| 34.文献阅读笔记 | ||
| 简介 | 题目 | Understanding image representations by measuring their equivariance and equivalence |
| 作者 | Karel Lenc, Andrea Vedaldi, CVPR, 2015. | |
| 原文链接 | http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Lenc_Understanding_Image_Representations_2015_CVPR_paper.pdf | |
| 关键词 | equivariance, invariance, and equivalence. | |
| 研究问题 | 尽管梯度直方图和深度卷积神经网络在图像表达上非常重要,但是我们对它们的理论了解仍然很受限。 a good representation should combine invariance and discriminability。 一个好的表达应该结合不变形和判别性。但这种定性是相当模糊的;例如,通常不清楚一个表示中包含哪些不变性以及它们是如何获得的。 提出了一种新的方法来研究图像表示。 | |
| 研究方法 | investigate three key mathematical properties of representations: equivariance, invariance, and equivalence. 研究三个数学属性:等变性、不变性和等价性。 等变性研究输入图像的变换是如何被表示编码的,不变性是变换没有影响的一种特殊情况。 等价性研究两个表示,例如CNN的两个不同参数化,是否捕获相同的视觉信息。 经验性的建立这些方法通过introducing transformation(转换) and stitching(拼接)(允许交换不同网络部分的拼接层)(验证等价性) layers in CNNs | |
| 研究结论 | 浅层表示和最先进的深度CNNs的前几层以一种容易预测的方式与图像变形进行转换,并且它们在不同的体系结构中可以互换,因此是等效的。更深层的层共享这些特性的一部分,但程度较低,更具有任务特异性。 | |
| 创新不足 | ||
| 额外知识 | geometric invariances:几何不变性。 Image representations:textons , histogram of oriented gradients (SIFT and HOG , bag of visual words , sparse and local coding, super vector coding, VLAD, Fisher Vectors, and the latest generation of deep convolutional networks. | |
| 35.文献阅读笔记 | ||
| 简介 | 题目 | Deep Neural Networks are Easily Fooled:High Confidence Predictions for Unrecognizable Images |
| 作者 | Anh Nguyen, Jason Yosinski, Jeff Clune, CVPR, 2015. | |
| 原文链接 | http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Nguyen_Deep_Neural_Networks_2015_CVPR_paper.pdf Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images-CSDN博客 | |
| 关键词 | DNN安全性、“fooling images” | |
| 研究问题 | 人类视觉和当前DNN之间的有趣差异,并提出了关于DNN计算机视觉通用性的问题。 | |
| 研究方法 | 生成一张人类无法分辨的图片,却能够让DNN以99%的置信度相信这是某个物体 。我们使用进化算法或者梯度上升来得到这样的图片。 multi-dimensional archive of phenotypic elites MAP-Elites ,这个算法可以让我们同时的进化出一个群体,如:ImageNet的1000个类。 多种不同的方法生成图片,称为“fooling images”: 1.普通的EA算法,对图片的某个像素进行变异、进化 2.CPPN EA算法,可以为图像提供一些几何特性,如对称等 3.梯度上升 | |
| 研究结论 | 会将人类无法识别的图案以非常高的置信度归为某个label。当经过重新训练的DNNs学会将负面例子分类为fool image时,即使经过多次再训练迭代,也可以产生一批新的fool image来愚弄这些新网络。 过拟合程度更低,更难去欺骗. 数据集的类别越多,越难被攻击 | |
| 创新不足 | ||
| 额外知识 | 在MNIST数据集上,由于数据量小,得到的网络模型的容量小,更容易生成fooling images,也跟难通过利用fooling images重新训练模型的方式来提高其防御能力 在ImageNet数据集上,数据量大,类别多,得到的网络模型的容量大,更难生成fooling images,不过由于其容量大,能够通过重新训练的方式提高防御能力 | |
| 36.文献阅读笔记 | ||
| 简介 | 题目 | Understanding Deep Image Representations by Inverting Them (反演) |
| 作者 | Aravindh Mahendran, Andrea Vedaldi, CVPR, 2015 | |
| 原文链接 | http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Mahendran_Understanding_Deep_Image_2015_CVPR_paper.pdf | |
| 关键词 | Understanding of Image Representations、Inverting | |
| 研究问题 | 给定一幅图像的编码,在多大程度上有可能重建图像本身? | |
| 研究方法 | 贡献了一个通用的框架来反演表示。 Hog、sift代表浅层表示法。 CNN表示深层表示法。 展示了如何将 HOG 和 DSIFT 作为 CNN 来实现,从而简化其导数的计算。 将反演技术分别应用于浅层表示(HOG 和 DSIFT)和深层表示(CNN)的分析。 反转只使用最终图像代码,即研究的是网络输出保留了哪些信息。 使用自然图像先验。 损失函数:欧氏距离 | |
| 研究结论 | CNN中的几个层保留了图像的精确信息,具有不同程度的几何和光度不变性。
基于梯度下降优化目标函数的反演浅层和深层表示的优化方法。与替代方案相比,一个关键的区别是使用图像先验,如Vβ范数,可以恢复由表示去除的低级图像统计。应用于卷积神经网络,可视化显示了每一层所代表的信息。特别是,很明显,在网络中形成了一个渐进的、更具有不变性和抽象性的图像内容的概念。 | |
| 创新不足 | 方法只使用图像表示和通用自然图像先验的信息,以随机噪声作为初始解,因此只捕捉到表示本身所包含的信息。 | |
| 额外知识 | 图像表示:sift->bag of visual words->cnns | |

| 37.文献阅读笔记 | ||
| 简介 | 题目 | Object Detectors Emerge in Deep Scene CNNs |
| 作者 | Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba, ICLR, 2015. | |
| 原文链接 | http://arxiv.org/abs/1412.6856 | |
| 关键词 | 理解CNN | |
| 研究问题 | 理解这些深层架构的内层所学习到的表象。 手工特征的表征结构往往是清晰的、可解释的,而对于深度网络来说,学习到的表征的性质是什么以及它为什么能如此出色地工作,仍然不清楚。 学习场景分类(即将图像分类为办公室、餐厅、街道等),为研究 CNN 在物体识别以外的任务中学到的内部表示提供了机会。 场景类别由其包含的物体定义,并在一定程度上由这些物体的空间配置定义。物体代表了场景的分布式代码(即不同场景类别之间共享物体类)。重要的是,在场景中,物体的空间配置虽然紧凑,但自由度要大得多。正是这种松散的空间依赖性,使得场景表示不同于大多数对象类(大多数对象类各部分之间没有松散的交互)。 | |
| 研究方法 | 展示了目标检测器是通过训练CNN来进行场景分类的。由于场景是由物体组成的,用于场景分类的CNN自动发现有意义的物体检测器,代表学习到的场景类别。随着物体检测器作为学习识别场景的结果而出现。 只使用场景,不使用对象级的监督。 进行了一个简单的实验,以确定每个网络不同层所偏好的图像类型的差异:创建了一组 20 万张图像,其中以场景为中心的图像和以物体为中心的图像分布大致相同,并将它们同时运行于两个网络,记录每一层的激活情况。对于每一层,我们将获得平均激活度(特定层所有空间位置的总和)最大的前 100 张图像。图 1 显示了每一层的前 3 幅图像。我们观察到,对于两个网络来说,pool1和pool2等较早的层更偏好类似的图像,而较晚的层则倾向于更专注于场景或物体分类的特定任务。  给定一幅被网络正确分类的图像,我们希望简化这幅图像,使其保留尽可能少的视觉信息,同时对同一类别仍有较高的分类得分。简化后的图像(命名为最小图像表示)将使我们能够突出导致高分类得分的元素。为此,我们在梯度空间中处理图像。 研究了以下两种不同的方法。 在第一种方法中,我们给定一幅图像,创建边缘和区域的分割,然后从图像中迭代移除分割。每次迭代时,我们都会移除正确分类分数下降最小的片段,直到图像被错误分类为止。最后,我们会得到原始图像的表示形式,该表示形式大约包含了网络正确识别场景类别所需的最小信息量。图 2 展示了这些最小图像表征的一些示例。  物体似乎为网络识别场景贡献了重要信息。例如,在卧室的情况下,这些最小图像表征通常包含床的区域,或者在美术馆类别中,包含墙上画作的区域。 第二种方法:我们使用 SUN Database (Xiao et al., 2014)的全注释图像集生成最小图像表征(有关该数据集的详细信息),而不是进行自动分割。我们采用与第一种方法相同的程序,使用数据库中提供的ground-truth object segments。 对于卧室,在87 %的情况下,最小表示保留了床。卧室的其他物品为墙壁( 28 % )和窗户( 21 % )。对于美术馆来说,最小的图像表征包括绘画( 81 % )和图片( 58 % );在游乐园中,旋转木马( 75 % ),骑马( 64 % ),过山车( 50 % );书店以书柜( 96 % )、书( 68 % )、书架( 67 % )为主。这些结果表明,目标检测是网络构建的表示的重要组成部分,以获得用于场景分类的判别信息。 数据驱动的方法来估计每一层中每个单元的感受野(RF)。 作为输入,我们使用由 200k 张图像组成的图像集,其中场景和物体的分布大致相同(与第 2 章类似)。然后,我们选出给定单元激活度最高的 K 幅图像。对于 K 幅图像中的每一幅图像,我们现在要确定的是图像中哪些区域会导致高单元激活。为此,我们对每幅图像进行多次复制,并在图像的不同位置添加小的随机遮挡物(大小为 11×11 的图像斑块)。具体来说,我们以 3 为步长的密集网格生成遮挡物,这样每张原始图像就会有大约 5000 个遮挡图像。现在,我们将所有被遮挡的图像输入同一个网络,并记录与使用原始图像相比激活度的变化。如果差异很大,我们就知道给定的补丁(patch)很重要,反之亦然。这样,我们就能为每张图像建立差异图。 随着层数的加深,RF 的大小逐渐增大,激活区域也变得更具语义意义。我们使用不同单元的特征图来分割图像。RF 的实际大小远远小于理论大小,尤其是在后面几层。总之,通过这种分析,我们可以精确地聚焦于每个图像的重要区域,从而更好地理解每个单元。 | |
| 研究结论 | 物体检测器是在学习对场景类别进行分类的过程中出现的,这表明单个网络可支持多个抽象层次(如边缘、纹理、物体和场景)的识别,而无需多个输出或网络。训练一个网络完成多项任务并将最后一层作为输出是很常见的做法,而在这里,我们展示了可以在每一层提取可靠的输出。由于物体是构成场景的部分,因此在网络的内层会学习到能区分不同场景的物体检测器。请注意,只有对特定场景识别任务有参考价值的物体才会出现。同一个网络可以在一次前向传递中完成物体定位和场景识别。 | |
| 创新不足 | ||
| 额外知识 | 与 ImageNet-CNN 的特征相比,Places-CNN 的深度特征在场景相关的识别任务中往往表现更好。 receptive fields (RFs):感受野 | |
| 38.文献阅读笔记 | ||
| 简介 | 题目 | Inverting Visual Representations with Convolutional Networks |
| 作者 | Alexey Dosovitskiy, Thomas Brox, arXiv, 2015. | |
| 原文链接 | http://arxiv.org/abs/1506.02753 | |
| 关键词 | 重建彩色图像。 | |
| 研究问题 | 提出了一种新方法来分析特征表示保留了哪些信息,丢弃了哪些信息。对模式识别任务有用的特征表示应集中于输入图像中对任务重要的属性,而忽略输入图像中无关的属性。 | |
| 研究方法 | 浅层特征。我们反转了三种传统的计算机视觉特征表示:定向梯度直方图(HOG)、尺度不变特征变换(SIFT)和局部二值模式(LBP)。我们选择这些特征是有原因的。目前已经有了反转 HOG 的方法,因此我们可以与现有的方法进行比较。LBP 的有趣之处在于它不可微,因此基于梯度的方法无法反转它。SIFT 是一种基于关键点的表示法,因此网络必须将不同的关键点拼接成一张平滑的图像。 在提取特征之前,我们将图像转换为灰度图像。 任务是重建彩色图像。特征不包含任何颜色信息,因此要预测颜色,网络就必须分析图像内容,并利用在训练过程中学到的自然图像先验信息。 很多时候,网络都能正确预测颜色,尤其是天空、大海、草地和树木。在其他情况下,网络无法预测颜色(例如图 3 最上面一行中的人),导致某些区域呈灰色。偶尔,网络也会预测出错误的颜色,如图 3 底行。 | |
| 研究结论 | 图像的颜色和粗略轮廓可以从更高网络层的激活中重建,甚至可以从预测的类概率中重建。 隐含地学习自然图像先验。 将我们的方法应用于 AlexNet 卷积网络学习到的表征,可以得出以下几个结论: 1)网络各层(包括最后的 FC8 层)的特征都保留了图像中物体的精确颜色和大致位置;2)在较高层中,输入图像的几乎所有信息都包含在非零激活模式中,而不是其精确值中;3)在 FC8 层中,输入图像的大部分信息都包含在那些不在网络预测前 5 位的类别的小概率中。 | |
| 创新不足 | ||
| 额外知识 | "层的输出 ":指的是该层最后一个处理步骤的输出。例如,第一个卷积层 CONV1 的输出是经过 ReLU、池化和归一化后的结果。 | |
| 39.文献阅读笔记 | ||
| 简介 | 题目 | Visualizing and Understanding Convolutional Networks |
| 作者 | Matthrew Zeiler, Rob Fergus, ECCV, 2014. | |
| 原文链接 | https://www.cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf | |
| 关键词 | 特征可视化技术 | |
| 研究问题 | 深入了解中间特征层的功能和分类器的功能 | |
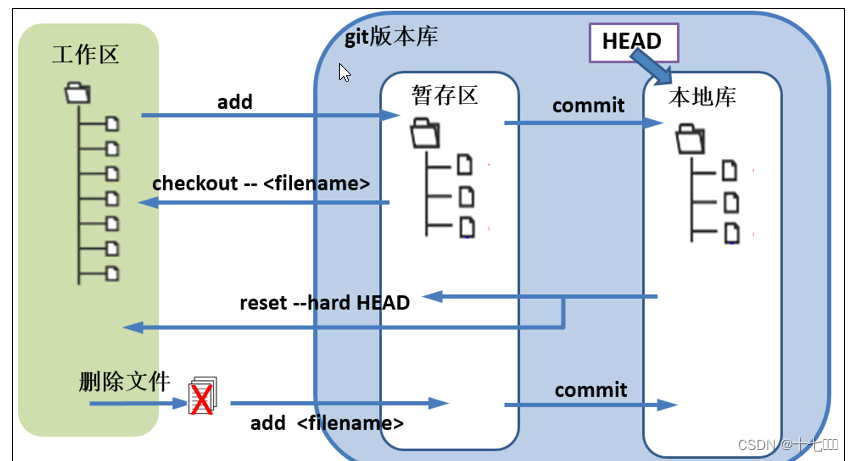
| 研究方法 | 介绍了一种新颖的可视化技术。 将特征激活投射回输入像素空间。还通过遮挡部分输入图像对分类器输出进行敏感性分析,揭示场景中哪些部分对分类很重要。 deconvnet layer:(反卷积层)
| |
| 研究结论 | 随着层数的增加,它们显示出许多直观可取的特性,如组成性、不断增加的不变性和类别区分度。该模型在进行分类训练的同时,对图像中的局部结构高度敏感,而不仅仅是利用广泛的场景背景。对模型的消融研究表明,网络的最小深度,而不是任何单独的部分,对模型的性能至关重要。 | |
| 创新不足 | ||
| 额外知识 | 消融研究:以发现不同模型层的性能贡献。 Ablation study(消融研究、消融学习、消融实验)_Accelerating的博客-CSDN博客 | |






![[sqlserver]在count(*)末尾增加单位(sql语句中的类型转换函数convert())](https://img-blog.csdnimg.cn/cf04f28e06a6466aa4559ea3850eeb3e.png)