To u&me: 努力经营当下,直至未来明朗
文章目录
- 前言
- 一、网络编程(没时间可以跳过)
- 一)网络编程了解
- 二)相关基本概念
- 二、Socket套接字
- 三、数据报套接字通信(UDP)
- 写一个最简单的UDP版本的客户端-服务器程序:回显程序
- 写一个简单的、有实际意义的程序:翻译服务器
- 参考代码:
- 四、流套接字通信(TCP)
- TCP中的长短连接
- 【关于TCP版本的客户端和服务器程序:回显】
- 代码参考:
- 五、再谈协议(了解,可以先略过)
- THINK
前言
一个人最大的痛苦来源于对自己无能的愤怒!
Hi 这里是已经快要秃头的宝贝儿

本文主要内容:套接字的使用以及 TCP、UDP介绍,还有客户端&服务器的简单示例代码。
一、网络编程(没时间可以跳过)
一)网络编程了解
- 网络编程可以获得更丰富的网络资源,而所有的网络资源,都是通过网络编程来进行数据传输的。
- 网络编程,指网络上的主机,通过不同的进程,以编程的方式实现网络通信(或称为网络数据传输)。
- 当然,我们只要满足进程不同就行;所以即便是同一个主机,只要是不同进程,基于网络来传输数据,也属于网络编程。
特殊的,对于开发来说,在条件有限的情况下,一般也都是在一个主机中运行多个进程来完成网络编程。
但是,我们一定要明确,我们的目的是提供网络上不同主机,基于网络来传输数据资源。
二)相关基本概念
(此处只列出相关名称,不作具体解释)
- 发送端(发送数据进程 ) 和 接收端 (另:收发端)
【注意:发送端和接收端只是相对的,只是一次网络数据传输产生数据流向后的概念。】 - 请求和响应
- 客户端(获取服务) 和 服务端
- 常见的客户端服务端模型最常见的场景,客户端是指给用户使用的程序,服务端是提供用户服务的程序:
1) 客户端先发送请求到服务端
2) 服务端根据请求数据,执行相应的业务处理
3) 服务端返回响应:发送业务处理结果
4) 客户端根据响应数据,展示处理结果(展示获取的资源,或提示保存资源的处理结果)
二、Socket套接字
- 网络编程套接字就是研究如何写代码完成网络编程的。
- 套接字socket:就是操作系统给应用程序提供的API。(应用程序其实就相当于应用层和传输层之间进行交互的,所以此时的API其实就是传输层给应用层提供的,即socket其实是传输层的)
- Socket套接字是基于TCP/IP协议的网络通信的基本操作单元。
- 网络传输层中有很多协议,其中最知名的就是TCP和UDP。(TCP和UDP工作特性差别较大,所以操作系统提供了两个版本、风格迥异的API)
- Socket套接字主要针对传输层协议划分为如下三类:
1)流套接字:使用传输层TCP协议
① TCP,即Transmission Control Protocol(传输控制协议),传输层协议。
② 以下为TCP的特点:
有连接
可靠传输
面向字节流
有接收缓冲区,也有发送缓冲区
大小不限
③ 对于字节流来说,可以简单的理解为,传输数据是基于IO流,流式数据的特征就是在IO流没有关闭的情况下,是无边界的数据,可以多次发送,也可以分开多次接收。
2)数据报套接字:使用传输层UDP协议
① UDP,即User Datagram Protocol(用户数据报协议),传输层协议。
② 以下为UDP的特点):
无连接
不可靠传输
面向数据报
有接收缓冲区,无发送缓冲区
大小受限:一次最多传输64k
③ 对于数据报来说,可以简单的理解为,传输数据是一块一块的,发送一块数据假如100个字节,必须一次发送,接收也必须一次接收100个字节;而不能分100次,每次接收1个字节。
3)原始套接字
原始套接字用于自定义传输层协议,用于读写内核没有处理的IP协议数据。(简单了解即可。)
- 简单说一下TCP和UDP的区别:
1)TCP:
有连接、可靠传输、面向字节流、全双工
2)UDP:
无连接、不可靠传输、面向数据报、全双工
① 有无连接:如打电话是有连接的,发微信是没连接的。即有连接是要先建立连接后才可以通信,无连接是可以直接进行发送。
② 可靠传输:不是说A给B发的数据100%能够让B收到,而是A可以知道B有没有收到。
③ 字节流:IO的章节有介绍,如InputStream、OutputStream,即TCP是基于流的。
④ 面向数据报:UDP是以“数据报”为基本单位的
⑤ 全双工相对的词是半双工。
全双工:一个通道,双向通信; 半双工:一个通道,单向通信。
网络通信一般都是全双工。
- 那么:一根网线为啥能够双向通信还不互相干扰(即:可以同时上传/下载)?
网线里面其实不是一根线,里面有8根线,被分成了两组,其实只要你接了4根线就可以正常使用了(接8根是每种多一根备用线),4根线其实就相当于4个车道,两个进、两个出。
三、数据报套接字通信(UDP)
- 对于UDP协议来说,具有无连接,面向数据报的特征,即每次都是没有建立连接,并且一次发送全部数据报,一次接收全部的数据报。
- java中使用UDP协议通信,主要基于 DatagramSocket 类来创建数据报套接字,并使用DatagramPacket 作为发送或接收的UDP数据报。
- Socket编程注意事项:
1)客户端和服务端:开发时,经常是基于一个主机开启两个进程作为客户端和服务端,但真实的场景一般都是不同主机。
2) 注意目的IP和目的端口号,标识了一次数据传输时要发送数据的终点主机和进程
3) Socket编程我们是使用流套接字和数据报套接字,基于传输层的TCP或UDP协议,但应用层协议 也需要考虑。
4) 关于端口被占用的问题:
如果一个进程A已经绑定了一个端口,再启动一个进程B绑定该端口,就会报错,这种情况也叫端口被占用。对于java进程来说,端口被占用的常见报错信息如下:
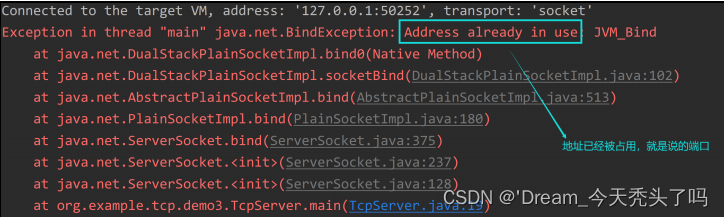
此时需要检查进程B绑定的是哪个端口,再查看该端口被哪个进程占用。以下为通过端口号查进程的方式:
在cmd输入 netstat -ano | findstr 端口号 ,则可以显示对应进程的pid ,或者使用jdk中的bin/jconsole查看阻塞位置。
- UDP socket要掌握的类:DatagramSocket、DatagramPacket (Datagram数据报)
1)DatagramSocket API
DatagramSocket 是UDP Socket,用于发送和接收UDP数据报。
① DatagramSocket 构造方法:
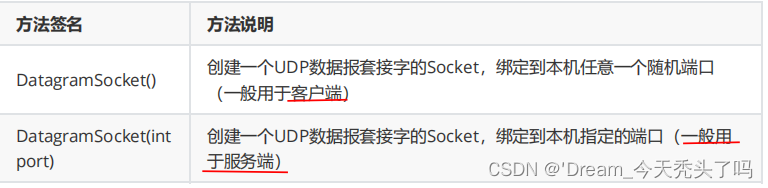
② DatagramSocket 方法:
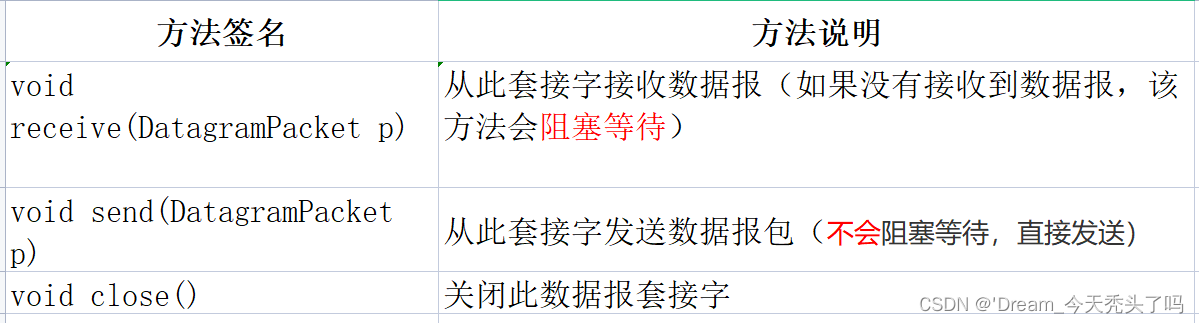
2)DatagramPacket API
DatagramPacket是UDP Socket发送和接收的数据报
① DatagramPacket 构造方法:

② DatagramPacket 方法:

构造UDP发送的数据报时,需要传入 SocketAddress ,该对象可以使用InetSocketAddress 来创建。
3)InetSocketAddress API
InetSocketAddress ( SocketAddress 的子类 )构造方法:

-
Socket本质上是文件。
【狭义的文件就是存储在磁盘上的文件; 广义的文件:操作系统把各种硬件设备和软件资源都抽象成文件,统一按照文件的方式来管理。】
(socket对应到网卡这个硬件设备,操作系统也是把网卡当做文件来管理。通过网卡发送数据就是“写文件”,通过网卡接收数据就是“读文件”) -
DatagramSocket是网卡的代言人,可以操作网卡;而DatagramPacket就代表一个UDP数据报,也就是一次发送/接收的基本单位。
写一个最简单的UDP版本的客户端-服务器程序:回显程序
-
回显服务器echo server (客户端发啥,服务器就返回啥 :其实没有任何实际意义)
-
一个正经的服务器其实有一个非常关键的环节:根据请求计算出响应。
-
服务器启动会绑定端口号,目的就是为了能够让客户端明确是访问主机上的哪个进程!
要想通过端口确定一个进程,就需要在进程启动的时候绑定一个端口,并且在通常情况下一个端口只能被一个进程绑定。
如:数据库服务器启动就会绑定3306端口 -
【由于服务器不确定客户端啥时候发请求过来,所以要时刻“严阵以待”,通常情况就使用 while true来作为一个循环】
-
DatagramSocket socket 调用的receive()方法,参数是DatagramPacket类型的输出型参数,没有返回值。 也就是说:调用receive的时候就需要构造一个空的DatagramPacket对象,然后把对象交给receive,在receive里面负责把从网卡读到的数据给填充到这个对象中。
-
服务器收到的包裹 DatagramPacket requestPacket上就包含了客户端的地址信息(客户端ip和端口号),后面服务器要返回响应的时候直接从这里取就行
-
requestPacke 调用getSocketAddress() 方法,返回的是InetSocketAddress类型的数据,可以同时包含客户端的IP和端口信息。
-
【注:服务器端的构造方法传入的参数是服务器自己绑定的端口号;服务器端的ip一般不用写,因为这里的ip就是本机的ip,程序在哪个主机上启动,对应的ip就是主机自身的ip。(如果一个主机有多个网卡,涉及到了多个IP,并且如果你只希望你的服务器被通过某个指定的IP能够访问,此时就需要手动指定IP; 一般来说,如果不进行手动指定IP,此时就会针对所有的主机IP都生效。)】
-
客户端的构造方法传入的参数是服务器端的IP地址和服务器端口号(也就是服务器端绑定的端口号)
(一个电脑一个IP) -
客户端new DataGramSocket时是没有指定参数的,服务器端是传入参数的,因为服务器要绑定端口号。
-
客户端给服务器发送一个数据的时候:
①客户端自己的主机IP:源IP
②客户端是没有手动绑定一个端口号的,操作系统会自动分配一个空闲的端口:源端口
③服务器的主机:目的IP
④服务器绑定的端口:目的端口)
(客户端手动指定端口也不是不行,但是不确定该端口是否是空闲的。) -
为啥服务器不害怕端口冲突,而客户端就担心端口冲突呢?
因为服务器是在程序员手里的,运行的程序分别是啥端口是可控的; 而客户端是在用户自己的电脑中,用户电脑上安装的软件等就可能占用了指定的端口号。 -
客户端的ip就是运行客户端程序的主机IP,不需要再代码中添加;只需要告诉客户端我们所访问的服务器IP就行啦。
-
补充:端口号是一个16位(二进制)的整数,即0~ 65535,但是我们使用的一般是从1024开始的端口号,这些端口号可以任意使用;但是0~1023成为“知名端口号”,被一些比较知名的应用程序占用。
(补充:DataGramSocket中的receive在阻塞时是死等)
-
注意:服务器端与客户端的工作流程!
【服务器:①读取请求并解析; ②根据请求计算响应; ③将请求写回客户端; ④打印日志
客户端:①从控制台读取用户输入的内容; ②构造一个UDP请求,发送给服务器; ③从服务器读取UDP响应数据,并解析; ④把服务器的响应显示到控制台】 -
可以把两个程序放到不同主机上也是可以通信的,但是要确保服务器的地址是可以访问到的。 注:NAT机制下,我的电脑IP只是一个局域网内部使用的IP,不能在广域网中直接使用。
-
服务器是要给多个客户端提供服务的。那么如何在IDEA中启动多个客户端?
需要自己修改一下配置,具体如下所示:
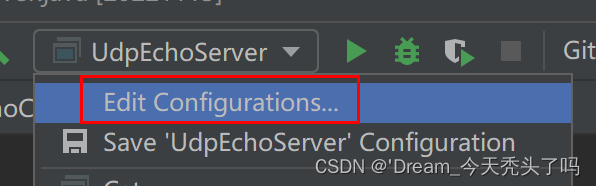
(一定要选中“客户端”,然后选择完成后点击“ok”)

写一个简单的、有实际意义的程序:翻译服务器
-
要求:英译汉
(核心其实和回显服务器差不多,差别只是在process根据请求计算响应的逻辑,那就直接继承回显服务器,然后再重写process方法就行。) -
其实一个服务器的基本流程都是差不多的,最核心的区别其实就是process“根据请求计算响应”,因为不同的服务器有不同的业务逻辑
-
(补充:Map中的getOrDefault(默认值)方法,找到key就输出对应的value,没有找到就输出默认值)
参考代码:
UDP:回显+翻译
四、流套接字通信(TCP)
- ServerSocket API
ServerSocket 是创建TCP服务端Socket的AP,给服务器使用。
① ServerSocket 构造方法:

② ServerSocket 方法:

2)Socket API :既会给服务器用,又会给客户端用
Socket 是客户端Socket,或服务端中接收到客户端建立连接(accept方法)的请求后,返回的服务端Socket。
不管是客户端还是服务端Socket,都是双方建立连接以后,保存的对端信息,即用来与对方收发数据的。
① Socket 构造方法:

② Socket 方法:

TCP中的长短连接
- TCP发送数据时,需要先建立连接,什么时候关闭连接就决定是短连接还是长连接:
- 短连接:每次接收到数据并返回响应后都关闭连接,即是短连接。也就是说,短连接只能一次收发数据。
- 长连接:不关闭连接,一直保持连接状态,双方不停的收发数据,即是长连接。也就是说,长连接可以多次收发数据。
- 对比以上长短连接,两者区别如下:
① 建立连接、关闭连接的耗时:短连接每次请求、响应都需要建立连接,关闭连接;而长连接只需要第一次建立连接,之后的请求、响应都可以直接传输。相对来说建立连接、关闭连接也是要耗时的,长连接效率更高。
② 主动发送请求不同:短连接一般是客户端主动向服务端发送请求;而长连接可以是客户端主动发送请求,也可以是服务端主动发。
③ 两者的使用场景有不同:短连接适用于客户端请求频率不高的场景,如浏览网页等。长连接适用于客户端与服务端通信频繁的场景,如聊天室,实时游戏等。 - 扩展了解:
基于BIO(同步阻塞IO)的长连接会一直占用系统资源。对于并发要求很高的服务端系统来说,这样的消耗是不能承受的。
由于每个连接都需要不停的阻塞等待接收数据,所以每个连接都会在一个线程中运行。
一次阻塞等待对应着一次请求、响应,不停处理也就是长连接的特性:一直不关闭连接,不停的处理请求。
实际应用时,服务端一般是基于NIO(即同步非阻塞IO)来实现长连接,性能可以极大的提升。
【关于TCP版本的客户端和服务器程序:回显】
(TCP是有、可、字节流)
- TCP回显服务器:
为啥循环中要关闭clientsocket,而前面的listenSocket以及udp程序中的socket为啥没关闭?
理由:socket也是文件,而一个进程能够打开的文件个数是有上限的(因为PCB文件描述符表不是无限的)。listenSocket在TCP服务器程序中只有唯一的对象,就不太会把文件描述符表占满;而clientSocket则是在循环中,也就是说每个客户端进来都要分配一个,则该对象就会被反复创建出实例,每创建一个实例对象都要消耗一个文件描述符表,因此就需要把不再使用的clientSocket释放掉。 - 注意:要先启动服务器,然后再启动客户端
- 会发现,如果多个客户端同时启动使用的话,只有其中一个会有响应,其余都没有,此时:
如果客户端没有没有建立连接,此时服务器就会阻塞到accept;
而如果有一个客户端过来了,此时就会进入processConnection方法中,如果此时客户端没有发消息则代码会阻塞在hasNext处,所以此时就无法第二次调用accept,也就没办法处理第二个客户端了
==》此时其实就是希望:既能够快速重复的调用accept,又能够循环的处理客户端的请求
==》所以就使用多线程处理processConnection:每个客户端进来都分配一个新的线程负责处理
==》但是依旧有频繁创建、释放线程的开销,所以改为使用线程池(注意创建方式!)
- 为啥TCP有这个无法响应问题,而UDP没有呢?是和UDP无连接有关系吗?
有点关系。
但是主要关系:UDP客户端直接发送消息即可,不必专注于处理某个客户端;而TCP建立连接之后要处理客户端的多次请求才导致无法快速的调用到accept(长连接:一次处理多个请求);如果TCP每个连接只处理一个客户端的请求,此时是能够保证快速调用到accept的(短连接:一次处理一个请求)
(IO流对象本身是线程安全的)
代码参考:
TCP回显

五、再谈协议(了解,可以先略过)
- 回顾并理解为什么需要协议
以上我们实现的UDP和TCP数据传输,除了UDP和TCP协议外,程序还存在应用层自定义协议,可以想想分别都是什么样的协议格式。
对于客户端及服务端应用程序来说,请求和响应,需要约定一致的数据格式:
- 客户端发送请求和服务端解析请求要使用相同的数据格式。
- 服务端返回响应和客户端解析响应也要使用相同的数据格式。
- 请求格式和响应格式可以相同,也可以不同。
- 约定相同的数据格式,主要目的是为了让接收端在解析的时候明确如何解析数据中的各个字段。
- 可以使用知名协议(广泛使用的协议格式),如果想自己约定数据格式,就属于自定义协议。
- 封装/分用 vs 序列化/反序列化
1)一般来说,在网络数据传输中,发送端应用程序,发送数据时的数据转换(如java一般就是将对象转换为某种协议格式),即对发送数据时的数据包装动作来说:
- 如果是使用知名协议,这个动作也称为封装
- 如果是使用小众协议(包括自定义协议),这个动作也称为序列化,一般是将程序中的对象转换为特定的数据格式。
2)接收端应用程序,接收数据时的数据转换,即对接收数据时的数据解析动作来说:
- 如果是使用知名协议,这个动作也称为分用
- 如果是使用小众协议(包括自定义协议),这个动作也称为反序列化,一般是基于接收数据特定的格式,转换为程序中的对象
- 如何设计协议
对于协议来说,重点需要约定好如何解析,一般是根据字段的特点来设计协议:
① 对于定长的字段: 可以基于长度约定,如int字段,约定好4个字节即可
② 对于不定长的字段:可以约定字段之间的间隔符,或最后一个字段的结束符,如换行符间隔,\3符号结束等等
③ 除了该字段“数据”本身,再加一个长度字段,用来标识该“数据”长度;即总共使用两个字段:
“数据”字段本身,不定长,需要通过“长度”字段来解析;
“长度”字段,标识该“数据”的长度,即用于辅助解析“数据”字段。
THINK
【回顾】
- UDP:DatagramSocket网卡的代言人,借助这个类来读写网卡; DatagramPacket一个数据报的代言人,UDP中传输数据的基本单位。
- TCP:ServerSocket:给服务器用的,监听端口;
Socket:给服务器和客户端用的,用来传输数据。 - 注意TCP和UDP区别
- 重点是TCP和UDP的实例代码!

![[附源码]java毕业设计科院垃圾分类系统](https://img-blog.csdnimg.cn/79be43367810495daa565a357a10ad83.png)

![[附源码]Python计算机毕业设计 家乡旅游文化推广网站](https://img-blog.csdnimg.cn/5ff7bc31ff694d8ca2d44f4aa9ae92d4.png)

![[力扣] 剑指 Offer 第二天 - 复杂链表的复制](https://img-blog.csdnimg.cn/5dedb2575c7c4a74a5de4d13c3525474.png)