虚拟线程概述
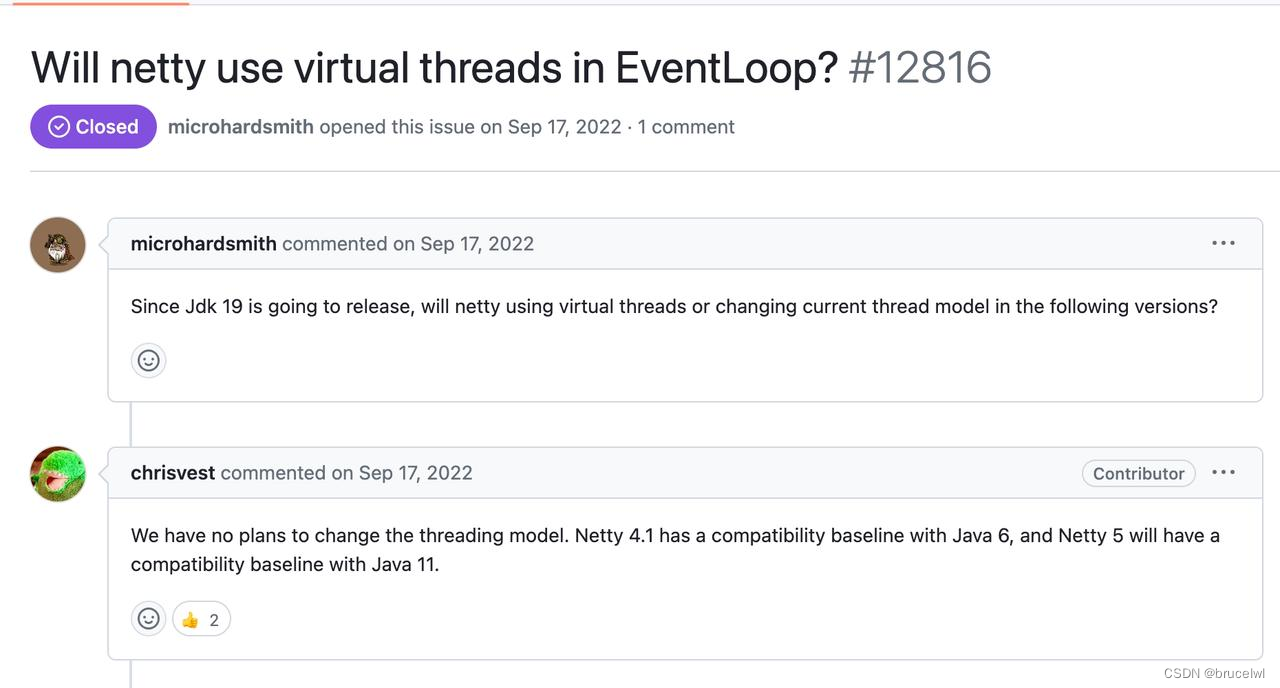
jdk21已于北京时间9月19日21点正式发布, 其中引人注目的就是虚拟线程(Virtual Thread)随之正式发布, 不再是此前jdk19、jdk20中的预览版本。
平台线程:java传统的线程是对系统线程的包装,为了区别于虚拟线程,因此将通过传统方式实现的线程叫做平台线程(Platform Thread)
虚拟线程:虚拟线程是由JDK内部实现的轻量级线程,不依赖于操作系统,可以显著减少编写、维护和观察高吞吐量并发应用程序的工作量。
jdk为什么增加虚拟线程
添加虚拟线程工作量巨大,花费了数年时间,不断孵化,虚拟线程主要是为了解决异步编程相关的问题, 让应用程序能够以简单的一个请求一个处理线程的方式运行,并且能够达到硬件的最佳利用率,先回顾下java传统方式实现编发的两个方案:
一个请求一个处理线程
这种方式可以让开发专注于业务逻辑,使用命令式编程,代码在一条线程上从头到尾执行, Tomcat的Servlet线程就是该模式。
为了提高应用程序的并发请求数,通常会启用多个线程来接受请求,jdk中的线程是对操作系统线程的包装。这导致java的线程创建,销毁成本比较高,为了避免这种情况通常会使用线程池来提高程序性能。
假如一个请求需要耗时50ms,要想实现每秒200的吞吐量, 则理论上至少需要10条线程。如果要想达到2000的吞吐量,怎需要将线程池线程数量设置到100条。
缺点
但一个操作系统能创建的线程数量是有限的,线程池化虽然避免了线程创建、销毁的开销,但并不能提高线程数。在CPU和连接数被耗尽之前很可能无法再创建线程,CPU也就无法得到充分利用。
通过异步方式提高可扩展性
为了充分提高硬件利用率,则出现了类似netty这种异步事件驱动的网络I/O框架,以及Reactive Stream这种反应式编程模式(Spring-WebFlux就是反应式编程的一种实现)。代码不是在一个线程上从头到尾处理请求,而是在等待另一 I/O 操作完成时将其线程返回到池中,以便该线程可以为其它请求提供服务,可以实现通过少量线程数达到大量并发操作。
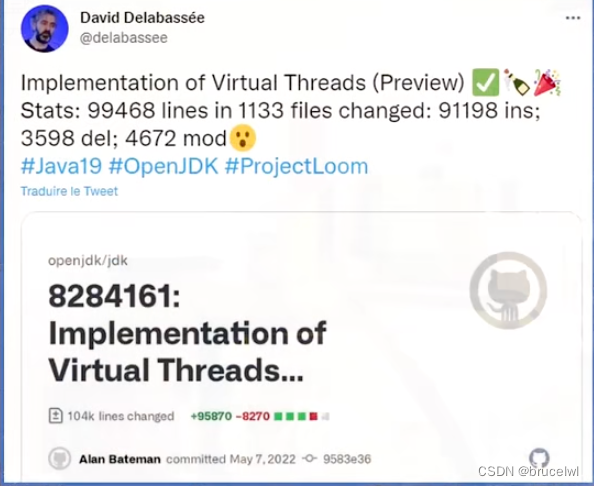
但是这种编程方式比较难以维护,通过大量的回调方法编排业务逻辑(通常是使用java8的lambda语法实现),方法的返回值变成了Mono、或者CompletableFuture类型。大量回调不便于理解业务需求,需要在onErrorResume中做异常处理,也无法对整个方法加try/catch块达到预期的异常处理。
如上是一个Spring-webflux的示例代码,一个方法存在4层return语句,并且这4层代码块很可能是运行在不同线程。
存在的缺点:
- 代码运行在不同的线程,堆栈跟踪无法提供可用的上下文,调试器无法单步执行请求处理逻辑
- 无法通过ThreadLocal传值.
- 难以专注业务逻辑,当想扩展业务逻辑时, 不知道在何处编写自己的代码, 在对反应式编程不熟悉的情况下可能在线程中执行耗时操作, 导致线程阻塞
使用虚拟线程来达到一个请求一个处理线程
JDK传统方式实现的平台线程是对操作系统线程包装,线程的创建受到操作系统的限制,一条平台线程的创建要占用到1M左右的内存。
而虚拟线程是JDK基于平台线程实现的轻量级线程,虚拟线程依附于平台线程(此时称为载体线程)运行,它的创建成本很低,不会像平台线程独占操作系统线程,Java 通过将大量虚拟线程映射到少量平台线程来提供充足线程的假象。
因此可以通过虚拟线程来实现一次请求代码只会执行在同一个虚拟线程中,让开发者更专注于业务逻辑。
但虚拟线程仅在 CPU 上执行计算时才消耗操作系统线程,有着与异步编程方式相同的吞吐量,只不过它是透明实现的:当在虚拟线程中运行的代码调用阻塞 I/O 操作时,java会自动挂起虚拟线程,IO操作完成后再自动恢复执行虚拟线程。
为什么增加虚拟线:简单直白的描述就是希望java开发人员能够以简单易懂的编码方式来实现高吞吐量量的应用程序,提高CPU利用率,避免资源浪费。
非虚拟线程目标
- 并不是想替换传统的线程实现,也并不是为了让所有应用程序全部切换到虚拟线程
- 并不是为了改变基本的并发模型, 也就是说原来的线程、锁、条件变量、信号量、阻塞队列该用还是得用
- 并不是为了提供新的并行结构,
Stream API仍然是并行处理数据集的首选方式
使用虚拟线程注意事项 - 虚拟线程便宜且充足,因此永远不应该被池化,每次使用时应该创建一个新的虚拟线程。
- 池化虚拟线程甚至可能带来性能上的影响,例如之前可能通过ThreadLocal来保存创建的大对象,来避免每次创建,但是大量的虚拟线程可能导致创建大量大对象而影响性能。
- 如果要想要控制并发量, 可以通过
java.util.concurrent.Semaphore信号量这样的方式控制 - 虚拟线程始终是守护线程。该
Thread.setDaemon(boolean)方法无法将虚拟线程更改为非守护线程。 - 虚拟线程具有固定的优先级
Thread.NORM_PRIORITY。该Thread.setPriority(int)方法对虚拟线程没有影响。未来版本中可能会重新考虑此限制。 - 虚拟线程在集合运行时没有权限
SecurityManager。 java.lang.management.ThreadMXBeanAPI支持平台线程的监控和管理,但不支持虚拟线程。- 该
-XX:+PreserveFramePointer标志对虚拟线程性能有巨大的负面影响
虚拟线程的使用
示例1
创建虚拟线程并直接启动
Thread.startVirtualThread(new Runnable() {
@Override
public void run() {
log.info("虚拟线程执行:threadId:{}", Thread.currentThread().threadId());
}
});
创建2条虚拟线程调用代码启动,并等待执行完成
// 这种写法会让日志中无法打印线程名
public static void main(String[] args) throws InterruptedException {
var vthread = Thread.ofVirtual().unstarted(() -> {
log.info("虚拟线程休眠开始:" + Thread.currentThread());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.info("虚拟线程休眠结束:" + Thread.currentThread());
});
var vthread2 = Thread.ofVirtual().unstarted(() -> {
log.info("虚拟线程休眠开始:" + Thread.currentThread());
try {
Thread.sleep(110);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.info("虚拟线程休眠结束:" + Thread.currentThread());
});
vthread.start();
vthread2.start();
vthread2.join();
vthread.join();
}
如下是执行结果:
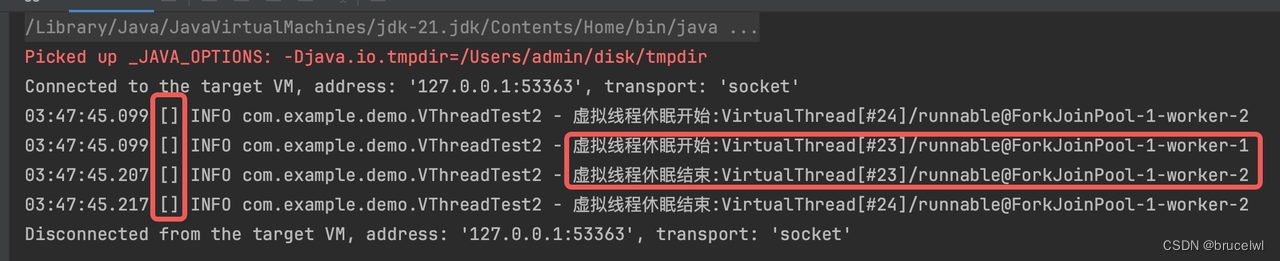
通过这个日志可以发现两个问题:
1. 日志中没能打印出线程名
给虚拟线程添加线程名,便于业务分析,排障
// 给虚拟线程添加线程名,便于业务分析,排障
public static void main(String[] args) throws InterruptedException {
var vthread = Thread.ofVirtual().name("vThread-test-", 1).unstarted(() -> {
log.info("虚拟线程休眠结束:{}", Thread.currentThread());
});
var vthread2 = Thread.ofVirtual().name("vThread-test2-", 2).unstarted(() -> {
log.info("虚拟线程休眠结束:{}", Thread.currentThread());
});
vthread.start();
vthread2.start();
vthread2.join();
vthread.join();
}
实际上Thread.ofVirtual().name("vThread-test-", 1)返回的Thread.Builder.OfVirtual是
VirtualThreadBuilder实现类,并不需要每次创建,可以改成如下方式:
public static void main(String[] args) throws InterruptedException {
Thread.Builder.OfVirtual virtualThreadBuilder
= Thread.ofVirtual()
.name("vThread-test-", 1)
.uncaughtExceptionHandler((t, e) -> System.out.println("异常处理"));
var vthread = virtualThreadBuilder.unstarted(() -> {
log.info("虚拟线程休眠结束:{}", Thread.currentThread());
});
var vthread2 = virtualThreadBuilder.unstarted(() -> {
log.info("虚拟线程休眠结束:{}", Thread.currentThread());
});
vthread.start();
vthread2.start();
vthread2.join();
vthread.join();
}
也可以使用创建线程的工厂模式,
这种方式估计是为了适配原先的java.util.concurrent.ThreadFactory
ThreadFactory factory = Thread.ofVirtual()
.name("virtual-thread-test-2-", 1)
.uncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
System.out.println("虚拟线程触发异常" + t + ",throwable:" + e.getMessage());
log.info("虚拟线程Id:{}, 虚拟线程名:{}, 依附的平台线程:{}", t.threadId(), t.getName(), t);
}
})
.factory();
// 通过工厂创建虚拟线程
factory.newThread(runnable);

2. 再看日志的第二个问题,虚拟线程号#23开始和结束日志后面的ForkJoinPool-1-worker-后面的序号不一样,这是为什么???
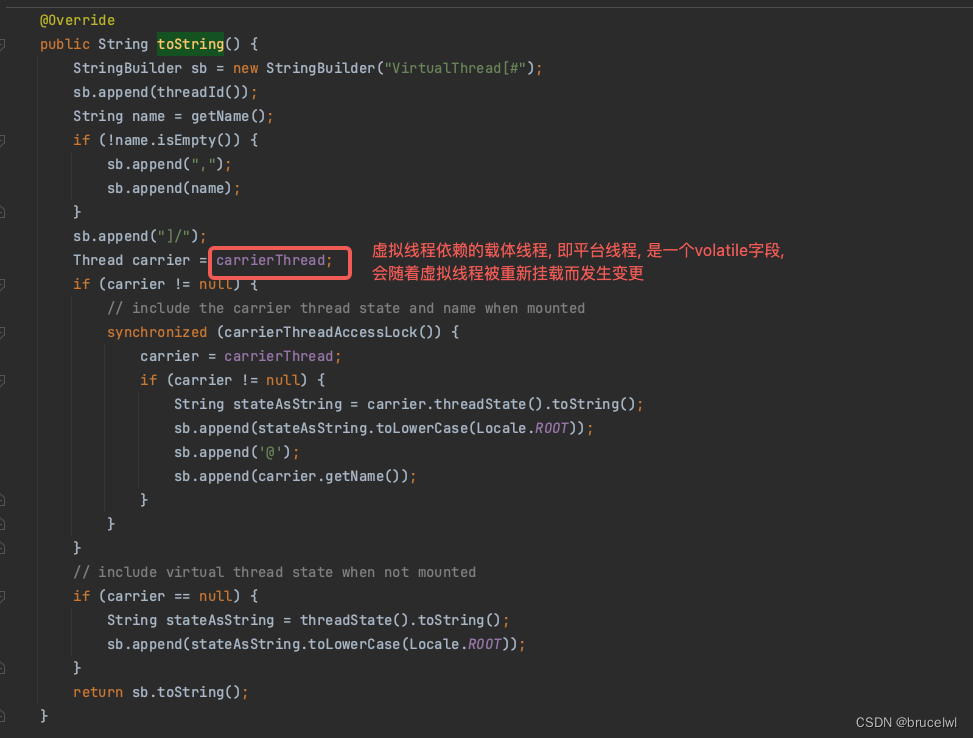
#23是虚拟线程的线程号,而后面的ForkJoinPool-1-worker-实际上是虚拟线程所被挂载到的平台线程(载体线程),从名字可以看出,虚拟线程依赖的载体线程实际上由ForkJoinPool来实现,jdk在调度虚拟线程时保证代码在挂起前后是在同一个虚拟线程执行,但是不保证所依赖的载体线程也是同一个,也不需要有这样的保证。
java.lang.VirtualThread#toString方法
示例2
下面是JDK官网一个创建大量虚拟线程的示例程序。程序首先获得一个ExecutorService将为每个提交的任务创建一个新的虚拟线程。然后它提交 10,000 个任务并等待所有任务完成:
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10_000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return i;
});
});
} // executor.close() is called implicitly, and waits
此示例中的任务是简单的代码(休眠一秒钟),现代硬件可以轻松支持 10,000 个虚拟线程同时运行此类代码。但实际上却仅依赖少量的平台线程
- 如果这个程序使用
Executors.newCachedThreadPool()创建ExecutorService,ExecutorService将尝试创建 10,000 个平台线程,从而创建 10,000 个操作系统线程,可能会出现程序崩溃,具体取决于机器性能和操作系统,我实验的时候电脑直接崩了重启,估计是内存不足导致。 - 如果程序使用
Executors.newFixedThreadPool(200)创建ExecutorService,ExecutorService将创建 200 个平台线程,10,000 个任务共用该线程池,许多任务将顺序运行而不是并发运行,并且程序将需要很长时间才能完成。对于该程序,具有 200 个平台线程的池只能实现每秒 200 个任务的吞吐量,而虚拟线程可实现每秒约 10,000 个任务的吞吐量。此外,如果将10_000示例程序中的 更改为1_000_000,则该程序将提交 1,000,000 个任务,创建 1,000,000 个并发运行的虚拟线程,并且(在充分预热后)实现每秒约 1,000,000 个任务的吞吐量。 - 如果该程序中的任务执行一秒钟的计算(例如,对一个巨大的数组进行排序),而不是仅仅休眠,无论它们是虚拟线程还是平台线程,只要线程数量超出处理器核心数量都没有效果。
虚拟线程并不能让运行代码的速度比平台线程快,但可以显著提高应用程序吞吐量。 - 虚拟线程可以运行平台线程可以运行的任何代码。特别是,虚拟线程支持ThreadLocal和线程中断,就像平台线程一样。这意味着处理请求的现有 Java 代码可以轻松地在虚拟线程中运行。许多服务器框架会选择自动执行此操作,为每个传入请求启动一个新的虚拟线程并在其中运行应用程序的业务逻辑。
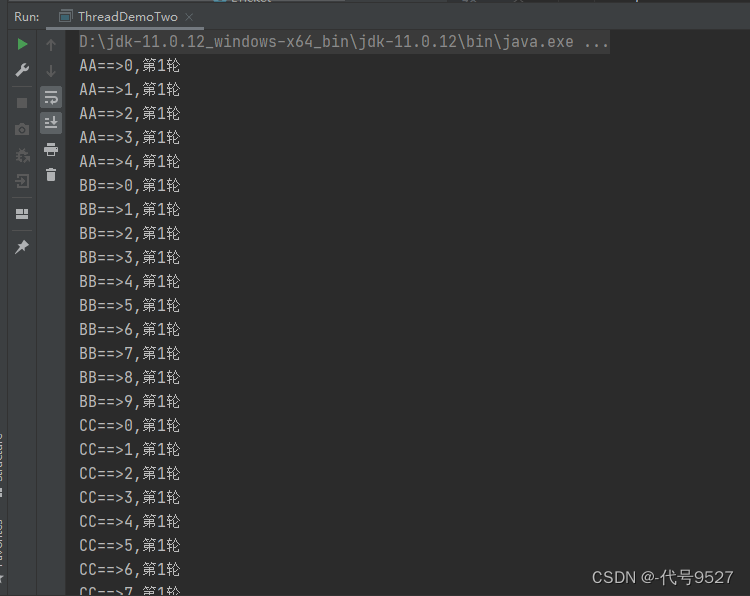
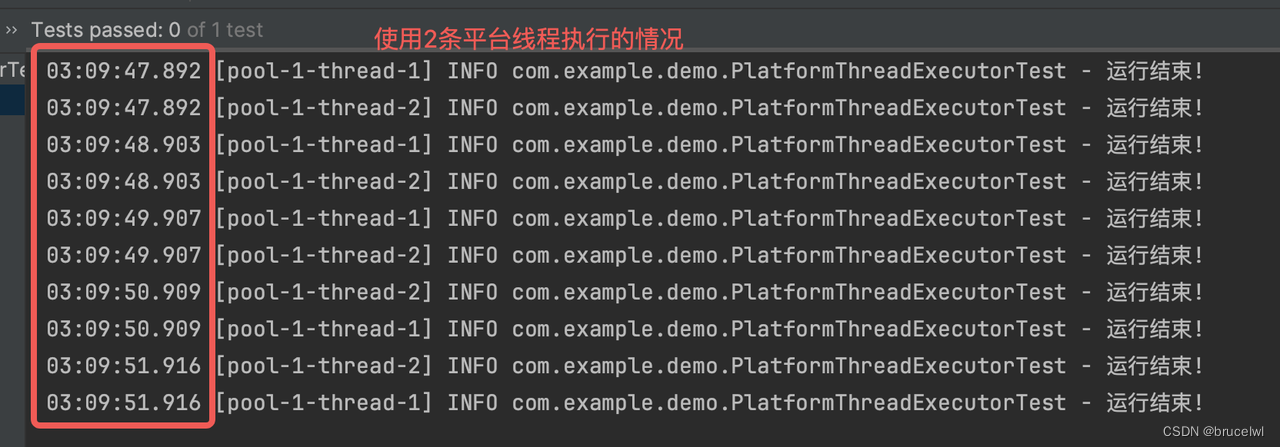
可以将示例中的测试数据改小点看下效果:
使用平台线程, 程序吞吐量受到线程数影响,只有2条并发,其他任务在等待平台线程释放。
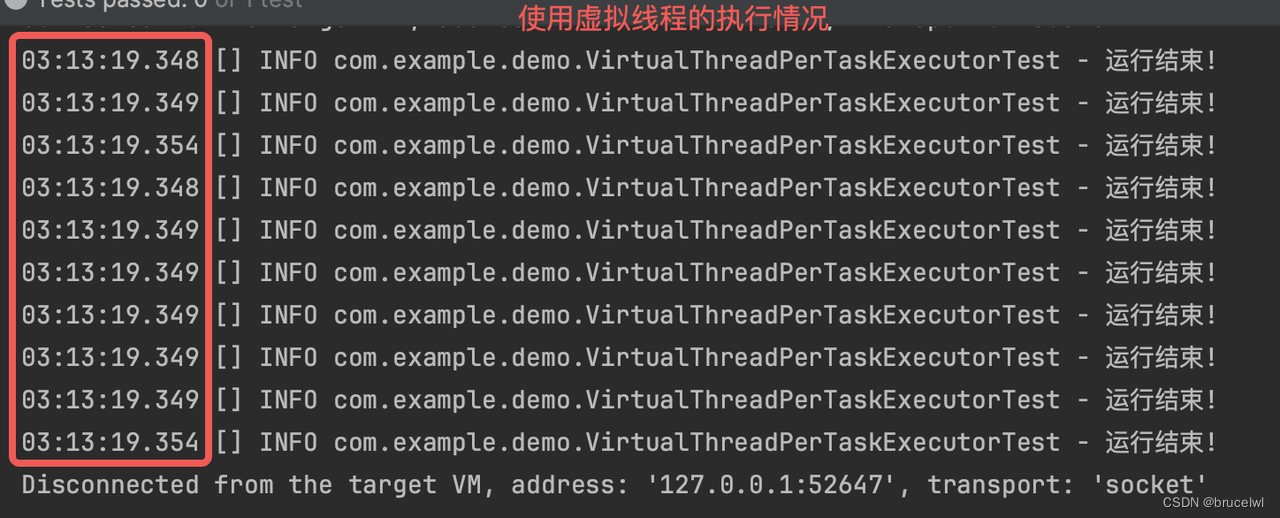
而使用虚拟线程几乎同时执行完成
以上示例使用Executor.newVirtualThreadPerTaskExecutor()直接创建虚拟线程,同样丢失了虚拟线程名,可以通过虚拟线程工来添加虚拟线程名
ThreadFactory factory = Thread.ofVirtual().name("virtual-thread-test-", 1).factory();
ExecutorService virtualThreadExecutor = Executors.newThreadPerTaskExecutor(factory);

示例3
下面是聚合两个远程请求结果并作为返回值的示例:
public Response handle(Request request) {
var url1 = ...
var url2 = ...
Response response = new Response();
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
var future1 = executor.submit(() -> fetchURL(url1));
var future2 = executor.submit(() -> fetchURL(url2));
response.send(future1.get() + future2.get());
} catch (ExecutionException | InterruptedException e) {
response.fail(e);
}
return response;
}
String fetchURL(URL url) throws IOException {
try (var in = url.openStream()) {
return new String(in.readAllBytes(), StandardCharsets.UTF_8);
}
}
handle方法中通过虚拟线程访问2个远程服务,并通过future1.get()等待结果,将结果聚合返回。像这样的服务器应用程序具有简单的阻塞代码,可以很好地扩展,因为它可以使用大量虚拟线程。
虚拟线程调度原理
JDK传统的平台线程依赖于操作系统调度。

而对于虚拟线程,由JDK 调度执行。JDK的调度程序将虚拟线程分配给平台线程(此时平台线程称为虚拟线程的载体)。然后,操作系统像往常一样调度平台线程,(可以实现虚拟线程和平台线程M:N调度关系)。
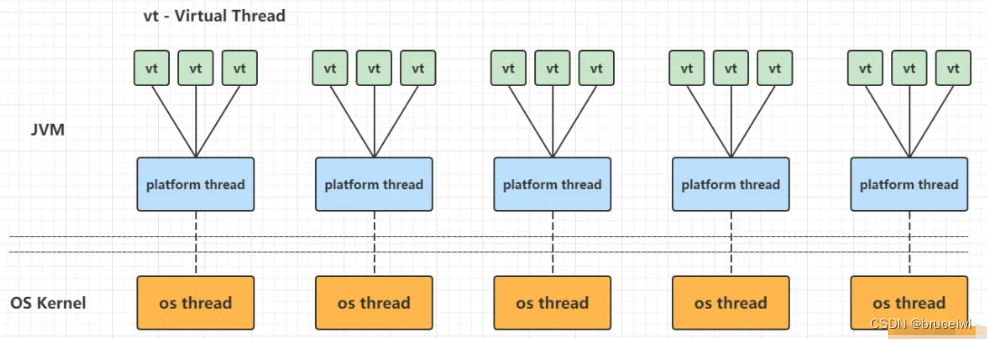
JDK的虚拟线程调度程序通过ForkJoinPool以先进先出(FIFO)模式调度。调度程序默认的平台线程数它等于可用处理器的数量,可以通过系统属性进行调整jdk.virtualThreadScheduler.parallelism。
源码见: java.lang.VirtualThread#createDefaultScheduler
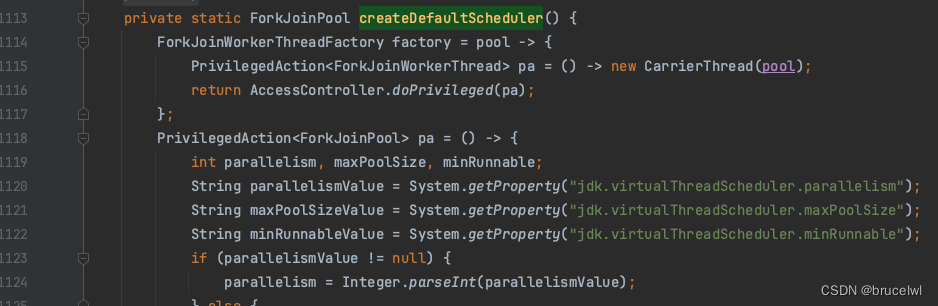
虚拟线程在其生命周期内可以被调度到不同的载体上;换句话说,调度程序不维护虚拟线程和任何特定平台线程之间的关联性。从Java代码的角度来看,一个正在运行的虚拟线程在逻辑上独立于它当前的载体:
- 虚拟线程无法获取载体线程,Thread.currentThread()返回的始终是虚拟线程本身。
- 载体和虚拟线程的堆栈跟踪是分开的。虚拟线程中抛出的异常将不包括载体线程的堆栈帧。线程转储不会显示虚载体线程的堆栈帧,反之亦然。
- 载体的线程局部变量对于虚拟线程不可用,反之亦然。
源码级分析参考: 虚拟线程 - VirtualThread源码透视
虚拟线程的挂载和卸载
当JDK调度程序调度虚拟线程执行时则为挂载,此时平台线程成为载体线程
当虚拟线程执行完成或被阻塞时则由调度程序从载体线程卸载,平台线程可以再次用于挂载其它虚拟线程执行
如下会触发虚拟线程卸载:
- 虚拟线程在 I/O 阻塞, 例如一次网络请求
- 队列的阻塞等待BlockingQueue.take()
- JDK中的绝大多数阻塞操作都会卸载虚拟线程, 这些操作对用户透明,无需额外代码。代码块中存在多个阻塞操作, 会导致虚拟线程多次执行挂载和卸载
然而,JDK中的一些阻塞操作不会卸载虚拟线程,从而阻塞其载体和底层操作系统线程。这是因为操作系统级别(例如,许多文件系统操作)或 JDK 级别(例如,Object.wait())的限制。因此,调度程序中的平台线程数量可能会暂时超过可用处理器的数量。可以通过系统参数jdk.virtualThreadScheduler.maxPoolSize设置最大平台线程数,默认是256。
另外如下两种情况,会导致虚拟线程被固定在载体线程上, 从而导致无法被卸载: - 执行的代码是一个synchronized方法或者存在synchronized代码块,(未来的jdk版本中可能考虑消除该限制)
- 执行的代码中调用native方法或通过JNI实现的一个外部函数时。(但是这个目前看来是无法消除的限制)
虚拟线程被固定到载体线程可能会导致其它虚拟线程无法得到载体线程执行,JDK提供了如下的监控方式,便于查找出被固定到载体线程的虚拟线程,并根据情况使用ReentrantLock替换synchronized - 当线程在固定状态下阻塞时,会发出 JDK Flight Recorder (JFR) 事件(请参阅JDK Flight Recorder)。
- 当线程在固定状态下阻塞时,开启系统属性-Djdk.tracePinnedThreads=full会打印完整的堆栈跟踪,突出显示native帧和持有监视器的帧。-Djdk.tracePinnedThreads=short仅输出有问题的帧。
隔离载体线程(重要)
jdk默认所有的虚拟线程都共用一个载体线程,如果虚拟线程出现上述出现的固定在载体线程执行等待的情况,可能导致其它线程无法得到载体线程执行,因此有必要隔离载体线程。
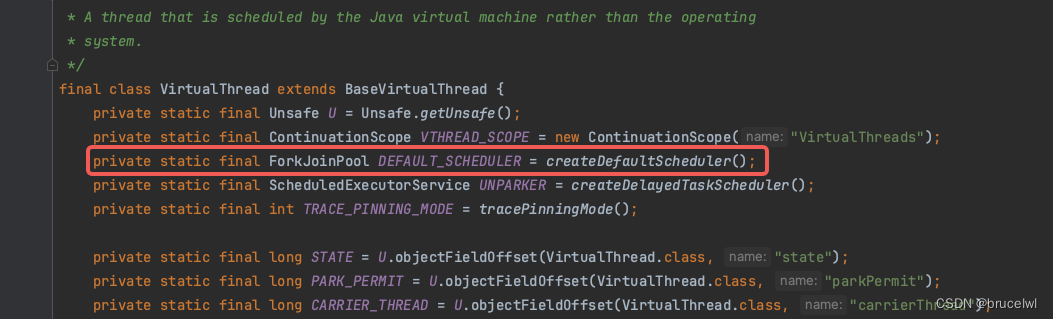
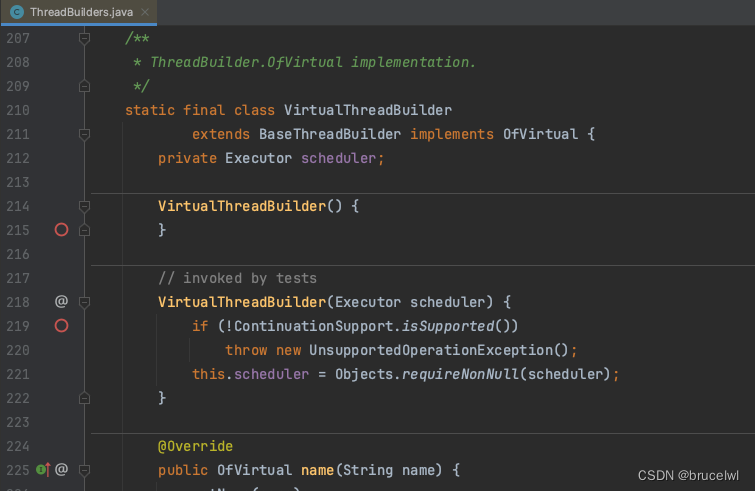
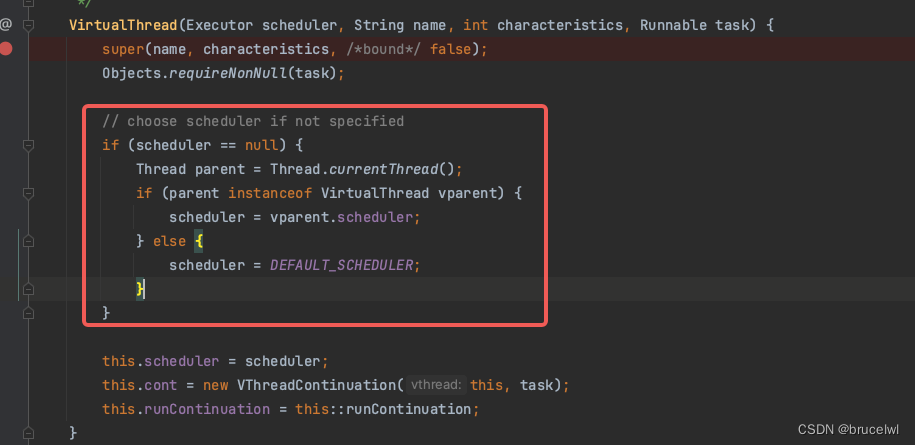
jdk没有开放自定义载体线程的方式,但是可以通过反射来设置自定义的载体线程
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = ForkJoinPoolFactory.createDefaultScheduler("custom-platform-thread-");
Thread.Builder.OfVirtual virtualBuilder = Thread.ofVirtual();
Field schedulerField = virtualBuilder.getClass().getDeclaredField("scheduler");
schedulerField.setAccessible(true);
schedulerField.set(virtualBuilder, forkJoinPool);
virtualBuilder.name("virtual-thread-test-", 0)
.uncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
System.out.println("异常处理");
}
})
.factory();
for (int i = 0; i < 10; i++) {
virtualBuilder.start(new Runnable() {
@Override
public void run() {
log.info("虚拟线程执行:thread:{}", Thread.currentThread());
}
});
}
Thread.sleep(Duration.ofSeconds(3));
}
运行结果: 可以看到, 载体线程被替换成自定义的平台线程

虚拟线程的观测
观察正在运行的程序的状态对于故障排除、维护和优化也至关重要,虚拟线程也是线程的一种实现,因此常见的监控工具也能监控虚拟线程。
-
Java 调试器可以单步执行虚拟线程、显示调用堆栈并检查堆栈帧中的变量。
-
JDK Flight Recorder (JFR)是 JDK 的低开销分析和监视机制,可以将应用程序代码中的事件(例如对象分配和 I/O 操作)与正确的虚拟线程关联起来。 -
JDK传统jstack或jcmd命令仅适用于数十或数百个平台线程,但不适合数千或数百万虚拟线程。因此JDK引入一种新的线程转储,jcmd以将虚拟线程与平台线程一起呈现,jcmd除了纯文本之外,还可以以 JSON 格式保存线程转储信息:
$ jcmd <pid> Thread.dump_to_file -format=json <file>但新的线程转存储格式不包括对象地址、锁、JNI 统计信息、堆统计信息以及传统线程转储中出现的其他信息。
由于可能存在大量线程,因此JDK将这种线程dump方式设计为不暂停应用程序。
如果设置系统属性-Djdk.trackAllThreads=false,则直接使用java.lang.Thread.BuilderAPI 创建的虚拟线程将不会被运行时跟踪,并且可能不会出现在线程dump信息中。只会列出阻塞在网络io操作的虚拟线程以及由Executors.newVirtualThreadPerTaskExecutor()创建的虚拟线程。 -
虚拟线程是在 JDK 中实现的,并且不依赖于任何特定的操作系统线程,因此操作系统级监控无法观察到虚拟线程。
内存使用以及与垃圾收集的交互
- 虚拟线程的堆栈作为堆栈块对象存储在 Java 的垃圾收集堆中。堆栈随着应用程序的运行而增长和缩小,既是为了提高内存效率,也是为了容纳深度达到 JVM 配置的平台线程堆栈大小的堆栈。这种效率使得大量虚拟线程成为可能,从而使服务器应用程序中按请求线程的方式保持持续的可行性。
- 与平台线程堆栈不同,虚拟线程堆栈不是 GC 根。因此,它们包含的引用不会被执行并发堆扫描的垃圾收集器(例如 G1)在停止世界暂停的情况下遍历。
- 与平台线程相比,在虚拟线程上运行此类工作负载有助于减少内存占用
- 当前虚拟线程存在的限制是由于G1 GC 不支持巨大的堆栈块对象。如果虚拟线程的堆栈达到区域大小的一半(可能小至 512KB),则
StackOverflowError可能会抛出异常。
线程局部变量
虚拟线程支持线程局部变量 (ThreadLocal) 和可继承的线程局部变量 (InheritableThreadLocal),就像平台线程一样,因此它们可以运行使用线程局部变量的现有代码。但是,由于虚拟线程可能非常多,因此只有在仔细考虑后才能使用线程局部变量。特别是,不要使用线程局部变量在线程池中共享同一线程的多个任务之间池化昂贵的资源。虚拟线程永远不应该被池化,因为每个虚拟线程在其生命周期内只运行一个任务。我们从JDKjava.base模块中删除了许多线程局部变量的使用,为虚拟线程做好准备,以便在运行数百万个线程时减少内存占用。
当虚拟线程设置任何线程局部变量的值时,系统属性jdk.traceVirtualThreadLocals可用于触发堆栈跟踪。当迁移代码以使用虚拟线程时,此诊断输出可能有助于删除线程局部变量。将系统属性设置为true来触发堆栈跟踪;默认值为false。
对于某些用例,ScopedValue(JEP 429是线程局部变量的更好替代方案, 但JDK21中仍然是预览版本。
有栈协程和无栈协程
- 有栈协程是指协程在运行时需要使用栈来保存函数调用的上下文信息,例如局部变量、函数返回地址等。当协程挂起时,栈中的上下文信息会保存下来,以便下次恢复执行。栈协程的优点是可以方便地保存和恢复函数调用的上下文信息,但缺点是需要为每个协程分配一定的栈空间。
- 无栈协程是指协程在运行时不需要使用栈来保存函数调用的上下文信息,而是使用状态机来保存协程的状态。当协程挂起时,当前的状态会被保存下来,以便下次恢复执行。无栈协程的优点是不需要为每个协程分配栈空间,节省了内存,但缺点是需要手动实现状态机来保存和恢复协程的状态,代码复杂度较高。
JDK21为什么使用有栈协程:JDK21虚拟线程的文档中指出: 将无堆栈协程(即async/await)添加到 Java 语言中,比用户模式线程更容易实现,但是这会导致使用发生较大的变化,一些监控工具需要发生大的变更,会导致需要更长的时间才能被java生态采用,栈协程迁移简单。
拥抱虚拟线程
Spring
Spring Framework、Spring Boot已经适配了虚拟线程
在SpringBoot中只需要通过如下配置即可让Spring异步任务,Servlet使用虚拟线程
@Bean(TaskExecutionAutoConfiguration.APPLICATION_TASK_EXECUTOR_BEAN_NAME)
public AsyncTaskExecutor asyncTaskExecutor() {
return new TaskExecutorAdapter(Executors.newVirtualThreadPerTaskExecutor());
}
@Bean
public TomcatProtocolHandlerCustomizer<?> protocolHandlerVirtualThreadExecutorCustomizer() {
return protocolHandler -> {
protocolHandler.setExecutor(Executors.newVirtualThreadPerTaskExecutor());
};
}
Spring在积极的改进相关代码,已适配虚拟线程, 例如数据库驱动程序、消息传递系统、HTTP 客户端等等。
但也表示虚拟线程不能完全替换ReactiveX 的编程模式,但是可以补充ReactiveX 中的一些不足.
Spring相关blog: https://spring.io/blog/2022/10/11/embracing-virtual-threads
Tomcat
![[图片]](https://img-blog.csdnimg.cn/032f680d62f5448fb01867b4a0df1e80.png)
Netty