文章目录
- 0.PID是什么?
- 1.通过代码创建子进程--fork
- 1.1fork()初识
- 1.2通过系统调用创建进程
- 1.3perror()函数的了解
- 2.fork()的进一步了解
- 2.1通过代码了解
- 2.2查看进程的指令
0.PID是什么?
- 进程PID(Process ID)是操作系统为每个正在运行的进程分配的唯一标识符。
- PID是一个整数值,用于在操作系统中唯一标识一个进程。每当一个新的进程被创建时,操作系统会为其分配一个唯一的PID。
- PID在操作系统中起到了重要的作用,它可以用来识别和管理进程。
- 操作系统可以通过PID追踪进程的状态、资源使用情况、与其他进程的关系。
- PID还可以用于进程间通信、进程调度、资源分配等操作。
- 在Linux中,进程PID的数据类型是pid_t,它定义在<sys/types.h>头文件中。pid_t类型是一个有符号整数类型
[实际使用中,PID的值始终是非负整数]
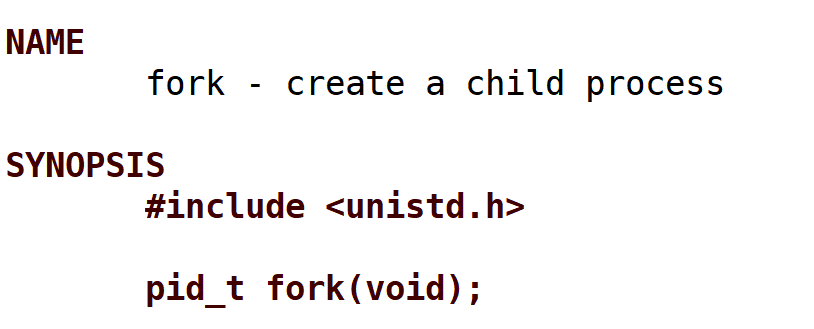
1.通过代码创建子进程–fork
1.1fork()初识
输出
hello linux!
i love you!
int main()
{
printf("hello linux!\n);
printf("i love you!\n);
return 0;
}
输出
hello linux!
i love you!
i love you!
int main()
{
printf("hello linux!\n");
fork();
printf("i love you!\n");
return 0;
}
输出
hello linux!
ret = xxx
ret = 0
int main()
{
printf("hello linux!\n");
pid_t ret = fork();
printf("ret = %d\n", ret);
return 0;
}
1.2通过系统调用创建进程
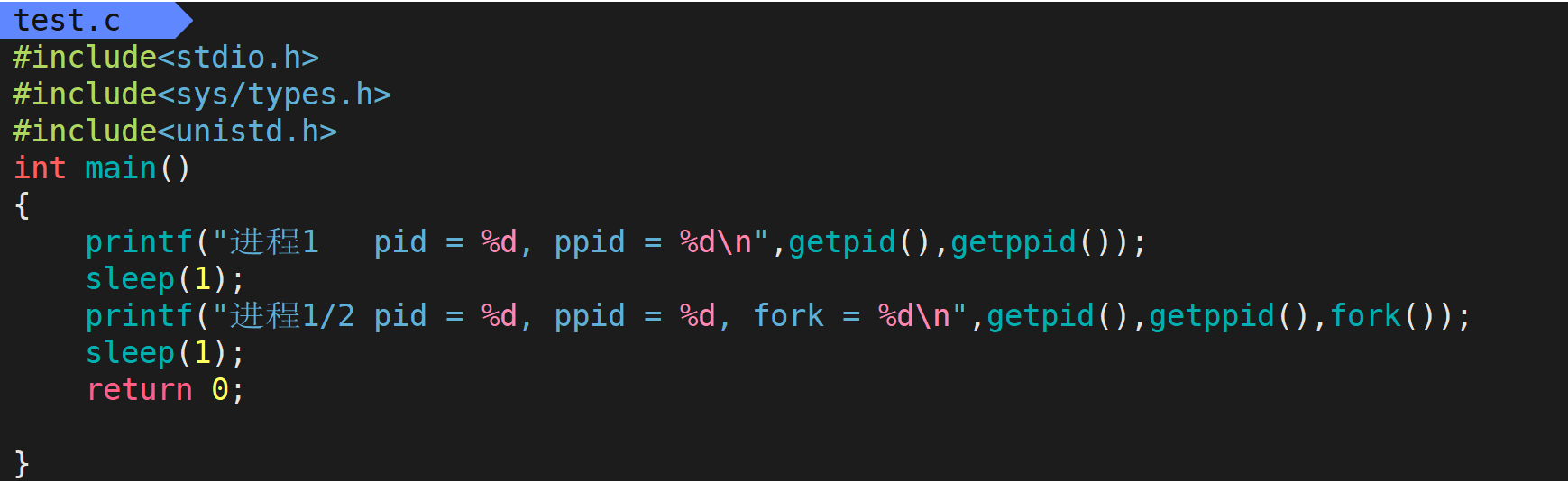

成功 在父进程中返回子进程的PID,在子进程中返回0
失败 在父进程中返回-1,不创建子进程,适当设置errno


1.3perror()函数的了解
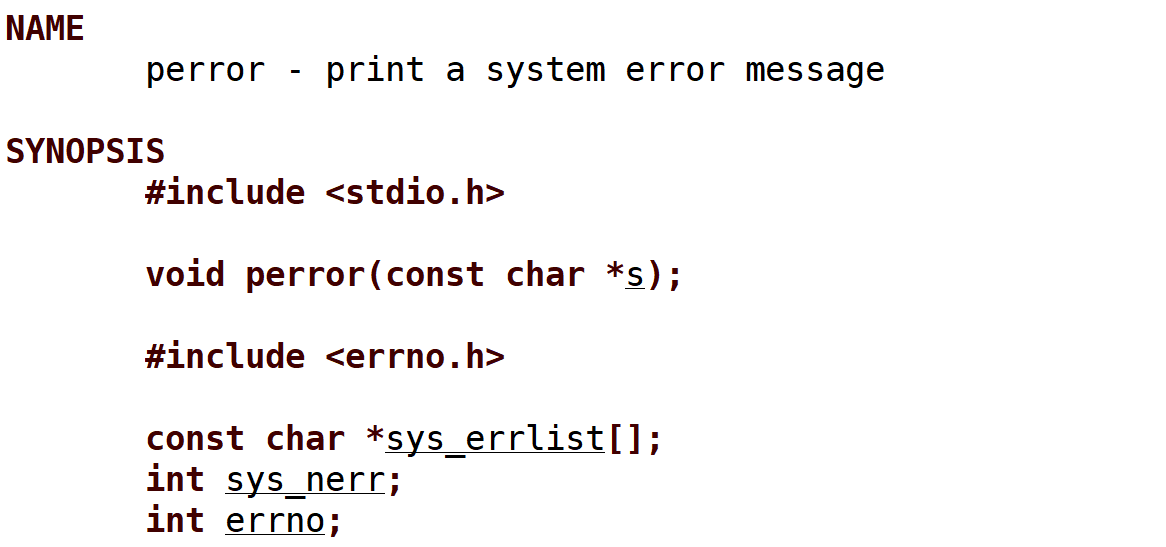
了解
- 打印与最近的错误代码相关的错误消息
- perror() 函数接收一个字符串参数 s,可以是自定义的错误提示信息
- 根据全局变量 errno 中保存的错误代码,将错误消息输出到标准错误流(stderr)
perror()函数的使用
- 在可能出错的操作后显示调用perror()函数
- perror()函数会检查 errno 的值,errno 是一个宏定义的全局变量,表示最近发生错误的错误代码
- 如果 errno 的值表示出现了错误,perror() 函数将根据 errno 的值输出相应的错误消息
举例:
FILE *pfile = fopen("file.txt", "r");
if (file == NULL)
{
perror("fopen");//输出: fopen: ...............
return 1;
}
2.fork()的进一步了解
2.1通过代码了解
- fork()之后 代码是父子共享的
- 虽然共享 但是通过if else 不一定都能执行 共享 != 能执行
int main()
{
pid t id = fork();
if(id< 0)
{
//创建失败perror ("fork") ;
return 1;
}
else if(id == 0)
{
//child process(task)
}
else
{
//parent process
}
printf("you can see me! n") ;
sleep(1);
return 0;
}
2.2查看进程的指令
1.
ps axj | head -1 && ps axj | grep test | grep -v grep
查看系统所有进程的信息只显示标题行
查看系统所有进程的信息只显示包含可执行程序test的内容
grep test 也是一个进程 为了显示只观 不显示 grep test 进程
2. 持续监控指定进程的脚本:
while :; do ps axj | head -1 && ps axj | grep myproc | grep -v grep; echo "分隔符"; sleep 1; done
> 1. while :; 永远返回true 死循环
> 2. do 执行后面的语句
> 3. echo 的作用: 输出一行分隔符便于查看如"--------------------------"
> 4. sleep 1: 暂停1秒 便于查看
对下面代码的认识
- fork()之后有两个执行流 即两个进程
- 由此实现了两个死循环同时执行
- 以及
if()和else if()同时执行 实际上是两个进程 判断了两次
int main()
{
pid t id = fork();
{
if(id< 0)
//创建失败
perror("fork") ;
return 1;
}
else if(id == 0)
{
//child process(task)while(1)
printf("I am child, pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
else
{
//parentprocesswhile(1)
printf("I am father,pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
return 0;
}
对
fork()函数返回值的认识
- 把子进程的pid返给父进程
- 把0返给子进程
- 父进程 : 子进程 == 1 : 0
- 把子进程的pid返给父进程 是为了让父进程能够对多个子进程进行管理
- 需要区分父子进程以进行分流操作
对子进程创建的认识
- fork()函数是OS提供的系统接口 由Linux内核实现
- 一个新的进程被创建 实际上就是OS多了一个进程
- 我们已知 每多一个进程 我们就要做相关的工作: a. 拷贝代码和数据至内存 b.建立PCB结构体
- 新进程的PCB实际上以父进程的PCB为模板[大部分相同 少部分是自己独有的 比如PID] 创建后加入到进程表 由操作系统进行管理
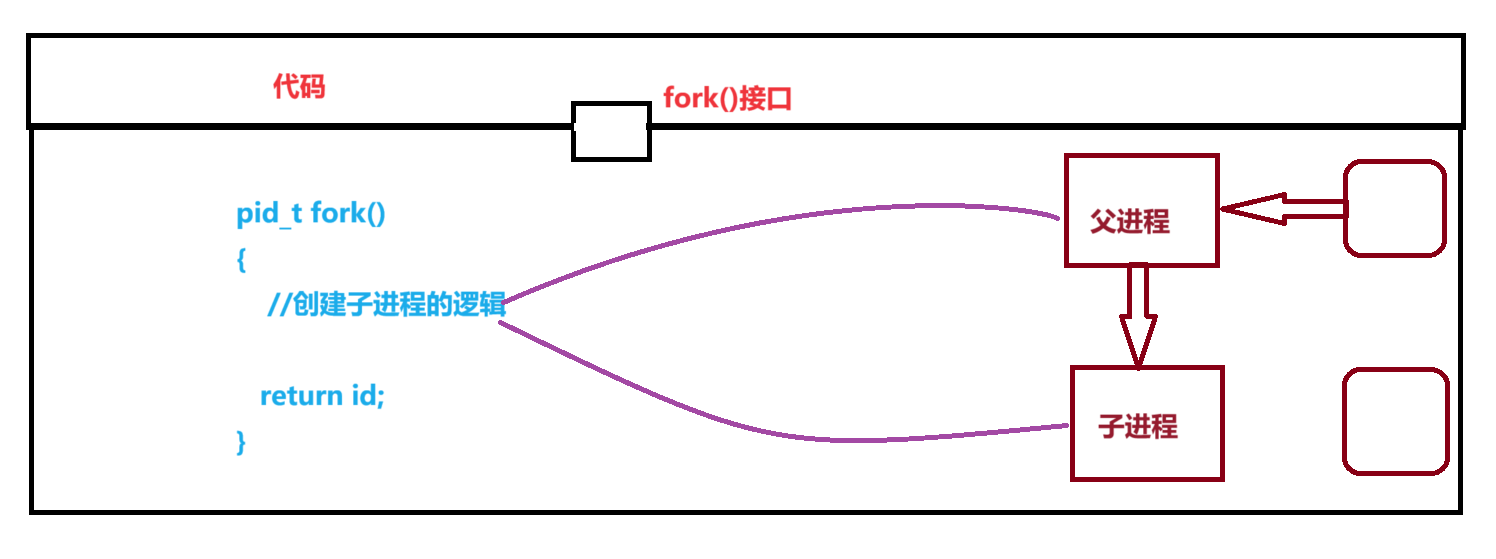
当fork()函数return后 核心代码执行结束了吗? 答案是: 已经执行完了
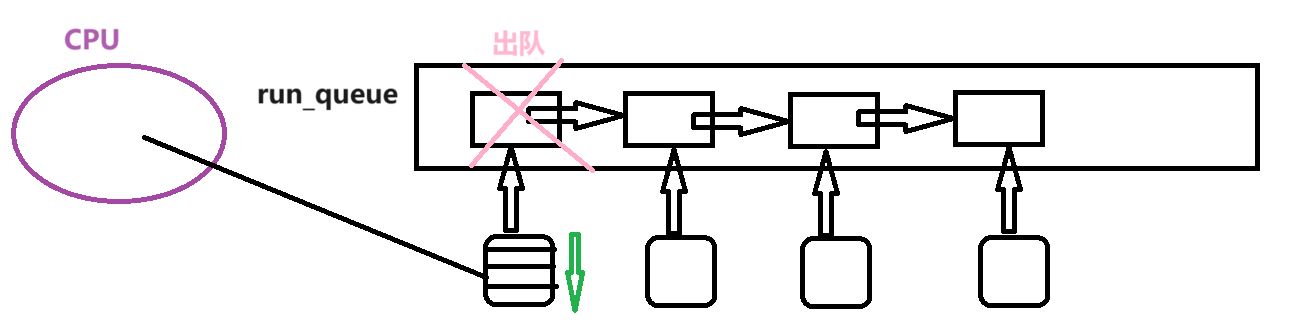
- 进程的调度: 在task_struct的队列中依据调度算法选择一个进程
- CPU运行队列根据不同的调度算法来确定进程的执行顺序,如先来先服务、短作业优先、时间片轮转
- 操作系统和cpu运行某一个进程,本质是从task_struct 形成的运行队列中按照调度算法挑选一个task_struct 来执行它的代码
- 把进程与进程对于的PCB–task_struct联系起来
进程列表和运行队列
- 进程表是操作系统中的数据结构,用于组织记录系统中所有进程的PCB。
- 每个进程都有一个对应的进程表项(PCB),包含进程的标识符、状态、优先级、资源使用情况等信息。
- 进程表可以用于管理和调度进程,操作系统可以根据进程表中的信息对进程进行分配资源、切换上下文等操作。
- CPU运行队列是操作系统中的一个数据结构,用于存放等待执行的进程
- 进程表是记录系统中所有进程的信息的数据结构 用于管理和调度进程
- CPU运行队列是存放等待在CPU上执行的进程的数据结构 用于确定进程的执行顺序
为什么会出现两个返回值?
- 子进程是在当前进程即父进程创建出来的
- 当子进程创建完 fork()函数准备return 之前 此时子进程已经被创建 当OS调度父进程时 父进程接收到的fork()函数的返回值id是已经创建好的子进程的pid 当子进程被调度 子进程接收到的fork()函数的返回值id是0 因为return id;语句被执行了两次 且是不同的值 所以才有了两个返回值的现象
- fork()函数内部 父子进程执行各自的return语句
- 返回两次 并不意味id有两个值
- 两个返回值返回到两个不同的进程
- 一个进程中只有一个确切的返回值
父子进程创建出来 谁先被运行呢?答案: 不一定
- 谁先运行不一定 由OS的调度器决定
- 比如: 当父进程执行了10ms 因为某些原因 父进程被放到运行队列的后面 OS又去执行子进程了