Java Stream 的使用
- 开始
- 中间操作
- forEach 遍历
- map 映射
- flatMap 平铺
- filter 过滤
- limit 限制
- sorted 排序
- distinct 去重
- 结束操作
- collect 收集
- toList、toSet 和 toMap
- Collectors.groupingBy
- Collectors.collectingAndThen
- metch 匹配
- find 查询
- findFirst 与 findAny 的使用
- Optional 的获取
- count 计数
- reduce 规约
Stream 的创建需要指定一个数据源,比如 java.util.Collection 的子类,任何集合类对象以及数组都可以作为这个数据源
它的作用就是链式的对一组元素进行操作,它的操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回 Stream 本身,以下是常见的操作
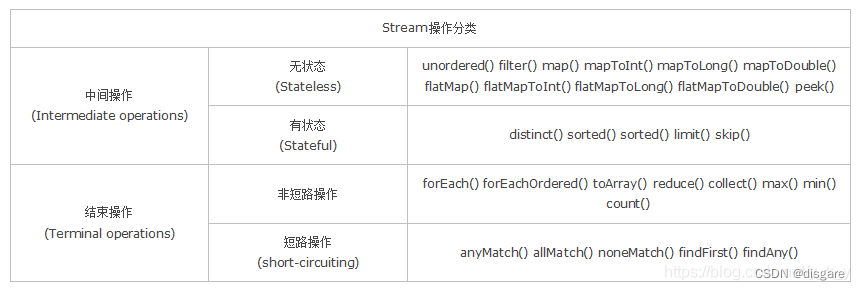
无状态:指元素的处理不受之前元素的影响
有状态:指该操作只有拿到所有元素之后才能继续下去
非短路操作:指必须处理所有元素才能得到最终结果
短路操作:指遇到某些符合条件的元素就可以得到最终结果
Stream 可以使用串行和并行来完成操作,串行操作是用一个线程依次执行,而并行操作使用了多线程,将 stream() 改为 parallelStream() 来使用并行流
流只能用计数器计数:流虽然可以实现很多高大上的操作,但是遇到需要使用数组下标的问题还是只能使用老土的计数器方式,因此如果程序中涉及到要取下标的操作还是推荐使用 for 循环
int index = 0;
list.stream().filter(s ->
//每比对一个元素,数值加1
s.getId() == 10086 ? true : index++ == -1;
).findFirst();
流的操作大多需要使用 lambda 重写逻辑,它的常见操作如下:
开始
我们对一个集合或者迭代器使用 stream 方法就可以得到一个流了
Lists.newArrayList().stream();
Lists.newArrayList().parallelStream();
可以使用 java.util.Arrays.stream(T[] array) 方法用数组创建流
int[] array={1,3,5,6,8};
IntStream stream = Arrays.stream(array);
还可以使用 Stream 的 of 方法获取一个或者多个流
Stream.of(splitter.splitToList(a, b));
同时,在 of 之后,使用 flatMap 方法即可将多个集合转换为一个流。使用 of 方法的话,各个数组并不是分别映射一个流,而是映射成多个流
Stream.of(splitter.splitToList(a, b)).flatMap(Arrays::stream);
此时使用 flatMap(Array::stream) 可以将生成的多个流被合并起来,即扁平化为一个流
中间操作
forEach 遍历
该方法是最常见的,该方法用来迭代流中的每个数据,不只是 stream 对象,集合也可以直接使用 forEach 方法
integers.forEach(System.out::println);
map 映射
该方法用于映射每个元素到对应的结果
integers.stream().map(i -> i+1).forEach(System.out::println);
flatMap 平铺
map 是对流元素进行转换,flatMap 是对流中的元素(数组)进行平铺后合并,即对流中的每个元素平铺后又转换成为了 Stream 流
System.out.println("=====flatmap list=====");
List<String> mapList = list.stream().flatMap(Arrays::stream).collect(Collectors.toList());
mapList.forEach(System.out::print);
System.out.println("\nflatmap list size: " + mapList.size());
System.out.println();
一般在里面直接填入 Arrays::stream 即可
filter 过滤
该方法用于通过设置的条件过滤出元素,只有满足条件的(里面的方法返回为 true)才会留下来,其他的都会被过滤掉。该方法不会删除原集合的数据
integers.stream().filter(a -> a/2 == 0).forEach(System.out::println);
limit 限制
该方法用于获取指定数量的流。 以下代码片段使用 limit 方法打印出前 10 条数据
integers.limit(10).forEach(System.out::println);
sorted 排序
该方法用于对流用指定的操作进行排序,如果不传入 Comparator 排序器,则默认使用自然排序,自然排序需要流中元素需实现 Comparable 接口
integers.sort((a1, a2) -> a2 - a1).forEach(System.out::println);
distinct 去重
方法用于去除流中的重复元素,该方法不用传入参数
integers.distinct().forEach(System.out::println);
distinct 使用 hashCode 和 equals 方法来获取不同的元素。因此,我们的类必须实现 hashCode 和 equals 方法
结束操作
以上方法属于中间操作,返回 Stream 本身,结束操作不会指的是不返回 Stream 的方法
collect 收集
该方法可以返回列表或者字符串,该方法可以接收一个集合实例,将流中元素收集成该集合实例
但是 collect 的功能不止于此,它可以说是内容最繁多、功能最丰富的部分了。从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合
toList、toSet 和 toMap
collect 主要依赖 java.util.stream.Collectors 类内置的静态方法,下面用一个案例演示 toList、toSet 和 toMap,以及把一个集合配合一些分隔符链接为一个字符串
List<String> list = strings.stream().collect(Collectors.toList());
List<String> set = strings.stream().collect(Collectors.toList());
Map<String, String> map = strings.stream().collect(Collectors.toMap(k -> k, v -> v));
String mergedString = strings.stream().collect(Collectors.joining(", "));
我们在 Collectors.toMap 中对重复的 key 去重
Map<Integer, String> map = list.stream().collect(Collectors.toMap(Person::getId, Person::getName, (oldValue, newValue) -> newValue));
Function.identity() 这个函数代表输入什么值就输出什么值,相当与 v -> v
后面的参数则代表遇到重复的 key 时在老值与新值之中取哪个值,举个例子:
list.stream().collect(Collectors.toMap(Person::getId, Function.identity(), (oldV, newV) -> oldV)).values().stream();
你还可以根据这个特性将重复的 key,放入 List,(当然我们也可以通过 groupBy 完成这件事)
Map<String, List<Working>> map =
workings.stream().collect(Collectors.toMap(Working::getInvoicePage,
e -> {
ArrayList<Working> list = new ArrayList<>();
list.add(e);
return list;
},
(oldList, newList) -> {
oldList.addAll(newList);
return oldList;
}));
Collectors.groupingBy
举个例子,我们可以优雅的对某个集合做分组统计,比如在学生这个 pojo 中,对属性班级做分组或者做分组统计
Map<Integer, List<Student>> studentGroup = studentList.stream().collect(Collectors.groupingBy(Student::getClassNumber));
Map<Integer, Long> map = studentList.stream().collect(Collectors.groupingBy(Student::getClassNumber, Collectors.counting()));
上面例子中的第二个,我们修改了返回 Map 值的类型。第二个重载 groupingBy 方法带另一个参数指定后续收集器,应用于第一个集合结果。当我们仅指定一个分类器函数,没有后续收集器,则返回 toList() 集合。如何后续收集器使用 toSet(),则会获得 Set 集合,而不是 List。我们甚至可以对已经分组的集合再进行分组
Map<BlogPostType, Set<BlogPost>> postsPerType = posts.stream()
.collect(groupingBy(BlogPost::getType, toSet()));
Map<String, Map<BlogPostType, List>> map = posts.stream()
.collect(groupingBy(BlogPost::getAuthor, groupingBy(BlogPost::getType)));
三个参数的 groupingBy 方法,通过提供 Map supplier 函数,其允许我们改变 Map 的类型
EnumMap<BlogPostType, List<BlogPost>> postsPerType = posts.stream()
.collect(groupingBy(BlogPost::getType,
() -> new EnumMap<>(BlogPostType.class), toList()));
Collectors.collectingAndThen
Collectors.collectingAndThen() 函数应该最像 map and reduce 了,它可接受两个参数,第一个参数用于 reduce 操作,而第二参数用于 map 操作
先把流中的所有元素传递给第一个参数,然后把生成的集合传递给第二个参数来处理
例如下面的代码
- 把 [1,2,3,4] 这个集合传递给 v -> v * 2 lambda表达式,计算得出结果为[2,4,6,8]
- 然后再把 [2,4,6,8]传递给 Collectors.averagingLong 表达式,计算得出 5.0
- 然后传递给 s -> s * s lambda表达式,计算得到结果为 25.0
@Test
public void collectingAndThenExample() {
List<Integer> list = Arrays.asList(1, 2, 3, 4);
Double result = list.stream().collect(Collectors.collectingAndThen(Collectors.averagingLong(v -> {
System.out.println("v--" + v + "--> " + v * 2);
return v * 2;
}),
s -> {
System.out.println("s--" + s + "--> " + s * s);
return s * s;
}));
System.out.println(result);
}
再比如,我想用对象中的某个属性 list 去重,就可以这么写
Stream.of(wechatUserInfosFromBackend, wechatUserInfosFromC2b)
.flatMap(Collection::stream)
.collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<WechatUserInfo>(Comparator.comparing(WechatUserInfo::getExternalUserid))), ArrayList::new))
metch 匹配
metch 函数只返回 true 与 false,该方法会对传入的数据进行逐个判断,有以下几种类型
- allMatch:接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回 true,否则返回 false
- noneMatch:接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回 true,否则返回 false
- anyMatch:接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回 true,否则返回 false
find 查询
有以下两个分支
- findFirst 返回流中满足条件的第一个元素
- findAny:返回流中找到的第一个元素
这两个方法在串行流中的概念以及效果是一模一样的,不同之处在于并行流
findFirst 与 findAny 的使用
在并行流中的 findAny() 操作,返回的元素是不确定的,对于同一个列表多次调用 findAny() 有可能会返回不同的值。使用 findAny() 是为了更高效的性能。如果是数据较少,串行地情况下,一般会返回第一个结果,如果是并行的情况,那就不能确保是第一个
举个栗子:
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
System.out.println(list.parallelStream().filter(a -> a.equals(2) || a.equals(1) || a.equals(3)).findAny().get());
System.out.println(list.parallelStream().filter(a -> a.equals(2) || a.equals(1) || a.equals(3)).findFirst().get());
这里两个并行流的结果是不一样的,findAny 方法会侧重第一个查到返回值的线程,而 findFirst 则会侧重数组中第一个满足条件的值
Optional 的获取
Optional 是对 stream 使用 findFirst 或者 findAny 方法会得到的类,它是为了防止空指针问题而被创造出来的,本来这块内容不应该是流结束操作涉及到的,但是 findAny 或者 findAny 也算是和 stream 结束有关系
我们在获取 Optional 后直接 get 会提示没有进行赋值检查,因此不推荐直接 get,准确的写法如下:
Optional.of("has value").orElse(getDefault());
Optional.of("has value").orElseGet(() -> getDefault());
Optional.of("has value").ifPresent(A::setB);
说一下 orElse 与 orElseGet 的区别,orElse 是传值的,所以里面的表达式会立即执行(在传入一个方法的时候),如果 optional 有值也会执行就没必要了;而 orElseGet 接受的是一个 function,只有 optional 为空的时候才会被执行,因此不会让 cpu 资源被浪费
尽量在 orElse 中传入属性,在 orElseGet 中传入方法,如果在 orElse 中传入了方法,而且方法中含有更新修改类的操作,这样就不光是 CPU 或者耗时的问题了
count 计数
返回流中元素的总个数
strings.stream().count();
reduce 规约
规约操作(reduction operation)又被称作折叠操作(fold),是通过某个连接动作将所有元素汇总成一个汇总结果的过程。元素求和、求最大值或最小值、求出元素总个数、合并、将所有元素转换成一个元素,都属于规约操作
reduce 擅长的是生成一个值,而 collect 擅长从 Stream 中生成一个集合或者 Map 等复杂的对象
reduce 的方法定义有三种重写形式,我们需要按顺序定义以下三种模式:
- Identity : 定义一个元素代表是归并操作的初始值,如果Stream 是空的,也是 Stream 的默认结果
- Accumulator: 定义一个带两个参数的函数,第一个参数是上个归并函数的返回值,第二个是Strem 中下一个元素。
- Combiner: 调用一个函数来组合归并操作的结果,当归并是并行执行或者当累加器的函数和累加器的实现类型不匹配时才会调用此函数
举几个例子,我们可以用它找出数组中最有特色的值,比如最大值最小值:
Optional<String> res = Stream.of("zhangsan", "lisi", "wanger", "mazi")
.reduce((s1, s2) -> s1.length() >= s2.length() ? s1 : s2);
System.out.println(res.get());
Optional<String> res2 = Stream.of("zhangsan", "lisi", "wanger", "mazi")
.max((s1, s2) -> s1.length() - s2.length());
System.out.println(res2.get());
可以用它来求和
Integer res1 = Arrays.stream(new Integer[]{2, 4, 6, 8})
.reduce(0, Integer::sum);
很明显我们只能将列表变成列表中的一个元素,那假如需要将整数列表变成一个字符串,我们该如何操作呢?我们当然可以先使用 map 做转换,但是也可以使用 reduce 提供的第三个参数
int result = users.stream()
.reduce("", (a, b) -> a + String.valueOf(b), String::concat);