有破要有立。
前面提到 经典端到端拥塞控制将越来越失效,未来该如何,谈谈我的看法。
端到端拥塞控制的难点根本上是要解决公平性问题,顺带着提高资源利用率。我们很容易理解,在共享资源场景下,不公平一定是低效的,公平甚至是高效的前提,但公平是加权的。
比如一些不重要的后台任务,一致算法对其强加一致公平就多此一举了,为解决这问题,将其纳入 app-limited 就不管了。自己都不需要公平但却被强加公平的情况还有很多,算法很难加权。
为刻画任务权重,引用自己一个想法:四象限调度 以及 Linux 四象限调度。
网络传输如何实现自决,引用自己一个借贷式方案:借贷式拥塞控制。借贷式拥塞控制尝试引入一个新的维度,burst 率,作为发送体验(或者计费)的度量依据,供求关系和 ROI 会自动收敛。
引用一个更实际的 Linux 新调度器:Linux 6.6 的 EEVDF 调度器。
了解一下 EEVDF(Earliest Eligible Virtual Deadline First):
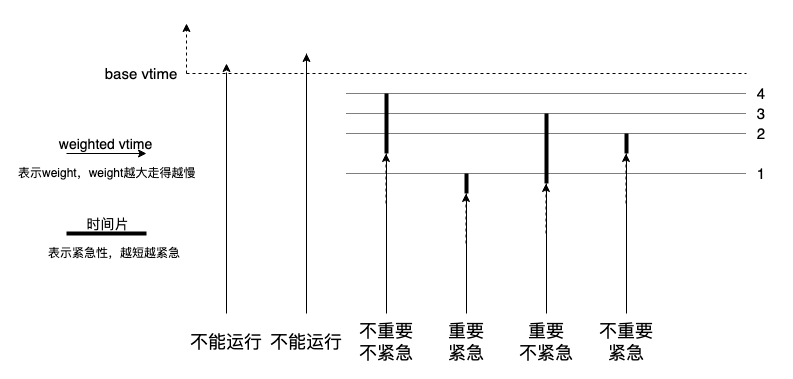
很有意思的一个调度器。
之前的调度器之所以引入那么多 “启发式” 把戏都不尽人意,就因为无论多么大的权重,很容易被那些来无影去无踪,不易捕捉的 “紧急” 小事不停打断,比如 hardirq,softirq,做过系统运维的都知道,一旦 hardirq 不均衡,softirq 高了,系统就抖动了,这是不公平的根源,也是低效的根源,但一直以来 Linux 调度器都没有把这些 “闪客” 纳入管理,这次 EEVDF 做到了,我觉得这就是一个四象限调度器。
网络传输也一样,类比的话我就不说太多,本质上就是一回事,就说一点,拥塞,公平性,抖动的根源同样来自那些来无影去无踪的 “紧急闪客”,也就是 burst!管理好 burst,拥塞问题就解决了一大半。
CFS 调度器 的优势之一就是承诺去除 O(1) 调度器的启发式把戏,但最终它自己也加入了越来越多的把戏,事后回想,其实就是信息不足,“紧急性” 维度一直作为 “额外” 因素作为把戏的输入,没有被融入到调度权重。
网络传输也有两个维度,cwnd 表示数据量(重要性),而 burst 率表示紧急性,一直以来后者也没有被融入权重,和调度器的问题几乎一模一样。
学学 EEVDF 如何识别并管理闪客的。其实它并没有能力识别,它靠的是信任。谁说时间片小的一定是紧急任务的,信任啊。这也就是拥塞控制自决的依据。
分布式网络非同步网络,没有哪个共享变量可以充作 base vtime,但绝对时间可以一用,我们要的不是它的粒度,而是它定义了一条死线,遵循同一算法的各 sender 的 vtime 不能越过该死线,我们是合作式网络,如果你能靠调本地时间来占便宜,你也可以不用这个算法,换用 pixie。我们是苦于没办法合作共赢,而不是苦于没办法抓坏蛋。
如果不理解为什么绝对时间可以用,就看看天上的太阳。
可以从下面开始实验。
- 各 sender 采用同一如下算法。
- 定义函数 cwnd_and_pacing_rate = f(curr_time),获取初始传输配置。
- 定义 acct,发送量平稳但多时,均匀增加 acct,突发增加时,快速增加 acct。
- 定义函数 vtime = g(acct),acct 越大,vtime 增长越快。
- gap = curr_time - vtime,gap 为负暂停传输,gap 越大,传输机会越大。
- 定义函数 cwnd_and_pacing_rate = h(gap),获取即时传输配置。
- 各 sender 同一调好一套参数。
再次强调,假设网络是合作网络,没有机会主义者想占便宜,这其实也是所有拥塞控制算法的基本假设,但这也是人们(特别是国内)对拥塞控制算法的误解,以为既然没人管,那就使劲占便宜吧。因此,难点是如何将上述算法迭代得更优秀,而不是如何钻空子。
事实上,Linux 内核也提供给 task 钻空子的机会,但系统的假设是系统是合作式的,没有这样的 task,如果有人非要写个 while(true) {i++} 或者 fork 炸弹,管理员会收拾他。
最后,如何响应丢包和时延增加就不是问题了,以上是 “拥塞控制自决” 框架,它定义了系统的基本法则,所有一切就都可自决,比如丢包,时延增加了,你主动减缓多少发送由自己决定,比如你有一笔紧急数据要发送,那就根据上面的公式计算,如果可以发就按照结果发就好了,如果你发的实在太多,vtime 会越过 base_vtime 的,你只要遵守规则,下次就没法发了,这就量化并节制了突发。perfect。
任何拥塞控制算法都和一个新的调度器一样,在大量部署并成为默认之前,必须经过大量的实验和验证以及数学论证,绝对不能损害他者。不能轻易部署。
浙江温州皮鞋湿,下雨进水不会胖。