1. 引言
高性能架构设计在现代系统中至关重要,它能够应对大规模的数据和用户需求增长,提供优秀的用户体验和实时数据处理能力。同时,它也是解决"三高"问题(高并发、高性能、高可用性)的关键。
2. 高性能定义
高性能(High Performance)就是指程序处理速度快,所占内存少,cpu占用率低。
3. 性能指标和度量标准
3.1. 基础指标
| 指标 | 描述 | 计算公式 |
| 响应时间 (Response Time) | 系统对用户请求的响应速度,通常以毫秒 (ms) 为单位 | 响应时间 = 结束时间 - 开始时间 |
| 吞吐量 (Throughput) | 系统在单位时间内处理的请求数量或数据量,通常以每秒请求数 (RPS) 或每秒字节数 (BPS) 为单位 | 吞吐量 = 请求完成的请求数 / 时间间隔 |
| 并发用户数 (Concurrent Users) | 同时连接或使用系统的用户数量 | 无具体公式,根据系统的并发连接数或同时活跃用户数进行统计分析 |
| CPU利用率 (CPU Utilization) | CPU在某个时间段内的使用率 | CPU利用率 = (CPU使用时间 / 总时间) * 100% |
| 内存利用率 (Memory Utilization) | 系统内存在某个时间段内的使用率 | 内存利用率 = (已使用内存 / 总内存) * 100% |
| 网络延迟 (Network Latency) | 网络通信的延迟时间,即数据从发送端到接收端的传输时间 | 网络延迟 = 结束时间 - 开始时间 |
| 错误率 (Error Rate) | 在一定时间内发生的错误或异常的数量,通常以百分比或每秒错误数来计算 | 错误率 = (错误数 / 总请求数) * 100% |
| 系统可用性 (System Availability) | 系统在一定时间内可用的时间比例,通常以百分比来表示 | 可用性 = (系统正常运行时间 / 总时间) * 100% |
3.2. 高性能指标(常用)
| 指标 | 请求耗时 |
| TP50 | 50ms |
| TP75 | 75ms |
| TP90 | 90ms |
| TP99(百分之99的请求) | 100ms |
-
TP50: 即中位数值。100个请求按照响应时间从小到大排列,位置为50的值,即为P50值
-
TP95:响应耗时从小到大排列,顺序处于95%位置的值即为P95值
通常,设定性能目标时会兼顾吞吐量和响应时间,比如这样表述:在每秒1万次请求下,AVG RT控制在50ms以下,TP99控制在100ms以下。对于高并发系统,AVG RT和TP99必须同时要考虑。
另外,从用户体验角度来看,200毫秒被认为是第一个分界点,用户感觉不到延迟,1秒是第二个分界点,用户能感受到延迟,但是可以接受。
这些性能指标和度量标准的计算公式可以根据具体的需求和场景进行调整和定制。通过计算和分析这些指标,可以了解系统的性能状况、发现潜在的瓶颈和问题,并采取相应的措施,以提升系统的性能和用户体验。
4. 常见解决策略
一个全局角度来看高性能的系统设计,需要整体考虑的包括如下几个层面
-
程序实现层面:代码逻辑的分层、分模块、协程、资源复用(对象池,线程池等)、异步、IO 多路复用(异步非阻塞)、并发、无锁设计、设计模式等。
-
单机架构设计层面:IO 多路复用、Reactor 和 Proactor 架构模式
-
系统架构设计层面:架构分层、业务分模块、集群(集中式、分布式)、缓存(多级缓存、本地缓存)、消息队列(异步、削峰)
-
基础建设层面:机房、机器、资源分配,CDN
-
运维部署层面: 容器化部署、弹性伸缩
-
性能测试优化层面:性能压测、性能分析、性能优化
5. 高性能常见技术介绍
本文会只选取其中的程序实现层面、系统架构设计层面以及基础建设层面相关的部分技术展开,关键的技术包括扩容、异步并发、池化、队列、多级缓存等
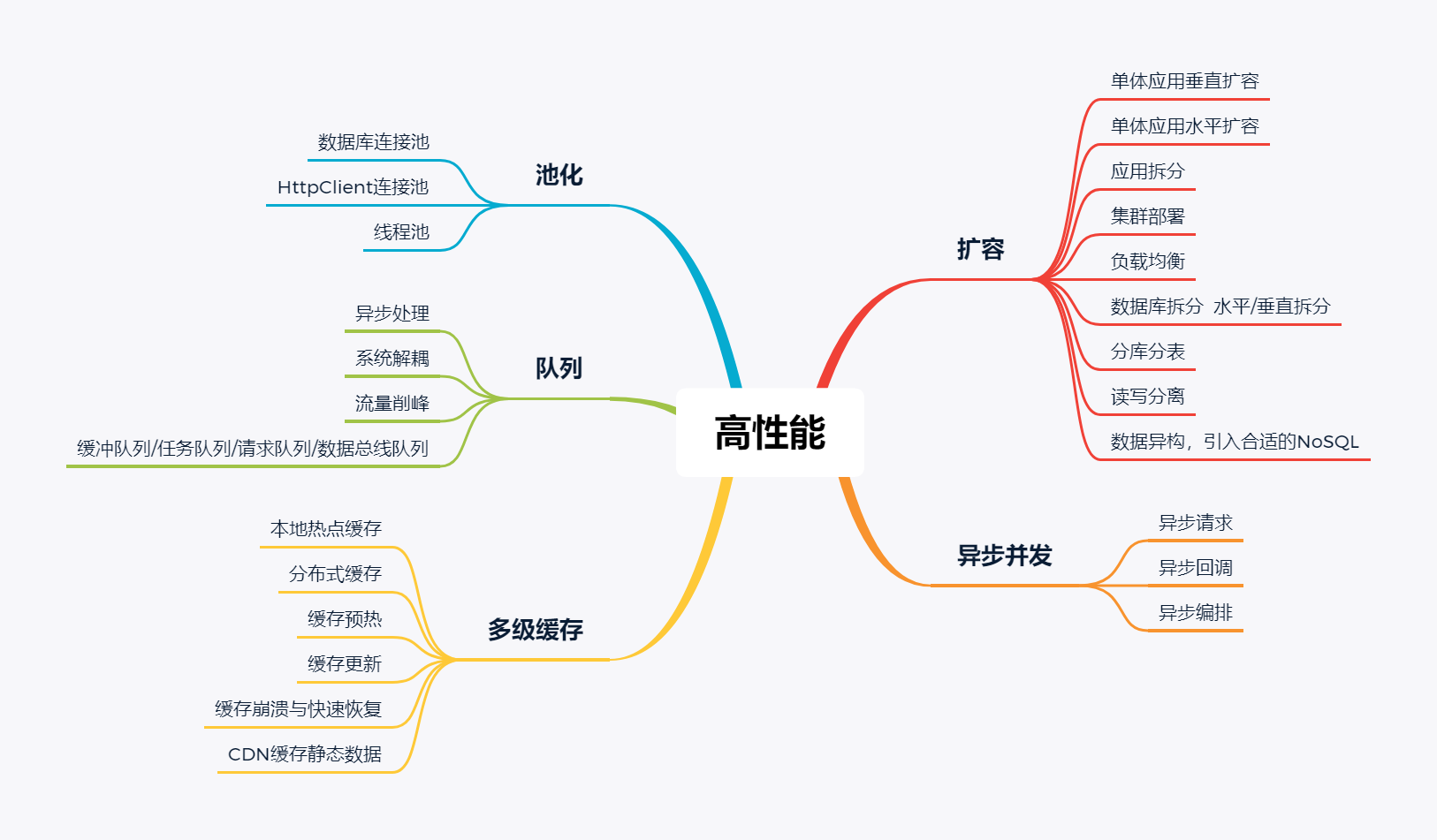
5.1. 池化
池化(Pooling)是一种常见的高性能架构设计技术,用于管理和复用资源,以提高系统的性能和效率。池化技术主要用于以下几个方面:
5.1.1. 连接池
连接池是一种管理数据库连接的技术,通过在应用程序和数据库之间建立连接池来复用数据库连接。连接池维护一定数量的数据库连接,并在需要时分配给应用程序使用,减少了创建和销毁连接的开销,提高了数据库访问的性能和效率。
5.1.2. 线程池
线程池是一种管理和复用线程资源的技术,通过预先创建一定数量的线程并放入池中,以避免频繁创建和销毁线程的开销。应用程序可以从线程池中获取线程来并发处理请求,提高系统的并发能力和响应速度。
5.1.3. 对象池
对象池是一种管理和复用对象资源的技术,通过预先创建一定数量的对象并放入池中,在需要时从池中获取对象并使用,使用完毕后将对象归还到池中。对象池可以用于复用各种资源密集型对象,如数据库连接、HTTP连接、线程安全对象等,提高系统的性能和效率。
5.1.4. 内存池
内存池是一种管理和复用内存资源的技术,通过预先分配一块连续的内存空间,并根据需要分配给应用程序使用。内存池可以减少频繁的内存分配和释放开销,提高内存的利用率和系统的性能。
池化技术的好处是可以减少资源的创建和销毁开销,提高资源的复用率和系统的性能。同时,池化技术还可以控制资源的数量和使用,避免资源过度消耗和系统崩溃。
需要注意的是,池化技术需要合理配置和管理,避免资源泄漏和资源争夺等问题。对于高性能系统设计,池化技术是一项重要的技术手段,可以提高系统的并发能力、响应速度和资源利用率。
5.2. 队列
队列是一种常见的高性能架构设计技术,用于实现异步通信和解耦系统组件,以提高系统的可伸缩性和容错性。队列技术主要用于以下几个方面:
5.2.1. 消息队列(Message Queue)
消息队列是一种基于发布/订阅模型的队列技术,用于在应用程序之间传递消息。它具有高度的可靠性和可扩展性,可以处理大量的消息,并提供消息持久化和消息重试机制。常见的消息队列实现包括RabbitMQ、Apache Kafka和ActiveMQ等。
5.2.2. 任务队列(Task Queue)
任务队列是一种用于处理异步任务的队列技术。它将任务放入队列中,然后由消费者按照一定的规则从队列中取出任务进行处理。任务队列可以实现任务的异步处理和分布式任务调度。常见的任务队列实现包括Celery和Apache Airflow等。
5.2.3. 事件队列(Event Queue)
事件队列是一种用于处理事件的队列技术。它可以用于实现事件驱动架构,通过将事件放入队列中,然后由消费者按照订阅的规则从队列中取出事件进行处理。事件队列可以实现解耦和松散耦合,使系统具有高度的可扩展性和灵活性。常见的事件队列实现包括Apache Kafka和Redis等。
5.2.4. 数据队列(Data Queue)
数据队列是一种用于在系统之间传输数据的队列技术。它可以用于解决生产者和消费者之间速度不匹配的问题,通过将数据放入队列中,然后由消费者按照自己的处理能力从队列中取出数据进行处理。数据队列可以实现解耦和提高系统的并发能力。常见的数据队列实现包括Apache Kafka和RabbitMQ等。
常见的队列技术包括消息队列(如RabbitMQ、Kafka、ActiveMQ)、任务队列(如Celery、Resque)、事件驱动队列(如Redis Pub/Sub)等。选择合适的队列技术需要根据系统的需求和技术栈进行权衡。
需要注意的是,在使用队列技术时,需要合理配置队列的容量和消费者的数量,避免队列过长或消费者过少导致系统的性能下降。同时,队列的持久化和消息的可靠性传输也是需要考虑的因素。
5.3. 多级缓存
在高性能架构设计中,多级缓存是一种常见的技术,用于提高系统的响应速度和降低后端资源的压力。多级缓存通过将数据存储在不同层次的缓存中,根据数据的访问频率和访问模式来实现数据的快速访问和高效存储。
多级缓存通常包括以下几个层次:
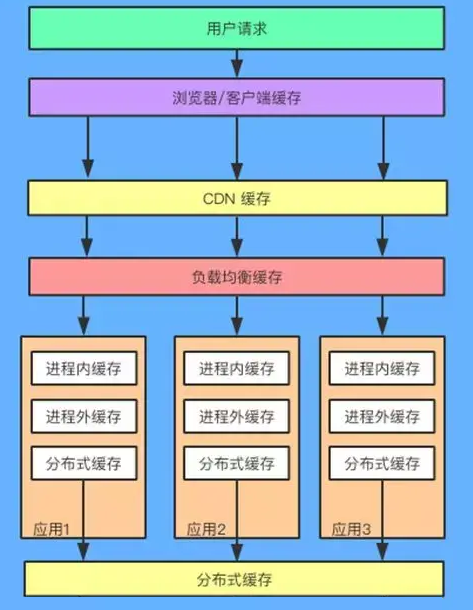
缓存的请求顺序是:用户请求 → HTTP 缓存 → CDN 缓存 → Nginx代理缓存 → 进程内缓存 → 分布式缓存。
5.4. 异步并发
通过异步可以降低时延,提升系统的整体性能,改善用户体验。
5.4.1. IO 层面的异步
针对 IO 层面的异步调用,就是我们常说的 I/O 模型,有阻塞、非阻塞和同步、异步这几种类型。
在 Linux 操作系统内核中,内置了 5 种不同的 IO 交互模式,分别是阻塞 IO、非阻塞 IO、多路复用 IO、信号驱动 IO、异步 IO。针对网络 IO 模型而言,Linux 下,使用最多性能较好的是同步非阻塞模型。
异步调用的常用技术
异步通信:NIO,Netty
5.4.2. 业务逻辑层面的异步
业务逻辑层面的异步流程,就是指让我们的应用程序在业务逻辑上可以异步的执行。
通常比较复杂的业务,都会有很多步骤流程,如果所有步骤都是同步的话,那么当这些步骤中有一步卡住,那么整个流程都会卡住,这样的流程显然性能不会很高。 场见异步包括
-
消息队列:异步解耦、流量削峰
-
异步编程:多线程,线程池
-
事件驱动:发布订阅模式(观察者模式)
-
作业驱动:定时任务,XXL-JOB
小结
一句话总结总结:虽然异步的执行效率高,但是复杂性和编程难度也高,所以切勿滥用。
5.5. 扩容
-
垂直扩容(Vertical Scaling):垂直扩容是通过增加单个节点的资源(例如CPU、内存)来提高系统性能。这可以通过升级硬件、增大虚拟机资源等方式来实现。垂直扩容的优点是简单、快速,但受限于单个节点的硬件容量。
-
水平扩容(Horizontal Scaling):水平扩容是通过增加系统的节点数量来提高系统性能。这可以通过增加服务器、容器或虚拟机来实现。水平扩容的优点是可以无限扩展,但需要考虑节点之间的通信和数据共享。
-
数据分片(Sharding):数据分片是一种将数据划分为多个片段并分布在不同节点上的技术。每个节点只负责处理部分数据,从而提高系统的并发性能和可伸缩性。数据分片需要考虑数据一致性、分片策略和分片管理等问题。
-
副本扩展(Replication):副本扩展是通过复制数据和服务来提高系统的可用性和性能。副本可以部署在不同的节点上,当一个节点发生故障时,其他节点可以接管服务。副本扩展需要考虑数据同步、一致性和负载均衡等问题。
-
弹性计算(Elastic Computing):弹性计算是一种根据系统负载的变化,自动调整节点数量和资源分配的技术。这可以通过自动扩容和缩容的方式来实现,从而根据需求动态调整系统的容量。
6. 结束语
高性能架构设计关注可扩展性、缓存优化、异步与事件驱动、数据库优化和高性能网络通信等核心技术。安全性与性能平衡、监控与调优也是关键因素。
随着新兴技术的发展,高性能架构设计将面临更多挑战和机遇。分布式计算、边缘计算、容器化和云原生架构等技术将成为重要方向。自动化运维、自愈式系统和智能优化将提高效率和可靠性。重视用户体验、数据安全和系统稳定性是关键。