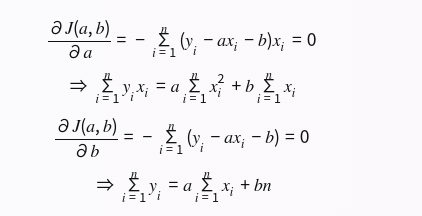目录
一、概览
二、文件操作
2.1 文件的打开、关闭
2.2 文件级操作
2.3 文件内容的操作
三、文件夹操作
四、常用技巧
五、常见使用场景
5.1 查找指定类型文件
5.2 查找指定名称的文件
5.3 查找指定名称的文件夹
5.4 指定路径查找包含指定内容的文件
一、概览
在工作中经常会遇到对文件,文件夹操作,在文件使用多时,使用python脚本是一种很便捷的方法,也可以实现一些工具如everything,notepad++无法实现的功能,更加灵活。本文将针对相关的基础操作进行介绍以及演示,其他的各种场景也都是基础操作的组合。

注:文章演示例子为window系统下的操作,python版本3.8.3,linux下类似,主要是路径格式和文件权限存在较大差异
二、文件操作
2.1 文件的打开、关闭
import os
#文件的打开、关闭
#方法一 使用open
file=open(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v",encoding="utf-8") #打开一个存在的文件counter.v,打开的编码格式为UTF-8,读取文件乱码内容大概率就是编码格式设置的不对,文件对象赋值给file
print("content:", file)
file2=open(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\test.v","a") #打开文件test.v,文件如果不存在时会自动创建test.v
file.close() #文件的关闭
#方法二 使用with
with open(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v") as f: #使用with相比方法一,会在执行完后自动释放资源,不会造成资源占用浪费
print("content:",f)open函数打开文件各选项配置参数含义

2.2 文件级操作
文件级操作主要包括文件的创建,删除,重命名,复制,移动。
import os
import shutil
#文件的创建,使用open打开要创建的文件,使用参数w即可,如指定路径下创建file.txt
with open(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\file.txt",'w'):
#文件删除
os.remove(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\file.txt")
#重命名,将file.txt重命名为file_rename.txt
os.rename(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\file.txt",r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\file_rename.txt")
#复制文件使用shutil库的copy函数,如将file.txt复制一份到上一级目录Verilog_test中,如果目标路径存在同名文件,则将其覆盖
source=r'C:\Users\ZYP_PC\Desktop\verilog_test\counter\file.txt'
dest=r"C:\Users\ZYP_PC\Desktop\verilog_test"
shutil.copy(source,dest) #复制后文件的更新时间为复制的时间
# shutil.copy(source,dest) #可保留复制后文件的原始创建时间等信息
#移动文件使用shutil库的move函数,如将file.txt移动到目录中counter中
source=r'C:\Users\ZYP_PC\Desktop\verilog_test\file.txt'
dest=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
shutil.move(source,dest) #需注意,如果目的路径已存在文件,会移动失败,此时可见对同名文件进行判断2.3 文件内容的操作
文件内容的常用操作包括读取,查找,增加,删除,修改
import os
import shutil
import re
#文件内容的读取
with open(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v",'r') as f:
all=f.read() #将整个文件内容作为一个字符串读取
print(all)
#对单行按字符逐个读取,默认第一行
for line in f.readline(5): #可设置读取字符数,如示例读取前5各字符
print(line)
# 逐行读取文件内容
for lines in f.readlines(): #读取的结果f.readlines()为整个文件内容按行为单位的list
print(lines)
#内容查找
#指定路径查找包含字符module的行
#方法1 使用字符匹配方法in
pattern = 'module'
path=r'C:\Users\ZYP_PC\Desktop\verilog_test\counter'
with open(path, 'r') as file:
for line in file:
if pattern in line:
print(line) #打印查找到位置所在行
#方法2,使用正则匹配
pattern = 'module'
path=r'C:\Users\ZYP_PC\Desktop\verilog_test\counter'
with open(path, 'r') as f:
for line in f:
if re.search(pattern, line):
print(line) #打印查找到位置所在行
#内容修改
#方法1,使用字符自带的replace函数
new_str="new" #替换的字符
old_str="old" #原始字符
path = r'C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v'
content=""
with open(path, "r", encoding="utf-8") as f:
for line in f:
if old_str in line:
line = line.replace(old_str,new_str)
content += line
with open(path,"w",encoding="utf-8") as f:
f.write(content) #将修改的内容写入文件中
#方法2,使用正则表达中的sub函数
new_str="new" #替换的字符
old_str="old" #原始字符
content=""
path = r'C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v'
with open(path, "r", encoding="utf-8") as f:
for line in f:
if old_str in line:
print(line)
line=re.sub(old_str,new_str,line) #使用sub函数进行替换
content += line
with open(path,"w",encoding="utf-8") as f: #将修改的内容写入文件中
f.write(content)
#内容删除,与内容修改类似,将新的替换字符修改为“”即可,内容增加类似三、文件夹操作
文件夹常见操作包括创建,删除,查找,重命名,复制,移动
import shutil
import re
from pathlib import Path
import glob
##指定路径下创建文件夹
#方法1
path = r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
folder = "new_folder"
os.mkdir(os.path.join(path, folder)) #如果已存在同名文件则会报错
os.makedirs(os.path.join(path, folder),exist_ok=True) #如果已存在同名文件则跳过
#方法2
path = Path(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter")
folder = "new_folder"
new_folder_path = path / folder
new_folder_path.mkdir()
##文件夹删除,删除文件夹counter_bak
path = r"C:\Users\ZYP_PC\Desktop\verilog_test\counter_bak"
shutil.rmtree(path)
##文件夹复制,
#方法1,使用shutil库,推荐使用该方法
new_path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter_new"
old_path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
if os.path.exists(new_path): #先对新文件夹进行判断是否已存在,已存在的进行复制会报错
print("文件夹已存在")
shutil.copytree(old_path,new_path) #counter目录下所有文件复制到counter_new下,如果counter_new不存在,则会先创建
##文件夹改名,和文件改名操作相同,将counter文件夹改名为counter_rename
old_name=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
new_name=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter_rename"
os.rename(old_name,new_name)
##文件夹移动,将counter文件夹移动到Desktop目录中
old_path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
new_path=r"C:\Users\ZYP_PC\Desktop"
if os.path.exists(old_path): #先对复制的文件夹进行是否存在进行判断
shutil.move(old_path,new_path)
else:
print("源文件不存在")四、常用技巧
下面将一些在文件,文件夹操作中经常需要用到的函数进行介绍,部分在前面的例子中已经涉及。
import os
import shutil
import re
from pathlib import Path
import glob
##返回当前的工作目录
current_path=os.getcwd()
print(current_path)
##判断路径是否有效,可为文件夹路径或文件路径
dir_path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
file_path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v"
print(os.path.exists(file_path)) #路径有效则返回true,否则返回false
##文件、文件夹的判断
#方法1
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter22"
print(os.path.isfile(path)) #判断给定的path是否是文件,是返回True,不是返回False
print(os.path.isdir(path)) #判断给定的path是否是文件夹,是返回True,不是返回False
#方法2 使用pathlib库中的函数Path
path = Path(r'C:\Users\ZYP_PC\Desktop\verilog_test\counter')
path.is_file() #判断给定的path是否是文件,是返回True,不是返回False
path.is_dir() #判断给定的path是否是文件夹,是返回True,不是返回False
#方法3 使用path的splittext函数,前提需先进行路径有效性判断
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter_v"
if os.path.exists(path):
print("path路径有效")
file_name, suffix = os.path.splitext(path) # splitext将返回文件名和后缀,如果type不为空说明为文件,为空则为文件夹,前提是path是存在的,否则会误判
if suffix:
print("这是一个文件")
else:
print("这是一个文件夹")
else:
print("path是一个无效地址")
##给定一个目录,返回该目录下所有文件的路径,返回结果为列表
path = Path(r'C:\Users\ZYP_PC\Desktop\verilog_test\counter')
files = glob.glob(os.path.join(path, '*'))
print(files)
##路径拼接,将多个路径拼接成一个路径
#方法1,使用字符串带的join函数
path1=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
path2="counter.v"
abs_path=os.path.join(path1,path2)
print(abs_path)
#方法2,使用pathlib的Path函数
path1=Path(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter")
path2="counter.v"
abs_path=path1 / path2
print(abs_path)
#方法3,使用字符串直接连接
path1=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
path2="counter.v"
abs_path=path1+'\\'+path2 #中间的\\需根据path1是否包含来决定是否需要
print(abs_path)
##文件夹遍历
#方法1 使用os.walk函数
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
for root,dirs,file in os.walk(path): #root为当前目录,dirs为当前目录所有的文件夹列表,file为当前目录的所有文件列表
print("root:",root)
print("dirs:",dirs)
print("file:",file)
#方法2 使用os.listdir函数,和os.walk的区别是不会遍历子目录,要实现递归遍历需要定义函数实现
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
for file in os.listdir(path): #root为当前目录,dirs为当前目录所有的文件夹列表,file为当前目录的所有文件列表
abs_path=os.path.join(path,file)
print("abs_path:",abs_path)
#方法3 使用glob.glob函数,也不会遍历子目录,要实现递归遍历需要定义函数实现
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
files=glob.glob(os.path.join(path,"*")) #获取当前目录下所有的文件和文件夹
print("files:",files)五、常见使用场景
5.1 查找指定类型文件
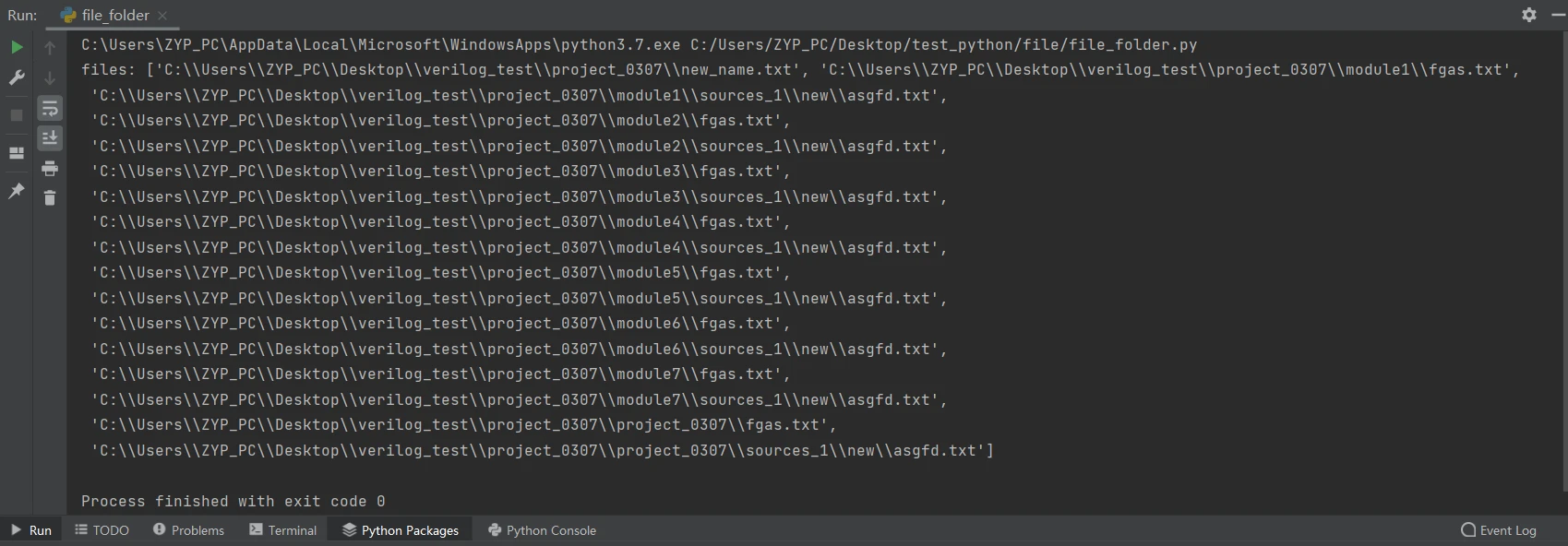
指定目录下查询所有的txt文件,返回查找到的文件路径,以列表形式保存
import os
# 查询指定目录下指定类型的文件,返回查找到结果的绝对路径
def find_type(path,type):
file_find=[]
for root,dirs,files in os.walk(path): #获取指定目录下的所有文件
for file in files:
if file.endswith(".txt"):
file_find.append(os.path.join(root, file))
print("files:",file_find)
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
suffix=".txt"
find_type(path,suffix) #以查找目录project_0307下的所有txt文件为例查询结果
5.2 查找指定名称的文件
和5.1的类似,主要是if后的判断条件进行修改,如在project_0307目录下查找counter_tb.v文件
def find_file(path,f_name):
file_find=[]
for root,dirs,files in os.walk(path): #获取指定目录下的所有文件
for file in files:
if file==f_name: #判断条件进行替换,替换为文件名称查找
file_find.append(os.path.join(root, file))
print("files:",file_find)
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
file="counter_tb.v"
find_file(path,file) #以查找目录project_0307下的counter_tb.v文件为例查询结果

5.3 查找指定名称的文件夹
以在目录project_0307下查找所有名称为sim_1的文件夹为例
# 查询指定目录下指定名称的文件夹,返回查找到结果的绝对路径
def find_dir(path,dir_name):
folder_find=[]
for root,dirs,files in os.walk(path): #获取指定目录下的所有文件,文件夹
for dir in dirs:
if dir==dir_name:
folder_find.append(os.path.join(root, dir))
print("find_result:",folder_find)
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
dir_name="sim_1"
find_dir(path,dir_name) #以查找目录project_0307下所有名称为sim_1的文件夹为例查找结果

5.4 指定路径查找包含指定内容的文件
以在目录project_0307下查找包含字符FPGA的log文件
def find_file(path,suffix,content):
file_find=[]
for root,dirs,files in os.walk(path): #获取指定目录下的所有文件
for file in files:
if file.endswith(suffix): #判断条件进行替换,替换为文件名称查找
abs_path=os.path.join(root, file)
with open(abs_path,"r") as f:
for line in f:
if content in line:
file_find.append(abs_path)
print("files:",file_find)
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307" #查找目录
suffix=".log" #查找的文件类型为log类型
content="FPGA" #文件中包含字符FPGA
find_file(path,suffix,content) #以查找目录project_0307下的counter_tb.v文件为例查找结果