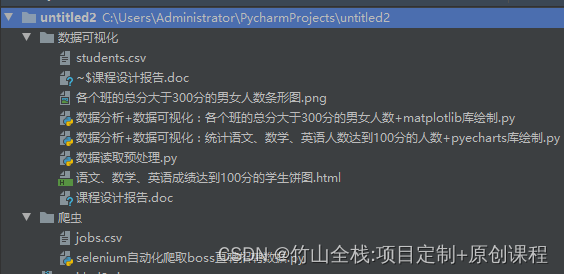
这是一个数据分析可视化课程的结课作业设计,受人所托写的,现在分享出来,有需要的同学自取哈,以下是文件目录,包括数据分析和爬虫代码都有,下载下来当一个demo也还是不错的,这篇博客就是文档里的内容哈,和nice的一个报告,本人亲自设计写的,代码也是
目录
第一部分 选取数据 3
第二部分 读取数据和处理数据 5
第三部分 数据分析 5
1.各个班总分大于300分的男女人数 6
2.各科成绩达100分的人数 6
第四部分 绘制数据分析的可视化图形 5
1.matplotlib绘制条形图 6
2.pyecharts绘制饼图 6
第五部分 心得总结 5
第一部分 分析目的
分析目的是基于高三学生三个班级的学生成绩数据,通过统计和可视化总分大于300分的男女人数情况,以及语文、数学、英语成绩等各科达到100分的学生人数,深入了解学生的学业表现。这有助于识别学科学习中的优势和劣势,发现性别在学业成绩方面的差异,为学校和教师提供有针对性的教学和辅导方案,以促进学生的全面发展。
第二部分 数据预处理
1)预处理输出结果
2)详细代码
读取数据、数据清洗
data = pd.read_csv(‘students.csv’, encoding=‘utf-8’)
数据清洗处理:去除缺失值、异常值和重复值
data = data.dropna() # 去除缺失值
data = data[(data[‘数学’] >= 0) & (data[‘数学’] <= 150) & # 去除数学成绩异常值
(data[‘语文’] >= 0) & (data[‘语文’] <= 150) & # 去除语文成绩异常值
(data[‘英语’] >= 0) & (data[‘英语’] <= 150)] # 去除英语成绩异常值
data = data.drop_duplicates() # 去除重复值
打印处理后的数据
print(data)
3)实现细节介绍
数据清洗的过程包括以下步骤:首先,使用pd.read_csv()函数读取名为’students.csv’的数据文件;然后,通过data.dropna()方法去除缺失值;接着,通过设定条件(data[‘数学’] >= 0) & (data[‘数学’] <= 150)等去除数学、语文、英语成绩的异常值;最后,使用data.drop_duplicates()方法去除重复值。经过这些步骤,数据中的缺失值、异常值和重复值得到了清洗和处理。
第三部分 数据分析
1.分析各个班总分大于300分的男女人数
1.1 代码如下
各个班的总分大于300分的男女人数数据分析
def analyze_data(df):
# 计算总分
df[‘ljp总分’] = df[‘ljp语文’] + df[‘ljp数学’] + df[‘ljp英语’]
# 过滤出总分大于300的数据
df_filtered = df[df['ljp总分'] > 300]
# 统计各个班的总分大于300分的男女人数
class_gender_total = df_filtered.groupby(['ljp班级', 'ljp性别']).size().unstack(fill_value=0)
print(class_gender_total)
return class_gender_total1.2 文字介绍
代码实现了对学生数据的分析,具体包括以下步骤:
首先,您计算了每个学生的总分,通过将语文、数学和英语成绩相加得到了每个学生的总分。
然后,您筛选出了总分大于300分的学生数据,这可能代表着学业成绩较好的学生群体。
接着,您对这些数据进行了按班级和性别进行分组统计,以统计各个班的总分大于300分的男女人数。
这个数据分析具有一定的现实意义,可以帮助学校了解学生学业表现的情况,以便采取针对性的教学措施。这种分析可以帮助学校发现学业表现较好的学生群体,从而对这些学生提供更有针对性的教学和辅导。
2.分析各科成绩达100分的人数
2.1 代码
def data_analysis(data):
# 数据分析统计语文、数学、英语成绩达到100分的学生人数
chinese_100 = data[data[‘ljp语文’] == 100].shape[0]
math_100 = data[data[‘ljp数学’] == 100].shape[0]
english_100 = data[data[‘ljp英语’] == 100].shape[0]
result = [(“语文>100分人数”, chinese_100), (“数学>100分人数”, math_100), (“英语>100分人数”, english_100)]
print(result)
return result2.2 文字介绍
上述代码中的data_analysis函数是对数据进行分析的函数,具体来说,它统计了语文、数学、英语成绩达到100分的学生人数,并将结果存储在一个列表中返回。以下是对函数实现的详细介绍:
data[data['ljp语文'] == 100]筛选出语文成绩等于100分的学生数据,.shape[0]获取筛选结果的行数,即语文成绩等于100分的学生人数。data[data['ljp数学'] == 100]筛选出数学成绩等于100分的学生数据,.shape[0]获取筛选结果的行数,即数学成绩等于100分的学生人数。data[data['ljp英语'] == 100]筛选出英语成绩等于100分的学生数据,.shape[0]获取筛选结果的行数,即英语成绩等于100分的学生人数。- 将语文、数学、英语成绩等于100分的学生人数存储在一个列表中,列表中的每个元素是一个二元组,第一个元素是科目名称,第二个元素是对应科目成绩等于100分的学生人数。
- 最后,函数输出列表并返回。
第四部分数据分析
1.matplotlib绘制各个班总分大于300分的男女人数的条形图
这张图展示了各个班级总分大于300分的男女人数。其中,每个班级的男女人数分别用不同的颜色表示,男性用蓝色表示,女性用橙色表示。我们可以看到,班级1和班级3的男女人数都比较均衡,班级1和班级2的男女人数差别比较大。同时,我们也可以看到,班级2和班级3的总分大于300分的学生人数比较多,班级1的总分大于300分的学生人数比较少。
代码
数据分析
class_gender_totals = analyze_data(df)
数据可视化
class_gender_totals.plot(kind=‘bar’, stacked=True)
ax = class_gender_totals.plot(kind=‘bar’, stacked=True)
ax.set_xticklabels(class_gender_totals.index, rotation=0) # 设置x轴标签的旋转角度
plt.title(‘各个班的总分大于300分的男女人数’)
plt.xlabel(‘班级’)
plt.ylabel(‘人数’)
plt.show()
代码中,我们首先调用了analyze_data函数对数据进行分析,得到各个班级总分大于300分的男女人数的数据。然后,我们使用plot函数绘制了一个堆叠条形图。其中,kind='bar'表示绘制条形图,stacked=True表示堆叠显示男女人数。接着,我们设置了x轴标签的旋转角度为0,以便更清晰地显示班级名称。最后,我们设置了图表的标题、x轴标签和y轴标签,并使用show函数显示图表。
2.pyecharts绘制语文、数学、英语成绩达到100分的学生饼图
这张饼图展示了语文、数学、英语成绩达到100分的学生人数的占比情况。每个扇形部分代表一个科目,扇形的大小表示该科目成绩达到100分的学生人数在总人数中的占比。通过这个饼图,我们可以清晰地看到每个科目的成绩达到100分的学生人数在总人数中的比例。
def visualize_pie_chart(result):
# 使用pyecharts绘制饼图
pie_scores = (
Pie()
.add(“”, result)
.set_global_opts(title_opts=opts.TitleOpts(title=“语文、数学、英语成绩达到100分的学生饼图”))
)
pie_scores.render(“C:\Users\Administrator\PycharmProjects\untitled2\数据可视化\语文、数学、英语成绩达到100分的学生饼图.html”)
上述代码中的visualize_pie_chart函数使用了Pyecharts库来绘制饼图。具体来说,它接受一个result参数,该参数是一个包含了语文、数学、英语成绩达到100分的学生人数的数据。然后,函数使用Pyecharts的Pie类来创建一个饼图,并将result作为数据添加到饼图中。接着,函数设置了饼图的全局选项,包括了标题为"语文、数学、英语成绩达到100分的学生饼图"。最后,函数使用render方法将饼图保存为一个HTML文件。
第五部分 设计总结和心得体会
在完成这次数据分析统计课程的作业过程中,我学到了很多关于数据处理分析和可视化的知识和技能。通过这次作业,我对数据的预处理有了更深入的理解,包括如何去除缺失值、异常值和重复值,确保数据的准确性和完整性。同时,我也学会了如何使用不同的可视化方法来呈现数据,比如散点图、直方图、热力图和箱线图等,这些图表可以帮助我更直观地了解数据的分布情况和特征。
在完成作业的过程中,我也发现了数据分析和可视化的重要性。通过可视化图表,我能够更清晰地了解数据的特征和规律,从而做出更准确的分析和判断。同时,我也意识到了数据分析的技能对于未来的学习和工作是非常重要的,它不仅可以帮助我更好地理解和利用数据,还可以提高我的数据思维和解决问题的能力。
通过这次作业,我对数据分析和统计有了更深入的认识,也提高了自己的数据处理和可视化能力。我相信这些知识和技能会对我的未来学习和工作产生积极的影响,我会继续努力学习和提升自己在数据分析领域的能力。