大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用16-基于pytorch框架搭建的注意力机制,在汽车品牌与型号分类识别的应用,该项目主要引导大家使用pytorch深度学习框架,并熟悉注意力机制模型的搭建,这个项目提供了一个深度学习的舞台,让我们能够设计和训练一个卷积神经网络+注意力机制的模型。这个模型就像是一台强大的汽车引擎,能够从汽车图片中提取出独特的特征。
目录
- 引言
- 数据集介绍
- 理解卷积神经网络和注意力机制
- 搭建模型
- 数据预处理
- 模型训练
- 模型评估及结果可视化
- 总结
1. 引言
在当前的深度学习领域,图像分类任务已经成为了一个非常成熟的领域。本文将介绍如何使用卷积神经网络(CNN)和注意力机制来进行汽车品牌与型号的分类识别。我们将使用PyTorch这个强大的深度学习框架,以及StanfordCars数据集来实现这个任务。
这个项目主要通过CNN来提取汽车图像的特征,然后利用注意力机制来聚焦于图像中最具代表性的区域,从而提高分类的准确性。 在实施过程中,我们先收集并整理了包含不同汽车品牌和型号的图像数据集。接着,利用CNN对这些图像进行特征提取和学习,以便识别不同汽车品牌和型号的特征。为了进一步提高分类的准确性,引入了注意力机制,该机制有助于模型聚焦于图像中最重要的部分,从而更好地进行分类。
通过训练和优化模型,最终实现了对汽车品牌与型号的准确分类识别。该项目对于汽车行业的自动驾驶、智能交通等领域具有重要意义,可以帮助系统更准确地识别不同品牌和型号的汽车,为智能交通系统的发展提供支持。
2. 数据集介绍
StanfordCars数据集是一个大型的汽车图像数据集,该汽车数据集包含196类汽车的16185个图像。数据分为8,144个训练图像和8,041个测试图像,其中每个类别大致分为50-50个分割。这为我们提供了丰富的数据来训练和测试我们的模型。
3. 理解卷积神经网络和注意力机制
卷积神经网络(CNN)是一种专门处理具有网格结构的数据的神经网络。注意力机制则可以帮助模型在处理图像时,更加关注图像中的重要部分,从而提高模型的识别性能。

4. 搭建模型
我们将在PyTorch中搭建一个基于注意力机制的CNN模型。首先,我们需要导入必要的库。
import torch
from torch import nn
from torch.nn import functional as F
from torchvision import datasets, transforms
然后,我们搭建一个基于注意力机制的CNN模型。
class AttentionConvNet(nn.Module):
def __init__(self):
super(AttentionConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 32 * 32, 1024)
self.fc2 = nn.Linear(1024, 196)
self.attention = nn.Sequential(
nn.Linear(64 * 32 * 32, 32 * 32),
nn.Softmax(dim=1),
nn.Linear(32 * 32, 64 * 32 * 32),
)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = x.view(x.size(0), -1)
a = self.attention(x)
x = a * x
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
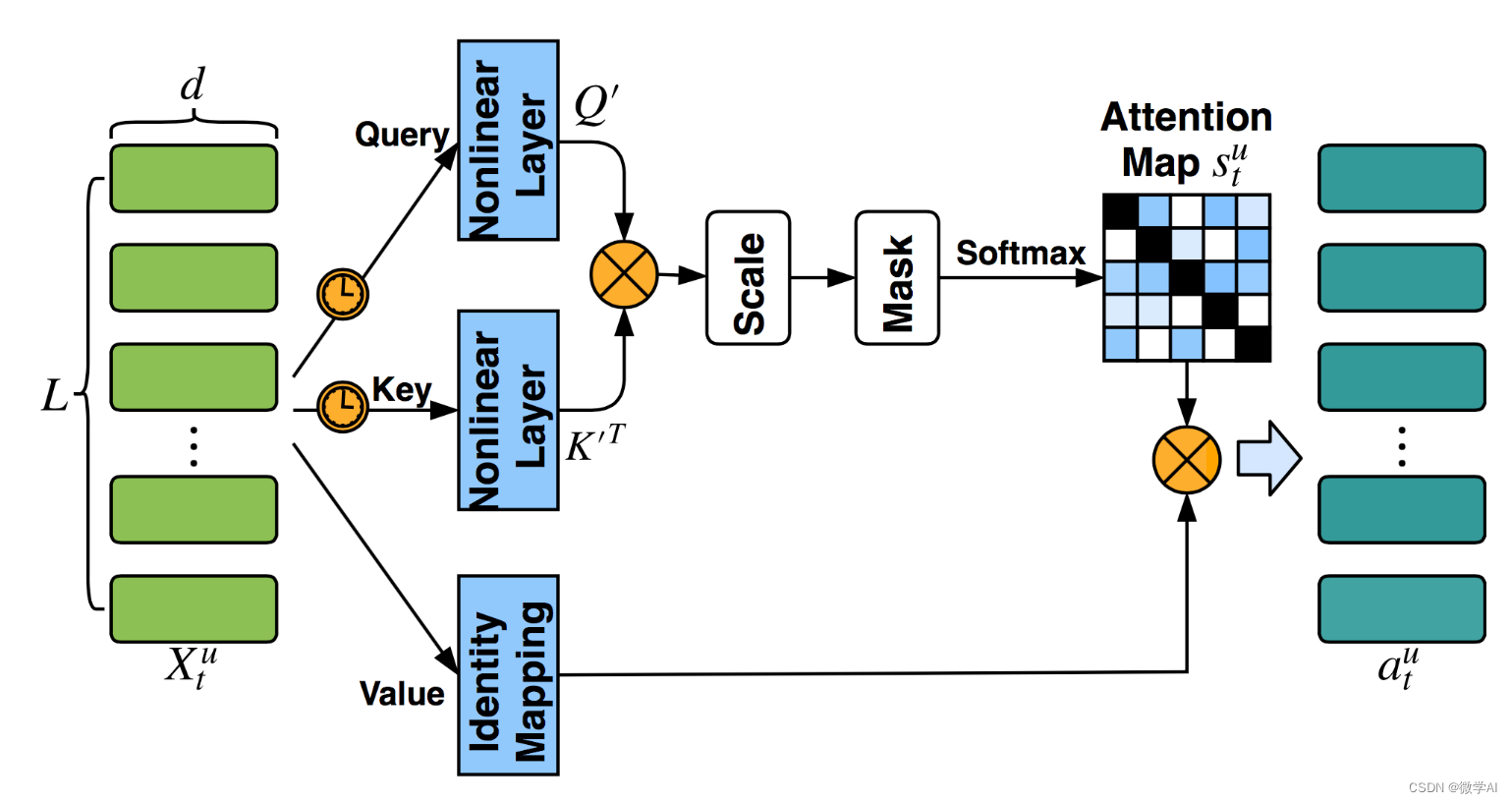
根据上述代码,并没有明确的Q、K、V矩阵。在传统的注意力机制中,通常会使用Q (查询), K (键) 和 V (值) 三个矩阵来计算注意力权重,然后将权重应用于值矩阵以获得最终的输出。
然而,这里的注意力机制被表示为一个简单的全连接神经网络模块 self.attention。它接收一个展平的特征向量 x 作为输入,并生成一个具有相同形状的权重向量 a。然后,该权重向量与特征向量相乘 x = a * x,以产生加权的特征向量。
因此,这个网络中的注意力机制与传统的 Q、K、V 矩阵表示方式略有不同。如果大家想要使用明确的 Q、K、V 矩阵,你可能需要修改网络结构以适应这种表示方式。
5. 数据预处理
为了使我们的模型能够更好地学习,我们需要对数据进行预处理。在PyTorch中,我们可以使用transforms模块来进行这一步。
数据的下载地址:链接:https://pan.baidu.com/s/1ygeTU3XnAgOiYOsxJ4zj3w?pwd=5y28
提取码:5y28
我们下载后解压文件car_ims
transform = transforms.Compose(
[
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
data_path = 'car_ims'
train_data = datasets.ImageFolder(root=data_path, transform=transform)
6. 模型训练
接下来,我们就可以开始训练我们的模型了。首先,我们需要定义损失函数和优化器。
model = AttentionConvNet()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(10):
for inputs, labels in train_data:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
``## 7. 模型评估及结果可视化
在训练完成后,我们需要对模型进行评估来查看其性能。
```python
correct = 0
total = 0
with torch.no_grad():
for data in test_data:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the test images: %d %%' % (
100 * correct / total))
此外,我们可以使用混淆矩阵等工具来更直观的展示我们模型的分类效果。
8. 总结
本文详细介绍了如何使用PyTorch和注意力机制来进行汽车品牌和型号的分类。我们首先介绍了数据集,然后详细讲解了如何构建模型,接着对数据进行了预处理,并进行了模型训练,最后对模型进行了评估。
希望通过本文的介绍,大家可以对如何使用深度学习技术进行图像分类有更深入的理解。同时,也希望大家可以在实际的项目中,尝试并改进这个模型,探索更多的可能性。
实际操作中可能需要进行一些调整以适应特定的环境和需求。例如,调整网络结构、优化器、学习率等参数以提高模型性能,或者增加数据增强技术以提高模型的泛化能力等。
最后,希望大家在深度学习的道路上越走越远,取得好成绩。



![[sqlserver]在count(*)末尾增加单位(sql语句中的类型转换函数convert())](https://img-blog.csdnimg.cn/cf04f28e06a6466aa4559ea3850eeb3e.png)