文章目录
- [Learning to Speak Fluently in a Foreign Language:Multilingual Speech Synthesis and Cross-Language Voice Cloning](https://arxiv.org/abs/1907.04448)[2019interspeech][google]
- [Improving Cross-lingual Speech Synthesis with Triplet Training Scheme](https://arxiv.org/abs/2202.10729)[2022icassp][喜马拉雅]
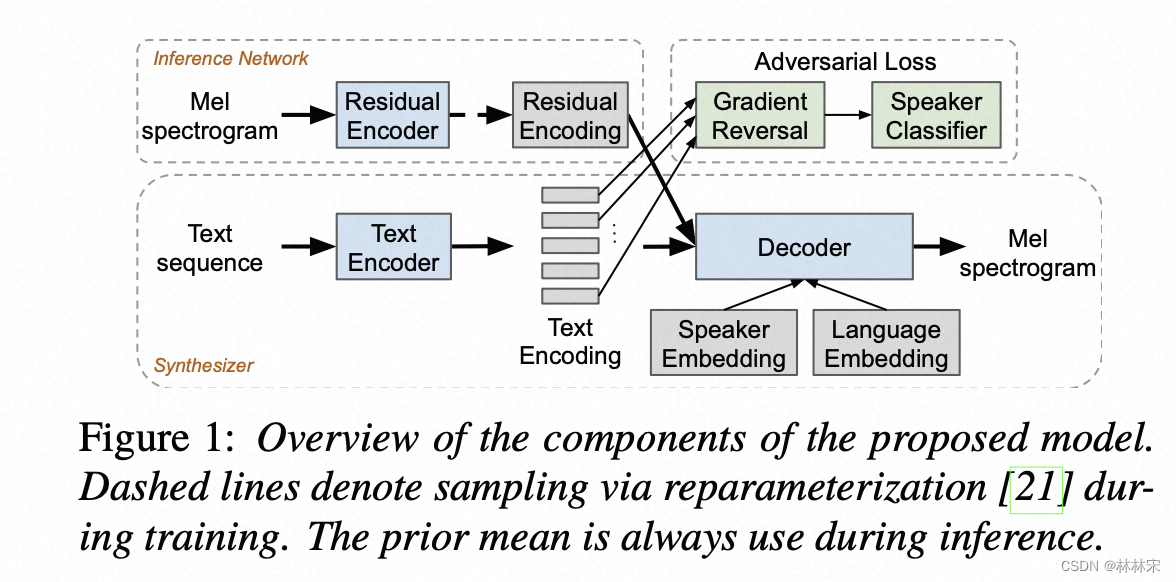
Learning to Speak Fluently in a Foreign Language:Multilingual Speech Synthesis and Cross-Language Voice Cloning[2019interspeech][google]
-
motivation:单语种多语言发音问题
-
核心思想:
- 单个语言增加说话人数目,改善比较明显;
- phn input比utf-8 encoding鲁棒性更强,性能接近;明显优于char encoding;
- text encoder增加对抗训练,对音色相似度和口音native有改善;
- Mel VAE,对效果稳定有提升,dim=16后增加对抗作用不大;
- language id,dim=3,一定的提升,比较次要;
-
结果:
相似语种,英文-西班牙语的音色迁移更容易一些,英文-普通话效果差一些;
音色迁移成功,不代表口音native
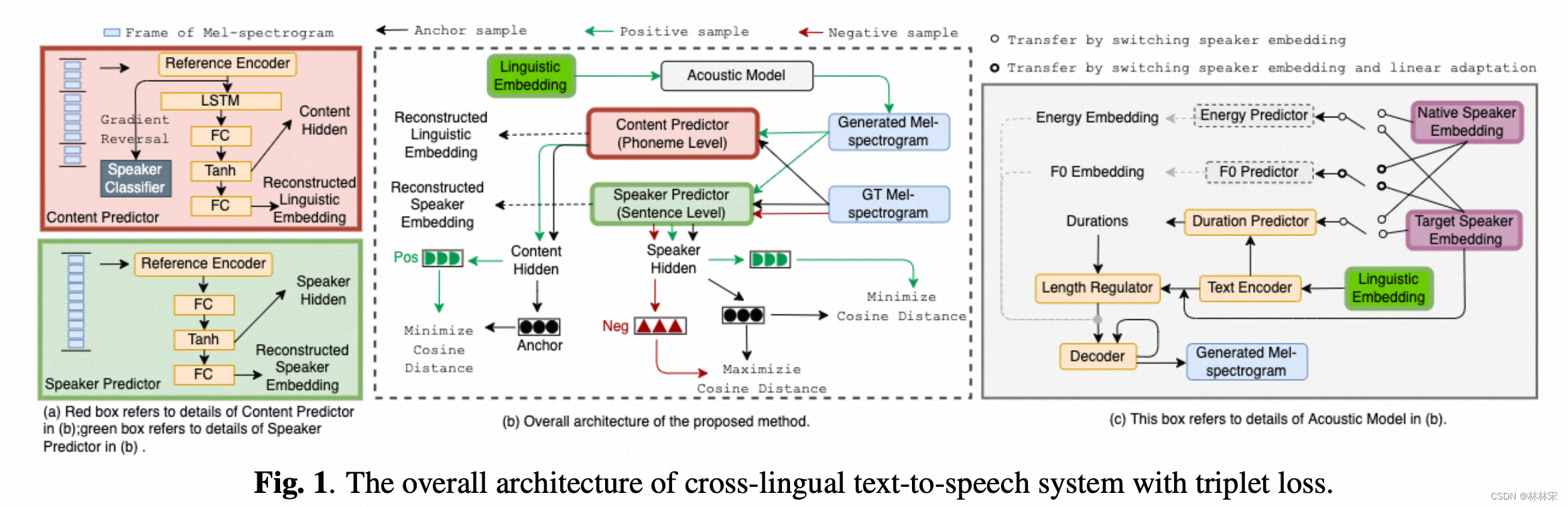
Improving Cross-lingual Speech Synthesis with Triplet Training Scheme[2022icassp][喜马拉雅]
- 背景学习:triplet loss,小样本差别学习
- demo page: FE/DFE实验是在duarin base的基础上加入f0/energy predictor。
- motivation:单语种多语言发音问题进阶,口音要足够native
- 解决思路
- 引入triplet loss,分两阶段训练:
- 第一阶段,正常训练,只是loss项多了CP对抗loss,CP & SP重建损失;
- 第二阶段,content triplet:【anchor,pos,None】,anchor-选择native speaker,且有同样文本;positive sample,非native speaker同样文本生成的 speech;neg,None;speaker triplet【anchor, pos, neg】anchor-native speaker,且有同样文本;positive sample,生成的非native speech;neg,非同样文本仍然是anchor speaker,这样做可以保证学的是口音,保留了音色;
- 没有margin para,因为不需要分类;

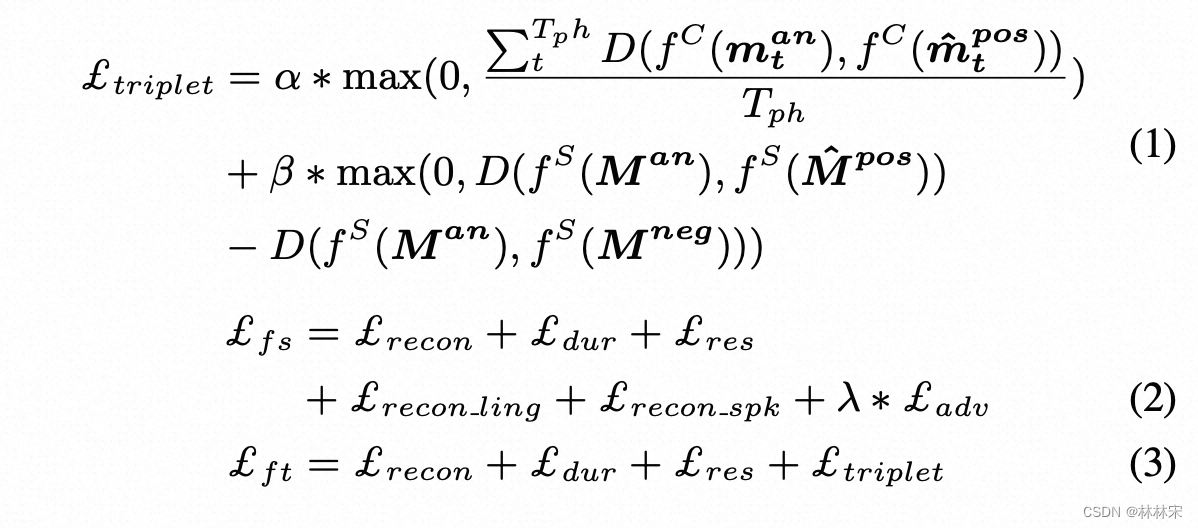
- 引入triplet loss,分两阶段训练: