作者:JOE MCELROY
什么是检索增强生成 (RAG) 以及该技术如何通过提供相关源知识作为上下文来帮助提高 LLMs 生成的响应的质量。

生成式人工智能最近取得了巨大的成功和令人兴奋的成果,其模型可以生成流畅的文本、逼真的图像,甚至视频。 就语言而言,经过大量数据训练的大型语言模型能够理解上下文并对问题生成相关响应。

生成式人工智能 (Generative AI) 的挑战
然而,重要的是要了解这些模型并不完美。 这些模型拥有的知识是它们在训练过程中学到的参数知识,是整个训练数据集的浓缩表示。
缺乏领域知识
这些模型应该能够对训练数据中有关常识的问题产生良好的响应。 但他们无法可靠地回答有关训练数据集中不存在的事实的问题。 如果模型很好地对齐自己已经知道的知识,它将拒绝回答此类域外问题。 然而,它也有可能只是编造答案(也称为幻觉)。 例如,通用模型通常会笼统地理解每个公司都有休假政策,但它不会了解我的特定公司的休假政策。
冻结的参数知识
LLMs 的知识是冻结的,这意味着它对培训后发生的事件一无所知。 这意味着它将无法可靠地回答有关当前事件的问题。 模型通常经过训练来验证他们对此类问题给出的答案。

幻觉
有人建议 LLMs 在其参数中捕获类似于一般本体论的知识图表示的东西:表示有关实体的事实和实体之间的关系。 训练数据中频繁出现的常见事实在知识图中得到了很好的体现。 然而,小生态范围的知识鲜少在训练数据中有很多例子,它只能被近似地体现,知识仅被近似地表示。 因此, LLMs 对这些事实的理解很混乱。 校准过程至关重要,模型根据其已知信息进行校准。 错误经常发生在已知信息和未知信息之间的灰色地带,凸显了区分相关细节的挑战。

在上面的例子中,关于与 Borcherds 同年的菲尔兹奖获得者的问题是此类小范围知识的一个典型例子。 在这种情况下,我们在对话中植入了有关其他数学家的信息,而 ChatGPT 似乎对要关注哪些信息感到困惑。 例如,它错过了蒂姆·高尔斯(Tim Gowers)并加入了弗拉基米尔·沃耶夫斯基(Vladimir Voevodsky)(2002年获胜)。
训练费用昂贵
虽然 LLMs 在特定领域内的数据训练时能够对问题生成相关答案,但它们的训练成本很高,并且需要大量数据和计算来开发。 同样,微调模型需要专业知识和时间,并且在此过程中存在 “忘记” 其他重要功能的风险。
RAG如何帮助解决这个问题?
检索增强生成(RAG)通过将生成模型的参数知识与来自数据库等信息检索系统的外部源知识作为基础,帮助解决这个问题。 这些源知识作为附加上下文传递给模型,并帮助模型生成对问题更相关的响应。
RAG 是如何运作的?
RAG 管道通常具有三个主要组件:

- Data:包含回答问题的相关信息的数据集合(例如文档、网页)。
- Retrieval:可以从数据中检索相关源知识的检索策略。
- Generation:利用相关的来源知识,在 LLM 的帮助下生成响应。
RAG 管道流程
当直接与模型交互时,LLM 会收到一个问题,并根据其参数知识生成响应。 RAG 在管道中添加了一个额外的步骤,使用检索来查找相关数据,为 LLM 构建额外的背景。
在下面的示例中,我们使用密集向量检索策略从数据中检索相关源知识。 然后,该源知识将作为上下文传递给 LLM 以生成响应。
RAG 不必使用密集向量检索,它可以使用任何能够从数据中检索相关源知识的检索策略。 它可以是简单的关键字搜索,甚至可以是 Google 网络搜索。
我们将在以后的文章中介绍其他检索策略。

检索源知识
检索相关源知识是有效回答问题的关键。
使用生成式 AI 进行检索的最常见方法是使用密集向量的语义搜索。 语义搜索是一种需要嵌入模型将自然语言输入转换为表示源知识的密集向量的技术。 我们依靠这些密集向量来表示源知识,因为它们能够捕获文本的语义。 这很重要,因为它允许我们将源知识的语义与问题进行比较,以确定源知识是否与问题相关。

给定一个问题及其嵌入,我们可以找到最相关的源知识。

使用密集向量进行语义搜索并不是唯一的检索选项,但它是当今最流行的方法之一。 我们将在以后的文章中介绍其他方法。
RAG 的优点
训练结束后,LLMs 将被冻结。 模型的参数知识是固定的,无法更新。 然而,当我们向 RAG 管道添加数据和检索时,我们可以随着底层数据源的变化更新源知识,而无需重新训练模型。
以源头知识为基础
模型的响应也可以限制为仅使用上下文中提供的源知识,这有助于限制幻觉。 这种方法还提供了使用较小的、特定于任务的 LLMs 而不是大型的通用模型的选择。 这使得能够优先使用源知识来回答问题,而不是在培训期间获得的一般知识。
在回复中引用来源
此外,RAG 还可以提供用于回答问题的源知识的清晰可追溯性。 这对于合规性和监管原因非常重要,也有助于发现 LLM 的幻觉。 这称为源跟踪。
RAG 实践
一旦我们检索到相关的源知识,我们就可以用它来生成对问题的回答。 为此,我们需要:
构建上下文
包含回答问题的相关信息的源知识(例如文档、网页)的集合。 这为模型生成响应提供了上下文。
提示模板
针对特定任务(回答问题、总结文本)用自然语言编写的模板。 用作 LLM 的输入。
问题
与任务相关的问题。
一旦我们有了这三个组成部分,我们就可以使用 LLM 来生成对问题的回答。 在下面的示例中,我们将提示模板与用户的问题以及检索到的相关段落结合起来。 提示模板将相关的源知识段落构建到上下文中。
此示例还包括源追踪,其中在响应中引用了源知识段落。
Given the following extracted parts of a long document and a question, create an answer with references ("SOURCES").
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
ALWAYS return a "SOURCES" part in your answer.
Question: "Which state/country's law governs the interpretation of the contract?"
=========
Content: This Agreement is governed by English law and the parties submit to the exclusive jurisdiction of the English courts in relation to any dispute (contractual or non-contractual) concerning this Agreement save that either party may apply to any court for an injunction or other relief to protect its Intellectual Property Rights.
Reference: 28-pl
Content: No Waiver. Failure or delay in exercising any right or remedy under this Agreement shall not constitute a waiver of such (or any other) right or remedy.\n\n11.7 Severability. The invalidity, illegality or unenforceability of any term (or part of a term) of this Agreement shall not affect the continuation in force of the remainder of the term (if any) and this Agreement.\n\n11.8 No Agency. Except as expressly stated otherwise, nothing in this Agreement shall create an agency, partnership or joint venture of any kind between the parties.\n\n11.9 No Third-Party Beneficiaries.
Reference: 30-pl
Content: (b) if Google believes, in good faith, that the Distributor has violated or caused Google to violate any Anti-Bribery Laws (as defined in Clause 8.5) or that such a violation is reasonably likely to occur,
Reference: 4-pl
=========RAG 面临的挑战
有效的检索是有效回答问题的关键。 良好的检索可以提供与上下文相关的多种源知识。 然而,这更多的是一门艺术而不是一门科学,需要大量的实验才能正确,并且高度依赖于用例。
精确密集向量
大型文档很难表示为单个密集向量,因为它们包含多种语义。 为了有效检索,我们需要将文档分解为更小的文本块,这些文本块可以准确地表示为单个密集向量。
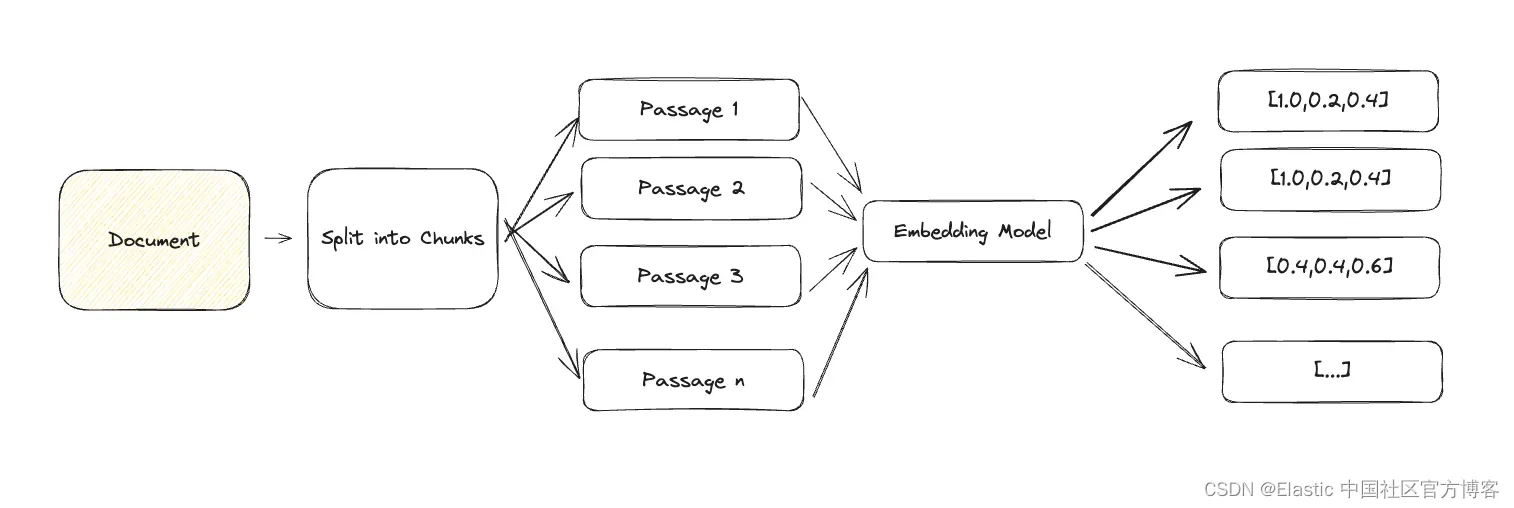
通用文本的常见方法是按段落进行分块并将每个段落表示为密集向量。 根据你的用例,你可能希望使用 titles、headings 甚至句子将文档分解为块。
大上下文(context)
使用 LLMs 时,我们需要注意传递给模型的上下文的大小。
LLMs 对其一次可以处理的 token 数量有限制。 例如,GPT-3.5-turbo 的限制为 4096 个 token。
其次,随着上下文的增加,生成的响应质量可能会下降,从而增加产生幻觉的风险。
更大的上下文也需要更多的时间来处理,最重要的是,它们会增加 LLM 的成本。
这又回到了检索的艺术。 我们需要在分块大小和嵌入的准确性之间找到适当的平衡。
结论
检索增强生成是一种强大的技术,可以通过提供相关源知识作为上下文来帮助提高 LLM 生成的响应的质量。 但 RAG 并不是灵丹妙药。 它需要大量的实验和调整才能正确,并且还高度依赖于你的用例。
在下一篇文章中,我们将介绍如何使用 LangChain(一种用于 LLM 的流行框架)构建 RAG 管道。
原文:Retrieval Augmented Generation (RAG) — Elastic Search Labs