1.游戏玩法分析
SQL
Create table If Not Exists Activity (player_id int, device_id int, event_date date, games_played int);
Truncate table Activity;
insert into Activity (player_id, device_id, event_date, games_played) values ('1', '2', '2016-03-01', '5');
insert into Activity (player_id, device_id, event_date, games_played) values ('1', '2', '2016-03-02', '6');
insert into Activity (player_id, device_id, event_date, games_played) values ('2', '3', '2017-06-25', '1');
insert into Activity (player_id, device_id, event_date, games_played) values ('3', '1', '2016-03-02', '0');
insert into Activity (player_id, device_id, event_date, games_played) values ('3', '4', '2018-07-03', '5');
Table: Activity
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| player_id | int |
| device_id | int |
| event_date | date |
| games_played | int |
+--------------+---------+
(player_id,event_date)是此表的主键(具有唯一值的列的组合)。
这张表显示了某些游戏的玩家的活动情况。
每一行是一个玩家的记录,他在某一天使用某个设备注销之前登录并玩了很多游戏(可能是 0)。
编写解决方案,报告在首次登录的第二天再次登录的玩家的 比率,四舍五入到小数点后两位。换句话说,你需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数。
结果格式如下所示:
示例 1:
输入:
Activity table:
+-----------+-----------+------------+--------------+
| player_id | device_id | event_date | games_played |
+-----------+-----------+------------+--------------+
| 1 | 2 | 2016-03-01 | 5 |
| 1 | 2 | 2016-03-02 | 6 |
| 2 | 3 | 2017-06-25 | 1 |
| 3 | 1 | 2016-03-02 | 0 |
| 3 | 4 | 2018-07-03 | 5 |
+-----------+-----------+------------+--------------+
输出:
+-----------+
| fraction |
+-----------+
| 0.33 |
+-----------+
解释:
只有 ID 为 1 的玩家在第一天登录后才重新登录,所以答案是 1/3 = 0.33
思路
1.获取每个用户第一次登录时间
2.连接Activity表
3.计算event_date的差值为1的记录
4.排除没有连续登录的记录
题解
select round(avg(t2.event_date is not null), 2) fraction
from (
-- 获取第一天
select player_id,min(event_date)event_date
from Activity
group by player_id
) t1
left join Activity t2
on t1.player_id=t2.player_id and datediff(t2.event_date,t1.event_date) =1
2.至少有5名直接下属的经理
SQL
Create table If Not Exists Employee (id int, name varchar(255), department varchar(255), managerId int);
Truncate table Employee;
insert into Employee (id, name, department, managerId) values ('101', 'John', 'A', '0');
insert into Employee (id, name, department, managerId) values ('102', 'Dan', 'A', '101');
insert into Employee (id, name, department, managerId) values ('103', 'James', 'A', '101');
insert into Employee (id, name, department, managerId) values ('104', 'Amy', 'A', '101');
insert into Employee (id, name, department, managerId) values ('105', 'Anne', 'A', '101');
insert into Employee (id, name, department, managerId) values ('106', 'Ron', 'B', '101');
表: Employee
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
| department | varchar |
| managerId | int |
+-------------+---------+
在 SQL 中,id 是该表的主键列。
该表的每一行都表示雇员的名字、他们的部门和他们的经理的id。
如果managerId为空,则该员工没有经理。
没有员工会成为自己的管理者。
查询至少有5名直接下属的经理 。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:
Employee 表:
+-----+-------+------------+-----------+
| id | name | department | managerId |
+-----+-------+------------+-----------+
| 101 | John | A | None |
| 102 | Dan | A | 101 |
| 103 | James | A | 101 |
| 104 | Amy | A | 101 |
| 105 | Anne | A | 101 |
| 106 | Ron | B | 101 |
+-----+-------+------------+-----------+
输出:
+------+
| name |
+------+
| John |
+------+
思路
1.获取每个经理下的员工
2.通过连表的方式进行连接
3.筛选出有5名直接下属的经理
题解
方式一:
-- 2.查询至少有5名直接下属的经理
select name
from
(
-- 1.两个连接
select t1.name,count(distinct t2.id) distinctId
from employee t1
left join employee t2
on t1.id=t2.managerId
group by t1.id
)t
where distinctId>=5
方式二:
-- 1.两个连接
select t1.name,count(distinct t2.id) distinctId
from employee t1
left join employee t2
on t1.id=t2.managerId
group by t1.id
-- 2.查询至少有5名直接下属的经理
having distinctId>=5
3.2016的投资
SQL
Create Table If Not Exists Insurance (pid int, tiv_2015 float, tiv_2016 float, lat float, lon float);
Truncate table Insurance;
INSERT INTO Insurance (pid, tiv_2015, tiv_2016, lat, lon) VALUES
(1, 224.17, 952.73, 32.4, 20.2),
(2, 224.17, 900.66, 52.4, 32.7),
(3, 824.61, 645.13, 72.4, 45.2),
(4, 424.32, 323.66, 12.4, 7.7),
(5, 424.32, 282.9, 12.4, 7.7),
(6, 625.05, 243.53, 52.5, 32.8),
(7, 424.32, 968.94, 72.5, 45.3),
(8, 624.46, 714.13, 12.5, 7.8),
(9, 425.49, 463.85, 32.5, 20.3),
(10, 624.46, 776.85, 12.4, 7.7),
(11, 624.46, 692.71, 72.5, 45.3),
(12, 225.93, 933, 12.5, 7.8),
(13, 824.61, 786.86, 32.6, 20.3),
(14, 824.61, 935.34, 52.6, 32.8);
Insurance 表:
+-------------+-------+
| Column Name | Type |
+-------------+-------+
| pid | int |
| tiv_2015 | float |
| tiv_2016 | float |
| lat | float |
| lon | float |
+-------------+-------+
pid 是这张表的主键(具有唯一值的列)。
表中的每一行都包含一条保险信息,其中:
pid 是投保人的投保编号。
tiv_2015 是该投保人在 2015 年的总投保金额,tiv_2016 是该投保人在 2016 年的总投保金额。
lat 是投保人所在城市的纬度。题目数据确保 lat 不为空。
lon 是投保人所在城市的经度。题目数据确保 lon 不为空。
编写解决方案报告 2016 年 (tiv_2016) 所有满足下述条件的投保人的投保金额之和:
- 他在 2015 年的投保额 (
tiv_2015) 至少跟一个其他投保人在 2015 年的投保额相同。 - 他所在的城市必须与其他投保人都不同(也就是说 (
lat, lon) 不能跟其他任何一个投保人完全相同)。
tiv_2016 四舍五入的 两位小数 。
查询结果格式如下例所示。
示例 1:
输入:
Insurance 表:
| pid | tiv_2015 | tiv_2016 | lat | lon |
| --- | -------- | -------- | ---- | ---- |
| 1 | 224.17 | 952.73 | 32.4 | 20.2 |
| 2 | 224.17 | 900.66 | 52.4 | 32.7 |
| 3 | 824.61 | 645.13 | 72.4 | 45.2 |
| 4 | 424.32 | 323.66 | 12.4 | 7.7 |
| 5 | 424.32 | 282.9 | 12.4 | 7.7 |
| 6 | 625.05 | 243.53 | 52.5 | 32.8 |
| 7 | 424.32 | 968.94 | 72.5 | 45.3 |
| 8 | 624.46 | 714.13 | 12.5 | 7.8 |
| 9 | 425.49 | 463.85 | 32.5 | 20.3 |
| 10 | 624.46 | 776.85 | 12.4 | 7.7 |
| 11 | 624.46 | 692.71 | 72.5 | 45.3 |
| 12 | 225.93 | 933 | 12.5 | 7.8 |
| 13 | 824.61 | 786.86 | 32.6 | 20.3 |
| 14 | 824.61 | 935.34 | 52.6 | 32.8 |
+-----+----------+----------+-----+-----+
输出:
+----------+
| tiv_2016 |
+----------+
| 4220.72 |
+----------+
解释:
表中的第一条记录和最后一条记录都满足两个条件。
tiv_2015 值为 10 与第三条和第四条记录相同,且其位置是唯一的。
第二条记录不符合任何一个条件。其 tiv_2015 与其他投保人不同,并且位置与第三条记录相同,这也导致了第三条记录不符合题目要求。
因此,结果是第一条记录和最后一条记录的 tiv_2016 之和,即 45 。
思路
1.获取tiv_2015相同投保额的次数超过1
2.获取所在的城市经纬度不一样
题解
方式一:
SELECT
round(SUM(insurance.TIV_2016),2) AS TIV_2016
FROM
insurance
WHERE
insurance.TIV_2015 IN
(
SELECT
TIV_2015
FROM
insurance
GROUP BY TIV_2015
HAVING COUNT(*) > 1
)
AND CONCAT(LAT, LON) IN
(
SELECT
CONCAT(LAT, LON)
FROM
insurance
GROUP BY LAT , LON
HAVING COUNT(*) = 1
);
方式二:
SELECT
ROUND( SUM( tiv_2016 ), 2 ) tiv_2016
FROM
( SELECT *, COUNT(*) OVER ( PARTITION BY tiv_2015 ) cnt_tiv_2015, COUNT(*) OVER ( PARTITION BY lat, lon ) cnt_lat FROM Insurance ) t
WHERE
cnt_tiv_2015 > 1
AND cnt_lat =1
4.好友申请:谁有最多的好友
SQL
Create table If Not Exists RequestAccepted (requester_id int not null, accepter_id int null, accept_date date null);
Truncate table RequestAccepted;
insert into RequestAccepted (requester_id, accepter_id, accept_date) values ('1', '2', '2016/06/03');
insert into RequestAccepted (requester_id, accepter_id, accept_date) values ('1', '3', '2016/06/08');
insert into RequestAccepted (requester_id, accepter_id, accept_date) values ('2', '3', '2016/06/08');
insert into RequestAccepted (requester_id, accepter_id, accept_date) values ('3', '4', '2016/06/09');
RequestAccepted 表:
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| requester_id | int |
| accepter_id | int |
| accept_date | date |
+----------------+---------+
(requester_id, accepter_id) 是这张表的主键(具有唯一值的列的组合)。
这张表包含发送好友请求的人的 ID ,接收好友请求的人的 ID ,以及好友请求通过的日期。
编写解决方案,找出拥有最多的好友的人和他拥有的好友数目。
生成的测试用例保证拥有最多好友数目的只有 1 个人。
查询结果格式如下例所示。
示例 1:
输入:
RequestAccepted 表:
+--------------+-------------+-------------+
| requester_id | accepter_id | accept_date |
+--------------+-------------+-------------+
| 1 | 2 | 2016/06/03 |
| 1 | 3 | 2016/06/08 |
| 2 | 3 | 2016/06/08 |
| 3 | 4 | 2016/06/09 |
+--------------+-------------+-------------+
输出:
+----+-----+
| id | num |
+----+-----+
| 3 | 3 |
+----+-----+
解释:
编号为 3 的人是编号为 1 ,2 和 4 的人的好友,所以他总共有 3 个好友,比其他人都多。
思路
成为朋友是一个双向的过程,所以如果一个人接受了另一个人的请求,他们两个都会多拥有一个朋友。
所以我们可以将 requester_id 和 accepter_id 联合起来,然后统计每个人出现的次数。
1.使用union拼接两个表结果
题解
方式一:
select id, sum(count_id)num
from
(
select requester_id id,count(requester_id) count_id
from RequestAccepted
group by requester_id
union all
select accepter_id id,count(accepter_id) count_id
from RequestAccepted
group by accepter_id
)t
group by id
order by sum(count_id) desc
limit 1
方式二:
select id, count(id)num
from
(
select requester_id id
from RequestAccepted
union all
select accepter_id id
from RequestAccepted
)t
group by id
order by num desc
limit 1
5.树节点
SQL
Create table If Not Exists Tree (id int, p_id int);
Truncate table Tree;
insert into Tree (id, p_id) values ('1', null);
insert into Tree (id, p_id) values ('2', '1');
insert into Tree (id, p_id) values ('3', '1');
insert into Tree (id, p_id) values ('4', '2');
insert into Tree (id, p_id) values ('5', '2');
表:Tree
+-------------+------+
| Column Name | Type |
+-------------+------+
| id | int |
| p_id | int |
+-------------+------+
id 是该表中具有唯一值的列。
该表的每行包含树中节点的 id 及其父节点的 id 信息。
给定的结构总是一个有效的树。
树中的每个节点可以是以下三种类型之一:
- “Leaf”:节点是叶子节点。
- “Root”:节点是树的根节点。
- “lnner”:节点既不是叶子节点也不是根节点。
编写一个解决方案来报告树中每个节点的类型。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
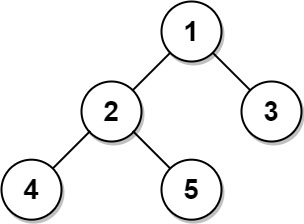
输入:
Tree table:
+----+------+
| id | p_id |
+----+------+
| 1 | null |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
+----+------+
输出:
+----+-------+
| id | type |
+----+-------+
| 1 | Root |
| 2 | Inner |
| 3 | Leaf |
| 4 | Leaf |
| 5 | Leaf |
+----+-------+
解释:
节点 1 是根节点,因为它的父节点为空,并且它有子节点 2 和 3。
节点 2 是一个内部节点,因为它有父节点 1 和子节点 4 和 5。
节点 3、4 和 5 是叶子节点,因为它们有父节点而没有子节点。
示例 2:

输入:
Tree table:
+----+------+
| id | p_id |
+----+------+
| 1 | null |
+----+------+
输出:
+----+-------+
| id | type |
+----+-------+
| 1 | Root |
+----+-------+
解释:如果树中只有一个节点,则只需要输出其根属性
思路
我们可以按照下面的定义,求出每一条记录的节点类型。
Root: 没有父节点
Inner: 它是某些节点的父节点,且有非空的父节点
Leaf: 除了上述两种情况以外的节点
题解
SELECT
id AS `Id`,
CASE
WHEN tree.id = (SELECT a.id FROM tree a WHERE a.p_id IS NULL)
THEN 'Root'
WHEN tree.id IN (SELECT a.p_id FROM tree a)
THEN 'Inner'
ELSE 'Leaf'
END AS Type
FROM
tree
ORDER BY `Id`;
null |
±—±-----+
输出:
±—±------+
| id | type |
±—±------+
| 1 | Root |
±—±------+
解释:如果树中只有一个节点,则只需要输出其根属性
**思路**
```sql
我们可以按照下面的定义,求出每一条记录的节点类型。
Root: 没有父节点
Inner: 它是某些节点的父节点,且有非空的父节点
Leaf: 除了上述两种情况以外的节点
题解
SELECT
id AS `Id`,
CASE
WHEN tree.id = (SELECT a.id FROM tree a WHERE a.p_id IS NULL)
THEN 'Root'
WHEN tree.id IN (SELECT a.p_id FROM tree a)
THEN 'Inner'
ELSE 'Leaf'
END AS Type
FROM
tree
ORDER BY `Id`;