文章目录
- 一、概述
- 二、实操
- 1、导入相关包
- 2、导入乳腺癌数据集,建立模型
- 3、调参
- 三、总结
Link:https://zhuanlan.zhihu.com/p/126288078
Author:陈罐头
一、概述
sklearn是目前python中十分流行的用来实现机器学习的第三方包,其中包含了多种常见算法如:决策树,逻辑回归、集成算法(如随机森林)等等。
本文将使用sklearn自带的乳腺癌数据集,建立随机森林,并基于 泛化误差(Genelization Error) 与模型复杂度的关系来对模型进行调参,从而使模型获得更高的得分。
泛化误差是机器学习中,用来衡量模型在未知数据上的准确率的指标,其与模型复杂度的关系如下图所示:

当模型复杂度不足时,机器学习不足,会出现欠拟合现象,泛化误差变大;当复杂度逐渐提高到最佳模型复杂度时,泛化误差会达到最低点(即最高准确度);若复杂度仍在提高,泛化误差从最小值开始逐渐增大,出现过拟合现象。
因此,我们的目的,是通过不断调参来不断调整模型复杂度,尽可能地接近泛化误差最低点。
二、实操
1、导入相关包
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2、导入乳腺癌数据集,建立模型
由于sklearn自带的数据集已经很工整了,所以无需做预处理,直接使用。
# 导入乳腺癌数据集
data = load_breast_cancer()
# 建立随机森林
rfc = RandomForestClassifier(n_estimators=100, random_state=90)
用交叉验证计算得分
score_pre = cross_val_score(rfc, data.data, data.target, cv=10).mean()
score_pre

3、调参
随机森林主要的参数有n_estimators(子树的数量)、max_depth(树的最大生长深度)、min_samples_leaf(叶子的最小样本数量)、min_samples_split(分支节点的最小样本数量)、max_features(最大选择特征数)。
它们对随机森林模型复杂度的影响如下图所示:

可以看到,n_estimators是影响程度最大的参数,我们先对其进行调整:
# 调参,绘制学习曲线来调参n_estimators(对随机森林影响最大)
score_lt = []
# 每隔10步建立一个随机森林,获得不同n_estimators的得分
for i in range(0,200,10):
rfc = RandomForestClassifier(n_estimators=i+1, random_state=90)
score = cross_val_score(rfc, data.data, data.target, cv=10).mean()
score_lt.append(score)
score_max = max(score_lt)
print('最大得分:{}'.format(score_max),
'子树数量为:{}'.format(score_lt.index(score_max)*10+1))
# 绘制学习曲线
x = np.arange(1,201,10)
plt.subplot(111)
plt.plot(x, score_lt, 'r-')
plt.show()

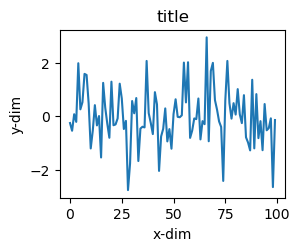
如图所示,当n_estimators从0开始增大至21时,模型准确度有肉眼可见的提升。这也符合随机森林的特点:在一定范围内,子树数量越多,模型效果越好。而当子树数量越来越大时,准确率会发生波动,当取值为41时,获得最大得分。
接下来,我们在将取值范围缩小至41左右,以获得更好的取值。
# 在41附近缩小n_estimators的范围为30-49
score_lt = []
for i in range(30,50):
rfc = RandomForestClassifier(n_estimators=i
,random_state=90)
score = cross_val_score(rfc, data.data, data.target, cv=10).mean()
score_lt.append(score)
score_max = max(score_lt)
print('最大得分:{}'.format(score_max),
'子树数量为:{}'.format(score_lt.index(score_max)+30))
# 绘制学习曲线
x = np.arange(30,50)
plt.subplot(111)
plt.plot(x, score_lt,'o-')
plt.show()

如图所示,当n_estimators=45时,获得最大得分score_max=0.9719,相较于score_pre提升0.005

由此我们发现:当n_estimators由100减小至45时(模型复杂度由大到小),模型准确度提升了(泛化误差减小),说明在泛化误差图中,模型往左移动了!
因此,接下来的调参方向是使模型复杂度减小的方向,从而接近泛化误差最低点。我们使用能使模型复杂度减小,并且影响程度排第二的max_depth。
# 建立n_estimators为45的随机森林
rfc = RandomForestClassifier(n_estimators=45, random_state=90)
# 用网格搜索调整max_depth
param_grid = {'max_depth':np.arange(1,20)}
GS = GridSearchCV(rfc, param_grid, cv=10)
GS.fit(data.data, data.target)
best_param = GS.best_params_
best_score = GS.best_score_
print(best_param, best_score)

如图所示,最佳深度为11,最大得分为0.9718,竟然比不调整深度的得分0.9719还低,难道我们刚才就已经十分接近最低泛化误差了吗?
本着严谨的态度,我们再进行调整。调整max_depth使模型复杂度减小,却获得了更低的得分,因此接下来我们需要朝着复杂度增大的方向调整。我们在n_estimators=45,max_depth=11的情况下,对唯一能够增加模型复杂度的参数max_features进行调整:

查看数据集大小,发现一共有30列特征,由于max_features默认取值特征数量的开平方值,因此我们从5开始调整:
# 用网格搜索调整max_features
param_grid = {'max_features':np.arange(5,31)}
rfc = RandomForestClassifier(n_estimators=45
,random_state=90
,max_depth=11)
GS = GridSearchCV(rfc, param_grid, cv=10)
GS.fit(data.data, data.target)
best_param = GS.best_params_
best_score = GS.best_score_
print(best_param, best_score)

输出结果为5,和默认值一样。得分为0.9718,仍然小于0.9719。因此,仅需n_estimators=45就能使模型的准确率达到最高0.9719,相较于初始得分0.9667,提升0.005,最接近最小泛化误差,调参工作到此结束。
三、总结
总结一下在sklearn中调参的思路:
① 基于泛化误差与模型复杂度的关系来进行调参;
② 根据对模型的影响程度,由大到小对参数排序,并确定哪些参数会使模型复杂度减小,哪些会增大;
③ 依次选择合适的参数,通过绘制学习曲线或网格搜索的方法调参,直到找到最大准确得分。