作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
双向链表
- **作者前言**
- 链表的差别
- 带头双向循环链表的实现
- 链表初始化
- 节点创建
- 链表的尾插
- 链表尾删
- 打印链表
- 链表头插
- 链表头删
- 判断链表是否为空
- 链表pos前插入
- 计算链表长度
- 链表删除pos前一个节点
- 删除pos节点
- 释放链表
- 顺序表和链表的差异
链表的差别
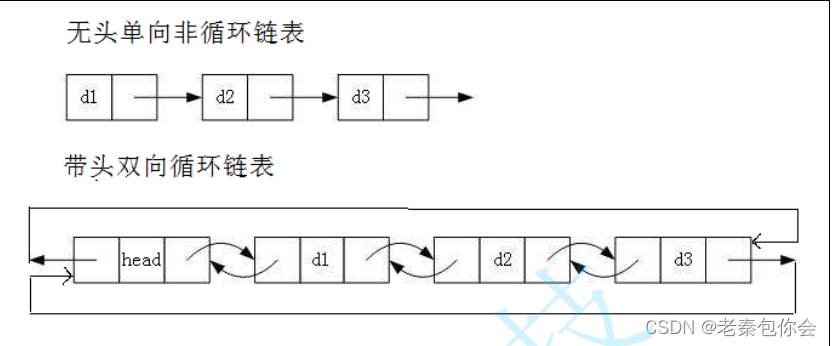
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结
构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。 - 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都
是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带
来很多优势,实现反而简单了,后面我们代码实现了就知道了。
带头双向循环链表的实现

我们需要的当这种链表为空时,
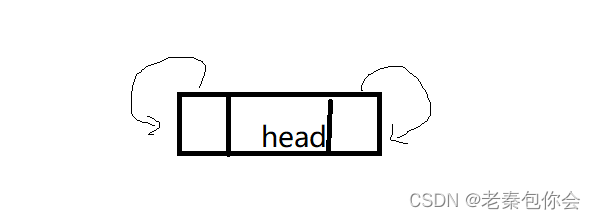
这个小知识一定要记住
链表初始化
DLists* plist = (DLists*)malloc(sizeof(DLists));
plist->next = plist;
plist->prev = plist;
一个节点要包含三部分分别是值,两个指针
节点创建
//创建节点
DLists* CreateNode(DLDataType elemest)
{
DLists* newnode = (DLists*)malloc(sizeof(DLists));
newnode->next = newnode;
newnode->prev = newnode;
newnode->val = elemest;
return newnode;
}
链表的尾插

void DLPushBack(DLists* plist, DLDataType elelmest)
{
assert(plist);
//创建节点
DLists* newnode = CreateNode(elelmest);
DLists* n = plist->prev;
newnode->next = plist;
newnode->prev = n;
n->next = newnode;
plist->prev = newnode;
}
这里我们只需要更改四个指针指向就可以,分别是哨兵位的 、prev 和新节点的prev 、next和旧节点的next
链表尾删
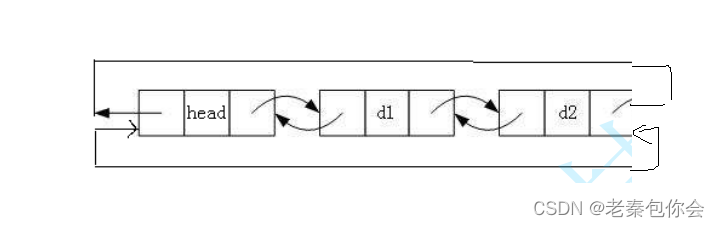
void DLPopBack(DLists* plist)
{
assert(plist->next != plist && plist);
//保存最后一个节点的地址
DLists* p = plist->prev;
plist->prev = p->prev;
DLists* p1 = p->prev;
p1->next = plist;
free(p);
}
这样写可以防止只有一个节点的时候报错
我们可以创建两个指针,一个指向要free的节点,一个是要和哨兵位关联的节点也就是d2
打印链表

我们可以从d1这个节点开始打印,遇见头节点就结束
//打印
void DLPrint(DLists* plist)
{
assert(plist);
printf("哨兵位");
DLists* tail = plist->next;
while (tail != plist)
{
printf("<=>%d", tail->val);
tail = tail->next;
}
printf("<=>哨兵位\n");
}
链表头插
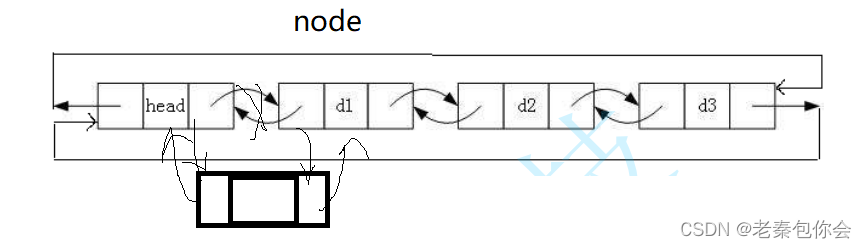
我们可以创建一个指针用于存储d1的地址,然后把节点插入,这样可以简单快捷
//头插
void DLPushFront(DLists* plist, DLDataType elemest)
{
assert(plist);
DLists* n1 = plist->next;
//创建节点
DLists* newnode = CreateNode(elemest);
plist->next = newnode;
newnode->prev = plist;
n1->prev = newnode;
newnode->next = n1;
}
链表头删
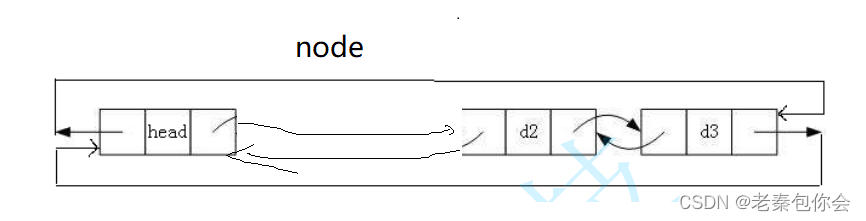
当我们删除到哨兵位就不要删除了
//头删
void DLPopFront(DLists* plist)
{
assert(plist->next != plist && plist);
// 保存下一个节点
DLists *nextnode = plist->next;
DLists* nexnode_next = nextnode->next;
plist->next = nexnode_next;
nexnode_next->prev = plist;
free(nextnode);
}
判断链表是否为空
// 判断链表是否为空
bool Empty(DLists* plist)
{
assert(plist);
return plist->next == plist;
}
链表pos前插入
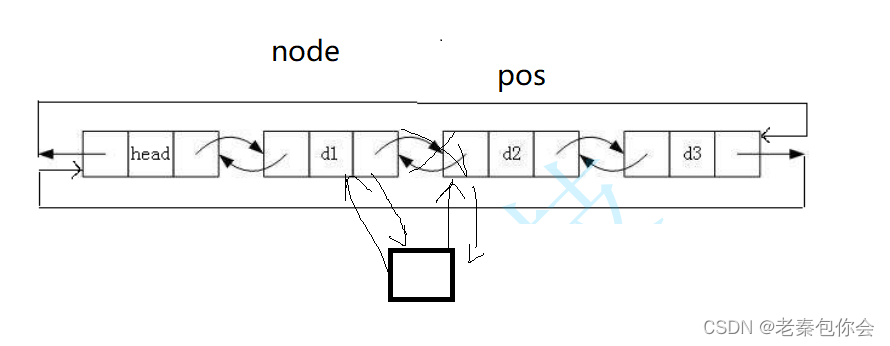
//在pos前面插入
DLists* DLPushbefore(DLists* plist, DLists* pos, DLDataType elemest)
{
assert(plist);
//创建节点
DLists* newnode = CreateNode(elemest);
//pos的前一个节点
DLists* node = pos->prev;
pos->prev = newnode;
newnode->next = pos;
newnode->prev = node;
node->next = newnode;
}
计算链表长度
// 长度
int DLSize(DLists* plist)
{
assert(plist);
DLists* tail = plist->next;
int size = 0;
while (tail != plist)
{
size++;
tail = tail->next;
}
return size;
}
链表删除pos前一个节点
//删除pos前一个节点
DLists* DLPopbefore(DLists* plist, DLists* pos)
{
assert(plist && pos);
assert(pos->prev != plist);
//前一个节点
DLists* n2 = pos->prev;
//前前一个节点
DLists* n1 = n2->prev;
n1->next = pos;
pos->prev = n1;
free(n2);
}
删除pos节点
// 删除 pos节点
DLists* DLPop(DLists* plist, DLists* pos)
{
assert(plist && pos);
assert(pos!= plist);
//pos前一个节点
DLists* n2 = pos->prev;
//pos后一个节点
DLists* n1 = pos->next;
n2->next = n1;
n1->prev = n2;
free(pos);
}
释放链表
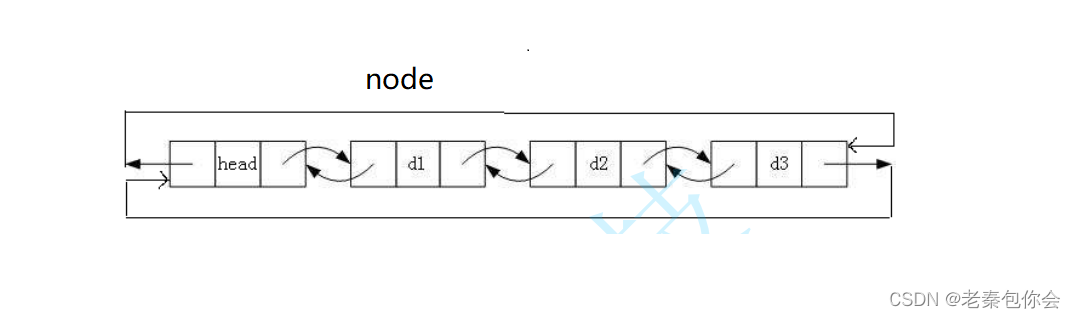
从d1开释放,遇见head停止
//释放链表
void DLDestroy(DLists** plist)
{
assert(*plist && plist);
DLists* tail = (*plist)->next;
while (tail != *plist)
{
DLists* node = tail;
tail = tail->next;
free(node);
}
free(*plist);
*plist = NULL;
}
顺序表和链表的差异
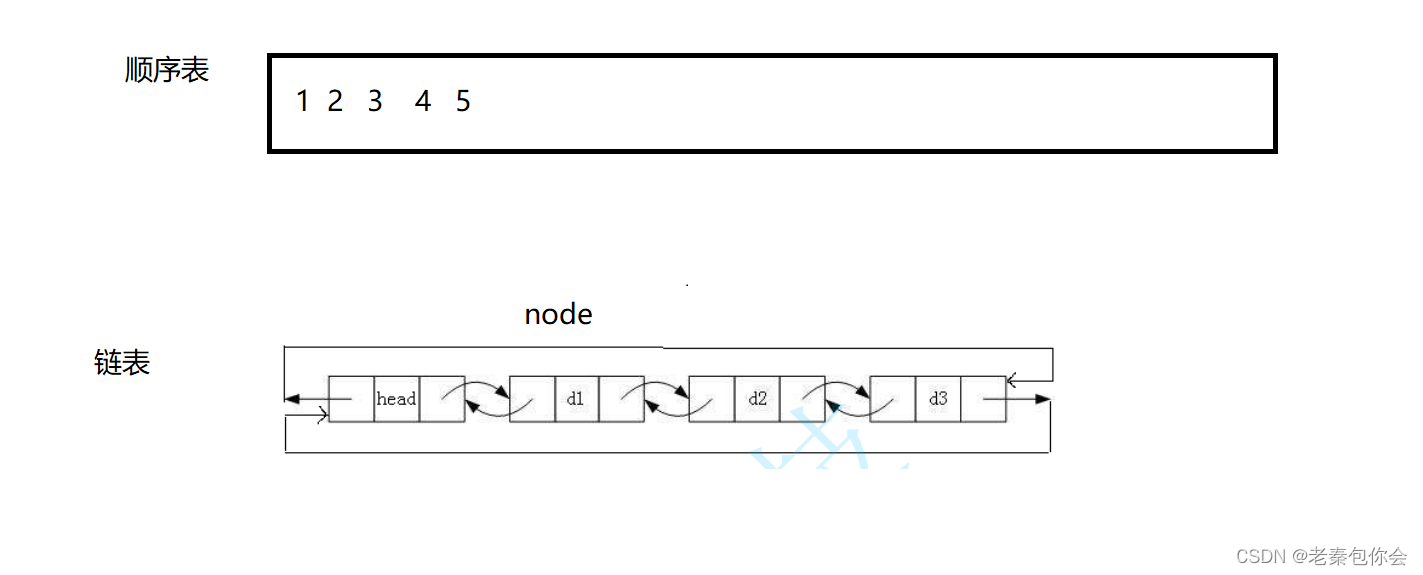
链表的优势
- 任意位置插入和删除都是O(1),前提是知道位置
- 按需申请和释放
缺点问题
3. 下标随机访问不方便,物理空间不连续,O(n)
4. 链表不好排序
顺序表的问题
5. 头部插入或者中间插入删除效率低下,要移动数据
6. 空间不够要扩容,扩容会有一定消耗且可能存在一定的空间浪费.
7. 只适合尾插尾删
优势
支持下标的随机访问