基于Paddle的肝脏CT影像分割系统的体系结构说明书
目录
HIPO图
H图
Ipo图
软件结构图
面向数据流的体系结构设计图
程序流程图
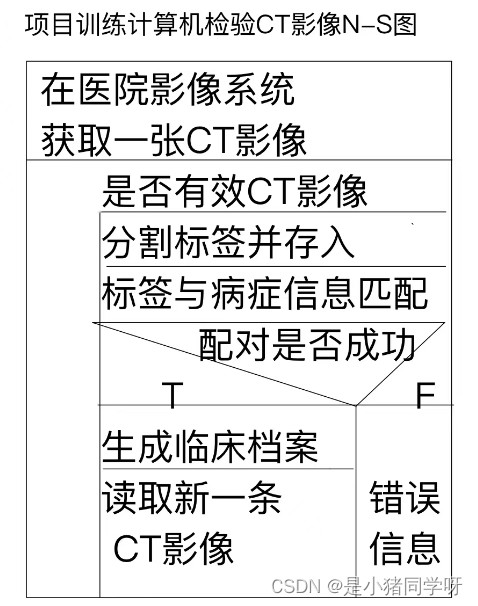
S图
用PDL语言描述的伪代码
HIPO图
H图

Ipo图

软件结构图

面向数据流的体系结构设计图

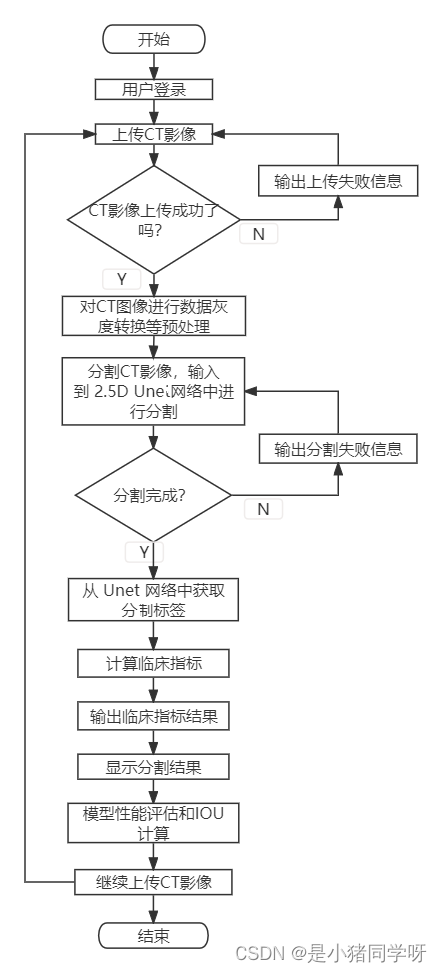
程序流程图
-
S图
PAD图

用PDL语言描述的伪代码
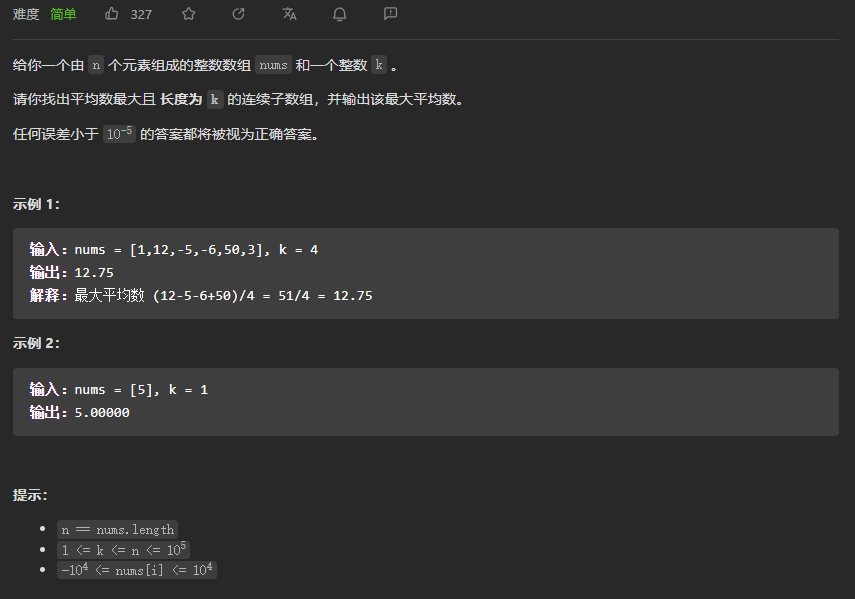
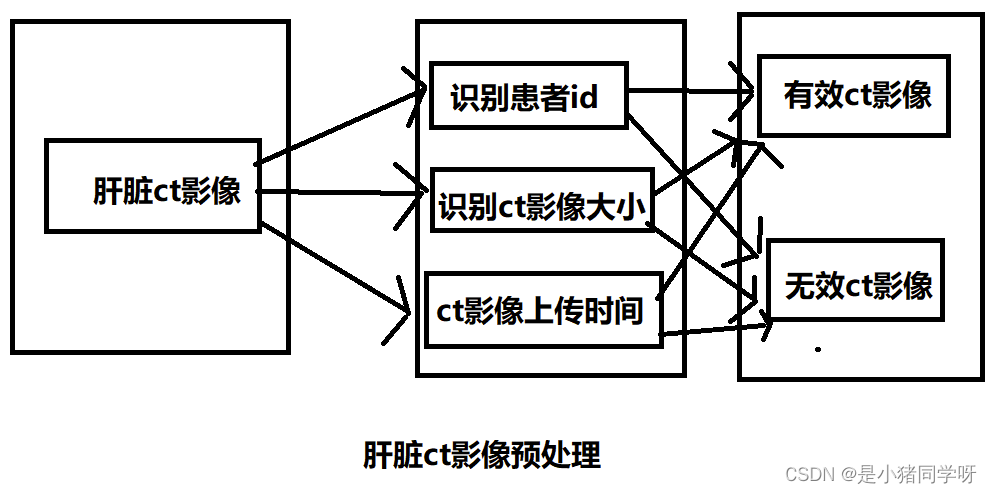
(1) 数据准备和预处理
DECLARE
ARRAY[] CT影像数据集
INTEGER 影像数量
INTEGER 影像高度
INTEGER 影像宽度
FLOAT 影像标准化参数
ARRAY[影像数量][影像高度][影像宽度] 预处理后的数据集
END
# 获取原始的CT影像数据集,可以通过API接口或者本地文件存储方式进行获取。
CT影像数据集 = GET_CT影像数据集()
# 获取CT影像数据集的基本信息(包括数量、高度和宽度等)
影像数量 = GET_影像数量(CT影像数据集)
影像高度 = GET_影像高度(CT影像数据集)
影像宽度 = GET_影像宽度(CT影像数据集)
# 进行CT影像数据集的预处理,包括裁剪、归一化等(可根据具体需求进行调整)
FOR i=1 TO 影像数量
预处理后的数据集[i] = PREPROCESSING(CT影像数据集[i], 影像高度, 影像宽度, 影像标准化参数)
END FOR
# 将预处理后的影像数据集保存到本地或上传到服务器等
PUT(预处理后的数据集)
(2) 构建Unet语义分割模型
# 定义模型结构
DECLARE
LAYERS=4
FILTERS=[32,64,128,256]
KERNEL_SIZE=(3,3)
STRIDES=(2,2)
PADDING='same'
ACTIVATION='relu'
OUTPUT_ACTIVATION='sigmoid'
BATCH_NORMALIZATION=True
DROPOUT_RATE=0.2
CONCATENATE_AXIS=-1
OPTIMIZER='Adam'
LEARNING_RATE=0.001
LOSS_FUNCTION='binary_crossentropy'
METRICS=['accuracy']
MODEL=Unet(输入形状=(影像高度,影像宽度,1),层数=LAYERS,卷积核数=FILTERS,卷积核大小=KERNEL_SIZE,
步长=STRIDES,填充方式=PADDING,激活函数=ACTIVATION,输出激活函数=OUTPUT_ACTIVATION,是否批量归一化=BATCH_NORMALIZATION,
Dropout率=DROPOUT_RATE,拼接轴向=CONCATENATE_AXIS)
MODEL.compile(optimizer=OPTIMIZER,learning_rate=LEARNING_RATE,loss=LOSS_FUNCTION,metrics=METRICS)
END
# 训练模型
DECLARE
EPOCHS=10
BATCH_SIZE=32
VALIDATION_SPLIT=0.2
CHECKPOINT_PATH='/path/to/checkpoint'
TRAIN_HISTORY=None
TRAINED_MODEL=None
END
TRAIN_HISTORY=MODEL.fit(预处理后的数据集, validation_split=VALIDATION_SPLIT, epochs=EPOCHS, batch_size=BATCH_SIZE, callbacks=[ModelCheckpoint(CHECKPOINT_PATH, save_best_only=True)])
# 保存模型
TRAINED_MODEL=MODEL.save('trained_model.h5')
PUT(TRAINED_MODEL)
(3) 模型评估和结果分析
# 加载训练好的模型
TRAINED_MODEL=GET_TRained_MODEL()
# 获取测试集
TEST_SET=GET_TEST_SET()
# 对测试集进行预测
PREDICTIONS=TRAINED_MODEL.predict(TEST_SET)
# 计算性能指标
DECLARE
DICE_COEFFICIENT=None
ACCURACY=None
END
DICE_COEFFICIENT=DiceCoefficient(PREDICTIONS, TEST_SET)
ACCURACY=Accuracy(PREDICTIONS, TEST_SET)
# 分析结果并撰写报告
DECLARE
RESULT_ANALYSIS=None
PROJECT_REPORT=None
END
RESULT_ANALYSIS=ANALYZE_RESULTS(PREDICTIONS, TEST_SET)
PROJECT_REPORT=WRITE_REPORT(预处理后的数据集, MODEL, TRAIN_HISTORY, RESULT_ANALYSIS)
# 保存报告
PUT(PROJECT_REPORT)
(4) 模型部署和应用
# 加载训练好的模型,将训练好的模型部署到实际应用中,如医疗影像诊断系统。
TRAINED_MODEL=GET_TRained_MODEL()
# 预处理待分类影像数据
待分类影像数据=GET_待分类影像数据()
预处理后的待分类影像数据=PREPROCESSING(待分类影像数据, 影像高度, 影像宽度, 影像标准化参数)
# 进行分类
分类结果=TRAINED_MODEL.predict(预处理后的待分类影像数据)
# 显示分类结果
#进行后续的优化和改进,如增加更多的训练数据、调整模型架构等。
#撰写项目报告,包括数据集描述、模型架构、训练过程、结果分析等。
提供详细的技术文档,以便其他人能够理解和复现该项目。
显示分类结果(分类结果)
在模型部署和应用阶段,我们首先加载已经训练好的模型。然后,获取待分类影像数据并进行预处理,确保数据与训练时相同的标准。接着,通过模型进行分类预测,得到分类结果。最后,将分类结果进行显示或者保存,以供使用者查看或进一步处理。