1 模型并行化训练
1.1 为什么要并行训练
在训练大型数据集或者很大的模型时一块GPU很难放下,例如最初的AlexNet就是在两块GPU上计算的。并行计算一般采取两个策略:一个是模型并行,一个是数据并行。左图中是将模型的不同部分放在不同GPU上进行训练,最后汇总计算。而右图中是将数据放在不同GPU上进行训练,最后汇总计算,不仅能增大BatchSize,还能加快计算速度,提高计算精度
1.2 并行化训练策略
并行化深度学习模型有两种流行的方式:模型并行和数据并行
-
模型并行
模型并行性是指模型在逻辑上分为几个部分(即,一个部分中的某些层,而另一部分中的某些层),然后将其放置在不同的硬件/设备上。尽管将零件放在不同的设备上确实在执行时间(数据的异步处理)方面有很多好处,但通常可以采用它来避免内存限制。具有大量参数的模型由于这种类型的策略而受益,这些模型由于内存占用量大而难以放入单个系统中。
-
数据并行
另一方面,数据并行性是指通过位于不同硬件/设备上的同一网络的多个副本来处理多段数据(技术上为批次)。与模型并行性不同,每个副本可能是整个网络,而不仅仅是一部分。这种策略可以随着数据量的增加而很好地扩展。但是,由于整个网络必须驻留在单个设备上,因此无法帮助占用大量内存的模型。

1.3 单机多卡与多级多卡
在深度学习和其他高性能计算任务中,"单机多卡"(Single-Node Multi-GPU)和"多机多卡"(Multi-Node Multi-GPU)是两种常见的硬件配置,它们涉及使用多个图形处理单元(GPUs)来加速计算。单机多卡配置通常更容易管理和维护,而多机多卡配置提供了更高的计算能力和扩展性,但也带来了更高的复杂度和成本。
2.1.1 单机多卡 (Single-Node Multi-GPU)
-
定义:所有的 GPU 都安装在同一台机器上。
-
通信:GPU之间通过PCIe总线或者更高带宽的NVLink进行通信。
-
适用性:适合中等规模的数据集和模型,通常用于实验室环境或小规模的商业应用。
-
设置复杂度:相对简单,因为所有的通信都在一个节点内部进行。
-
扩展性:受限于单个节点能够支持的最大GPU数量。
-
示例场景:在一个数据中心的单个服务器上训练深度学习模型。
2.1.2 多机多卡 (Multi-Node Multi-GPU)
-
定义:GPU 分布在多台机器上,这些机器通过网络连接。
-
通信:机器之间的通信通过高速网络(例如InfiniBand)进行,但比单节点内部的通信要慢。
-
适用性:适合大规模数据集和模型,通常用于大型数据中心或复杂的机器学习任务。
-
设置复杂度:更复杂,需要管理节点间的网络通信和同步。
-
扩展性:理论上可以通过增加更多节点来无限扩展。
-
示例场景:在多个数据中心分布的服务器上训练大型深度学习模型,如训练大型语言模型或复杂的科学计算任务。
2 使用DistributedDataParallel实现模型并行化训练
2.1 基本概念
DistributedDataParallel中的关键概念


训练过程示意如下:
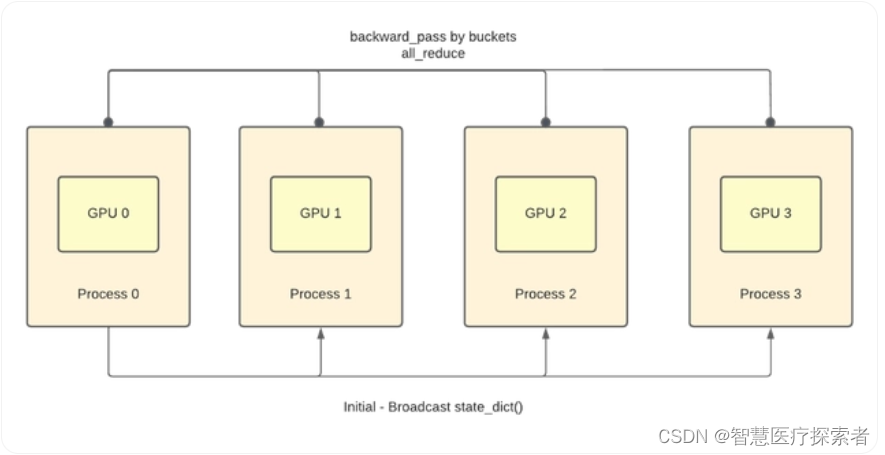
分布式训练的启动有两种方法,一种是torch.multiprocessing,还有一种是torch.distributed
- 第一种在启动程序时不需要在命令行输入额外的参数,写起来也比较容易,但是调试较麻烦,比如MAE;
- 第二种必须要用命令行启动,写起来略微复杂,但是调试较方便。
2.2 torch.distributed分布式训练步骤
2.2.1 导入分布式模块
其中distributed中必须导入的是以下模块
import torch.distributed as dist2.2.2 用argparse编写模型的个性化参数
parser = argparse.ArgumentParser()
''' ...your params '''
''' ...distributed params'''
# 开启的进程数,不用设置该参数,会根据nproc_per_node自动设置
parser.add_argument('--world-size', default=4, type=int, help='number of distributed processes')
parser.add_argument('--local_rank', type=int, help='rank of distributed processes')
opt = parser.parse_args()
注意这里如果使用了argparse方法的话,必须传入local_rank参数,系统会自动给他进行赋值,如果不传入会报错!
2.2.3 初始化distributed
初始化过程如下:假设我们的world_size=8,那么我们有8张GPU初始化,初始化有快有慢,快的GPU初始化会在dist.barrier()处停下来等待,当所有的GPU都到达这个函数时,才会继续运行之后的代码。
# 初始化各进程环境
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ['WORLD_SIZE'])
args.gpu = int(os.environ['LOCAL_RANK'])
else:
print('Not using distributed mode')
return
# 设置当前程序使用的GPU。根据python的机制,在单卡训练时本质上程序只使用一个CPU核心,而DataParallel
# 不管用了几张GPU,依然只用一个CPU核心,在分布式训练中,每一张卡分别对应一个CPU核心,即几个GPU几个CPU核心
torch.cuda.set_device(args.gpu)
# 分布式初始化
args.dist_url = 'env://' # 设置url
args.dist_backend = 'nccl' # 通信后端,nvidia GPU推荐使用NCCL
print('| distributed init (rank {}): {}'.format(args.rank, args.dist_url), flush=True)
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
dist.barrier() # 等待所有进程都初始化完毕,即所有GPU都要运行到这一步以后在继续
'''
| distributed init (rank 1): env://
| distributed init (rank 2): env://
| distributed init (rank 0): env://
| distributed init (rank 3): env://
''' torch.distributed.init_process_group 是PyTorch中的一个函数,它用于初始化默认的分布式进程组,从而允许进行跨多个进程的通信。这个函数在使用 PyTorch 的分布式功能时非常重要,特别是在使用 DistributedDataParallel (DDP) 进行多GPU或多节点训练时。真正意义上来讲,分布式的初始化就只有dist.init_process_group这一句。
从上面我们print的输出可以得到不同GPUs初始化的速度是不同的,这也正是因为每个GPU都分配了一个CPU核心,他们的速度有快有慢,比如本次实验初始化顺序为1,2,0,3
关于环境变量,有一下几点需要注意
- local_rank是被自动赋值的,在单机多卡中他和rank的值相同
- os.environ[“RANK”]是没有值的,运行时在命令行上输入python -m torch.distributed.launch --nproc_per_node=4 --use_env train.py他才被赋予了值
- –nproc_per_node=4这条指令可以将os.environ[“WORLD_SIZE”]赋值为4
- 如果用argparse这个库,就必须加上local_rank变量,如果忘记加了,在命令行启动时就需要加上–use_env参数,–use_env 表示 Local Rank 用 LOCAL_RANK 这个环境变量传参
2.2.4 设置数据集分布式的数据集加载
设置数据集分布式的数据集加载不同于之前的单卡,这里需要将数据集分为N部分,N为卡的数量。单卡时只需要设置Datasets→DataLoader即可,但是分布式中需要对每一块GPU分配不重复的数据,分配方式也不难,分配方式变为:Datasets→DistributedSampler→BatchSampler→DataLoader(BatchSampler可以省略)
DistributedSampler将数据集N等分,BatchSamper将每一等分后的数据内部进行batch的划分。BatchSampler的作用就是分配batchsize,这一步可以再DataLoader中分配,因此也可以将BatchSampler省略。下图展示了数据集的分配过程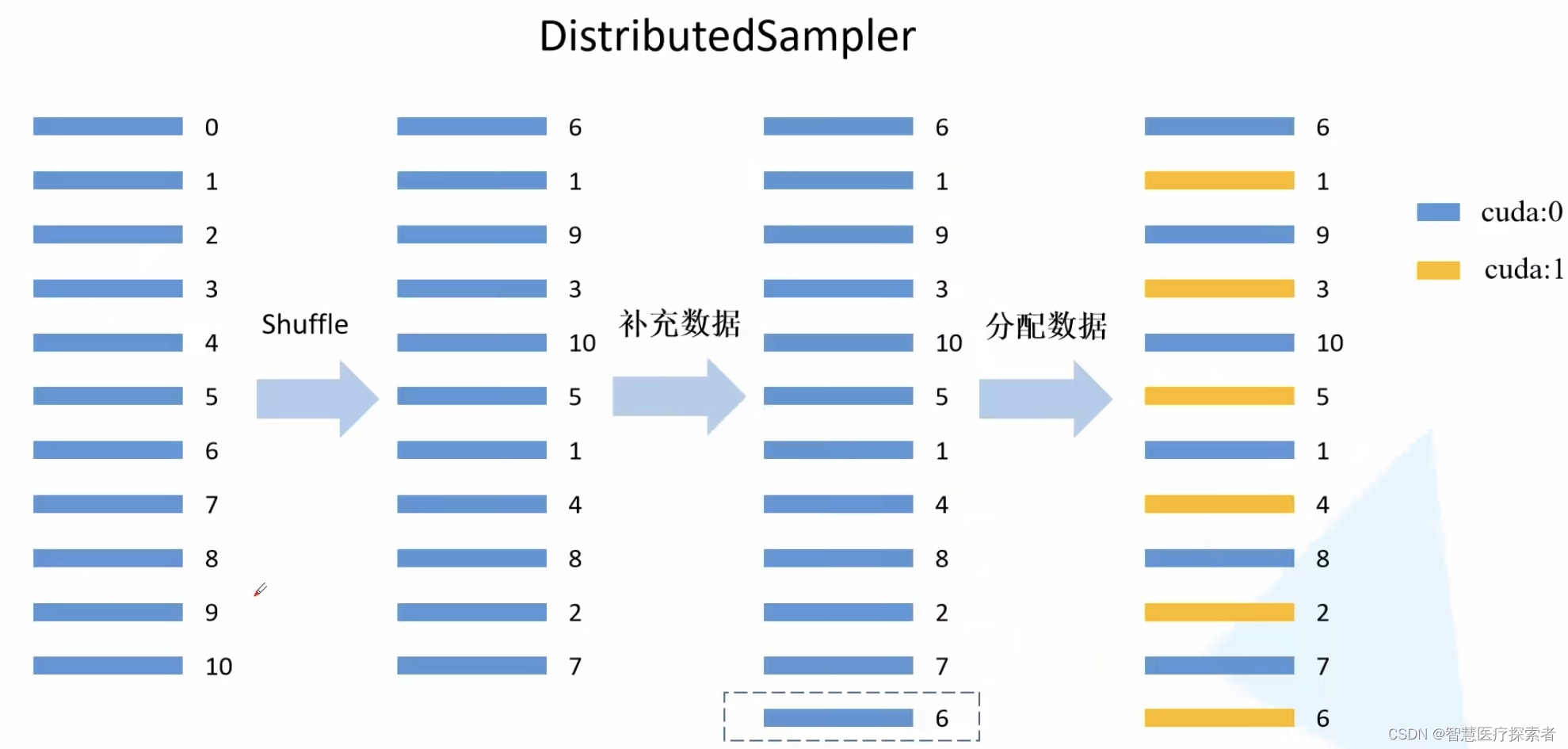
# 1. datasets
train_datasets = MyDataSet(xxx)
val_datasets = MyDataSet(xxx)
# 2. DistributedSampler
# 给每个rank对应的进程分配训练的样本索引,比如一共800样本8张卡,那么每张卡对应分配100个样本
train_sampler = torch.utils.data.distributed.DistributedSampler(train_datasets)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_datasets)
# 3. BatchSampler
# 刚才每张卡分了100个样本,假设BatchSize=16,那么能分成100/16=6...4,即多出4个样本
# 下面的drop_last=True表示舍弃这四个样本,False将剩余4个样本为一组(注意最后就不是6个一组了)
train_batch_sampler = torch.utils.data.BatchSampler(train_sampler, batch_size, drop_last=True)
# 4. DataLoader
# 验证集没有采用batchsampler,因此在dataloader中使用batch_size参数即可
train_dataloader = torch.utils.data.DataLoader(train_datasets,
batch_sampler=train_batch_sampler, pin_memory=True, num_workers=nw)
val_dataloader = torch.utils.data.DataLoader(val_datasets,
batch_size=batch_size, sampler=val_sampler, pin_memory=True, num_workers=nw)2.2.5 加载模型到所有GPUs上
在训练时,因为我们用到了DistributedSampler,所以需要每一个epoch都将原数据打乱一下,其他剩下的过程和单卡相同
model = UNet().cuda()
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[rank])
...
for epoch in range(start_epoch, n_epochs):
if is_distributed:
train_sampler.set_epoch(epoch)
...2.2.6 启动分布式训练
python -m torch.distributed.launch --nproc_per_node=4 --master_port=2424 --use_env main.py (your_argparse_params)在pytorch新版中将python -m torch.distributed.launch替换为了torchrun,在训练时我们需要指定通讯端口master_port,也可以让程序自动寻找,即将--master_port=xxxx替换为--rdzv_backend c10d --master_port=0
2.3 torch.multiprocessing分部署训练步骤
通过核心函数spawn函数调用GPU并行,函数的参数如下:
torch.multiprocessing.spawn(fn, args=(), nprocs=1, join=True, daemon=False, start_method='spawn')
- fn:这个就是我们要分布式运行的函数,一般来说是main函数,main(rank, *args),其中rank为必须,单机多卡中可以理解为第几个GPU,args为函数传入的参数,类型tuple,在spawn(…args)的args参数中定义
- args:传入fn的参数,tuple
- nprocs:进程数,即几张卡
- join: 默认为True即可
- daemon: 默认为False即可
# 调用
mp.spawn(main, args=(opt, ), nprocs=opt.world_size, join=True)与distributed大同小异,完整的训练代码如下:
# 单机多卡并行计算示例
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "6, 7"
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", init_method='tcp://127.0.0.1:6666', rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
print("finished rank: {}".format(rank))
def main():
world_size = torch.cuda.device_count()
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()2.4 dist.barrier()函数
单机多卡环境下使用分布式训练具有更快的速度。PyTorch在分布式训练过程中,对于数据的读取是采用主进程预读取并缓存,然后其它进程从缓存中读取,不同进程之间的数据同步具体通过torch.distributed.barrier()实现,示例如下:
if args.local_rank not in [-1, 0]:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
... (loads the model and the vocabulary)
if args.local_rank == 0:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab假设我们有4张卡[0, 1, 2, 3],其中[0]卡是first process或者base process,有些操作不需要所有的卡同时进行,比如在预处理的时候只用base process即可。
在上述代码中,第一个if是说除了主卡之外的卡运行到此处会被barrier,也就是说运行到这里就停止了,而base process不会停止,会继续运行,执行预加载模型等操作,当主卡运行到第二个if时,他也会进入到barrier,就是说他已经预加载完了,现在他也需要被barrier了。
此时所有的卡都进入到了barrier,意味着所有的卡可以继续运行(主卡已经加载完了,这个数据所有的卡都可以使用),此后,所有的卡从barrier撤出,开始执行训练。
a process is blocked by a barrier until all processes have encountered a barrier, upon which the barrier is lifted for all processes
3 一个完整的例子
3.1 初始化进程组
import os
from torch import distributed
try:
world_size = int(os.environ["WORLD_SIZE"]) # 全局进程个数
rank = int(os.environ["RANK"]) # 当前进程编号(全局)
local_rank = int(os.environ["LOCAL_RANK"]) # 每台机器上的进程编号(局部)
distributed.init_process_group("nccl") # 初始化进程, 使用nccl后端
except KeyError:
world_size = 1
rank = 0
local_rank = 0
distributed.init_process_group(
backend="nccl",
init_method="tcp://127.0.0.1:12584",
rank=rank,
world_size=world_size,
)3.2 使用DistributedSampler划分数据集
与nn.DataParrallel不同的是,分布式训练中的batch_size为单卡的输入样本数,因为它代表的是当前rank下对应的partition,总batch_size是这里的batch_size再乘以并行数。举个例子,假设使用8张卡训练模型,nn.DataParrallel中的batch_size为3200,nn.DistributedDataParallel中的batch_size则为400。
from dataloader.distributed_sampler import DistributedSampler
train_sampler = DistributedSampler(
train_set, num_replicas=world_size, rank=rank, shuffle=True, seed=seed)
trainloader = DataLoader(
dataset=train_set,
pin_memory=true,
batch_size=batch_size,
num_workers=num_workers,
sampler=train_sampler
) # pin_memory: 是否提前申请CUDA内存. 创建DataLoader时,设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些.3.3 使用DistributedDataParallel封装模型
DistributedDataParallel能够为不同GPU上求得的梯度进行all reduce(即汇总不同GPU计算所得的梯度,并同步计算结果)。all reduce后不同GPU中模型的梯度均为all reduce之前各GPU梯度的均值。
backbone = get_model(
cfg.network, dropout=0.0, fp16=cfg.fp16, num_features=cfg.embedding_size).cuda()
backbone = torch.nn.parallel.DistributedDataParallel(
module=backbone, broadcast_buffers=False, device_ids=[local_rank], bucket_cap_mb=16,
find_unused_parameters=True)3.4 训练模型
把输入图片、标签及模型加载到当前进程使用的GPU中,
for epoch in range(start_epoch, cfg.num_epoch):
if isinstance(train_loader, DataLoader):
# 设置train_loader中的sampler的epoch,DistributedSampler需要这个参数来维持各个进程之间的相同随机数种子
train_loader.sampler.set_epoch(epoch)
for _, (img, local_labels) in enumerate(train_loader):
global_step += 1
local_embeddings = backbone(img)
loss: torch.Tensor = module_partial_fc(local_embeddings, local_labels, opt)
loss.backward()
torch.nn.utils.clip_grad_norm_(backbone.parameters(), 5)
opt.step()
opt.zero_grad()
lr_scheduler.step()3.5 计算损失
distributed.all_gather(tensor_list,input_tensor):从所有设备收集指定的input_tensor并将其放置在所有设备上的tensor_list变量中,
from torch import distributed
distributed.all_gather(_gather_embeddings, local_embeddings)
distributed.all_gather(_gather_labels, local_labels)
distributed.all_reduce(loss, distributed.ReduceOp.SUM)3.6 保存模型
if rank == 0:
path_module = os.path.join(cfg.output, "model_final.pt")
torch.save(backbone.module.state_dict(), path_module)3.7 启动并行程序
(1) 使用torch.distributed.launch
该指令会使脚本并行地运行n次(n为使用的GPU个数),
python -m torch.distributed.launch --nproc_per_node=8 train.py configs/ms1mv3_r50(2) 使用torch.multiprocessing
torch.multiprocessing会自动创建进程,绕开torch.distributed.launch开启和退出进程的一些小毛病,
def main(rank):
pass
torch.multiprocessing.spawn(main, nprocs, args)3.8 完整代码
import argparse
import logging
import os
from datetime import datetime
import numpy as np
import torch
from backbones import get_model
from dataset import get_dataloader
from losses import CombinedMarginLoss
from lr_scheduler import PolyScheduler
from partial_fc import PartialFC, PartialFCAdamW
from torch import distributed
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from utils.utils_callbacks import CallBackLogging, CallBackVerification
from utils.utils_config import get_config
from utils.utils_distributed_sampler import setup_seed
from utils.utils_logging import AverageMeter, init_logging
assert torch.__version__ >= "1.12.0", "In order to enjoy the features of the new torch, \
we have upgraded the torch to 1.12.0. torch before than 1.12.0 may not work in the future."
try:
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
world_size = int(os.environ["WORLD_SIZE"])
distributed.init_process_group("nccl")
except KeyError:
rank = 0
local_rank = 0
world_size = 1
distributed.init_process_group(
backend="nccl",
init_method="tcp://127.0.0.1:12584",
rank=rank,
world_size=world_size,
)
def main(args):
# get config
cfg = get_config(args.config)
# global control random seed
setup_seed(seed=cfg.seed, cuda_deterministic=False)
torch.cuda.set_device(local_rank)
os.makedirs(cfg.output, exist_ok=True)
init_logging(rank, cfg.output)
summary_writer = (
SummaryWriter(log_dir=os.path.join(cfg.output, "tensorboard"))
if rank == 0
else None
)
wandb_logger = None
if cfg.using_wandb:
import wandb
# Sign in to wandb
try:
wandb.login(key=cfg.wandb_key)
except Exception as e:
print("WandB Key must be provided in config file (base.py).")
print(f"Config Error: {e}")
# Initialize wandb
run_name = datetime.now().strftime("%y%m%d_%H%M") + f"_GPU{rank}"
run_name = run_name if cfg.suffix_run_name is None else run_name + f"_{cfg.suffix_run_name}"
try:
wandb_logger = wandb.init(
entity = cfg.wandb_entity,
project = cfg.wandb_project,
sync_tensorboard = True,
resume=cfg.wandb_resume,
name = run_name,
notes = cfg.notes) if rank == 0 or cfg.wandb_log_all else None
if wandb_logger:
wandb_logger.config.update(cfg)
except Exception as e:
print("WandB Data (Entity and Project name) must be provided in config file (base.py).")
print(f"Config Error: {e}")
train_loader = get_dataloader(
cfg.rec,
local_rank,
cfg.batch_size,
cfg.dali,
cfg.seed,
cfg.num_workers
)
backbone = get_model(
cfg.network, dropout=0.0, fp16=cfg.fp16, num_features=cfg.embedding_size).cuda()
backbone = torch.nn.parallel.DistributedDataParallel(
module=backbone, broadcast_buffers=False, device_ids=[local_rank], bucket_cap_mb=16,
find_unused_parameters=True)
backbone.train()
# FIXME using gradient checkpoint if there are some unused parameters will cause error
backbone._set_static_graph()
margin_loss = CombinedMarginLoss(
64,
cfg.margin_list[0],
cfg.margin_list[1],
cfg.margin_list[2],
cfg.interclass_filtering_threshold
)
if cfg.optimizer == "sgd":
module_partial_fc = PartialFC(
margin_loss, cfg.embedding_size, cfg.num_classes,
cfg.sample_rate, cfg.fp16)
module_partial_fc.train().cuda()
# TODO the params of partial fc must be last in the params list
opt = torch.optim.SGD(
params=[{"params": backbone.parameters()}, {"params": module_partial_fc.parameters()}],
lr=cfg.lr, momentum=0.9, weight_decay=cfg.weight_decay)
elif cfg.optimizer == "adamw":
module_partial_fc = PartialFCAdamW(
margin_loss, cfg.embedding_size, cfg.num_classes,
cfg.sample_rate, cfg.fp16)
module_partial_fc.train().cuda()
opt = torch.optim.AdamW(
params=[{"params": backbone.parameters()}, {"params": module_partial_fc.parameters()}],
lr=cfg.lr, weight_decay=cfg.weight_decay)
else:
raise
cfg.total_batch_size = cfg.batch_size * world_size
cfg.warmup_step = cfg.num_image // cfg.total_batch_size * cfg.warmup_epoch
cfg.total_step = cfg.num_image // cfg.total_batch_size * cfg.num_epoch
lr_scheduler = PolyScheduler(
optimizer=opt,
base_lr=cfg.lr,
max_steps=cfg.total_step,
warmup_steps=cfg.warmup_step,
last_epoch=-1
)
start_epoch = 0
global_step = 0
if cfg.resume:
dict_checkpoint = torch.load(os.path.join(cfg.output, f"checkpoint_gpu_{rank}.pt"))
start_epoch = dict_checkpoint["epoch"]
global_step = dict_checkpoint["global_step"]
backbone.module.load_state_dict(dict_checkpoint["state_dict_backbone"])
module_partial_fc.load_state_dict(dict_checkpoint["state_dict_softmax_fc"])
opt.load_state_dict(dict_checkpoint["state_optimizer"])
lr_scheduler.load_state_dict(dict_checkpoint["state_lr_scheduler"])
del dict_checkpoint
for key, value in cfg.items():
num_space = 25 - len(key)
logging.info(": " + key + " " * num_space + str(value))
callback_verification = CallBackVerification(
val_targets=cfg.val_targets, rec_prefix=cfg.rec,
summary_writer=summary_writer, wandb_logger = wandb_logger
)
callback_logging = CallBackLogging(
frequent=cfg.frequent,
total_step=cfg.total_step,
batch_size=cfg.batch_size,
start_step = global_step,
writer=summary_writer
)
loss_am = AverageMeter()
amp = torch.cuda.amp.grad_scaler.GradScaler(growth_interval=100)
for epoch in range(start_epoch, cfg.num_epoch):
if isinstance(train_loader, DataLoader):
train_loader.sampler.set_epoch(epoch)
for _, (img, local_labels) in enumerate(train_loader):
global_step += 1
local_embeddings = backbone(img)
loss: torch.Tensor = module_partial_fc(local_embeddings, local_labels, opt)
if cfg.fp16:
amp.scale(loss).backward()
amp.unscale_(opt)
torch.nn.utils.clip_grad_norm_(backbone.parameters(), 5)
amp.step(opt)
amp.update()
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(backbone.parameters(), 5)
opt.step()
opt.zero_grad()
lr_scheduler.step()
with torch.no_grad():
if wandb_logger:
wandb_logger.log({
'Loss/Step Loss': loss.item(),
'Loss/Train Loss': loss_am.avg,
'Process/Step': global_step,
'Process/Epoch': epoch
})
loss_am.update(loss.item(), 1)
callback_logging(global_step, loss_am, epoch, cfg.fp16, lr_scheduler.get_last_lr()[0], amp)
if global_step % cfg.verbose == 0 and global_step > 0:
callback_verification(global_step, backbone)
if cfg.save_all_states:
checkpoint = {
"epoch": epoch + 1,
"global_step": global_step,
"state_dict_backbone": backbone.module.state_dict(),
"state_dict_softmax_fc": module_partial_fc.state_dict(),
"state_optimizer": opt.state_dict(),
"state_lr_scheduler": lr_scheduler.state_dict()
}
torch.save(checkpoint, os.path.join(cfg.output, f"checkpoint_gpu_{rank}.pt"))
if rank == 0:
path_module = os.path.join(cfg.output, "model.pt")
torch.save(backbone.module.state_dict(), path_module)
if wandb_logger and cfg.save_artifacts:
artifact_name = f"{run_name}_E{epoch}"
model = wandb.Artifact(artifact_name, type='model')
model.add_file(path_module)
wandb_logger.log_artifact(model)
if cfg.dali:
train_loader.reset()
if rank == 0:
path_module = os.path.join(cfg.output, "model.pt")
torch.save(backbone.module.state_dict(), path_module)
from torch2onnx import convert_onnx
convert_onnx(backbone.module.cpu().eval(), path_module, os.path.join(cfg.output, "model.onnx"))
if wandb_logger and cfg.save_artifacts:
artifact_name = f"{run_name}_Final"
model = wandb.Artifact(artifact_name, type='model')
model.add_file(path_module)
wandb_logger.log_artifact(model)
distributed.destroy_process_group()
if __name__ == "__main__":
torch.backends.cudnn.benchmark = True
parser = argparse.ArgumentParser(
description="Distributed Arcface Training in Pytorch")
parser.add_argument("config", type=str, help="py config file")
main(parser.parse_args())4 分布式训练可能遇到的问题
4.1 runtimeerror: address already in use
这种情况是端口被占用了,可能是由于你上次调试之后端口依旧占用的缘故,假设88889端口被占用了,用以下命令查询其PID,然后杀掉即可。第二种方法是将当前终端关闭,重新开一个他会自动解除占用
4.2 调试时可能会出现的问题
- 显存未释放:nvidia-smi看一下显存是否释放,如果没有释放使用kill -9 PID命令进行释放。如果kill也无法释放显存,直接将terminal关闭重新开一个即可
- 端口被占用:如果第一次调试后进行第二次调试时提示xx端口被占用了,这里最快的解决方法时将当前terminal关闭,然后重新开一个即可,或者参考第一个问题,kill掉相应的PID