作者:Insist--
个人主页:insist--个人主页
梦想从未散场,传奇永不落幕,博主会持续更新优质网络知识、Python知识、Linux知识以及各种小技巧,愿你我共同在CSDN进步
目录
一、Transformer架构
1. 自注意力层
2. 前馈神经网络层
3. Transformer编码器
4. Transformer解码器
二、训练过程
1. 预训练阶段
2. 微调阶段
三、生成文本
四、总结
前言
ChatGPT是一种基于Transformer架构的自然语言对话系统,通过预训练和微调阶段的学习,可以生成符合特定任务的文本。本文详细介绍了ChatGPT的工作原理,包括Transformer架构的组成和训练过程,以及如何使用解码器生成文本。

一、Transformer架构
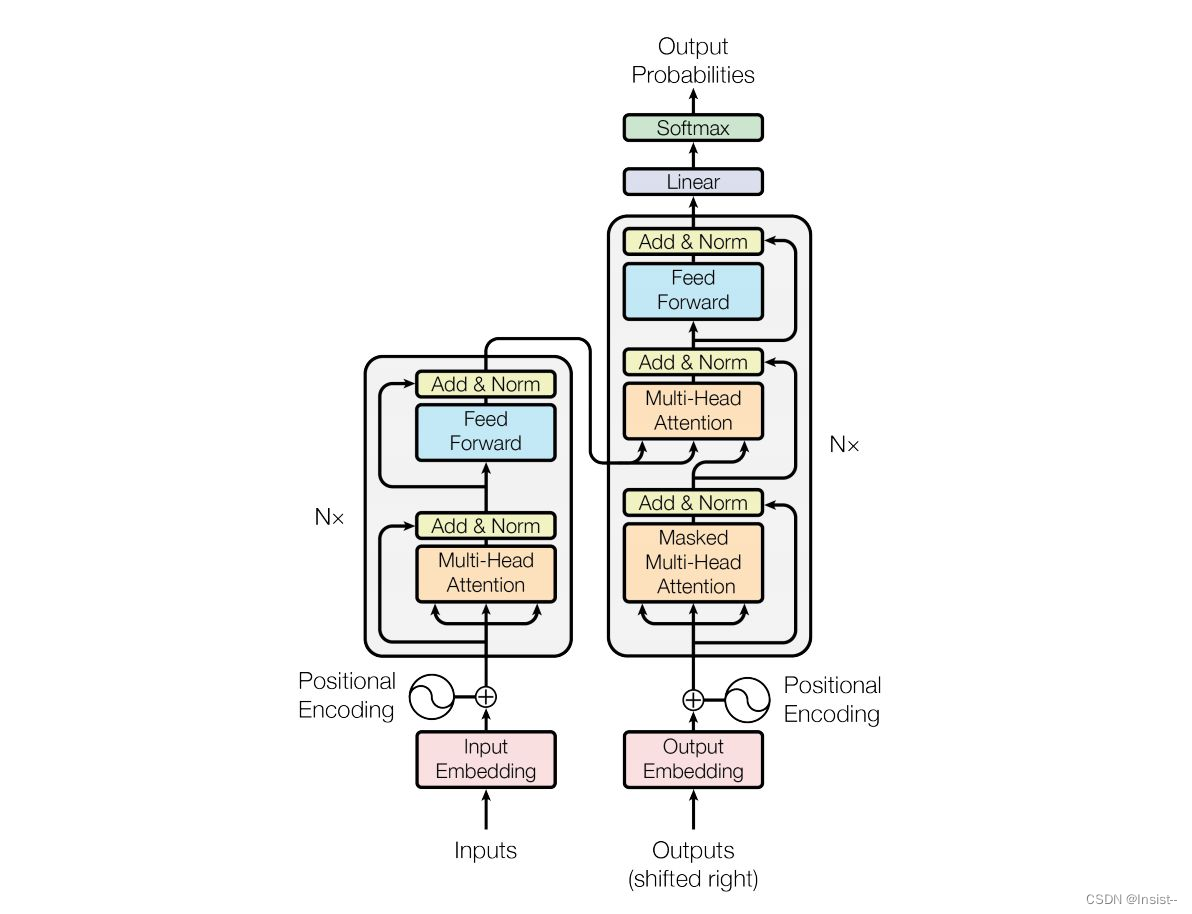
ChatGPT的核心是Transformer架构,它是一种深度学习模型,主要用于处理自然语言处理任务,如语言翻译、文本生成等。Transformer模型由多个自注意力层(Self-Attention Layer)和前馈神经网络层(Feed-Forward Neural Network Layer)组成。
1. 自注意力层
自注意力层是Transformer模型的核心部分,它通过计算输入序列中每个位置上的词向量之间的相似度来生成每个位置的表示向量。具体来说,自注意力层会对输入序列中的每个词向量进行加权平均,生成一个全局表示向量,这个向量可以捕捉到输入序列中的语义信息。
2. 前馈神经网络层
前馈神经网络层是一种全连接神经网络,它将自注意力层的输出向量进行进一步的处理,生成每个位置的输出向量。在前馈神经网络层中,每个位置的输出向量是由前一层中的隐藏状态和当前位置的输入向量共同决定的。
3. Transformer编码器
Transformer编码器是由多个自注意力层和前馈神经网络层交替堆叠而成的。它将输入序列分成若干个长度相等的块,并对每个块进行独立的编码。编码器的输出向量是所有块中对应位置的向量拼接而成。
4. Transformer解码器
Transformer解码器也是由多个自注意力层和前馈神经网络层交替堆叠而成的。它接收编码器的输出向量作为输入,并生成输出序列。在解码过程中,解码器会使用编码器输出的上下文向量(Context Vector)来指导输出序列的生成。
二、训练过程
ChatGPT的训练过程主要分为两个阶段:预训练阶段和微调阶段。
1. 预训练阶段
在预训练阶段,ChatGPT使用大量的语料库进行训练。语料库可以是互联网上的文本、社交媒体上的对话、新闻文章等等。ChatGPT将语料库中的文本视为输入序列,并使用Transformer编码器对其进行编码。编码器的输出向量被用作目标序列的表示向量。在这个阶段,ChatGPT会通过最小化预测误差来优化模型参数。
2. 微调阶段
在微调阶段,ChatGPT使用特定的任务数据进行训练,比如,对话数据、问题回答数据等等。这些任务数据通常会包含一些特定的问题和回答,用于指导模型的学习。在这个阶段,ChatGPT会使用目标序列的表示向量来生成输出序列。比如,对于对话任务,ChatGPT会根据用户输入的消息和之前的对话历史来生成回复。通过最小化损失函数,ChatGPT可以学习到如何生成符合特定任务的文本。
三、生成文本
在生成文本时,ChatGPT会使用解码器来生成输出序列。解码器会接收编码器的输出向量作为输入,并使用自注意力机制来生成每个位置的表示向量。然后,解码器会使用前馈神经网络层来生成每个位置的输出向量,并将这些向量拼接起来生成完整的输出序列。在生成文本的过程中,ChatGPT会根据任务数据中的上下文信息来指导生成过程,例如根据之前的对话历史来生成回复。
四、总结
ChatGPT是一种基于自然语言生成的对话系统,它使用Transformer架构来学习语言模型并生成输出文本。通过预训练和微调阶段的学习过程,ChatGPT可以学习到如何根据输入序列生成符合特定任务的文本。在生成文本时,ChatGPT会使用解码器来生成输出序列,并根据任务数据中的上下文信息来指导生成过程。通过这种方式,ChatGPT可以实现与用户进行自然流畅的对话交互。