大家好,我是老三,不知道大家有没有经历过这样的场景,线上出了问题,着急火燎地去排查:
唉,问题可能出在这个地方,捞个日志看下,卧槽,怎么找不到……哪个**不打日志,啊,原来是我自己。
日志这东西,平时看不出来什么,真要出了问题,那就是救命的稻草。这期就给大家分享一些日志相关的东西。
弄懂日志
什么是日志?
日志,维基百科中对其的定义是一个或多个由服务器自动创建和维护的日志文件,其中包含其所执行活动的列表。
作为开发,我们都熟悉日志的重要性,良好的日志,能帮助我们快速定位到错误发生的详情和原因,并快速解决问题。
为什么要打日志?
前面提到日志可以提供精准的系统记录方便根因分析,那为什么要记录日志,记录日志有哪些作用呢?
-
调试和排查问题:通过记录日志,可以在程序运行时打印关键变量、逻辑和流程,方便我们进行调试和排查问题。
-
监控和告警:通过对日志进行监控和分析,可以及时发现系统的异常行为和潜在问题。通过设置合适的告警规则,可以在系统发生异常或达到预警条件时及时通知开发,以便采取相应的措施。
-
用户行为审计:记录和采集用户的操作行为以及事件可以用于审计和安全监控。通过分析用户行为日志,可以了解用户的操作习惯、需求和偏好。
-
问题原因分析(甩锅):在关键地方记录日志。方便和其它业务方解决问题的时候,获取问题的根源,及时甩锅。
……
什么时候打日志?
那么一般会在什么时候打日志呢?下面列举了一些常见的场景:
- 系统初始化:在系统或服务的启动过程中,记录一些关键配置参数和启动完成状态,以便于排查问题和了解系统的运行情况。通常使用 INFO 级别记录。
- 异常情况:当系统遇到编程语言的异常或业务流程不符合预期时,记录日志以便于追踪和调试。根据异常的严重程度,可以使用 WARN 或 ERROR 级别记录。
- 业务流程的关键点:对于业务流程中的关键点或核心角色的动作,建议记录日志以监控系统的运行情况。比如用户从登录到下单的整个流程,微服务之间的交互,核心数据表的增删改等。通常使用 INFO 级别记录。
- 第三方服务远程调用:在微服务架构中,第三方服务的可靠性是一个重要的问题。建议记录第三方服务的请求和响应参数,以便于排查问题和定位故障。通常使用 INFO 级别记录。
需要注意的是,日志记录的频率和打印量应根据具体情况进行评估和调整,避免日志过于频繁或过于庞大。
怎么打日志?
大家都知道,Java别的不多,就是轮子多,在Java程序里,打印日志,可以选择的方法和轮子也不少:
System.out.println():将日志信息打印到标准输出流(控制台),最简单的方式,但是不灵活。java.util.logging:Java自带的日志框架,提供了一套API用于记录日志,可以控制日志级别和输出目标。- Log4j:流行的开源日志框架,提供了丰富的功能和配置选项,支持异步输出和滚动日志文件等特性。
- SLF4J:日志门面框架,提供了统一的API,可以与不同的日志实现进行适配。
- Logback:由Log4j的创始人开发的高性能日志框架,可作为SLF4J的实现。
在项目中,一般推荐用SLF4J作为日志门面框架,和不同的日志框架进行适配,如果因为某些原因,比如前两年,Log4j曝出了大漏洞,需要进行替换和升级的时候,只需要修改相应的依赖和配置即可,而不需要修改项目里的日志记录代码。
怎么查日志?
日志打完了就得用,用就得查,那么我们打印的日志怎么查询呢?
日志文件
一般通过日志框架打印日志的时候,都会配置日志输出的路径:
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>/path/to/logs/myapp.log</file>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
查看日志最简单直接的方法,就是在对应的目录下,去寻找相应的日志,在Linux系统中,可以通过这些命令去查看日志文件:
-
cat:可以使用cat命令来查看日志文件的内容。例如,使用
cat /var/log/syslog命令可以查看系统日志文件的内容。 -
tail:tail命令可以用来显示文件的末尾内容,常用于实时查看日志文件的更新。使用
tail -f /var/log/syslog命令可以实时查看系统日志文件的更新内容。 -
less:less命令可以用来浏览文件的内容,并且支持向上和向下滚动。例如,使用
less /var/log/syslog命令可以打开系统日志文件,并通过上下箭头键来滚动浏览文件内容。 -
grep:grep命令可以用来在文件中搜索指定的关键字或模式。例如,使用
grep "error" /var/log/syslog命令可以查找系统日志文件中包含"error"关键字的行。
除了命令行工具,还可以使用一些图形化的日志查看工具来浏览和分析日志文件,例如logrotate、journalctl等。
现在的服务,一般都是容器化部署,可以通过容器的日志命令来查看日志:
- Docker:如果用的是Docker管理容器,可以使用
docker logs命令来查看容器的日志。例如,使用docker logs命令可以查看指定容器的日志内容。 - Kubernetes:如果用的是Kubernetes管理容器,可以使用
kubectl logs命令来查看容器的日志。例如,使用kubectl logs命令可以查看指定Pod中容器的日志内容。
ELK
直接通过日志文件查询日志可能会比较繁琐,效率比较低,可以使用一些日志聚合工具来收集和管理日志。例如使用使用ELK Stack(Elasticsearch, Logstash, Kibana)来集中管理和可视化日志。
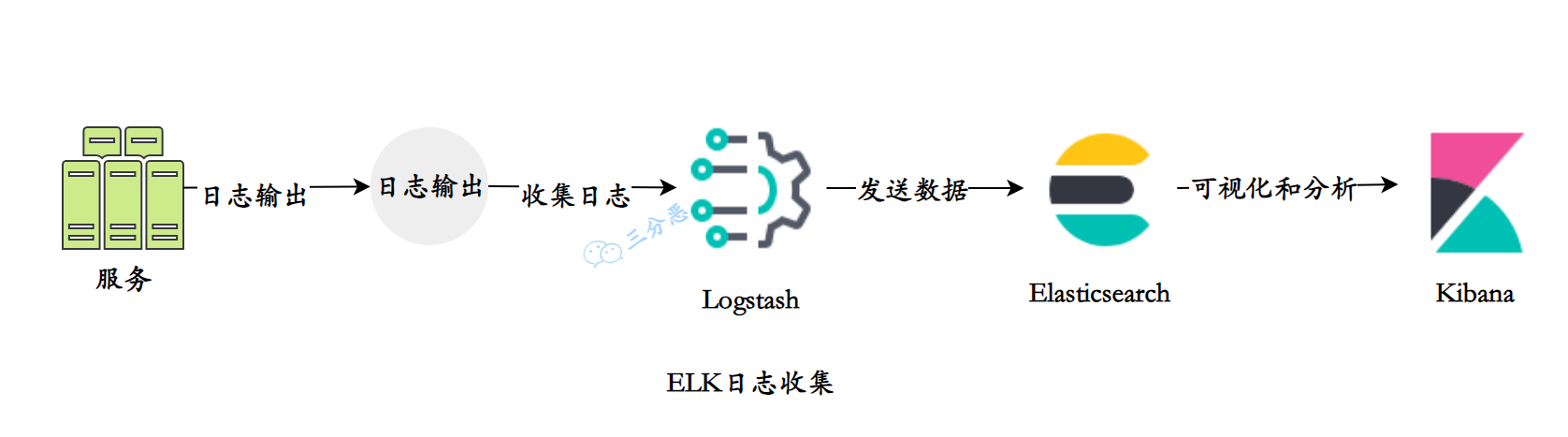
- Elasticsearch:用于存储和索引日志数据,提供高效的搜索和分析功能。
- Logstash:用于收集、过滤和转发日志数据,可以从多个来源(如文件、网络等)收集日志,并将其发送到Elasticsearch进行存储和索引。
- Kibana:用于可视化和分析日志数据,提供灵活的查询和可视化工具,可以创建仪表板、图表和报表来展示日志数据的统计和趋势。
SLS
SLS(阿里云日志服务)是由阿里云提供的商业化日志收集解决方案,它提供了一站式的日志数据采集、消费和查询分析功能,无需开发即可使用。

通过SLS,可以方便地收集、存储和查询日志数据,进行实时监控、故障排查和业务分析。同时,SLS还提供了丰富的查询和分析功能,如日志关键词搜索、日志分析报表等,整体功能还是非常强大的——毕竟要氪金。
更多关于SLS阿里云日志服务的详细信息,大家可以搜索相关文档或访问阿里云官方网站进行了解,这里就不展开更多了。
打印日志最佳实践
打日志这件事情,说起来很简单,有手就行,但是想要打良好的日志,就没那么那么简单。
那么,怎样才算是一份良好的日志呢?应该具备这些特点:
- 详细和准确:日志应该记录足够详细的信息,包括时间、触发事件、相关参数和上下文等,方便我们快速理解时间的发生和上下文。
- 可读性强:日志应该使用易于阅读和理解的格式,日志信息能够被其它开发人员快速理解,而不需要费力解析复杂的日志内容。
- 可配置性:日志系统应该具备可配置的选项,以便开发人员可以根据需要调整日志级别、输出目标和格式等。
- 性能高效:日志记录应该对系统性能的影响尽可能小,避免对应用程序的正常运行造成明显的延迟。
- 安全性:日志应该保护敏感信息的安全性,避免将敏感数据记录在日志中,以防止信息泄露的风险。
那么接下来,围绕这些要点,我们来看看打印日志的最佳实践。
1.选择合适的日志级别
在选择日志级别时,需要根据不同的场景和需求来确定合适的级别。
以下是常见的日志级别及其适用场景:
- Error(错误):表示比较严重的问题,可能会导致业务运行异常或失败。这些错误可能需要立即处理,来保证业务的正常运行。例如,数据库连接失败、关键功能异常等。
- Warn(警告):表示一些不太严重的问题,对业务的影响不大,但需要开发人员注意。这些警告可能是一些潜在的问题或异常情况,需要及时关注和处理。例如,接口请求超时、配置项缺失等。
- Info(信息):用于记录日常排查问题的关键信息,如接口的入参和出参、关键业务操作的结果等。这些信息对于了解系统运行状态和分析问题非常有帮助,但不会对业务流程造成直接影响。
- Trace(详细信息):提供更详细的日志信息,通常用于调试和排查问题。这些日志包含了更详细的上下文信息,可以用来追踪代码执行路径和查看具体的变量值。由于详细程度较高,一般在开发和测试环境中使用,不适合线上环境。
- Debug(调试):仅用于开发或测试阶段,用于查看重要的内部逻辑细节。这些日志级别通常和线上业务关系不密切,主要用于开发人员进行代码调试和问题排查。
在实际应用中,可以根据具体需求和系统特点,选择合适的日志级别来平衡日志的详细程度和性能开销。通常建议在生产环境中使用较高级别的日志级别(如Error、Warn、Info),而在开发和测试环境中可以使用更详细的级别(如Trace、Debug)来辅助调试和排查问题。
2.选择适当的日志格式
在实际的开发中,可能会打印不同种类的日志,常见的日志种类包括:

日志打印的时候,日志格式要尽量兼顾完备性、可读性和性能。
摘要日志
摘要日志是一种标准化的日志文件,主要用于监控系统配置和进行离线日志分析。它通常包含以下关键信息:
- 调用时间:记录了日志产生的具体时间。
- 日志链路 id:包括traceId和rpcId,用于追踪请求的完整路径。
- 线程名:记录了产生日志的线程名称。
- 接口名:记录了被调用的接口名称。
- 方法名:记录了被调用的方法名称。
- 调用耗时:记录了方法调用的耗时。
- 调用是否成功:记录了方法调用是否成功,通常用Y/N表示。
- 错误码:如果方法调用失败,会记录相应的错误码。
- 系统上下文信息:包括调用系统名、调用系统ip、调用时间戳、是否压测等。
2022-12-12 06:05:05,129 [0b26053315407142451016402xxxxx 0.3 - /// - ] INFO [SofaBizProcessor-4-thread-333] - [(interfaceName,methodName,1ms,Y,SUCCESS)(appName,ip地址,时间戳,Y)
在Java中,通常可以通过配置日志框架来定义一些通用信息的打印,比如调用时间、日志链路id、方法名等。具体的配置方式取决于所选择的日志框架。
例如使用Logback作为日志框架:
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{traceId}] [%thread] [%logger{0}] - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
详细日志
详细日志是一种补充摘要日志中的业务参数的日志文件,主要用于问题排查。除了包含摘要日志的所有信息,详细日志还会记录请求的入参和出参。
2022-12-12 06:05:05,129 [0b26053315407142451016402xxxxx 0.3 - /// - ] INFO [SofaBizProcessor-4-thread-333] - [(interfaceName,methodName,1ms,Y,SUCCESS)(appName,ip地址,时间戳,Y)(参数1,参数2)(xxxx)
业务执行日志
业务执行日志主要记录系统执行过程,用于跟踪代码执行逻辑。在打印业务执行日志时,需要考虑以下几个因素:
- 必要性:考虑是否真的需要打印这个日志,如果不打印是否会影响后续问题排查,如果打印这个日志后续输出频率是否会太高,造成线上日志打印过多。
- 辨识度:考虑日志格式是否具有辨识度,如果后续对该条日志进行监控或清洗,是否存在无法与其他日志区分或者每次打印的日志格式都不一致的问题。
- 关键步骤和参数:日志中需包含明确的打印意义,当前执行步骤的关键参数。
建议的格式是:[日志场景][日志含义]带业务参数的具体信息。这种格式可以清晰地表述出打印该条日志的作用,方便后续维护人员阅读。
[scene_bind_feature][feature_exists]feature xxx exists[tagSource='MIF_TAG',tagValue='123']
3.建议入参出参打印日志
建议在与接口相关的日志以及关键方法的入参和返回值中添加日志,以便更好地追踪和调试代码。
正例:
public String myMethod(String param1, int param2) {
logger.info("Entering myMethod. Param1: {}, Param2: {}", param1, param2);
// 方法逻辑
String result = "some result";
logger.info("Exiting myMethod. Result: {}", result);
return result;
}
4.使用占位符{}而不是拼接+
使用占位符{}而不是+号进行字符串拼接,更加优雅和高效。使用占位符{}的方式可以提高代码的可读性,并且避免了使用+号进行字符串拼接时可能出现的性能损耗。
反例:
logger.info("Processing trade with id: " + id + " and symbol: " + symbol);
正例:
logger.info("Processing trade with id: {} and symbol : {} ", id, symbol);
5.建议日志要打英文
建议在打印日志时使用英文,因为使用中文,可能会有两个问题:
- 中文日志可能会导致编码问题,在日志文件里出现乱码。
- 大多数日志分析工具都是基于英文字符进行匹配和检索的,使用中文可能影响日志的查询和分析。
反例:
logger.info("用户登录成功,用户名:{}","张三");
正例:
logger.info("User login successful. Username:{} ","Zhang San");
6.日志要打印关键参数
日志最重要的作用是用于排查问题和追踪代码执行过程,因此建议在日志中打印关键的公共参数或业务参数,如Trace ID、Order ID等。
正例:
logger.info("Placing order, Order ID: {}, Customer ID: {}, Amount: {}", orderId, customerId, amount);
// 下单逻辑
String result = "Order placed successfully";
logger.info("Order placed. Order ID: {}, Result: {}", orderId, result);
7.建议多分支首行打印日志
在条件分支比较复杂的情况下,建议在进入分支的首行打印相关信息,方便在调试,或者出现问题的时候,知道我们的代码进入的是哪一个分支。
正例:
public void process(String type) {
if ("xxx".equals(type)) {
logger.debug("Current branch type: xxx");
// Branch xxx logic
} else if ("aaa".equals(type)) {
logger.debug("Current branch type: aaa");
// Branch aaa logic
} else {
logger.debug("Current branch type: other");
// Default branch logic
}
}
8.不要直接使用日志系统(Log4j、Logback)中的 API
在应用中,应该依赖日志框架(如SLF4J、JCL)的API,而不是直接使用具体的日志系统(如Log4j、Logback)的API。
直接使用Log4j或Logback等日志系统的API会导致系统代码与具体的日志实现强耦合,当需要切换日志实现时,会带来较大的改造成本。而使用日志框架的API,如SLF4J或JCL,它们是使用门面模式的日志框架,可以实现解耦具体的日志实现,有利于后续的维护,并确保各个类的日志处理方式保持统一。
正例:
// 使用SLF4J:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static final Logger logger = LoggerFactory.getLogger(MyClass.class);
// 使用JCL:
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
private static final Log log = LogFactory.getLog(MyClass.class);
9.日志工具对象 Logger 应声明为 private static final
在声明日志工具对象Logger时,应该将其修饰符设置为private static final。
- 声明为private可以防止Logger对象被其他类非法使用,保证日志的访问权限。
- 声明为static可以避免重复创建Logger对象,节省资源开销。
- 声明为final可以确保Logger对象在类的生命周期内不会被修改,保持一致性。
正例:
private static final Logger LOGGER = LoggerFactory.getLogger(MyClass.class);
10.建议不要直接用 JSON 工具将对象转换成 String
反例:
public void doSomeThing() {
log.info("doSomeThing and print log, data={}", JSON.toJSONString(data));
// 业务逻辑
...
}
在日志打印过程中,建议不要直接使用JSON工具将对象转换成String。
- 使用JSON工具(如fastjson)将对象转换成String时,会调用对象的get方法进行序列化。如果对象中的某些get方法被覆写,并且可能会抛出异常,那么在打印日志时可能会影响正常的业务流程执行。
- 对象的序列化过程本身是一个计算密集型的过程,会消耗CPU资源。此外,序列化过程还会产生许多中间对象,对内存也不友好。
正例:
可以使用 apache 的 ToStringBulider 工具,或者自定义toString方法。
public void doSomeThing() {
log.info("doSomeThing and print log, data={}", ToStringBuilder.reflectionToString(data, ToStringStyle.SHORT_PREFIX_STYLE));
}
11.日志打印不能出现异常
在日志打印过程中,应该避免出现异常,以免影响正常的业务流程。
反例:
这个反例里直接调用了data.toString()方法来打印日志。如果data对象为null,那么在调用toString()方法时会抛出空指针异常,影响正常的业务流程。
public void doSomeThing() {
log.info("doSomeThing and print log, data={}", data.toString());
// 业务逻辑
...
}
正例:
在打印之前需要判空,或者使用Apache的ToStringBuilder工具,或者自定义toString()方法。
public void doSomeThing() {
log.info("doSomeThing and print log, data={}", ToStringBuilder.reflectionToString(data, ToStringStyle.SHORT_PREFIX_STYLE));
// 业务逻辑
...
}
public class Data {
private String field1;
private int field2;
// 省略构造方法和其他方法
@Override
public String toString() {
return "Data{" +
"field1='" + field1 + '\'' +
", field2=" + field2 +
'}';
}
}
public void doSomeThing() {
log.info("doSomeThing and print log, data={}", data);
// 业务逻辑
...
}
12.敏感信息需要脱敏
为了保护用户的隐私和防止敏感信息泄露,对于一些敏感的数据,如身份证号、银行卡号等,应该进行脱敏处理,而不是明文打印。
反例:
反例里直接将身份证号idCard明文打印到日志中,这样会导致敏感信息暴露的风险。
public void doSomeThing() {
log.info("doSomeThing and print log, idCard={}", idCard);
// 业务逻辑
...
}
正例:
可以使用脱敏方法对敏感信息进行处理,来防止敏感信息泄露。
public void doSomeThing() {
String maskedIdCard = maskIdCard(idCard);
log.info("do something and print log, idCard={}", maskedIdCard);
// 业务逻辑
...
}
private String maskIdCard(String idCard) {
// 实现脱敏算法,将身份证号进行脱敏处理
// 例如:将前四位和后四位保留,中间的数字用*代替
if (idCard.length() >= 8) {
String prefix = idCard.substring(0, 4);
String suffix = idCard.substring(idCard.length() - 4);
String maskedIdCard = prefix + "****" + suffix;
return maskedIdCard;
}
return idCard;
}
13.建议使用异步的方式来输出日志
为了提升日志的输出性能,特别是在涉及到IO操作的情况下,建议使用异步方式来输出日志。这样可以减少IO操作的阻塞时间,提升系统的整体性能。
以logback为例,可以使用AsyncAppender来配置异步输出日志。
<appender name="FILE_ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="ASYNC"/>
</appender>
14.不要使用e.printStackTrace()
使用e.printStackTrace()存在两个问题:
e.printStackTrace()打印出的堆栈日志跟业务代码日志是交错混合在一起的,通常排查异常日志不太方便。e.printStackTrace()语句产生的字符串记录的是堆栈信息,如果信息太长太多,字符串常量池所在的内存块没有空间了,即内存满了,那么用户的请求就可能被阻塞。
正例:
应该使用日志记录框架,如logback或log4j,来打印异常信息。
try {
// 业务代码处理
} catch (Exception e) {
log.error("An error occurred:", e);
}
15.异常日志打印完整堆栈
反例:
异常日志没有打印完整的堆栈信息,无法提供足够的信息来排查问题。
try {
// 业务代码处理
} catch (Exception e) {
// 错误
LOG.error("An error occurred:");
}
正例:
为了打印完整的堆栈信息,我们可以使用日志记录框架提供的方法,将异常对象作为参数传递给日志记录方法。
try {
// 业务代码处理
} catch (Exception e) {
log.error("An error occurred:", e);
}
另外,需要注意的是,使用e.getMessage()方法只能获取到异常的基本描述信息,而无法获取到完整的堆栈信息。如果需要打印完整的堆栈信息,应该使用日志记录框架提供的方法。
16.不要嵌套异常
嵌套异常会导致异常的捕获和处理变得混乱,增加问题排查的难度。在编写方法或类之前,需要提前考虑异常的处理方式,并及时回顾代码以确保异常的正确处理。
反例:
异常被嵌套捕获,导致外层的异常无法获取到真正的异常信息。
try {
// 业务代码处理
try {
// 业务代码处理
} catch (Exception e) {
log.error("Your program has an exception", e);
}
} catch (Exception e) {
log.error("Your program has an exception", e);
}
正例:
为了避免嵌套异常,我们应该在合适的地方捕获和处理异常,并将异常信息记录下来。
try {
// 业务代码处理
} catch (Exception e) {
log.error("Your program has an exception", e);
}
17.不要记录异常又抛出
记录异常后又抛出异常是一种危险的做法。外层可能不会再次处理内层抛出的异常,导致问题无法得到正确的处理。此外,这样做还会导致堆栈信息被重复打印,浪费系统性能。
反例:
下面的反例中,异常被记录后又抛出了自定义异常。这样做的问题在于,外层可能不会再次处理内层抛出的异常,导致问题得不到正确的处理。
try {
// 业务代码处理
} catch (Exception e) {
log.error("IO exception", e);
throw new MyException(e);
}
18.建议对日志配置告警
如果接入了日志分析工具,建议对日志进行告警配置。当错误日志数量超过设定的阈值时,可以及时发送告警通知,方便及时感知和排查问题。这样可以帮助我们快速发现和解决潜在的系统问题。
19.避免重复打印日志
为了提高日志的可读性和简洁性,应尽量避免重复打印日志。如果多个日志可以合并为一行来表示,可以将它们合并在一起,以减少冗余的日志输出。
反例:
log.info("User is vip, Id: {}", user);
// 冗余,可以跟前面的日志合并一起
log.info("Start solve vip, Id: {}", user);
20.不要打印无意义的日志
为了提高日志的可读性和实用性,应避免打印无意义的日志信息。无意义的日志指的是缺乏业务上下文或无关联日志链路ID的日志。
反例:
public void doSomeThing() {
log.info("doSomeThing and print log"); // 无业务信息的日志
// 业务逻辑
...
}
public void doSomeThing() {
doIt1();
log.info("doSomeThing 111"); // 无关联日志链路ID的日志
doIt2();
log.info("doSomeThing 222"); // 无关联日志链路ID的日志
}
正例:
下面是一个正例,展示了有意义的日志打印情况:
public void doSomeThing() {
log.info("doSomeThing and print log, id={}", id); // 带有相关的业务信息的日志
// 业务逻辑
...
}
在打印日志时,需要注意:
- 确保日志信息具有实际的业务意义,能够帮助理解和定位问题。
- 如果存在大量无意义的日志信息,可以考虑删除或以debug级别打印,以避免日志过于冗杂。
21.不要在循环中打印 INFO 级别日志
在循环中打印 INFO 级别的日志可能会导致日志输出过于冗杂,影响系统性能。因此,应避免在循环中打印大量的 INFO 级别日志。
反例:
下面是一个反例,展示了在循环中打印 INFO 级别日志的情况:
public void doSomeThing() {
for(String s : strList) {
log.info("doSomeThing and print log: {}", s);
// 业务逻辑
...
}
}
22.对于 trace/debug 级别的日志输出,必须要有开关
为了避免在配置了较高日志级别时产生不必要的日志输出,应在输出 trace/debug级别的日志之前进行相应级别的日志开关判断。
反例:
下面是一个反例,展示了没有进行日志级别开关判断的情况:
public void doSomeThing() {
String name = "xxx";
logger.trace("print debug log" + name);
logger.debug("print debug log" + name);
// 业务逻辑
...
}
正例:
为了避免不必要的日志输出,应在输出 trace/debug/info 级别的日志之前进行相应级别的日志开关判断。通常,可以将开关判断逻辑封装在日志工具类中,以实现统一的处理。
public void doSomeThing() {
String name = "xxx";
if (logger.isTraceEnabled()) {
logger.trace("print trace log {}", name);
}
if (logger.isDebugEnabled()) {
logger.debug("print debug log {}", name);
}
// 业务逻辑
...
}
好了,这就是本期的全部内容了,希望大家在工作中一定要好好打日志,宁愿多打,也不要少打,毕竟省的日志那一星半点,还不够一次事故的损失。
参考:
[1].https://xie.infoq.cn/article/c7e46aa4bd7de3edb855c1f29
[2].https://juejin.cn/post/7010889983149998117
[3].https://segmentfault.com/a/1190000043203675
[4].https://cloud.tencent.com/developer/article/1559519