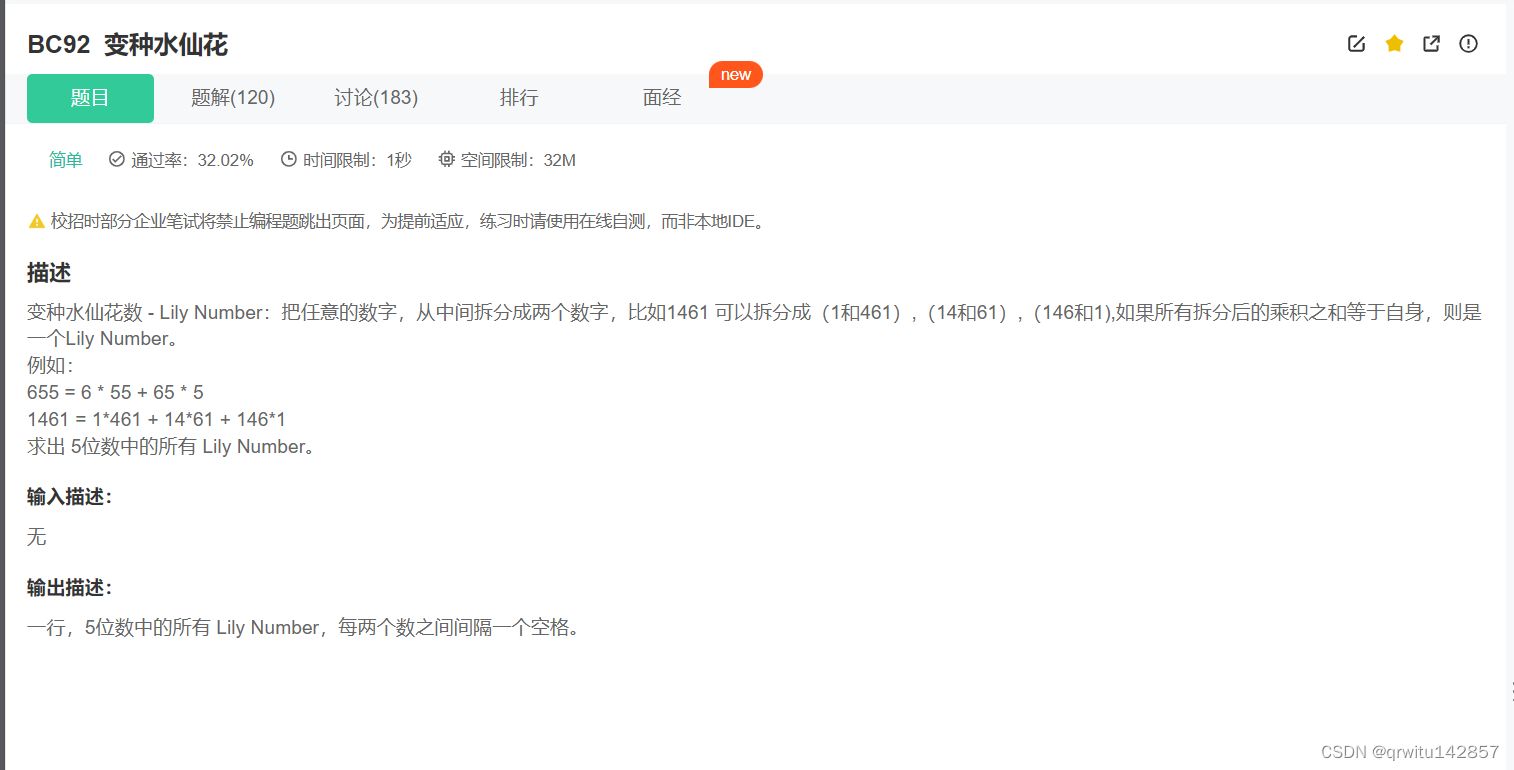
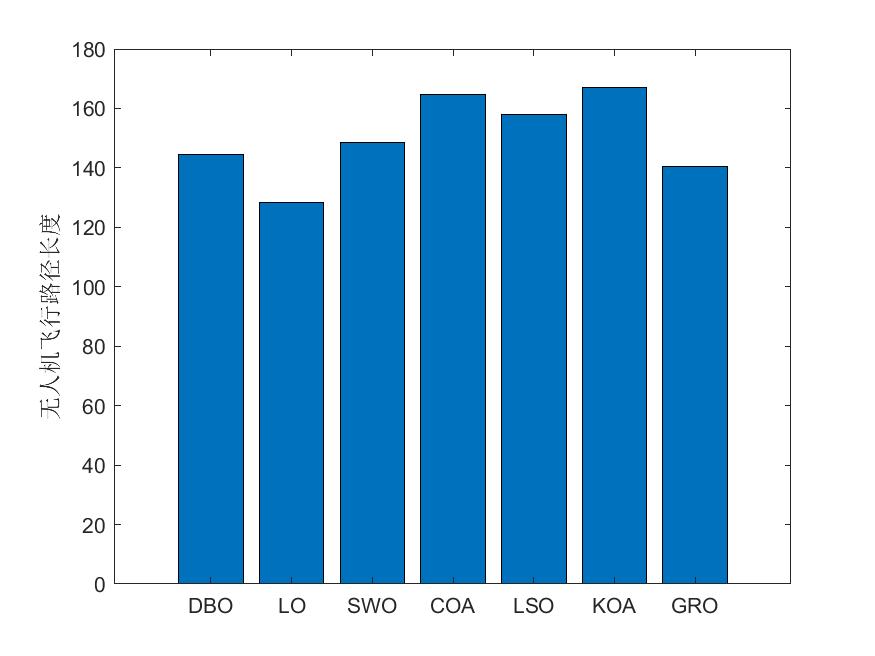
解码器组件
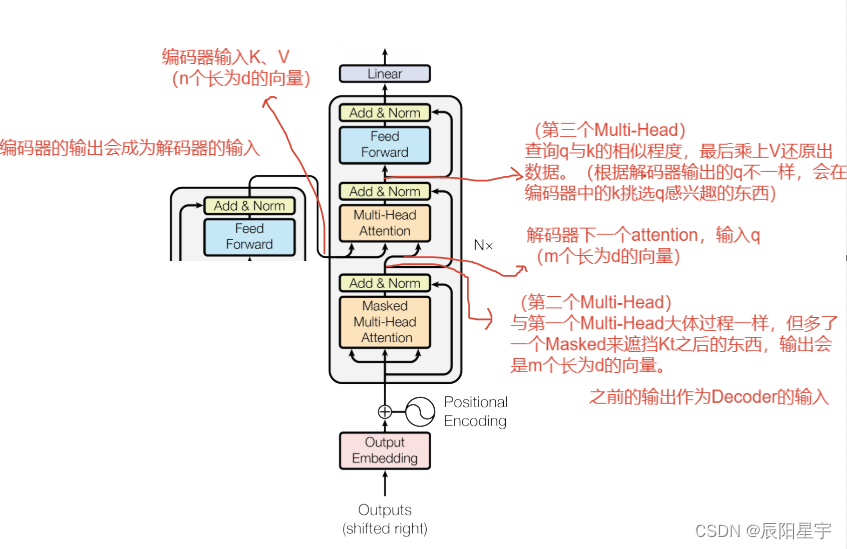
解码器部分:
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
解码器层的作用:
作为解码器的组成单元,每个解码器层根据给定的输入向目标方向进行特征提取操作,即解码过程。
解码器层代码
解码器曾主要由三个子层组成,这里面三个子层还用之前构建Encoder时的代码,详情请看:【Transformer从零开始代码实现 pytoch版】(二)Encoder编码器组件:mask + attention + feed forward + add&norm
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
"""
:param size: 词嵌入维度
:param self_attn: 多头自注意力层 Q=K=V
:param src_attn: 多头注意力层 Q!=K=V
:param feed_forward: 前馈全连接层
:param dropout: 置0比率
"""
super(DecoderLayer, self).__init__()
# 传参到类中
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.dropout = dropout
# 按照解码器层的结构图,使用clones函数克隆3个子层连接对象
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, source_mask, target_mask):
"""构建出三个子层:多头自注意力子层、普通的多头注意力子层、前馈全连接层
:param x: 上一层输入的张量
:param memory: 编码器的语义存储张量(K=V)
:param source_mask: 源数据的掩码张量
:param target_mask: 目标数据的掩码张量
:return:一层解码器的解码输出
"""
m = memory
# 第一步,让x进入第一个子层(多头自注意力机制的子层)
# 采用target_mask,将解码时未来的信息进行遮掩。
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))
# 第二步,让x进入第二个子层(常规多头注意力机制的子层,Q!=K=V)
# 采用source_mask,遮掩掉已经判定出来的对结果信息无用的数据(减少对无用信息的关注),提升计算效率
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))
# 第三步,让x进入第三个子层(前馈全连接层)
return self.sublayer[2](x, self.feed_forward)
示例
# 定义参数
size = d_model = 512
head = 8
d_ff = 64
dropout = 0.2
self_attn = src_attn = MultiHeadedAttention(head, d_model, dropout) # 定义多头注意力层
ff = PositionwiseFeedForward(d_model, d_ff, dropout) # 定义前馈全连接层
x = pe_res
memory = enc_res # 将之前编码器实例中的enc_res结果赋值给memory作为K和V
mask = torch.zeros(2, 4, 4)
source_mask = target_mask = mask # 简单示范,都先给同样的mask
dl = DecoderLayer(size, self_attn, src_attn, ff, dropout)
dl_res = dl(x, memory, source_mask, target_mask)
print(f"dl_res: {dl_res}\n shape:{dl_res.shape}")
dl_res: tensor([[[-2.7233e+01, 3.7782e+01, 1.7257e+01, ..., 1.2275e+01,
-4.7017e+01, 1.7687e+01],
[-2.6276e+01, 1.4660e-01, 5.5642e-02, ..., -2.5157e+01,
-2.8655e+01, -3.8758e+01],
[ 1.0419e+00, -2.7726e+01, -2.3628e+01, ..., -7.7137e+00,
-5.7320e+01, 4.6977e+01],
[-3.3436e+01, 3.2082e+01, -1.6754e+01, ..., -2.5161e-01,
-4.0380e+01, 4.7144e+01]],
[[-5.3706e+00, -2.4270e+01, 2.1009e+01, ..., 6.5833e+00,
-4.3054e+01, 2.5535e+01],
[ 3.1999e+01, -8.3981e+00, -5.6480e+00, ..., 3.1037e+00,
2.1093e+01, 3.0293e+00],
[ 5.5799e+00, 1.0306e+01, -2.0165e+00, ..., 3.8163e+00,
4.0567e+01, -1.2256e+00],
[-3.6323e+01, -1.4260e+01, 3.3353e-02, ..., -9.4611e+00,
-1.6435e-01, -3.5157e+01]]], grad_fn=<AddBackward0>)
shape:torch.Size([2, 4, 512])
对比下面编码器的编码结果:
enc_res: tensor([[[-0.9458, 1.4723, 0.6997, ..., 0.6569, -1.9873, 0.7674],
[-0.9278, 0.0055, -0.0309, ..., -1.2925, -1.2145, -1.6950],
[ 0.1456, -1.1068, -0.8927, ..., -0.2079, -2.2481, 1.8858],
[-1.2406, 1.3828, -0.8069, ..., 0.1041, -1.5828, 1.9792]],
[[-0.1922, -1.1158, 0.7787, ..., 0.2102, -1.7763, 1.1359],
[ 1.4014, -0.3193, -0.3572, ..., -0.0428, 0.7563, 0.1116],
[ 0.3749, 0.4738, -0.0470, ..., 0.1295, 1.8679, 0.0937],
[-1.5545, -0.5667, -0.0432, ..., -0.6391, -0.0121, -1.4567]]],
grad_fn=<AddBackward0>)
原数据的掩码张量存在意义:
掩码原数据中,关联性弱的数据,不让注意力计算分散,提升计算效率。
解码器代码
N个解码器层构成一个解码器
class Decoder(nn.Module):
def __init__(self, layer, N):
""" 确定解码器层和层数
:param layer: 解码器层
:param N: 解码器层的个数
"""
super(Decoder, self).__init__()
self.layers = clones(layer, N) # 使用clones函数克隆N个类
self.norm = LayerNorm(layer.size) # 实例化规范化层
def forward(self, x, memory, source_mask, target_mask):
""" 循环构建解码器,经过规范化层后输出
:param x:目标数据的嵌入表示
:param memory:解码器层的输出QV
:param source_mask:源数据掩码张量
:param target_mask:目标数据掩码张量
:return:经过规范化后的解码器
"""
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
return self.norm(x)
示例
size = d_model = 512
head = 8
d_ff =64
dropout = 0.2
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
layer = DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout) # 第一个attn作为自注意力机制,第二个attn作为注意力机制
N = 8
x = pe_res
memory = enc_res
mask = torch.zeros(2, 4, 4)
source_mask = target_mask = mask
de = Decoder(layer, N) # 实例化解码器
de_res = de(x, memory, source_mask, target_mask)
print(f"de_res: {de_res}\n shape: {de_res.shape}")
de_res: tensor([[[-0.7714, 0.1066, 1.8197, ..., -0.1137, 0.2005, 0.5856],
[-0.9215, -0.9844, -0.4962, ..., -0.1074, 0.4848, 0.3493],
[-2.2495, 0.0859, -0.7644, ..., -0.0679, -0.7270, -1.3438],
[-0.4822, 0.2821, 1.0786, ..., -1.9442, 0.8834, -1.1757]],
[[-0.2491, -0.6117, 0.7908, ..., -2.1624, 0.6212, 0.6190],
[-0.3938, -0.5203, 0.6412, ..., -0.8679, 0.8462, 0.3037],
[-1.0217, -1.0685, -0.5138, ..., 1.2010, 2.0795, -0.0143],
[-0.2919, -0.5916, 1.5231, ..., -0.1215, 0.7127, -0.0586]]],
grad_fn=<AddBackward0>)
shape: torch.Size([2, 4, 512])