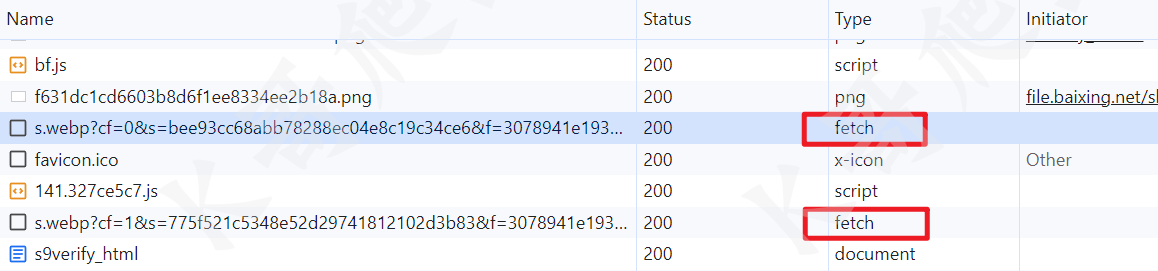
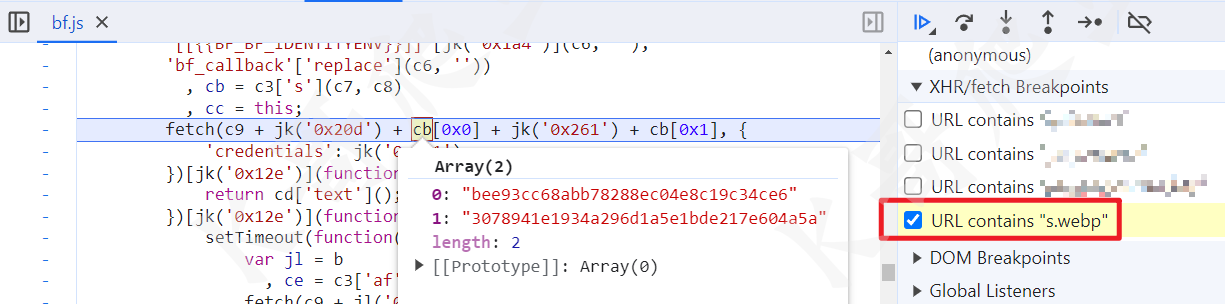
前两步倒没有啥,第 3、4 步都有加密参数 s 和 f,观察这两个 s.webp 都是 fetch 请求,所以我们直接一个 fetch 断点,断下后可以看到 cb 就是我们需要的两个参数:
观察 bf.js 是一个小小的类似 OB 混淆,可以 AST 解一下混淆,但这个逻辑不是很复杂,所以直接硬看也行,关键语句 cb = c3['s'](c7, c8),c7 是定值一个字符串 fc276cce08ba22dc,c8 也是定值表示颜色的字符串 rgba(255, 0, 0, 255):
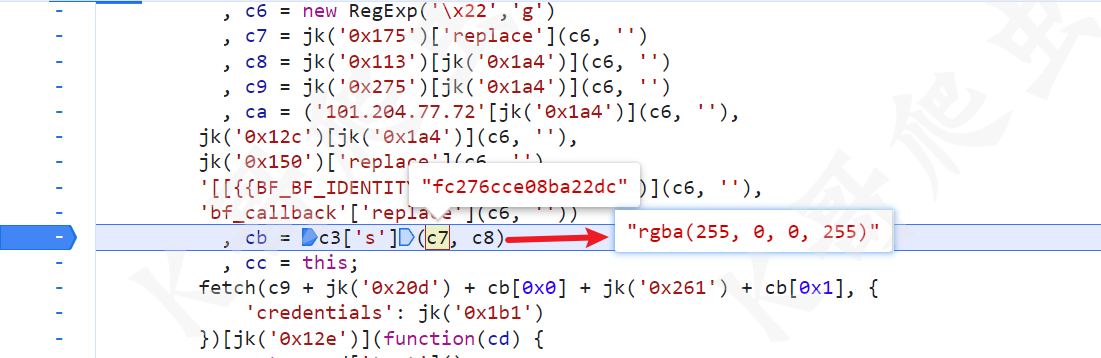
主要是 c3['s']() 这个方法,跟进去,首先会取一下 c0fc276cce08ba22dc、c1fc276cce08ba22dc 和 bxf 三个值,如果有的话,直接返回,如果没有的话,会生成新的,生成方法主要是 c6 这个函数,如下图所示:
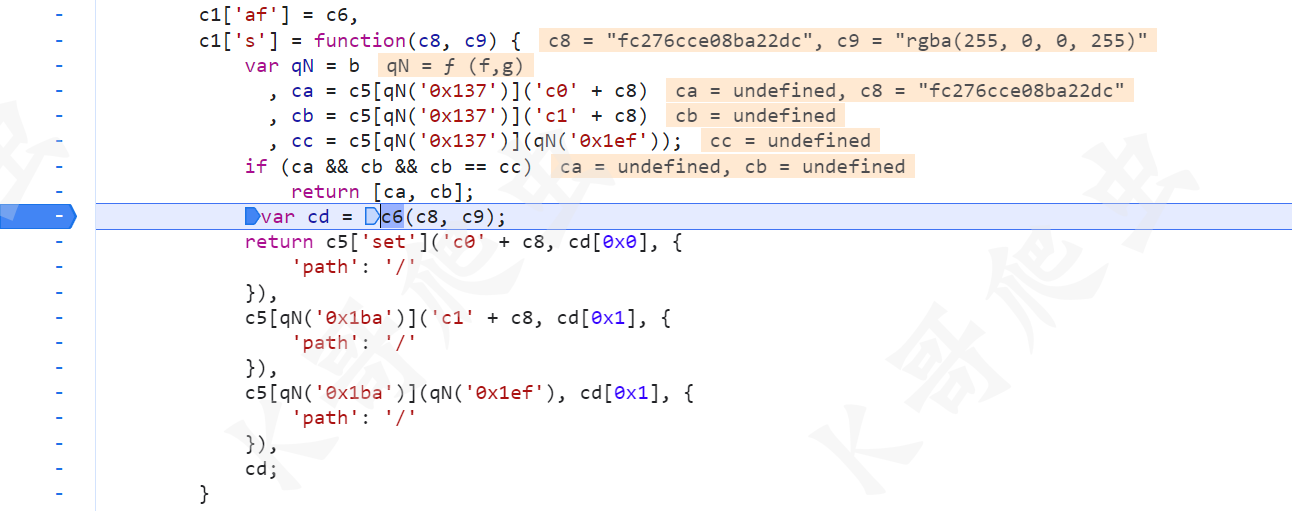
继续跟到 c6 方法里,首先对字符串 rgba(255, 0, 0, 255) 做了一个操作,生成了一张图片的 base64 字符串:
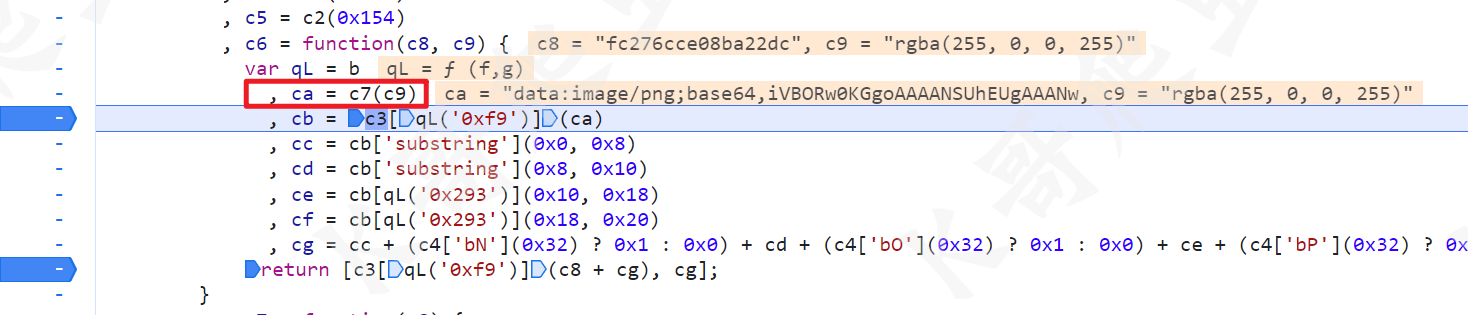
这里其实很明显是 canvas 绘图的一些操作,跟到 c7 看看确实是这样的:
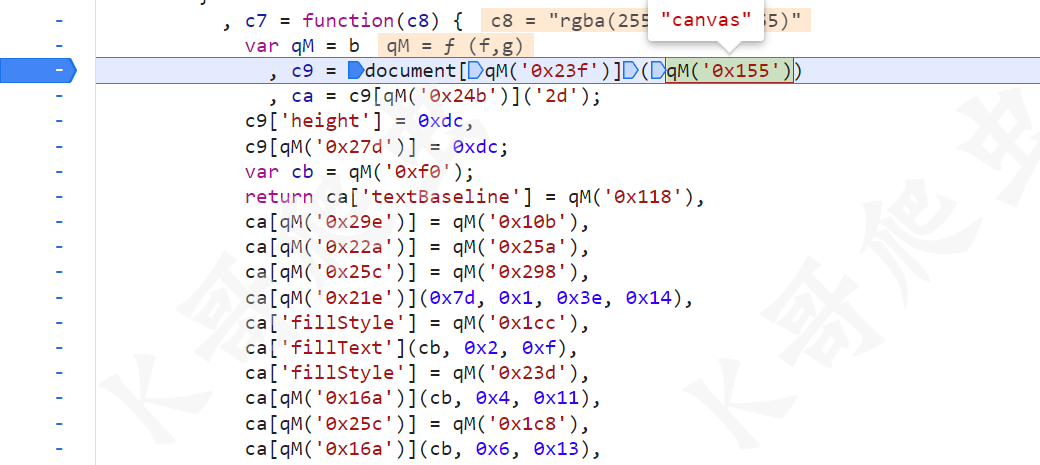
这里对于我们扣算法来说,其实就不需要管了,因为同一台设备的同一个浏览器,按照相同的规则绘制的图片,base64 值是一样的,所以我们直接忽略 c7 这个方法,直接把生成的 base64 值拿来用就行了。
然后又将 base64 值进行了一个 c3["hash"]() 的操作,根据最终的值,或者跟到方法里去看,很容易发现这个其实就是个 MD5 的操作:
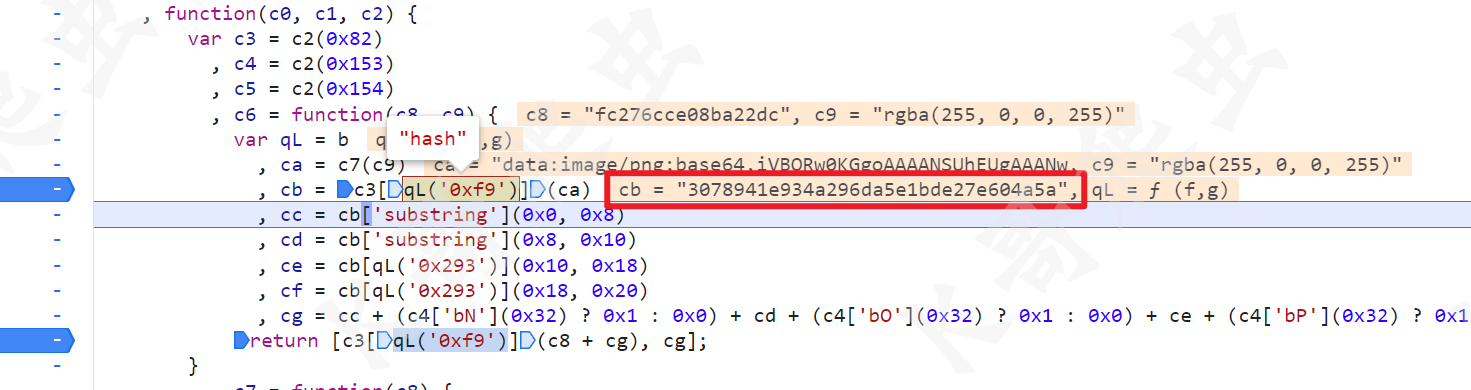
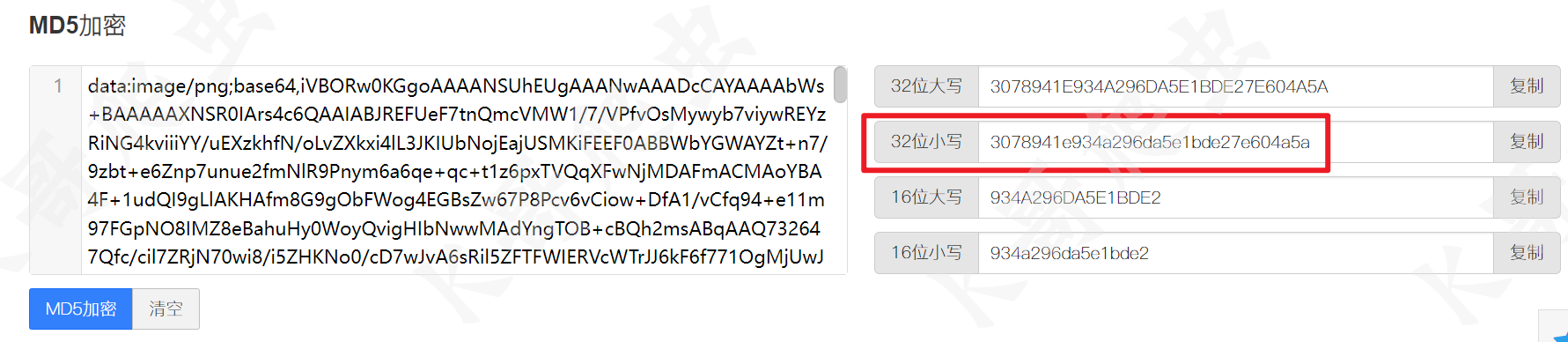
接着往下看,八个字符串为一组,将 md5 值分为四组,然后四组之间用 0 或者 1 连接,拼接成新的 35 位字符串,拼接的是 0 还是 1,取决于中间的三目语句,判断是否为 true,支持情况下都是 true,所以扣算法的话根本就没必要再跟进去看是怎么判断的,直接用 1 拼接就完事儿了。然后将固定的字符串 fc276cce08ba22dc 和这 35 位字符串拼接起来再一次 MD5,就得到了参数 s 的值,而参数 f 的值则是这个 35 位字符串。
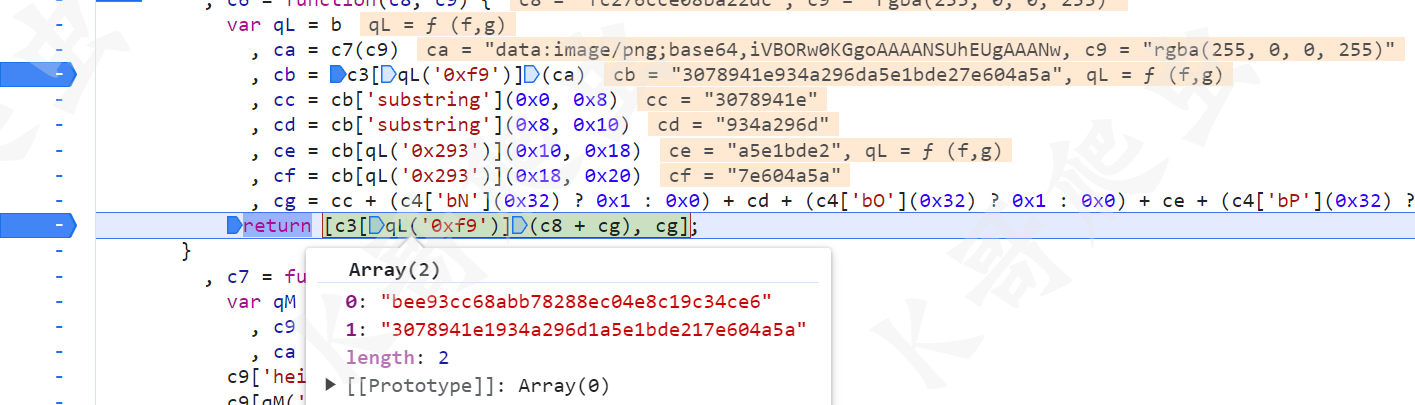
第一个 s.webp fetch 操作就完成了,接着是第二个 s.webp,就在第一个 fetch 附近,如下图的 ce 就是第二次的 s、f 参数的值:

这里生成的方法大致是一样的,首先 cd 是一个新的图片的 base64 值,这个值是第一次 s.webp 请求成功返回的,先把这个新的 base64 MD5 加密一下,生成一个新的字符串,相当于替换了第一次请求固定的字符串 fc276cce08ba22dc,后续的流程和第一次都一样了:
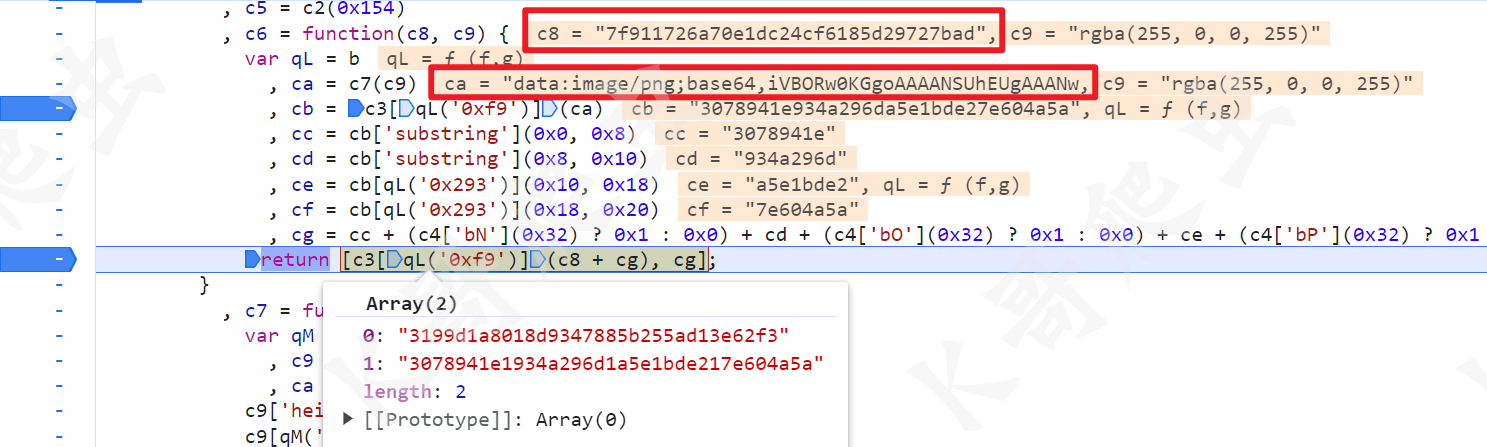
这两次生成 s 和 f 的值的流程可以精简成以下 js 实现:
MD5 = require("md5")
var baseImg = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAANwAAADcCAYAAAAbWs+BAAAAAXNSR0IArs4c6QAAIABJREFUeF7tnQm..."
function getParams(c8) {
var cb = MD5(baseImg)
, cc = cb.substring(0, 8)
, cd = cb.substring(8, 16)
, ce = cb.substring(16, 24)
, cf = cb.substring(24, 32)
, cg = cc + 1 + cd + 1 + ce + 1 + cf;
return {
"s": MD5(c8 + cg),
"f": cg
};
}
function getFirstParams() {
return getParams("fc276cce08ba22dc")
}
function getSecondParams(img) {
return getParams(MD5(img))
}
console.log(getFirstParams())
console.log(getSecondParams("data:image/png;base64,dqyixSOIJuJN0IRG288itylhqNFFXVqL"))
然后这个 cookie 值,你可以去 Hook 一下看看,但实际上观察一下就可以发现 c0fc276cce08ba22dc 就是第一次 s.webp 请求的 s 参数,c1fc276cce08ba22dc 和 bxf 就是第一次 s.webp 请求的 f 参数,所以直接拿来用就行了。
获取验证码
带上前面生成的正确的 cookie,再次请求主页,响应码为 200,然后在返回的 html 里可以看到有个超长的 js 地址,这个 js 直接把 .js 替换成 .jpg 就是验证码地址,替换成 .valid 就是验证结果的地址,这个 js 返回的内容里面就包含了要点击的数字。



获取点击坐标
最终提交的坐标是长这样的:
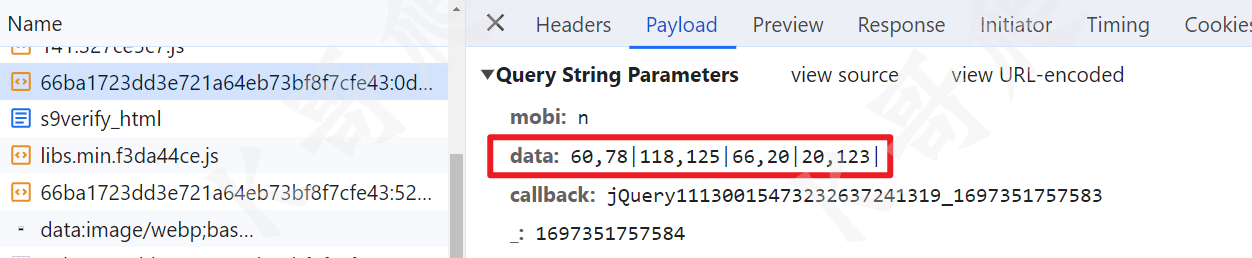
由于这个图片是九宫格的样式,一般的识别都是一排,所以这里可以将九宫格裁剪后重新排列一下(当然自己会搞深度学习的话可以单独给这种九宫格训练一下,就不用重新裁剪排列了),重新排列前后对比如下:

这一步的利用 Python 的 PIL 库很容易实现:
from PIL import Image
# 打开九宫格验证码
captcha = Image.open("captcha.jpg")
# 将图片等分成三份,每份长宽为 150px 和 50px
part1 = captcha.crop((0, 0, 150, 50))
part2 = captcha.crop((0, 50, 150, 100))
part3 = captcha.crop((0, 100, 150, 150))
part1.save("part1.jpg")
part2.save("part2.jpg")
part3.save("part3.jpg")
# 创建新的图片,长宽为 450px 和 50px
new_captcha = Image.new("RGB", (450, 50))
# 将三份图片按顺序拼接到新的图片上
new_captcha.paste(part1, (0, 0))
new_captcha.paste(part2, (150, 0))
new_captcha.paste(part3, (300, 0))
# 保存新的图片
new_captcha.save("captcha_new.jpg")
这样处理后,怎样得到对应的坐标呢?以上图为例,假设我们需要点击 question = [1, 8, 3, 6],我们识别 captcha_new.jpg 结果为 recognition_result = "172958643",生成最后的坐标流程如下:
import random
question = [1, 8, 3, 6] # 要点击的数字
recognition_result = "172958643" # captcha_new.jpg 识别的结果
mapping_table = {
"0": f"{str(random.randint(15, 35))},{str(random.randint(15, 35))}|",
"1": f"{str(random.randint(65, 85))},{str(random.randint(15, 35))}|",
"2": f"{str(random.randint(115, 135))},{str(random.randint(15, 35))}|",
"3": f"{str(random.randint(15, 35))},{str(random.randint(65, 85))}|",
"4": f"{str(random.randint(65, 85))},{str(random.randint(65, 85))}|",
"5": f"{str(random.randint(115, 135))},{str(random.randint(65, 85))}|",
"6": f"{str(random.randint(15, 35))},{str(random.randint(115, 135))}|",
"7": f"{str(random.randint(65, 85))},{str(random.randint(115, 135))}|",
"8": f"{str(random.randint(115, 135))},{str(random.randint(115, 135))}|",
}
answer = ""
for q in question:
for r in recognition_result:
if q == int(r):
answer += mapping_table[str(recognition_result.index(r))]
print(answer)
每一个数字的图片大小是 50x50,如果我要点击上图中的数字 1,那么我的 x、y 坐标范围就应该为 [0~50, 0~50],如果我要点击上图中的数字 8,那么我的 x、y 坐标范围就应该为 [100~150, 50~100]。
但是进过多次测试,点击区域要靠正中心一点,成功率才高,所以坐标范围前后各增加、减少了 15。对应数字 1 的坐标范围就应该是 [15~35, 15~35],数字 8 的坐标范围就应该是 [115~135, 65~85]。
这里为了简便,直接定义了一个映射表 mapping_table,如果我点击数字 8,那么 captcha_new.jpg 识别结果 172958643 中,8 的位置是 5,对应 mapping_table["5"],也就是 random.randint(115, 135), str(random.randint(65, 85)。
结果验证