MediaPipe Hands:On-device Real-time Hand Tracking
MediaPipe手势:设备上的实时手势跟踪
论文地址:2006.10214.pdf (arxiv.org)
源码地址:GitHub - vidursatija/BlazePalm: PyTorch
目录
摘要
介绍
架构
BlazePalm Detector
Hand Landmark Model
Dataset and Annotation
Result
Implementation in MediaPipe
Application examples
结论
代码
1 摘要
我们提出了一种实时的设备手跟踪解决方案,该解决方案可以从AR/VR应用的单个RGB相机预测人类的手骨架。我们的管道由两个模型组成:
- 1)手掌检测器,它为手掌提供一个边界框;
- 2)hand landmarks 模型,它预测手掌骨架。
它是通过MediaPipe[12]实现的,这是一个用于构建跨平台ML解决方案的框架。所提出的模型和流水线结构证明了移动GPU上的实时推理速度和高预测质量。MediaPipe Hands的源代码为MediaPipe Studio (google.com).
[12] Camillo Lugaresi,Jiuqiang Tang,Hadon Nash,Chris Mc-Clanahan,Esha Uboweja,Michael Hays,Fan Zhang,Chuo-Ling Chang,Ming Guang Yong,Juhyun Lee,Wan-TehChang,Wei Hua,Manfred Georg,and Matthias Grundmann.Mediapipe:A framework for building perception pipelines.volume abs/1906.08172,2019.

图1:渲染的手跟踪结果
- (左):用不同色调呈现相对深度的hand landmarks。圆圈越轻、越大,地标就越靠近相机。
- (右):像素3上的实时多手跟踪。
2 介绍
手部跟踪是为AR/VR中的交互和通信提供自然方式的重要组成部分,也是行业中一个活跃的研究课题[2][15]。基于视觉的手部姿态估计已经研究了多年。以前的大部分工作需要专门的硬件,例如深度传感器[13][16][17][3][4]。其他解决方案不够轻,无法在商品移动设备上实时运行[5],因此仅限于配备强大处理器的平台。在本文中,我们提出了一种新的解决方案,该解决方案不需要任何额外的硬件,并在移动设备上实时执行。我们的主要贡献是:
- 一个高效的两阶段手部跟踪管道,可以在移动设备上实时跟踪多只手。
- 一种手部姿势估计模型,能够仅使用RGB输入预测2.5D手部姿势。
- 以及开源手跟踪管道,作为各种平台上的现成解决方案,包括Android、iOS、Web(Tensorflow.js)和台式电脑。
3 架构
我们的手部跟踪解决方案利用了一个ML管道,该管道由两个协同工作的模型组成:
- 一种手掌检测器,对全输入图像进行操作,并通过定向的手边界框定位手掌。
- 在手掌检测器提供的裁剪的手边界框上操作并返回高保真度2.5D界标的手界标模型。
将精确裁剪的手掌图像提供给手部地标模型大大减少了对数据分析(如旋转、平移和缩放)的需求,并使网络能够将其大部分容量用于地标定位的准确性。在实时跟踪场景中,我们从前一帧的地标预测中导出一个边界框,作为当前帧的输入,从而在每一帧上应用检测器。相反,检测器仅应用于第一帧或当手部预测指示手部丢失时。
3.1 BlazePalm Detector
为了检测手部的初始位置,我们使用了一个针对移动实时应用优化的单次检测模型,类似于BlazeFace[1],也可在MediaPipe[12]中获得。检测手部是一项非常复杂的任务:我们的模型必须在大尺度跨度(~20x)的各种手部尺寸上工作,并且能够检测被遮挡和自遮挡的手部。尽管人脸有高对比度的图案,例如眼睛和嘴巴周围,但手上没有这些特征,因此很难单独从视觉特征中可靠地检测到它们。
我们的解决方案使用不同的策略来解决上述挑战。
首先,我们训练手掌检测器而不是手检测器,因为估计手掌和拳头等刚性物体的边界框比检测有关节手指的手要简单得多。此外,由于手掌是较小的对象,非最大值抑制算法即使在双手自遮挡的情况下也能很好地工作,比如握手。此外,手掌可以只使用方形绑定框(SSD)进行建模,忽略其他纵横比,从而将锚的数量减少3~5倍。
其次,我们使用类似于FPN[9]的编码器-解码器特征提取器来实现更大的场景上下文感知,即使对于小对象也是如此。
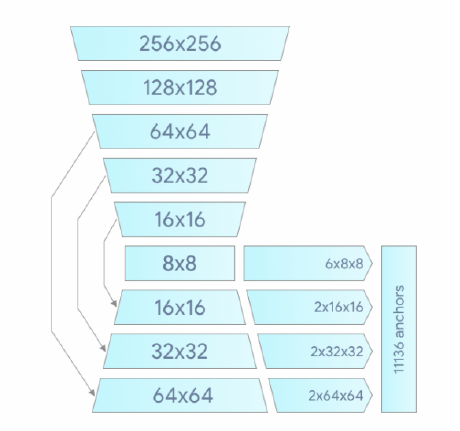
图2:手掌探测器模型架构
最后,我们最大限度地减少了训练过程中的焦点损失(Focal loss for dense object detection),以支持由高尺度方差引起的大量锚。高级手掌探测器架构如图2所示。我们在表1中对我们的设计元素进行了消融研究。
3.2 Hand Landmark Model
在对整个图像进行手掌检测后,我们随后的 hand landmark 模型通过回归对检测到的手部区域内的21个2.5D坐标进行精确的陆地标记定位。该模型学习一致的手部内部姿势表示,即使对部分可见的手部和自遮挡也很稳健。该模型有三个输出(见图3):

图3:我们的手动地标模型的架构。该模型有三个输出,共享一个特征提取器。每个头部都由标记为相同颜色的相应数据集进行训练。详见第2.2节。
- 由x、y和相对深度组成的21个手部标志。
- 指示手在输入图像中存在的概率的手标志。
- 利手性的二元分类,例如左手或右手。
对于21个地标,我们使用与[14]相同的拓扑结构。2D坐标是从真实世界的图像和合成数据集中学习的,如下所述,腕点的相对深度w.r.t.仅从合成图像中学习。为了从跟踪失败中恢复,我们开发了类似于[8]的模型的另一个输出,以降低所提供的作物中确实存在合理对准的手的事件概率。如果分数低于阈值,则检测器被触发以重新跟踪。手性是AR/VR中使用手进行有效交互的另一个重要属性。这对于每只手都与独特功能相关联的一些应用程序尤其有用。因此,我们开发了一个二进制分类头来预测输入手是左手还是右手。我们的设置针对实时移动GPU推理,但我们也设计了更轻和更重的模型版本,以解决移动设备上的CPU推理问题,这些移动设备分别缺乏适当的GPU支持和在桌面上运行的更高精度要求。
4 Dataset and Annotation
为了获得地面实况数据,我们创建了以下数据集来解决问题的不同方面:
- 野外数据集:该数据集包含6K的各种图像,如地理多样性、各种照明条件和手部外观。这个数据集的局限性在于它不包含复杂的手关节。
- 内部收集的手势数据集:该数据集包含10K张图像,涵盖了所有可能的手势的不同角度。这个数据集的局限性在于,它只收集了30个人,背景变化有限。野外数据集和内部数据集相互补充,以提高稳健性。
- 合成数据集:为了更好地覆盖可能的手部姿势并为深度提供额外的监督,我们在各种背景下绘制了一个高质量的合成手部模型,并将其映射到相应的3D坐标。我们使用了一个商业3Dhand模型,该模型配有24块骨头,包括36个混合形状,可以控制手指和手掌的厚度。该模型还提供了5种不同肤色的纹理。我们创建了手部姿势转换的视频序列,并从视频中采样了10万个图像。我们用一个高动态范围的照明环境和三个不同的相机渲染了每个姿势。示例见图4。
对于手掌检测器,我们只在野外数据集中使用,这足以定位手,并且在外观上提供了最高的多样性。然而,所有数据集都用于训练hand landmark模型。我们用21个landmarks对真实世界的图像进行注释,并使用投影的地面实况3D关节来合成图像。对于手的存在,我们选择真实世界图像的子集作为正示例,并在该区域上采样,不包括注释的手区域作为负示例。对于利手性,我们用利手性对一组真实世界的图像进行注释,以提供这样的数据。

图4:我们的数据集示例。
- (顶部):带注释的真实世界图像。
- (底部):带有地面实况注释的渲染合成手图像。详见第3节。
5 Result
对于手部里程碑模型,我们的实验表明,真实世界和合成数据集的组合提供了最佳结果。详见表2。我们只根据真实世界的图像进行评估。除了质量改进之外,使用大型合成数据集进行训练还可以减少帧间的视觉抖动。这一观察结果使我们相信,我们的真实世界数据集可以被放大以更好地泛化。

表1:手掌探测器的消融研究手掌探测器的设计元素(解码器和损失函数)。

表2:我们的模型从不同数据集训练的结果。

表3:手动地标模型性能特征。
我们的目标是在移动设备上实现实时性能。我们对不同尺寸的模型进行了实验,发现“完整”模型(见表3)在质量和速度之间提供了良好的权衡。增加模型容量只会在质量上带来微小的改进,但速度会显著降低(详见表3)。我们使用TensorFlow Lite GPU后端进行设备上推理[6]。
6 Implementation in MediaPipe
使用MediaPipe[12],我们的手跟踪管道可以构建为模块化组件的有向图,称为计算器。Mediapipe提供了一组可扩展的计算器,用于解决各种设备和平台上的模型推理、媒体处理和数据转换等任务。裁剪、渲染和神经网络计算等单独的计算器被进一步优化,以利用GPU加速。例如,我们在大多数现代手机上使用TFLite GPU推理。

图5:当触发手部检测模型时,hand landmark 模型输出控制。这种行为是通过MediaPipes强大的同步构建块实现的,从而实现ML管道的高性能和最佳吞吐量。
我们的手部跟踪MediaPipe图如图5所示。该图由两个子图组成,一个子图用于手部检测,另一子图用于landmark计算。MediaPipe提供的一个关键优化是,手掌可以根据需要检测运行(很少),从而节省大量计算。我们通过从前一帧中计算的手部着陆标记推导当前视频帧中的手部位置来实现这一点,从而无需在每一帧上应用手掌检测器。为了鲁棒性,手跟踪器模型还输出一个额外的标量,该标量捕获手在输入裁剪中存在并合理对齐的置信度。只有当置信度低于某个阈值时,手部检测模型才重新应用于下一帧。
7 Application examples

图6:实时手势识别的屏幕截图。手势的语义呈现在图像的顶部。

图7:基于我们预测的手部骨骼的实时AR效果示例。
我们的手跟踪解决方案可以很容易地用于许多应用,如手势识别和AR效果。在预测的手骨架之上,我们使用一个简单的算法来计算手势,见图6。首先,每个手指的状态,例如弯曲或笔直,是通过关节的累积角度来确定的。然后,我们将一组手指状态映射到一组预定义的手势。这种简单而有效的技术使我们能够以合理的质量估计基本的静态手势。除了静态手势识别之外,还可以使用一系列地标来预测动态手势。另一个应用程序是在骨骼顶部应用AR效果。基于手的AR效果目前很受欢迎。在图7中,我们展示了一个霓虹灯风格的手骨架的AR渲染示例。
8 结论
在本文中,我们提出了MediaPipe Hands,这是一种端到端的手部跟踪解决方案,可在多个平台上实现实时性能。我们的管道在没有任何专门硬件的情况下预测2.5D地标,因此可以轻松地部署到商品设备上。我们开源了该管道,以鼓励研究人员和工程师利用我们的管道构建手势控制和创造性的AR/VR应用程序。
代码
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=2,
min_detection_confidence=0.75,
min_tracking_confidence=0.75)
cap = cv2.VideoCapture(0)
while True:
ret,frame = cap.read()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame= cv2.flip(frame, 1)
results = hands.process(frame)
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
print('hand_landmarks:', hand_landmarks)
mp_drawing.draw_landmarks(
frame, hand_landmarks, mp_hands.HAND_CONNECTIONS)
cv2.imshow('MediaPipe Hands', frame)
if cv2.waitKey(1) & 0xFF == 27:
break
cap.release()
>>> 如有疑问,欢迎评论区一起探讨。











![[linux网络实验] 多网卡绑定](https://img-blog.csdnimg.cn/56c65b6b25ed4dba9165ccf5443ee3b5.png)