基于WIN10的64位系统演示
一、写在前面
从这一期开始,我们杀个回马枪,继续学习深度学习图像分割系列,以为4090上岗了。
图像分割是计算机视觉的一个重要任务,目的是将数字图像分割成多个部分或区域,这些部分通常对应于现实世界中的物体或其组成部分。
(1)基本原理:图像分割的主要目标是为图像中的每个像素分配一个标签,从而将整个图像划分为多个不同的区域或物体。因此,本质上还是一个分类问题。
(2)常见应用:
(a)医学图像: 用于病灶检测、器官定位和疾病诊断。
(b)自动驾驶: 对周围环境进行实时分析,例如检测行人、车辆和道路。
(3)常见模型:
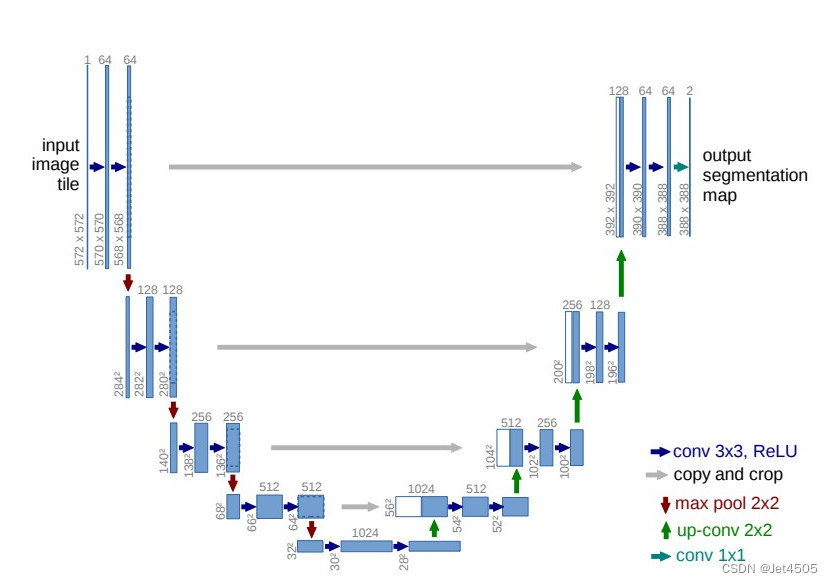
(a)U-Net: 该模型特别适用于医学图像分割。它有一个收缩的路径和一个对称的扩展路径,形成U型结构。
(b)Mask R-CNN: 在Faster R-CNN的基础上,增加了一个并行的分支来预测图像的分割掩模。
(c)FCN (Fully Convolutional Network): 第一个将深度卷积网络端到端应用于图像分割的方法。它使用上采样层将卷积特征图转换回像素级预测。
本期,我们来尝试一下U-Net。
二、U-Net
U-Net 是为生物医学图像分割而设计的一个深度学习模型,其名字“U-Net”来源于其U型的结构。
(1)架构:U-Net由两部分组成:一个“收缩”(或下采样)路径和一个“扩展”(或上采样)路径,这两个路径共同构成了一个U型结构。
(2)收缩路径:这是一个典型的卷积神经网络结构,包含了重复的两个3x3的卷积操作(每个后面都跟着ReLU激活函数),接着是一个2x2的最大池化操作来下采样。随着网络深入,特征通道的数量会加倍。此路径的目的是捕捉图像的上下文信息。
(3)扩展路径:为了得到精确的位置信息,U-Net使用了一个对称的扩展路径。
这个路径首先使用2x2的上采样操作,然后与相应的特征图进行连接,这种连接是为了获取更高分辨率的特征。接着,进行两次3x3的卷积操作,后面跟着ReLU激活函数。特征通道的数量随着网络深入而减半。
(4)跳跃连接:U-Net的一个关键特点是其跳跃连接(或称为“跳级连接”)。
在收缩路径中的每一步都有一个直接连接到扩展路径中相应步骤的连接,这保证了即使在深层网络中也能获取高分辨率的特征。
(5)最后的图层:在网络的最后是一个1x1的卷积层,用来将64个通道的特征向量映射到所需的输出类别数。
(2)数据源:
来源于公共数据,主要目的是使用U-Net分割出电子显微镜下的细胞边缘:
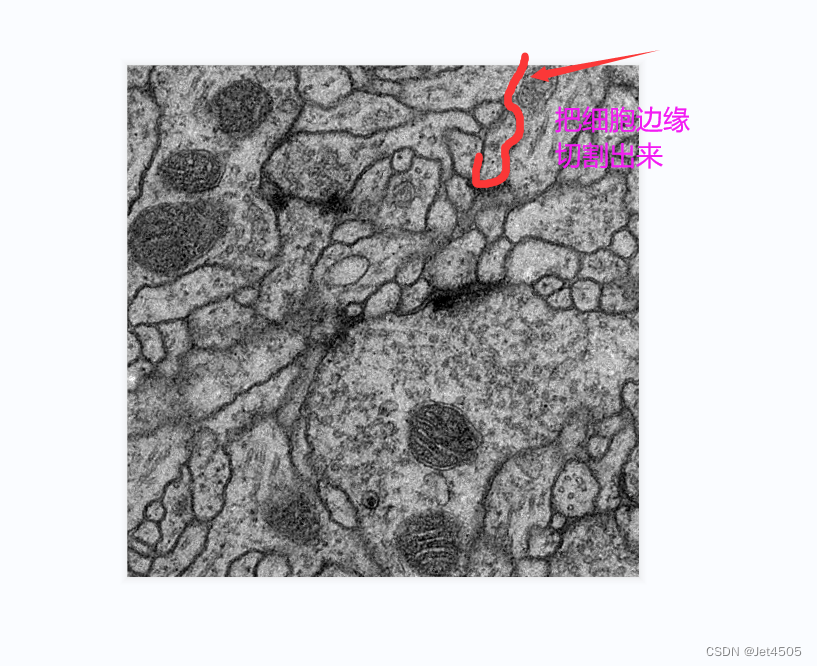
数据分为训练集(train)、训练集的细胞边缘数据(label)以及验证集(test),注意哈,没有提供验证集的细胞边缘数据。因此,后面是算不出验证集的性能参数的。




(2)U-Net实战:
上代码:
(a)数据读取和数据增强
import os
import numpy as np
from skimage.io import imread
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.layers import Input, Conv2D, MaxPooling2D, concatenate, UpSampling2D, Dropout, Softmax
from tensorflow.python.keras.optimizers import adam_v2
from tensorflow.python.keras.callbacks import ModelCheckpoint
import tensorflow as tf
physical_devices = tf.config.experimental.list_physical_devices('GPU')
if len(physical_devices) > 0:
tf.config.experimental.set_memory_growth(physical_devices[0], True)
# 设置文件路径
data_folder = 'U-net-master\data_set'
train_images_folder = os.path.join(data_folder, 'train')
label_images_folder = os.path.join(data_folder, 'label')
test_images_folder = os.path.join(data_folder, 'test')
train_images = sorted(os.listdir(train_images_folder))
label_images = sorted(os.listdir(label_images_folder))
test_images = sorted(os.listdir(test_images_folder))
# 读取训练和测试图像
X_train = np.array([imread(os.path.join(train_images_folder, img)) for img in train_images])
X_train = np.stack((X_train,)*3, axis=-1) # 复制通道以创建三通道图像
X_test = np.array([imread(os.path.join(test_images_folder, img)) for img in test_images])
X_test = np.stack((X_test,)*3, axis=-1)
y_train = np.array([imread(os.path.join(label_images_folder, img)) for img in label_images])
y_train = np.expand_dims(y_train, axis=-1) # 增加一个类别维度
# 定义数据增强生成器
data_gen_args = dict(rotation_range=0.2,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05,
zoom_range=0.05,
horizontal_flip=True,
rescale=1./255,
fill_mode='nearest')
image_datagen = ImageDataGenerator(**data_gen_args)
mask_datagen = ImageDataGenerator(**data_gen_args)
# 将种子提供给随机数生成器
seed = 1
# 将同样的种子应用于图像和标签以确保其转换方式相同
image_datagen.fit(X_train, augment=True, seed=seed)
mask_datagen.fit(y_train, augment=True, seed=seed)
image_generator = image_datagen.flow(X_train, batch_size=8, seed=seed)
mask_generator = mask_datagen.flow(y_train, batch_size=8, seed=seed)
# 将生成器组合成一个生成器,产生图像和标签
train_generator = zip(image_generator, mask_generator)
X_test = np.array([imread(os.path.join(test_images_folder, img)) for img in test_images])
X_test = np.stack((X_test,)*3, axis=-1) # 复制通道以创建三通道图像解读:
其他没什么好说的,就是要注意:上述代码的数据需要人工的安排训练集和测试集。严格按照下面格式放置好各个文件,包括文件夹的命名也不要变动:

(b)U-Net建模
# 定义U-Net模型结构
def get_unet(input_shape):
inputs = Input(input_shape)
# 下采样部分
c1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(inputs)
c1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(c1)
p1 = MaxPooling2D(pool_size=(2, 2))(c1)
c2 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(p1)
c2 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(c2)
p2 = MaxPooling2D(pool_size=(2, 2))(c2)
c3 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(p2)
c3 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(c3)
p3 = MaxPooling2D(pool_size=(2, 2))(c3)
c4 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(p3)
c4 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(c4)
drop4 = Dropout(0.5)(c4)
p4 = MaxPooling2D(pool_size=(2, 2))(drop4)
c5 = Conv2D(1024, 3, activation='relu', padding='same', kernel_initializer='he_normal')(p4)
c5 = Conv2D(1024, 3, activation='relu', padding='same', kernel_initializer='he_normal')(c5)
drop5 = Dropout(0.5)(c5)
# 上采样部分
u6 = UpSampling2D(size=(2, 2))(drop5)
u6 = Conv2D(512, 2, activation='relu', padding='same', kernel_initializer='he_normal')(u6)
merge6 = concatenate([drop4, u6], axis=3)
c6 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge6)
c6 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(c6)
u7 = UpSampling2D(size=(2, 2))(c6)
u7 = Conv2D(256, 2, activation='relu', padding='same', kernel_initializer='he_normal')(u7)
merge7 = concatenate([c3, u7], axis=3)
c7 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge7)
c7 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(c7)
u8 = UpSampling2D(size=(2, 2))(c7)
u8 = Conv2D(128, 2, activation='relu', padding='same', kernel_initializer='he_normal')(u8)
merge8 = concatenate([c2, u8], axis=3)
c8 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge8)
c8 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(c8)
u9 = UpSampling2D(size=(2, 2))(c8)
u9 = Conv2D(64, 2, activation='relu', padding='same', kernel_initializer='he_normal')(u9)
merge9 = concatenate([c1, u9], axis=3)
c9 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge9)
c9 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(c9)
c10 = Conv2D(1, 1, activation='sigmoid')(c9)
model = Model(inputs=[inputs], outputs=[c10])
return model
# 获取模型
model = get_unet(X_train.shape[1:])
# 编译模型
model.compile(optimizer=adam_v2.Adam(learning_rate=1e-4), loss='binary_crossentropy', metrics=['accuracy'])
# 设置模型检查点以保存训练中的最佳模型
model_checkpoint = ModelCheckpoint('unet_membrane.hdf5', monitor='loss', verbose=1, save_best_only=True)
# 训练模型
history = model.fit(train_generator, steps_per_epoch=len(X_train) // 16, epochs=100, verbose=1, callbacks=[model_checkpoint])让GPT解读:

可能是用了4090,1分钟不到:
(c)各种性能指标打印和可视化
###################################误差曲线#######################################
import matplotlib.pyplot as plt
# 设置matplotlib支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 绘制训练损失和准确率
plt.figure(figsize=(12, 5))
# 绘制损失
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='训练损失')
plt.title('损失随迭代次数的变化')
plt.xlabel('迭代次数')
plt.ylabel('损失')
plt.legend()
# 绘制准确率
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='训练准确率')
plt.title('准确率随迭代次数的变化')
plt.xlabel('迭代次数')
plt.ylabel('准确率')
plt.legend()
plt.tight_layout()
plt.show()
##############################评价指标#######################################
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, accuracy_score, recall_score, precision_score, f1_score
# 预测训练集
train_pred = model.predict(X_train)
# 确保y_train中的值是0或1
y_train[y_train == 255] = 1
def calc_iou(y_true, y_pred):
intersection = np.logical_and(y_true, y_pred)
union = np.logical_or(y_true, y_pred)
return np.sum(intersection) / np.sum(union)
# 计算ROC曲线
fpr_train, tpr_train, _ = roc_curve(y_train.ravel(), train_pred.ravel())
# 计算AUC
auc_train = auc(fpr_train, tpr_train)
# 计算其他评估指标
pixel_accuracy_train = accuracy_score(y_train.ravel(), train_pred.ravel() > 0.5)
iou_train = calc_iou(y_train, train_pred > 0.5)
accuracy_train = accuracy_score(y_train.ravel(), train_pred.ravel() > 0.5)
recall_train = recall_score(y_train.ravel(), train_pred.ravel() > 0.5)
precision_train = precision_score(y_train.ravel(), train_pred.ravel() > 0.5)
f1_train = f1_score(y_train.ravel(), train_pred.ravel() > 0.5)
# 绘制ROC曲线
plt.figure()
plt.plot(fpr_train, tpr_train, color='blue', lw=2, label='Train ROC curve (area = %0.2f)' % auc_train)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc='lower right')
plt.show()
# 定义指标列表
metrics = [
("Pixel Accuracy", pixel_accuracy_train),
("IoU", iou_train),
("Accuracy", accuracy_train),
("Recall", recall_train),
("Precision", precision_train),
("F1 Score", f1_train)
]
# 打印表格的头部
print("+-----------------+------------+")
print("| Metric | Value |")
print("+-----------------+------------+")
# 打印每个指标的值
for metric_name, metric_value in metrics:
print(f"| {metric_name:15} | {metric_value:.6f} |")
print("+-----------------+------------+")直接看结果:

误差和准确率曲线,看起来模型收敛的不错。

ROC曲线:这里存疑,感觉没啥意义,而且这个曲线看起来有问题,是一个三点折线。

一些性能指标,稍微解释,主要是前两个:
A)Pixel Accuracy:
定义:它是所有正确分类的像素总数与图像中所有像素的总数的比率。
计算:(正确预测的像素数量) / (所有像素数量)。
说明:这个指标评估了模型在每个像素级别上的准确性。但在某些场景中(尤其是当类别非常不平衡时),这个指标可能并不完全反映模型的表现。
B)IoU (Intersection over Union):
定义:对于每个类别,IoU 是该类别的预测结果(预测为该类别的像素)与真实标签之间的交集与并集的比率。
计算:(预测与真实标签的交集) / (预测与真实标签的并集)。
说明:它是一个很好的指标,因为它同时考虑了假阳性和假阴性,尤其在类别不平衡的情况下。
C)Accuracy:
定义:是所有正确分类的像素与所有像素的比例,通常与 Pixel Accuracy 相似。
计算:(正确预测的像素数量) / (所有像素数量)。
D)Recall (or Sensitivity or True Positive Rate):
定义:是真实正样本被正确预测的比例。
计算:(真阳性) / (真阳性 + 假阴性)。
说明:高召回率表示少数阳性样本不容易被漏掉。
E)Precision:
定义:是被预测为正的样本中实际为正的比例。
计算:(真阳性) / (真阳性 + 假阳性)。
说明:高精度表示假阳性的数量很少。
F)F1 Score:
定义:是精度和召回率的调和平均值。它考虑了假阳性和假阴性,并试图找到两者之间的平衡。
计算:2 × (精度 × 召回率) / (精度 + 召回率)。
说明:在不平衡类别的场景中,F1 Score 通常比单一的精度或召回率更有用。
(d)查看验证集具体分割情况
#看具体分割的效果
import matplotlib.pyplot as plt
# 选择一张测试图片
img_index = 3
test_img = X_test[img_index]
# 扩展维度以匹配模型输入,因为模型需要四个维度的输入,然后进行预测
test_img = np.expand_dims(test_img, axis=0)
pred = model.predict(test_img)
# 移除添加的维度,以便显示图像
pred_img = np.squeeze(pred)
# 使用matplotlib来展示原始图像和预测的分割图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title("Original Image")
plt.imshow(np.squeeze(test_img), cmap='gray')
plt.subplot(1, 2, 2)
plt.title("Predicted Segmentation")
plt.imshow(pred_img, cmap='gray')
plt.show()随意从验证集挑一张图片,查看分割效果:
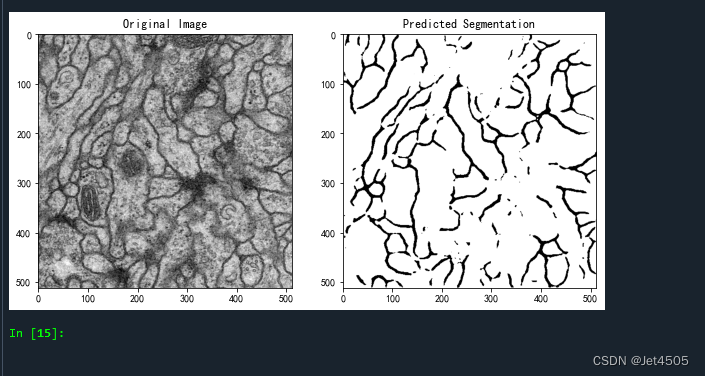
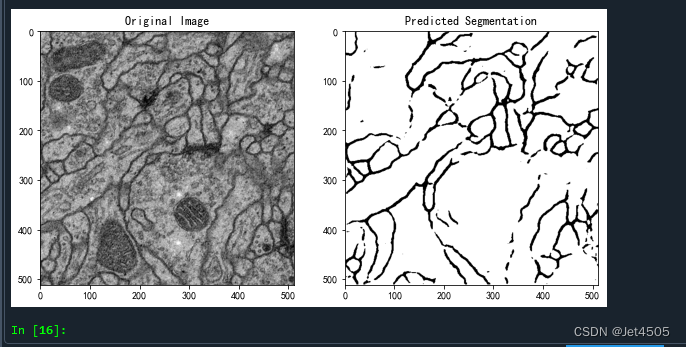
总体来看,勉强过关,收工!
四、写在后面
以上,只是U-Net的最简单的应用了,不过对于硬件要求还是挺高的,训练起来显卡可以煮鸡蛋的感觉。
后面会单独开个专栏,深入研究各种五花八门的数据应用。
五、数据
链接:https://pan.baidu.com/s/1Cb78MwfSBfLwlpIT0X3q9Q?pwd=u1q1
提取码:u1q1