目录:
- 学习目标
- 读写文件
- 写文件
- 读取文件
- index_col参数指定索引
- parse_dates参数指定列解析为时间日期类型
- encoding参数指定编码格式
- 读取tsv文件
- Pandas读写文件小结
- 读写数据库
- 安装pymysql包
- 将数据写入数据库
- 从数据库中加载数据
- 总结
- 项目地址
1.学习目标
-
能够使用Pandas读写文件中的数据
-
知道Pandas读取数据时常用参数index_col、parse_dates、encoding的作用和用法
-
知道Pandas和Mysql数据库做读写交互的方法
2.读写文件
| 文件格式 | 读取函数 | 写入函数 |
|---|---|---|
| xlsx | pd.read_excel | df.to_excel |
| xls | pd.read_excel | df.to_excel |
| csv | pd.read_csv | df.to_csv |
| tsv | pd.read_csv | df.to_csv |
| json | pd.read_json | to_json |
| html | pd.read_html | df.to_html |
| sql | pd.read_sql | df.to_sql |
| 剪贴板 | df.read_clipboard | df.to_clipboard |
写文件
import pandas as pd
# 构造df数据集
df = pd.DataFrame(
[
['1960-5-7', '刘海柱', '职业法师'],
['1978-9-1', '赵金龙', '大力哥'],
['1984-12-27', '周立齐', '窃格瓦拉'],
['1969-1-24', '于谦', '相声皇后']
],
columns=['birthday', 'name', 'AKA']
)
print(df)
# 此时应该在运行代码的相同路径下就生成了一个名为“写文件.csv”的文件
df.to_csv('./datas/写文件.csv')读取文件
import pandas as pd
df = pd.read_csv('./datas/写文件.csv')
print(df)
index_col参数指定索引
index_col参数可以在读文件的时候指定列作为返回dataframe的索引,两种用法如下
-
通过列下标指定为索引
-
通过列名指定为索引
-
通过列下标指定为索引
index_col=[列下标]
import pandas as pd
df = pd.read_csv('./datas/写文件.csv', index_col=[0])
print(df)
-
通过列名指定为索引
index_col=['列名']
import pandas as pd
df = pd.read_csv('./datas/写文件.csv', index_col=['Unnamed: 0'])
print(df)
-
上述代码返回结果一致
parse_dates参数指定列解析为时间日期类型
parse_dates参数可以在读文件的时候解析时间日期类型的列,两种作用如下:
-
将指定的列解析为时间日期类型
-
通过列下标解析该列为时间日期类型
-
通过列名解析该列为时间日期类型
-
-
将df的索引解析为时间日期类型
-
通过列下标解析该列为时间日期类型
parse_dates=[列下标]
import pandas as pd
print(pd.read_csv('./datas/写文件.csv').info())
print(pd.read_csv('./datas/写文件.csv', parse_dates=[1]).info())
-
通过列名解析该列为时间日期类型
parse_dates=[列名]
import pandas as pd
print(pd.read_csv('./datas/写文件.csv').info())
print(pd.read_csv('./datas/写文件.csv', parse_dates=['birthday']).info())
-
将df的索引解析为时间日期类型
parse_dates=True
import pandas as pd
df = pd.read_csv('./datas/写文件.csv', index_col=[1], parse_dates=True)
print(df)
print(df.index)
encoding参数指定编码格式
- 字符是有编码格式的,常见的编码格式有:ASCII、GB2312、UTF8;关于编码和编码格式课后阅读百度百科
https://baike.baidu.com/item/标准编码格式
-
运行下面的代码会报错,因为pandas在读取文件时,默认认为数据文件的编码格式是
UTF8,但1960-2019全球GDP数据.csv这个文件的编码格式是GBK
pd.read_csv('../数据集/1960-2019全球GDP数据.csv') # 报错 UnicodeDecodeError: 'utf-8' codec can't decode ...-
所以我们在读取这个文件的时候就需要指定编码格式为
encoding='gbk'
import pandas as pd
# print(pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv').head())
print(pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk').head())
读取tsv文件
- tsv文件:特殊的csv文件,以
\t作为字符分隔符(csv文件是以半角逗号,作为字符分隔符的),文件扩展名为.tsv -
还是使用
pd.read_csv()函数读取tsv文件,需要使用参数sep='\t'来指定字符分隔符
import pandas as pd
print(pd.read_csv('../datas/data_set/tsv示例文件.tsv', sep='\t', index_col=[0]))
Pandas读写文件小结
-
写文件方法
df.to_csv('xxx.csv') -
pd.read_csv()读取文件,常用参数如下-
index_col指定索引列-
index_col = [1]列下标指定为索引 -
index_col = ['col_name']列名指定为索引
-
-
parse_dates对指定列解析为时间日期类型-
将指定的列解析为时间日期类型
-
parse_dates=[1]通过列下标解析该列为时间日期类型 -
parse_dates=['col_name']通过列名解析该列为时间日期类型
-
-
parse_dates=True将df的索引解析为时间日期类型
-
-
encoding='gbk'参数指定编码格式 -
pd.read_csv('xxx.tsv', sep='\t')指定字符分隔符为\t读取tsv文件
-
3.读写数据库
- 以MySQL数据库为例,此时默认你已经在本地安装好了MySQL数据库。如果想利用pandas和MySQL数据库进行交互,需要先安装与数据库交互所需要的python包
安装pymysql包
pip install pymysql==1.0.2将数据写入数据库
import pandas as pd
df = pd.read_csv('../datas/data_set/tsv示例文件.tsv', sep='\t', index_col=[0])
print(df)
# 创建数据库操作引擎对象并指定数据库
# 需要安装pymysql,部分版本需要额外安装sqlalchemy
# 导入sqlalchemy的数据库引擎
from sqlalchemy import create_engine
# 创建数据库引擎,传入url规则的字符串
engine = create_engine('mysql+pymysql://root:666666@127.0.0.1:3308/test?charset=utf8')
# mysql+pymysql://root:chuanzhi@127.0.0.1:3306/test?charset=utf8
# mysql 表示数据库类型
# pymysql 表示python操作数据库的包
# root:chuanzhi 表示数据库的账号和密码,用冒号连接
# 127.0.0.1:3306/test 表示数据库的ip和端口,以及名叫test的数据库
# charset=utf8 规定编码格式
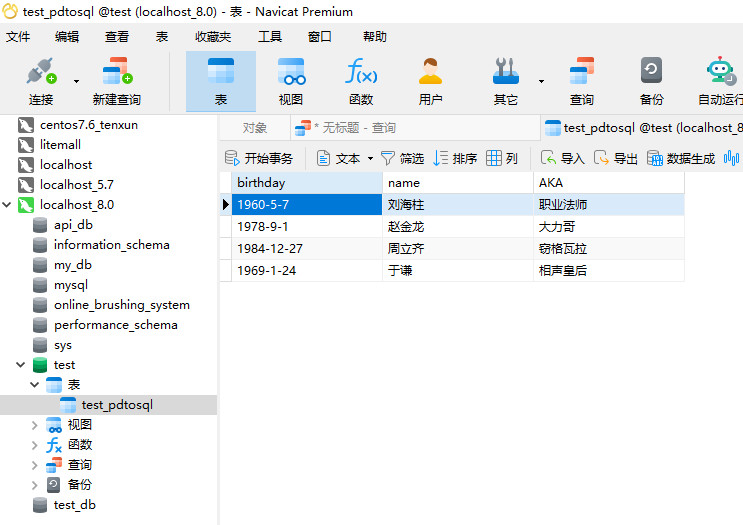
# 将数据写入MySQL数据库
# df.to_sql()方法将df数据快速写入数据库
df.to_sql('test_pdtosql', engine, index=False, if_exists='append')
# 第一个参数为数据表的名称
# 第二个参数engine为数据库交互引擎
# index=False 表示不添加自增主键
# if_exists='append' 表示如果表存在就添加,表不存在就创建表并写入-
此时我们就可以在本地test库的test_pdtosql表中看到写入的数据
从数据库中加载数据
-
读取整张表,返回dataframe
import pandas as pd
from sqlalchemy import create_engine
# 创建数据库引擎,传入url规则的字符串
engine = create_engine('mysql+pymysql://root:666666@127.0.0.1:3308/test?charset=utf8')
# 指定表名,传入数据库连接引擎对象
print(pd.read_sql('test_pdtosql', engine))
-
使用SQL语句获取数据,返回dataframe
import pandas as pd
from sqlalchemy import create_engine
# 创建数据库引擎,传入url规则的字符串
engine = create_engine('mysql+pymysql://root:666666@127.0.0.1:3308/test?charset=utf8')
# 传入sql语句,传入数据库连接引擎对象
print(pd.read_sql('select name,AKA from test_pdtosql', engine))
4.总结
-
df.to_csv('xxx.csv')写文件 -
pd.read_csv()读取文件,常用参数如下-
index_col指定索引列-
index_col = [1]列下标指定为索引 -
index_col = ['col_name']列名指定为索引
-
-
parse_dates对指定列解析为时间日期类型-
将指定的列解析为时间日期类型
-
parse_dates=[1]通过列下标解析该列为时间日期类型 -
parse_dates=['col_name']通过列名解析该列为时间日期类型
-
-
parse_dates=True将df的索引解析为时间日期类型
-
-
encoding='gbk'参数指定编码格式 -
pd.read_csv('xxx.tsv', sep='\t')指定字符分隔符为\t读取tsv文件
-
-
Pandas和Mysql进行交互(读写)
# 需要安装 pip istall pymysql
# 可能需要额外安装 pip istall sqlalchemy
# 导入sqlalchemy的数据库引擎
from sqlalchemy import create_engine
# 创建数据库引擎,传入uri规则的字符串
engine = create_engine('mysql+pymysql://root:chuanzhi@127.0.0.1:3306/test?charset=utf8')
# mysql+pymysql://root:chuanzhi@127.0.0.1:3306/test?charset=utf8
# mysql 表示数据库类型
# pymysql 表示python操作数据库的包
# root:chuanzhi 表示数据库的账号和密码,用冒号连接
# 127.0.0.1:3306/test 表示数据库的ip和端口,以及名叫test的数据库
# charset=utf8 规定编码格式
# df.to_sql()方法将df数据快速写入数据库
df.to_sql('test_pdtosql', engine, index=False, if_exists='append')
# 第一个参数为数据表的名称
# 第二个参数engine为数据库交互引擎
# index=False 表示不添加自增主键
# if_exists='append' 表示如果表存在就添加,表不存在就创建表并写入
# 指定表名,传入数据库连接引擎对象
pd.read_sql('test_pdtosql', engine)
# 传入sql语句,传入数据库连接引擎对象
pd.read_sql('select name,AKA from test_pdtosql', engine)5.项目地址
Python: 66666666666666 - Gitee.com
![【算法每日一练]-图论(保姆级教程 篇1(模板篇)) #floyed算法 #dijkstra算法 #spfa算法](https://img-blog.csdnimg.cn/737f0a7aba064b66935cb175d302571a.png)