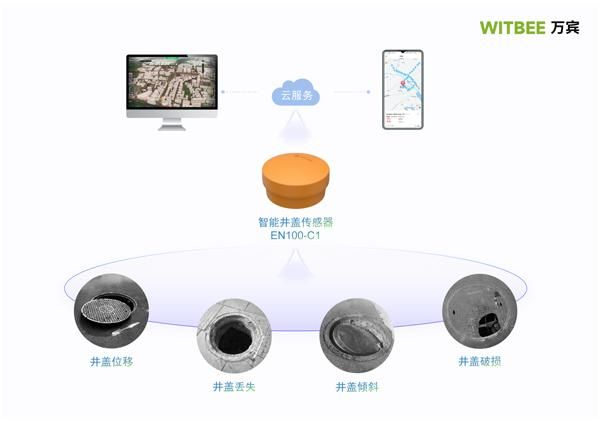
来源 — gifs.com
一、说明
还记得 2012 年的 ImageNet 视觉识别挑战赛吗?当然,你知道!经过大量的反复试验和实验,研究员 Alex Krizhevsky 及其合著者 Ilya Sutskever 和 Geoffrey E. Hinton(他真正理解了深度学习中的“深度”)引入了 AlexNet 架构,该架构以第一作者的名字命名,并赢得了 ImageNet 挑战赛,从而开创了利用深度卷积神经网络进行物体检测的深度迁移学习的新时代!
在这篇博客中,我们将揭开 AlexNet 论文的神秘面纱并深入讨论其架构,然后亲自实践我们所学到的知识!
二、预备知识⏮️
本文假设您非常了解 -
- 卷积运算
- 最大池化、步幅、内核、填充
- 神经网络 (CNN) 和激活函数(Softmax、ReLU)
- CNN(卷积神经网络)
如果您已经了解先决条件,请跳过此部分
让我附上一些我学习深度学习基础知识的资源,以帮助您。
- 卷积运算——看这个
- 卷积神经网络 —观看此内容
- 要学习激活函数,请访问我的博客
三、破解八层神兽🤖
为了更容易理解复杂的架构,我绘制了一个更容易理解的模型架构。在整个博客中仔细遵循架构!

AlexNet 架构简化(来源-作者)
让我们把它分解并逐步理解架构——
- 从上面绘制的架构中,观察224 x 224 维度以及 3 个通道(红色 (R)、绿色 (G) 和蓝色 (B))的 RGB 图像。它代表任何彩色图像,因此代表我们的输入。
- 第 1 层- 在第一层中,我们应用步幅大小为 4 的卷积运算,并具有 96 个大小为 11 x 11 的内核。应用这些操作时,会生成 96 个大小为 55 x 55 的图像(因为我们的内核有 96 个通道) )。这只是一个 3D 张量。
- 然后我们应用内核大小为 3x3 且步幅大小为 2 的最大池化。这会生成大小为 27x27、具有 96 个通道的图像。
- 第 2 层- 在 AlexNet 的第 2 层中,我们再次应用卷积以及使用 256 个大小为 5x5 的内核进行填充。请注意,我在图中的卷积旁边提到了“相同”。填充中的SAME意味着过滤器将应用于输入的所有元素,并且在模型训练阶段应将填充设置为 SAME。这可确保输出尺寸与输入尺寸相同。这再次产生大小为 27 x 27 的 3D 张量,具有 256 个这样的通道。
- 再次,我们应用内核大小为 3x3 的最大池层和大小为 2 的步长,就像我们在第 1 层之后所做的那样。这会生成大小为 13x13、具有 256 个通道的图像。
- 第 3 层- 在 AlexNet 的第 3 层中,我们再次应用具有相同填充(如第 2 层中所述)的卷积,其中包含 384 个大小为 3x3 的内核。这会产生大小为13x13、具有 384 个通道的 3D 张量。
- 第 4 层- 在第 4 层中,我们应用具有相同填充的卷积,其中包含 384 个大小为 3x3 的内核。这再次产生大小为13x13、具有 384 个通道的 3D 张量。
- 第 5 层- 在第 5 层中,我们应用具有相同填充的卷积,其中包含 256 个大小为 3x3 的内核。这再次产生大小为13x13、具有 256 个通道的 3D 张量。
- 现在我们再次应用步幅大小为 2 的最大池和 3x3 最大池过滤器(内核)。这会生成尺寸为 6x6、具有 256 个通道的图像。
- 第 6,7,8 层 -在 6x6x256 (= 9216) 3D 张量上应用展平操作(尺寸的简单乘积)时,我们只需得到 2 个完全连接的层,然后是最终的 softmax 层来输出我们的类。(请注意,该图有 1000 个输出类,因为它用于对 ImageNet 问题进行分类,该问题有 1000 个类需要识别)
因此,基本上,AlexNet 有 5 个卷积层,后跟 2 个全连接层,最后是用于生成输出的 Softmax 层。
四、为什么 AlexNet 如此酷?!
咬碎纸……
让我们讨论一些即使在今天也广泛用于深度学习和目标检测的最重要的概念,这些概念在AlexNet论文中介绍过——
- AlexNet 论文是第一篇使用强大的非线性激活函数ReLU概念的论文。
- Dropout用于防止过度拟合并确保模型在学习中的稳健性和泛化性。
- 数据增强用于将数据转换为各种形式(水平/垂直翻转、旋转等),以增强训练数据的多样化。
- 使用多个 GPU来训练模型以获得良好的性能指标。
除此之外,AlexNet 论文还使用了一个名为“局部响应归一化”(LRN)的概念,该概念虽然作为一个概念值得注意,但已被“批量归一化”等先进技术进一步取代。
就我个人而言,我在解决深度学习问题时确实更喜欢批量归一化,但 LRN 的概念是如此美丽,以至于我在研究 AlexNet 论文时无法跳过它。
五、LRN 将神经科学与人工智能连接起来🔮🪄
我们知道,在使用任何激活函数之前,神经网络的隐藏层希望我们将高维数据归一化为零均值和单位方差,以正确地对数据进行建模。标准化会转换数据集中列的值并对其进行缩放,而不会扭曲值范围的差异或丢失信息。
使用ReLU之后,即f(x)=max(0,x),你会发现使用ReLU之后得到的值没有像tanh和sigmoid函数那样的范围。因此,ReLU 之后必须进行归一化。研究人员在 AlexNet 论文中提到了一种名为“局部响应归一化”的方法,这对我来说似乎相当有趣,因为它是受到神经科学中一个名为“横向抑制”的重要概念的启发,该概念讨论了活跃神经元对其的作用。周围神经元对特定刺激做出反应。
假设您已经了解 ReLU 的工作原理,则数据应在 0 和 1 之间标准化,因为在 ReLU 理论中任何 <0 的值都是 0。对于像 ReLU 这样的无界函数(没有最大值),LRN 用于标准化 ReLU 给出的无界激活。
您会惊讶地发现人工神经网络中的 LRN 概念改编自称为横向抑制的神经科学概念。
横向抑制涉及通过兴奋神经元来抑制远处的神经元。
在我们的中枢神经系统中,兴奋或受刺激的神经元往往会抑制远处神经元的活动,这有助于增强我们的感官知觉(回想一下,当您的注意力集中在目标物体上时,您仍然可以模糊地识别周围环境 - 您仍然可以感知周围的环境)树,同时看着鸟)。这种视觉抑制反过来又增强了视觉图像的感知和对比度。它有助于改善我们观看时的视力和视力(以及听觉、嗅觉等)!
但是,LRN 与横向抑制有何关联?
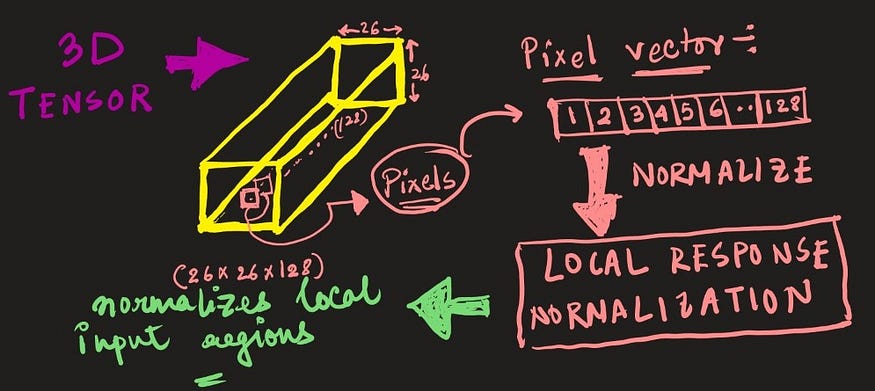
来源——作者
局部响应归一化也是一个涉及卷积神经网络输入特征(特征图)对比度增强的过程。LCN 在特征图(图像)的局部邻域中执行,考虑到每个像素。
总体概念是增强输入图像或特征图上的“峰值”并抑制“平坦”响应,因为峰值与目标对象或刺激的存在呈正相关,而不是平坦但高频的响应,而不会给出许多数据涉及物体或刺激是否实际存在。因此,LRN 增加了神经感觉对所需刺激的敏感性。
综上所述,我们可以推断,如果与目标对象/刺激(峰值)存在强相关性,则图像的该局部块(或邻域)中的神经元之间的模拟使得强相关性将抑制弱相关性,从而提升峰值。但如果存在平坦但强的相关性,那么每个强相关性将几乎同等地相互抑制,从而使整个邻域受到阻尼。
LRN 过程因此增强了对象检测和识别。
LRN 概念被即将到来的层和批量标准化概念所掩盖(它的影响很小),它标准化特征图的整个层或创建小批量的特征图并标准化每个批次,并且在几乎所有情况下都工作得很好到目前为止的每个神经网络。
至此,我们基本上就完成了研究论文。现在让我们进入有趣的部分。
六、AlexNet 的实践实现👩🏼💻
只需查看架构,我们就可以轻松编写 AlexNet 的架构。下面是相同的代码 -
#import dependencies
import tensorflow as tf
tf.__version__
'2.2.0'
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout, Flatten,Conv2D, MaxPooling2D,BatchNormalization
#Create a sequential model
model = Sequential()
# 1st Convolutional Layer
model.add(Conv2D(filters=96, input_shape=(227,227,3), kernel_size=(11,11),\
strides=(4,4), padding='valid'))
model.add(Activation('relu'))
# Pooling
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid'))
# Batch Normalisation before passing it to the next layer
model.add(BatchNormalization())
# 2nd Convolutional Layer
model.add(Conv2D(filters=256, kernel_size=(11,11), strides=(1,1), padding='valid'))
model.add(Activation('relu'))
# Pooling
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid'))
# Batch Normalisation
model.add(BatchNormalization())
# 3rd Convolutional Layer
model.add(Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), padding='valid'))
model.add(Activation('relu'))
# Batch Normalisation
model.add(BatchNormalization())
# 4th Convolutional Layer
model.add(Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), padding='valid'))
model.add(Activation('relu'))
# Batch Normalisation
model.add(BatchNormalization())
# 5th Convolutional Layer
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), padding='valid'))
model.add(Activation('relu'))
# Pooling
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid'))
# Batch Normalisation
model.add(BatchNormalization())
# Passing it to a dense layer
model.add(Flatten())
# 1st Dense Layer
model.add(Dense(4096, input_shape=(224*224*3,)))
model.add(Activation('relu'))
# Add Dropout to prevent overfitting
model.add(Dropout(0.4))
# Batch Normalisation
model.add(BatchNormalization())
# 2nd Dense Layer
model.add(Dense(4096))
model.add(Activation('relu'))
# Add Dropout
model.add(Dropout(0.4))
# Batch Normalisation
model.add(BatchNormalization())
# 3rd Dense Layer
model.add(Dense(1000))
model.add(Activation('relu'))
# Add Dropout
model.add(Dropout(0.4))
# Batch Normalisation
model.add(BatchNormalization())
# Output Layer
model.add(Dense(17))
model.add(Activation('softmax'))
model.summary()
七、结论
希望您在学习 AlexNet 过程中获得乐趣!如果您希望我介绍任何其他神经网络架构或研究论文,请在评论中告诉我!
就这样吧!传奇的 AlexNet 触手可及!
八、参考资料
我使用了以下资源并附加了链接,以供参考-
- AlexNet 论文 (2012)
- 横向抑制
- LRN