Python使用SQLAlchemy操作sqlite
- sqllite
- 1. SQLite的简介
- 2. 在 Windows 上安装 SQLite
- 3. 使用SQLite创建数据库
- 3.1 命令行创建数据库
- 3.2 navicat连接数据库
- 4.sqlite的数据类型
- 存储类
- SQLite Affinity 类型
- Boolean 数据类型
- Date 与 Time 数据类型
- 5. 常用的sql语法
- **创建表(CREATE TABLE)**
- **插入数据 (INSERT INTO)**
- **查询数据 (SELECT)**
- **更新数据 (UPDATE)**
- **删除数据 (DELETE)**
- **SQLite Glob 子句**
- **SQLite Limit 子句**
- **SQLite Order By 子句**
- **SQLite Group By 子句**
- **SQLite Having 子句**
- **SQLite Distinct 关键字**
- 聚合函数 (SUM, AVG, COUNT, MAX, MIN)
- **联合查询 (JOIN)**
- **创建视图 (CREATE VIEW)**
- **添加索引 (CREATE INDEX)**
- 6.Python使用SQLAlchemy操作sqlite
- 6.1 安装SQLAlchemy
- 6.2 创建实现脚本
sqllite
1. SQLite的简介
SQLite(Structured Query Language - Lite)是一种轻量级的嵌入式关系型数据库管理系统(RDBMS)。以下是一些关于SQLite的简介:
- 轻量级: SQLite 是一个轻量级的数据库引擎,完全配置时小于 400KiB,省略可选功能配置时小于250KiB
- 嵌入式数据库: SQLite 是一个嵌入式数据库,这意味着它可以被嵌入到应用程序中,而不需要一个独立的数据库服务器。这使得它非常适合嵌入到移动应用、桌面应用和其他小型项目中。
- 零配置: SQLite 不需要服务器进程和配置文件。你只需创建一个数据库文件,然后可以在应用程序中直接使用。
- 完全兼容 ACID: SQLite 事务是完全兼容 ACID 的,允许从多个进程或线程安全访问。
- 支持标准的 SQL 语法: SQLite 支持大部分标准的 SQL 语法,因此你可以使用常见的 SQL 查询和操作语句。
- 事务支持: SQLite 提供了对事务的支持,这对于确保数据库的一致性和可靠性非常重要。
- 跨平台: SQLite 可以在多个操作系统上运行,包括Windows、Linux、macOS等。
- 无服务器体系结构: 与传统的客户端-服务器数据库管理系统不同,SQLite 没有独立的服务器进程。数据库引擎直接嵌入到应用程序中。
- 自包含: SQLite 数据库是一个单一的独立文件,包含整个数据库结构和数据。这使得数据库的传输和备份变得相对简单。
2. 在 Windows 上安装 SQLite
- 进入官网下载:SQLite Download Page
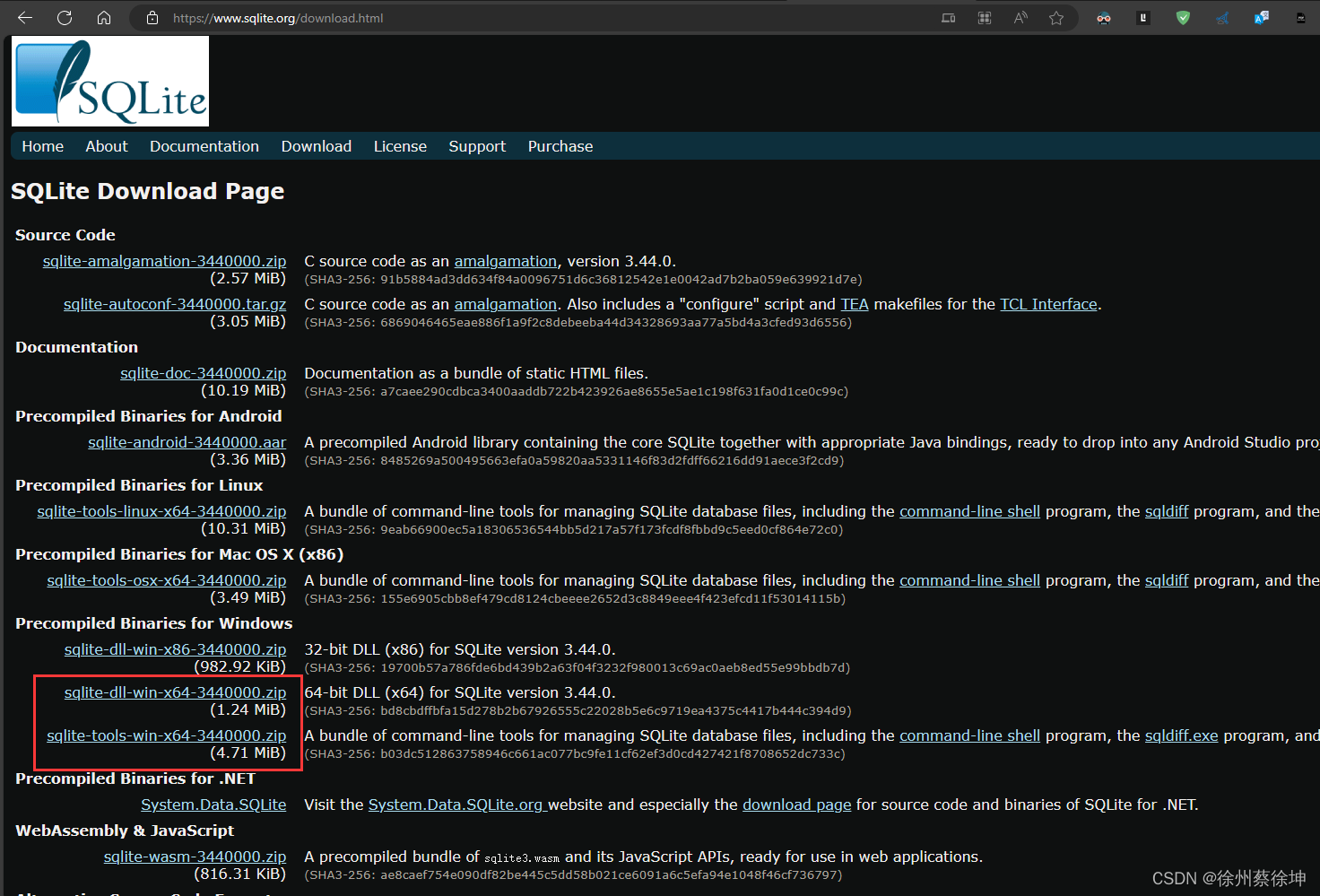
-
解压到指定文件夹,解压后如下
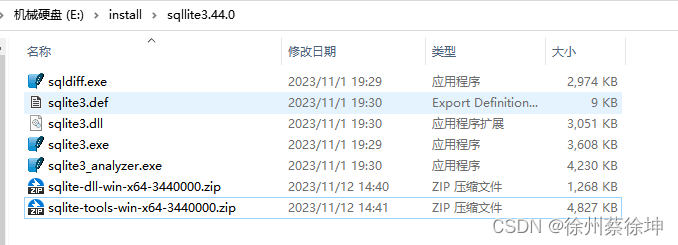
-
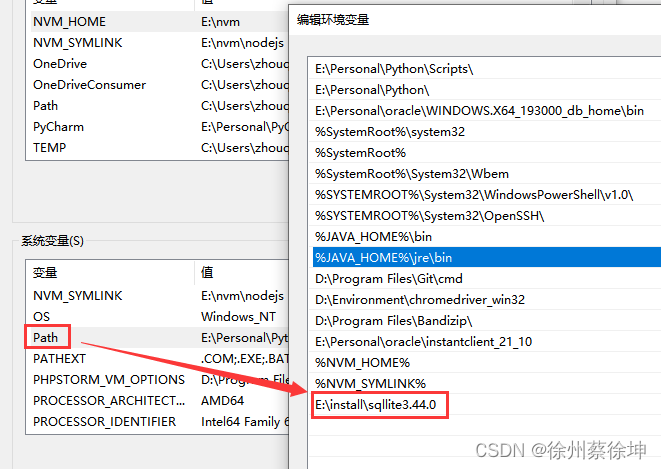
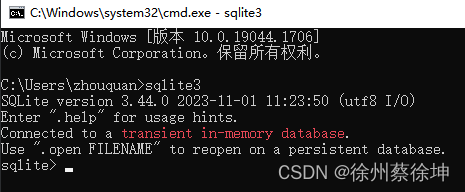
配置环境变量:添加 E:\install\sqllite3.44.0 到 PATH 环境变量,最后在命令提示符下,使用 sqlite3 命令,将显示如下结果。
3. 使用SQLite创建数据库
3.1 命令行创建数据库
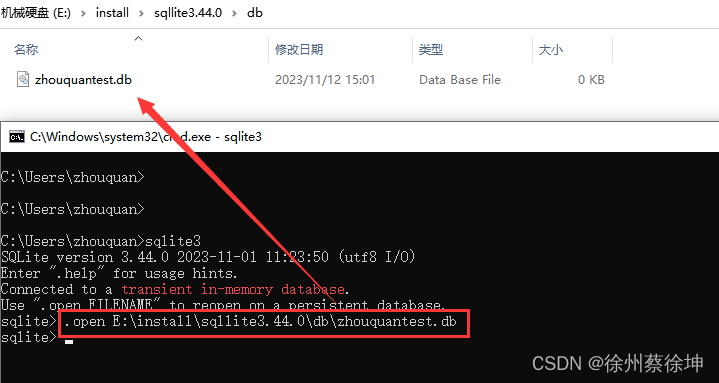
# 语法:.open [路径+数据库名字]
.open E:\install\sqllite3.44.0\db\zhouquantest.db
3.2 navicat连接数据库
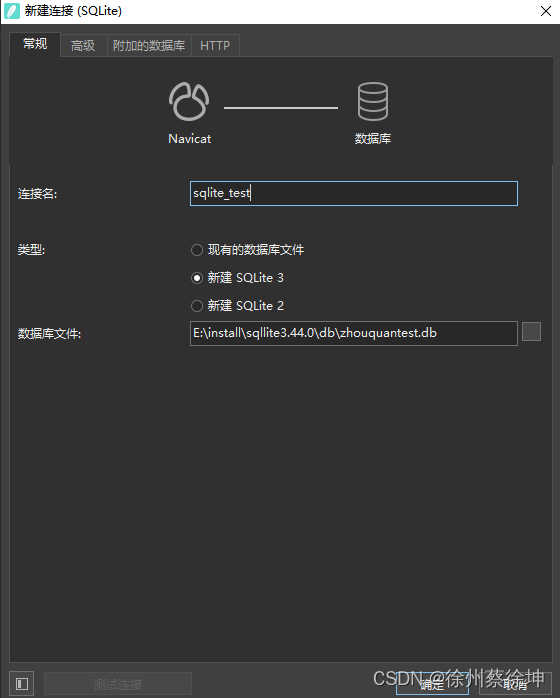
4.sqlite的数据类型
存储类
| 存储类 | 字段描述 |
|---|---|
| NULL | 值是一个 NULL 值。 |
| INTEGER | 值是一个带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中。 |
| REAL | 值是一个浮点值,存储为 8 字节的 IEEE 浮点数字。 |
| TEXT | 值是一个文本字符串,使用数据库编码(UTF-8、UTF-16BE 或 UTF-16LE)存储。 |
| BLOB | 值是一个 blob 数据,完全根据它的输入存储。 |
SQLite Affinity 类型
SQLite 支持列上的类型 affinity 概念。任何列仍然可以存储任何类型的数据,但列的首选存储类是它的 affinity。在 SQLite3 数据库中,每个表的列分配为以下类型的 affinity 之一:
| Affinity | 描述 |
|---|---|
| TEXT | 该列使用存储类 NULL、TEXT 或 BLOB 存储所有数据。 |
| NUMERIC | 该列可以包含使用所有五个存储类的值。 |
| INTEGER | 与带有 NUMERIC affinity 的列相同,在 CAST 表达式中带有异常。 |
| REAL | 与带有 NUMERIC affinity 的列相似,不同的是,它会强制把整数值转换为浮点表示。 |
| NONE | 带有 affinity NONE 的列,不会优先使用哪个存储类,也不会尝试把数据从一个存储类强制转换为另一个存储类。 |
Boolean 数据类型
SQLite 没有单独的 Boolean 存储类。相反,布尔值被存储为整数 0(false)和 1(true)。
Date 与 Time 数据类型
SQLite 没有一个单独的用于存储日期和/或时间的存储类,但 SQLite 能够把日期和时间存储为 TEXT、REAL 或 INTEGER 值。
| 存储类 | 日期格式 |
|---|---|
| TEXT | 格式为 “YYYY-MM-DD HH:MM:SS.SSS” 的日期。 |
| REAL | 从公元前 4714 年 11 月 24 日格林尼治时间的正午开始算起的天数。 |
| INTEGER | 从 1970-01-01 00:00:00 UTC 算起的秒数。 |
您可以以任何上述格式来存储日期和时间,并且可以使用内置的日期和时间函数来自由转换不同格式。
5. 常用的sql语法
创建表(CREATE TABLE)
CREATE TABLE employees (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER,
department TEXT
);
插入数据 (INSERT INTO)
INSERT INTO employees (name, age, department)
VALUES ('蔡徐坤', 30, 'dev');
INSERT INTO employees (name, age, department)
VALUES ('鸡哥', 28, 'net');
查询数据 (SELECT)
-
查询所有列:
SELECT * FROM employees; -
查询特定列:
SELECT name, age FROM employees; -
使用条件查询:
SELECT * FROM employees WHERE department = 'net'; -
使用通配符查询:
SELECT * FROM employees WHERE name LIKE '蔡%';
更新数据 (UPDATE)
UPDATE employees
SET age = 31
WHERE name = '蔡徐坤';
删除数据 (DELETE)
DELETE FROM employees
WHERE name = '鸡哥';
SQLite Glob 子句
Glob 子句用于执行基于模式匹配的字符串比较。
SELECT * FROM employees
WHERE name GLOB '蔡*';
SQLite Limit 子句
LIMIT 子句用于限制查询结果的行数。
SELECT * FROM employees
LIMIT 5;
SQLite Order By 子句
ORDER BY 子句用于对查询结果进行排序。
SELECT * FROM employees
ORDER BY age DESC;
SQLite Group By 子句
GROUP BY 子句用于对查询结果进行分组。
SELECT department, AVG(age) as avg_age
FROM employees
GROUP BY department;
SQLite Having 子句
HAVING 子句用于在 GROUP BY 子句中对分组进行过滤。
SELECT department, AVG(age) as avg_age
FROM employees
GROUP BY department
HAVING AVG(age) > 30;
SQLite Distinct 关键字
DISTINCT 关键字用于返回唯一的值,去除重复。
SELECT DISTINCT department FROM employees;
聚合函数 (SUM, AVG, COUNT, MAX, MIN)
-
计算年龄:
SELECT AVG(age),MAX(age),MIN(age) FROM employees; -
计算部门人数:
SELECT department, COUNT(*) as num_employees FROM employees GROUP BY department;
联合查询 (JOIN)
-- 创建部门表
CREATE TABLE departments (
id INTEGER PRIMARY KEY,
short_name TEXT,
name TEXT
);
-- 插入数据
INSERT INTO departments (short_name,name)
VALUES ('dev','开发部'), ('net','网络部');
-- 关联查询
SELECT employees.name, employees.age, departments.name as department
FROM employees
JOIN departments ON employees.department = departments.short_name;
创建视图 (CREATE VIEW)
CREATE VIEW view_employee_summary AS
SELECT department, AVG(age) as avg_age, COUNT(*) as num_employees
FROM employees
GROUP BY department;
添加索引 (CREATE INDEX)
CREATE INDEX idx_department ON employees (department);
6.Python使用SQLAlchemy操作sqlite
创建一个python项目
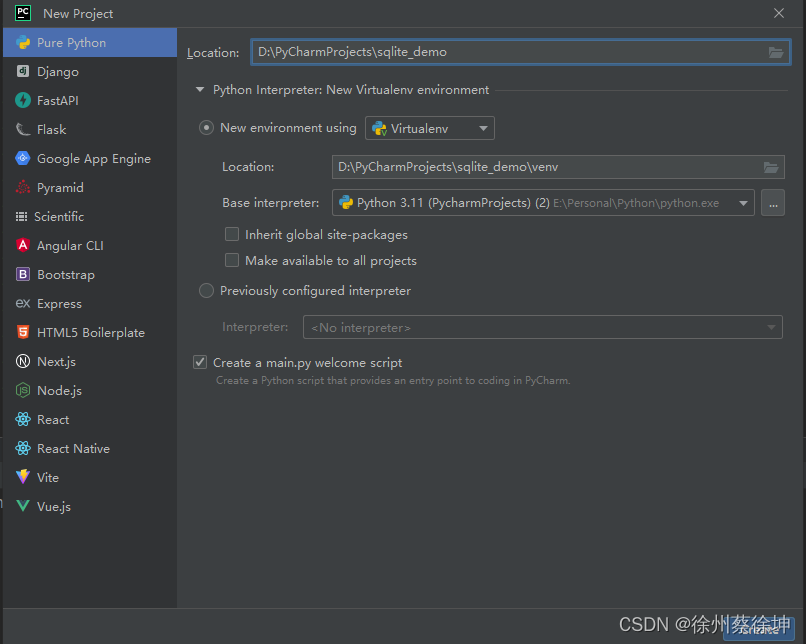
6.1 安装SQLAlchemy
SQLAlchemy 是一个强大的 SQL 工具包和对象关系映射(ORM)库,它允许在 Python 中更方便地与数据库进行交互
使用以下命令安装:
pip install SQLAlchemy
6.2 创建实现脚本
from sqlalchemy import create_engine, Column, Integer, String, Sequence
from sqlalchemy.orm import declarative_base, sessionmaker
# 创建一个SQLite数据库引擎
# sqlite:/// 表示 SQLite 数据库连接协议
# students.db 是 SQLite 数据库文件的名称
# echo=True将SQL语句打印到控制台
engine = create_engine('sqlite:///students.db', echo=True)
# 创建一个基类,用于声明类定义
Base = declarative_base()
# 定义Student类
class Student(Base):
__tablename__ = 'students'
id = Column(Integer, Sequence('student_id_seq'), primary_key=True)
name = Column(String(50), nullable=False)
age = Column(Integer)
grade = Column(String(10))
# 创建"students"表
Base.metadata.create_all(engine)
# 创建一个用于数据库交互的Session类
Session = sessionmaker(bind=engine)
session = Session()
# 新增
student1 = Student(id=1, name='小明', age=20, grade='A')
student2 = Student(id=2, name='小红', age=22, grade='B')
student3 = Student(id=3, name='小菜', age=21, grade='B')
student4 = Student(id=4, name='小坤', age=23, grade='A')
# 如果需要新增则取消下面两行注释
# session.add_all([student1, student2, student3, student4])
# session.commit()
# 查询并打印
print("所有学生:")
students = session.query(Student).all()
for student in students:
print(f"ID: {student.id}, 姓名: {student.name}, 年龄: {student.age}, 成绩: {student.grade}")
# 查询指定学生
specific_student = session.query(Student).filter_by(name='小明').first()
if specific_student:
print(f"\n特定学生: ID: {specific_student.id}, 姓名: {specific_student.name},"
f" 年龄: {specific_student.age}, 成绩: {specific_student.grade}")
else:
print("\n未找到特定学生")
# 更新学生的成绩
update_student = session.query(Student).filter_by(name='小红').first()
if update_student:
update_student.grade = 'A'
session.commit()
print("\n成绩已更新")
else:
print("\n未找到学生")
# 删除学生
delete_student = session.query(Student).filter_by(name='小明').first()
if delete_student:
session.delete(delete_student)
session.commit()
print("\n学生已删除")
else:
print("\n未找到学生")
# 关闭Session
session.close()