一、伙伴算法的由来
在实际情况中,操作系统必须能够在任意时刻申请和释放任意大小的内存,该函数的实现需要考虑延时问题和碎片问题。
延时问题指的是系统查找到可分配单元的时间变长,例如程序请求分配一个64KB的内存空间,系统查看64KB空间发现不全是空余的,于是查看65KB的空间,发现仍不能满足需求,直到查看80KB空间时,才满足了需求,这种方式请求次数多达17次,频繁操作时,非常耗时。
若系统以较大的定长空间来分配内存,在一定程度上可以节省时间,但带来的是碎片过多问题,由于每次用较大的空间进行分配,系统中出现大量碎片,导致内存浪费。严重者会导致内存无法完成分配,虽然仍有许多碎片空间。
基于此,系统需要一种能够高效分配内存,同时又能减少产生碎片的算法,伙伴算法能有效地解决该问题,如今已成为操作系统中的一种基础算法。
二、基本原理
伙伴算法(Buddy system)把所有的空闲页框分为11个块链表,每块链表中分布包含特定的连续页框地址空间,比如第0个块链表包含大小为2^0个连续的页框,第1个块链表中,每个链表元素包含2个页框大小的连续地址空间,….,第10个块链表中,每个链表元素代表4M的连续地址空间。每个链表中元素的个数在系统初始化时决定,在执行过程中,动态变化。
伙伴算法每次只能分配2的幂次页的空间,比如一次分配1页,2页,4页,8页,…,1024页(2^10)等等,每页大小一般为4K,因此,伙伴算法最多一次能够分配4M的内存空间。
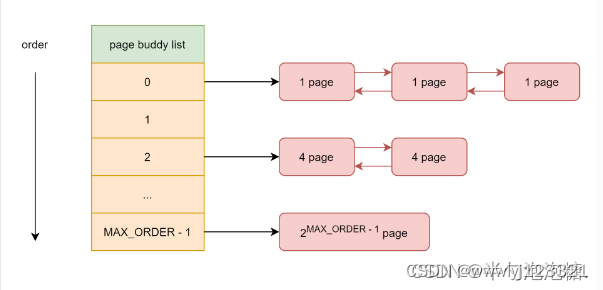
伙伴算法在内核中通常用free_area结构体表示,free_list链表数组,nr_free就是当前链表中空闲页框块数量。举例说明,free_area[2]中nr_free值为3,就是3个大小为4的页框块,总的空闲页就是3*4=12。
#define MAX_ORDER 11
struct free_area {//链表
struct list_head free_list[MIGRATE_TYPES];//页属性
unsigned long nr_free;//空闲页框块数目
};#define MAX_ORDER 11
struct zone{
struct free_area freearea[MAX_ORDER];
};
内存申请
例如需要分配16k的内存空间,算法会先从free_area[2]中查看nr_free是否为空,如果有空闲块,则从中分配,如果没有空闲块,就从它的上一级free_area[3](每块32K)中分配出16K,并将多余的内存(16K)加入到free_area[2]中去。如果free_area[3]也没有空闲,则从更上一级申请空间,依次递推,直到free_area[max_order],如果顶级都没有空间,那么就报告分配失败。
“伙伴关系”定义:
所谓“伙伴”,就是指在空闲块被分裂时,由同一个大块内存分裂出来的两个小块内存就互称“伙伴”。“伙伴”应当满足以下三个条件:
- 两个块大小相同
- 两个块地址连续
- 两个块必须是同一个大块中分离出来的
内存回收
回收是申请的逆过程,当释放一个内存块时,先在其对于的free_area链表中查找是否有伙伴存在,如果没有伙伴块,直接将释放的块插入链表头。如果有或板块的存在,则将其从链表摘下,合并成一个大块,然后继续查找合并后的块在更大一级链表中是否有伙伴的存在,直至不能合并或者已经合并至最大块2^10为止。
三、源码分析
获取物理页面的核心流程由alloc_pages()函数来完成
//定义一个函数alloc_pages,它接受两个参数:gfp(页面分配标志)和order(要分配的连续页面的数量,存在形式为2的order次幂个物理页面,就是页块在free_area数组中的索引)。函数返回一个指向struct page的指针
struct page *alloc_pages(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;//初始化为系统的默认内存策略
struct page *page;//保存分配到的页面的地址。
// 检查当前是否在中断上下文中,以及是否为特定节点分配页面
// 如果不在中断中并且没有为特定节点请求页面,则获取当前任务的内存策
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);//获取当前任务的内存策略
/*
* No reference counting needed for current->mempolicy
* nor system default_policy
*/
//判断内存策略的模式是否为交叉分配
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));//是多首选节点模式,根据指定的多首选节点策略分配页
else if (pol->mode == MPOL_PREFERRED_MANY)//如果是优先分配多个节点
page = alloc_pages_preferred_many(gfp, order,
policy_node(gfp, pol, numa_node_id()), pol);
else//均不是,使用__alloc_pages方法,传入相关的节点和nodemask信息
page = __alloc_pages(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;//返回分配到的页面的地址
}
四、调试
1. buddy_info
buddy info 描述了当前可用内存的分布情况,实际上就是每一个zone下的free_area结构体情况,每一列表示对应链表中对应的nr_free值。
# cat /proc/buddyinfo
Node 0, zone DMA 4 4 3 3 3 3 2 0 1 1 2
Node 0, zone Normal 140 90 34 5201 2816 556 29 0 0 0 0
Node 0, zone HighMem 0 2542 1859 253 961 3568 560 19 1 0 0 可以看到这份信息里面包含3个zone, DMA, Normal, HighMem。
DMA 行第3列表示有4个 2^2 × page_size 的内存块可以用
HighMem的第4列表示253个 2^3 × page_size 的内存块可以用
以此类推,越是往后的空间,就越是连续,数目越多,就代表这个大小的连续空间越多,当大的连续空间很少的时候,也就说明,内存碎片已经非常多了。
全部加起来就是当前free状态的内存size
ref:
伙伴算法学习笔记-CSDN博客
深入理解 Linux 物理内存分配全链路实现
https://www.cnblogs.com/cherishui/p/4246133.html
Linux内存分配与回收——伙伴算法_linux伙伴算法-CSDN博客
Linux 内存碎片化检视之 buddy_info | extfrag_index | unusable_index_cat /proc/buddyinfo-CSDN博客