Interactive Analysis of CNN Robustness----《CNN鲁棒性的交互分析》
摘要
虽然卷积神经网络(CNN)作为图像相关任务的最先进模型被广泛采用,但它们的预测往往对小的输入扰动高度敏感,而人类视觉对此具有鲁棒性。本文介绍了 Pertuber,这是一个基于 Web 的应用程序,允许用户即时探索当 3D 输入场景受到交互式扰动时 CNN 激活和预测如何演变。Pertuber 提供了各种各样的场景修改,例如摄像机控制、照明和阴影效果、背景修改、对象变形以及对抗性攻击,以方便发现潜在的漏洞。可以直接比较微调的模型版本,以定性评估其稳健性。机器学习专家的案例研究表明,Pertuber 可以帮助用户快速生成有关模型漏洞的假设并定性比较模型行为。通过定量分析,我们可以将用户的见解推广到其他 CNN 架构和输入图像,从而产生关于对抗训练模型的漏洞的新见解。
引言
卷积神经网络 (CNN) 在各种应用中取得了令人印象深刻的结果,例如图像分类 [KSH17] 或对象检测 [RHGS17]。在给定训练数据集上训练的 CNN 的性能通常根据验证数据集的预测准确性来评估。如果训练集和验证集的统计分布不同,高性能可能会急剧下降。在这种情况下,对于验证数据中的可变性,模型并不鲁棒。CNN的鲁棒性已被证明会受到图像扰动的影响,如裁剪[ZSLG16]、模糊[DK16]、高频噪声[YLS∗19]或纹理变化[GRM∗19]。噪声扰动的突出例子是对抗性攻击:输入图像的单个像素发生轻微的变化,这样CNN就会将其错误分类[SZS∗14]。对于人类来说,这些变化通常是察觉不到的,他们仍然会分配正确的标签。
在各种应用中,鲁棒性是CNN高度安全关键的一个方面,例如自动驾驶汽车[LHA∗20]。例如,研究人员已经证明,有针对性但毫无疑点的交通标志变化是如何导致CNN不断错过停车标志的[EEF∗18]。因此,了解哪些因素影响CNN的鲁棒性,进而设计和评估更鲁棒的模型,是机器学习界的核心重要研究主题[GSS14, SZS∗14,MMS∗19,LHG∗21]。
为解决鲁棒性问题奠定基础,研究人员旨在更好地全面了解CNN对哪些图像特征最敏感,以及这种敏感与人类视觉感知有何不同[BHL∗21]。例如,Geirhos等人[GRM∗19]研究了在图像分类中形状和纹理对人类和CNN的影响,发现CNN对纹理有很强的偏向。这种纹理偏差也被Zhang和Zhu [ZZ19]通过评估图像饱和度或图像块随机变换的效果来证实。通过对傅里叶域中的图像扰动进行系统分析,Yin 等人 [YLS19] 表明 CNN 对高频扰动高度敏感。
提高鲁棒性的常见方法是使用数据增强方法 [PW17]、图像风格化 [GRM19] 或对抗性示例 [MMS*19] 在更多变量的输入图像上训练模型。为了评估这些改进模型的性能,我们将它们与标准 CNN 模型进行比较。为了进行这些分析,研究人员自动对图像进行离线扰动,记录每个扰动输入图像的预测,并在模型之间比较结果。根据我们合作的领域专家的说法,这样的实验需要几个小时来设置,包括耗时的参数搜索。在一些实验中,甚至不可能完全自动地确定网络性能,因为由于所进行的图像扰动,输入图像的地面真相对人类来说也变得不清楚。显然,这些因素严重限制了机器学习专家快速探索可能影响CNN性能的图像扰动因素。
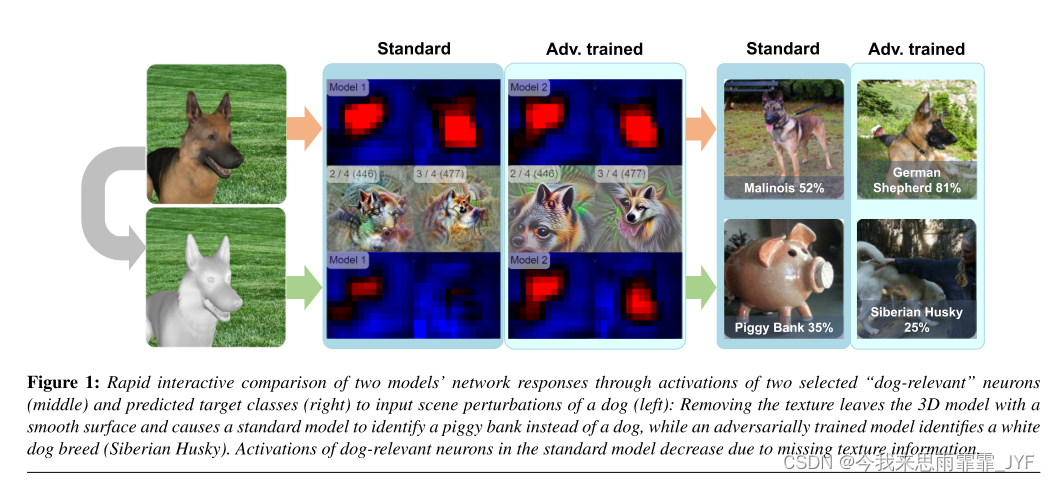
我们假设,能够通过大量且多样化的视觉扰动参数交互操作合成输入场景,并立即观察变化的激活和预测,将使研究人员能够快速生成假设,并对 CNN 的潜在漏洞建立更强大的直觉。因此,在这项工作中,我们引入了 Pertuber——一种新颖的实时实验界面,用于模型鲁棒性的探索性分析(见图 1)。我们的工作提供了以下贡献:
- 1、3D 场景的交互式输入扰动与特征可视化、激活图和模型预测相结合,作为交互式探索模型鲁棒性的新方法。
- 2、直接比较界面,用于对更稳健、微调的模型变体进行定性视觉验证。
- 3、实施可公开访问的基于网络的 VA 工具†,该工具支持 3D 输入场景的多种扰动方法并实时可视化模型响应。
- 4、机器学习专家的案例研究观察表明,对输入扰动的实时检查使专家能够直观地探索已知的漏洞,比较模型行为,并生成有关模型鲁棒性的新假设。
- 5、从案例研究中对选定用户观察结果的定量验证对对抗训练模型的鲁棒性提出了新的看法。
相关工作
近年来,出现了一系列广泛的深度学习可视化方法。对于深度学习的视觉分析(VA)的全面概述,我们请读者参考Hohman等人的一项调查[HKPC19]。例如,图形结构可视化,例如TensorFlow graph Visualizer [WSW∗18],可以帮助用户更好地理解他们的模型结构,其中包括许多层和连接。其他的,如DeepEyes [PHVG∗18]和DeepTracker [LCJ∗19],在整个训练过程中跟踪详细的度量,以方便识别模型问题或异常迭代。ExplAIner [SSSEA20] 不仅限于监控,还集成了不同的指导机制来帮助用户理解和优化他们的模型。使用 VA 系统评估模型检测和分类交通灯性能的案例研究表明,交互式 VA 系统可以成功指导专家改进其训练数据 [GZL20]。
虽然这些示例都侧重于单个模型的检查,但其他示例支持模型比较。例如,使用 REMAP [CPCS20],用户可以通过消融(即删除现有模型的单层)和变化(即通过层替换创建新模型)快速创建模型架构,并通过结构和性能比较创建的模型。Ma等人[MFH∗20]设计了多个协调视图,帮助专家分析迁移学习后的网络模型行为。CNNComparator [ZHP17] 使用多个协调视图来比较两个 CNN 之间的架构和所选输入图像的预测。模型比较也是我们工作的一个重要方面。然而,目前工作的重点在于输入刺激的流体修改以及网络响应的瞬时分析和比较。因此,我们让用户以“游乐场式”的方式从 3D 场景生成和扰乱输入图像,而不是让用户选择带有真实类别标签的输入图像。
交互式“游乐场”需要相对较少的底层深度学习知识,可用于教育目的。对于更有见识的用户来说,它们对于从文献中建立直觉和验证知识是有价值的[KTC∗19]。值得注意的例子有TensorFlow Playground [SCS∗17],它支持在浏览器中交互式修改和训练DNN,以及GANLab [KTC∗19],它以类似的风格设计,支持生成对抗网络实验。CNN 解释器 [WTS20] 通过显示层和激活图之间的连接,提供 CNN 内部工作原理的可视化解释,允许用户从固定的图像集合中选择输入。与我们的工作更相似的是,Harley [Har15] 提供了一个在线工具,用户可以在画布上绘制数字。然后,在 MNIST 训练的简单网络中所有神经元的响应都会实时可视化。Adversarial Playground [NQ17] 允许用户交互式地生成对抗攻击并立即观察 MNIST 训练的网络的预测。为了支持基于输入修改的模型响应的交互式探测,Prospector [KPN16]、what-if-tool [WPB∗20]和NLIZE [LLL∗18]分别允许用户通过改变表格数据和自然语言处理领域的输入来查询模型。这些工作启发我们构建一个系统,让用户通过输入扰动交互式地探索模型的鲁棒性。与之前的工作相比,Perturber操作复杂的CNN模型,如在ImageNet上训练的Inception-V1,可以用来发现和解释复杂输入场景的漏洞,比如不同环境中的动物或人造物体。
为了解释一个CNN模型,有一些强大的方法可以通过可视化网络的学习特征来揭示网络隐藏单元的作用。特征可视化是一种激活最大化技术,它通过结合多种正则化技术得到改进[YCN∗15,OMS17]。特征可视化已被用于识别和描述CNN中神经元的因果联系[CCG∗20],并全面记录单个神经元在大型CNN中的作用[Ope]。在VA工具中,特征可视化被用来比较迁移学习前后的学习特征[MFH∗20],或者可视化一个选定目标类的最相关神经元及其连接的图表[HPRC20]。类似地,Bluff [DPW20] 显示了一张包含解释预先计算的对抗性攻击的最相关神经元的图,其中神经元由其特征可视化表示。
其他强大的可解释性方法是显着性图(或归因图),它显示输入图像区域相对于所选目标类或网络组件的显着性[SVZ13]。然而,显着图和其他基于梯度的方法,如 LRP [LBM16]、积分梯度 [STY17] 或 Grad-CAM [SCD17],需要计算成本高昂的反向传播过程。揭示模型预测的相关图像区域的一个非常简单的解决方案是直接可视化中间层中选定特征图的前向传播激活。例如,DeepVis Toolbox [YCN15] 显示来自网络摄像头源的 CNN 激活的实时可视化。目标是获得 CNN 学到的特征的总体直觉。AEVis [LLS18] 显示神经元对沿着“数据路径可视化”的一组预定义输入图像的激活。这种可视化允许用户通过网络的隐藏层追踪对抗性攻击的影响。数据路径由负责预测的关键神经元及其连接形成。与 DeepVis Toolbox [YCN*15] 一样,Pertuber 根据实时输入可视化激活和预测。主要区别在于 Pertuber 从交互式 3D 场景生成输入图像,并提供丰富的输入扰动方法来逐步探索模型的潜在漏洞。此外,它有利于标准模型与其更稳健的变体之间的直接比较,以探索模型变体的优点和局限性。
Pertuber 接口
Pertuber 的高级目标是交互式地探索 CNN 的潜在漏洞来源,以促进更强大模型的设计。通过可视化研究人员和机器学习专家在模型可解释性和鲁棒性方面的不断交流,我们确定了VA应用程序的四个核心需求,以支持模型鲁棒性的探索性分析和定性验证:
- R1:代表性场景的丰富在线输入扰动对于快速生成可研究模型响应的输入图像至关重要。系统应提供多种可能的扰动参数,并允许这些扰动的灵活组合。
- R2:要了解模型的稳健性,仅仅了解模型如何响应扰动的输入以及模型响应发生变化的原因是不够的。为此,当试图理解是什么导致模型对人类做出不可预测的反应时,不仅要关注输入和输出,而且尤其要关注众多的隐藏层。
- R3:交互性可以帮助用户通过动态实验建立直觉[KC19]。因此,我们的目标是使模型对输入扰动的响应立即可见,以支持一个类似操场的环境中的流体反馈循环。
- R4:鲁棒性可以通过使用数据增强方法(例如仿射图像变换、图像风格化或对抗性训练)在更通用的输入图像上训练模型来实现。标准 CNN 模型与其更稳健的微调版本之间的直接视觉比较对于首次定性验证是必要的,微调模型是否通常对输入扰动更稳健,或者只是有选择地对其所训练的特定扰动更稳健。
Perturber由以下组件组成:三维输入场景(3.1节,图2a)、扰动控制(3.2节,图2b - c)、预测视图(3.3节,图2b - F)、和(比较)神经元激活视图(3.4节,图2 E-D)。这些视图允许对输入场景扰动对一个或两个选定模型的影响进行定性检查(章节3.5)。
从概念上讲,Pertuber 可以处理任何 CNN 架构。当前版本支持基于 Inception-V1(也称为 GoogLeNet)[SLJ15] 架构的模型。我们的标准模型在 ImageNet [RDS15] 上进行训练。我们使用预先训练的模型,其权重可通过 Lucid‡ 特征可视化库 [OMS17] 访问。

输入场景
输入图像是从交互式 3D 场景生成的,可以通过多种方式进行操作(第 3.2 节)。在计算机视觉项目中,渲染图像经常被用来代替或作为图片来训练CNN [SQLG15]。定量实验表明,对于高级计算机视觉算法,合成图像与真实图像之间的差距是相当小的[GWCV16]。CNN的反应在简单渲染的3D模型和自然图像之间是一致的[AR15]。因此,基于合成场景的CNN响应的交互式探索似乎足以代表真实世界的应用。合成 3D 场景的主要优点是可以轻松消除扰动因素。这意味着,输入修改可以彼此独立地灵活应用,以评估它们的孤立效应以及它们的相互作用。
在 1000 个 ImageNet 类别中,其中 90 个是狗品种。因此,我们的 Inception-V1 模型中有许多神经元专门研究与狗相关的模式,例如鼻子、头部方向、皮毛、眼睛、耳朵等。因此,我们选择了一只狗作为我们的主要前景3D对象来代表这一特殊意义,并输入一个许多手工识别的神经元回路(CCG∗20)强烈响应的输入图像。作为第二个3D模型,我们提供了一辆汽车,它具有与狗非常不同的特征,是机器学习社区中常见的分析对象(如[GWCV16, AR15])。此外,用户还可以上传定制的3D模型。这样,用户就可以验证他们对其他模型所做的观察。
扰动控制
Pertuber 的核心原理是用户可以灵活地改变他们想要探索的扰动因素(R1)并立即观察其效果(R3)。Pertuber 提供了 20 多个场景扰动因素,以及这些因素之间所有可能的组合。我们将这些扰动方法分为以下几类:
几何扰动,如旋转、平移或剪切图像,是CNN可能对[ZSLG16, ACW18, ETT∗19]敏感的经典扰动。因此,仿射图像变换也是一种常见的数据增强方法,用于更鲁棒的训练[PW17]。我们通过简单的相机控制支持几何扰动,允许用户围绕 3D 模型任意旋转,以及自由缩放和平移场景以创建图像裁剪效果。此外,用户还可以绕z轴旋转相机来模拟图像旋转。
对于人类观察者来说似乎无关的场景扰动可能很容易混淆标准 CNN 模型。例如,更改背景 [XEIM20] 会对预测产生巨大影响。因此,我们支持各种场景扰动操作,例如更改背景图像,以及修改主要对象的照明和纹理参数(见图 3)。通过这些参数的组合,可以生成专门的扰动,例如轮廓图像(见图 3 右下角)。

形状扰动让用户可以将主场景对象的形状变形为另一种形状。Pertuber 目前支持狗和猫之间以及消防车和赛车之间的变形。通过使物体的形状独立于其纹理而变形,可以研究纹理-形状线索冲突[GRM∗19]。
颜色扰动作用于光栅化的二维图像。我们支持单独的后处理效果,例如 Alpha 混合到黑色、色调偏移和(去)饱和度。除了这些参数之外,为用户提供了一个文本字段,他们可以在其中编写自己的 GLSL 代码,并采用由滑块控制的单个参数。代码片段默认为对比度调整代码。使用这些后处理效果,用户可以评估模型对低对比度[DK16]和低图像饱和度[SLL20]的惊人的高鲁棒性。
频率扰动选择性地改变不同的图像频率。Perturber提供了三个参数的频率分解,将图像分割成低、高频段,这是通过拉普拉斯分解实现的。通过选择性频率抑制,用户可以研究Yin等人所描述的现象[YLS∗19],其中作者表明对抗训练的网络对高频扰动具有鲁棒性,但对低频扰动非常敏感。
空间扰动是系统地改变图像像素顺序的后处理效果。Pertuber 支持 patch shuffle,Zhang 和 Zhu [ZZ19] 使用它来揭示模型对全局结构的敏感性,而 patch shuffle 对人类观察者来说会受到很大的干扰。图像被划分为由 k×k 个单元组成的网格,然后随机重新排序。
最后,对抗性扰动是理解模型鲁棒性的核心特征。用户可以对当前场景图像执行投影梯度下降(PGD)对抗攻击[MMS*19]。为此,他们选择一个模型来生成攻击,目标类别或抑制原始预测的选项,以及攻击 ε 和 Lp 范数(L2 或 L∞)。每按一次按钮,用户就会执行一个 PGD 步骤,步长为 ε/8。这种扰动成本高昂并且不能立即执行。在功能强大的PC上,第一步通常需要10秒左右,因为首先需要计算当前输入图像的梯度函数。为了让用户像其他扰动参数一样流畅地检查对抗性攻击对模型的影响,我们在计算出扰动向量后将当前输入图像与扰动向量叠加。通过这种方式,用户可以交互地使用滑块淡化攻击alpha值,并即时观察系统的响应。他们还可以淡化原始图像以检查扰动向量本身。
预测视图
预测视图以概率或 Logits 形式显示每个模型的前 5 个分类结果(图 2 F)。这允许用户实时观察输入扰动导致的分类变化 (R3)。每个模型的最佳结果都由类图像示例表示。Pertuber 显示 ImageNet 验证数据集中相应类别的第一张图像。
神经元激活视图
神经元激活视图是分析输入扰动如何影响模型隐藏层 (R2) 的中心界面。扰动器通过特征可视化来表示神经元。特征可视化旨在为网络提供一个镜头,以可视化某些网络单元响应的模式[OMS17]。例如,这些图案可能是较早层中特定方向的边缘(参见图 4),或者是后面层中的特定对象,例如狗头(参见图 1)或车窗。

激活图显示输入图像的哪些区域导致相应的神经元被激活。在尝试了基于梯度的可视化方法 GradCAM [RSG16] 的实现之后,我们决定专注于计算成本低得多的激活图,显示前向传播过程中的神经元激活。这样,可以立即观察到神经元激活(R3)。高度激活神经元的输入区域显示为红色,而蓝色区域则导致负激活(见图 4)。当用户操纵输入场景时,激活图会立即更新,以便用户可以实时观察神经元在模型中响应哪些图像特征。例如,在图4中,mixed4a层的神经元412和418响应定向模式。旋转有纹理的赛车会导致这两个神经元的激活发生强烈变化。
Inception-V1 包含数千个神经元。显然,不可能同时显示所有神经元的特征可视化和交互式激活图。相反,我们为每一层提供了预先选择的神经元组和类别,它们被划分为语义上有意义的神经元族[CCG∗20]。除了前面介绍的这些神经元组,我们使用Summit [HPRC20]在后面的层次中进一步确定了与狗、猫、赛车和消防车相关的神经元组。这些预选的神经元组由 1 个到大约 70 个神经元组成,可以从下拉菜单中选择(图 2D)。
模型对比
这些预选的神经元组由 1 个到大约 70 个神经元组成,可以从下拉菜单中选择(图 2D)。为了利用 Pertuber 直接比较鲁棒性 (R4),我们采用了迁移学习方法,该方法使用标准模型的权重进行初始化。这是必要的,以保证各网络单元的特征通信保持完整。只有这样,我们才能假设模型间的单元对相同的输入图像的响应是相似的。
为了说明各个网络单元的响应,Pertuber 依赖于特征可视化。特征可视化独立于输入图像,但它们在模型之间有所不同。事实上,表 1 显示了三种不同模型变体的单个神经元特征可视化之间的显着差异。

为了展示模型比较,Pertuber 已经包含了 Inception-V1 的两个强大的模型变体:第一个模型采用投影梯度下降(PGD)进行对抗性训练,Madry 等人对此进行了描述。 [MMS19]。对抗性训练通过将强对抗性攻击纳入训练过程来提高模型的鲁棒性。第二个模型由 Stylized-ImageNet 训练,它是 ImageNet 的变体,其中使用风格转移算法 [GRM19] 将图像转换为不同的绘画风格。Stylized-ImageNet 的目的是引起形状偏差,而标准 ImageNet 训练模型被发现不成比例地偏向纹理 [GRM*19]。用户可以从界面中选择两个模型进行比较(图2D)。此外,他们可以在增量微调过程中选择多个检查点来分析训练期间模型的发展。然后将相应的神经元激活视图并置在 Pertuber 界面中以进行直接比较(图 2 E)。
基于网络的实施
Pertuber 纯粹在用户浏览器的客户端上运行,在运行时没有任何服务器端计算。我们预先计算了所有不依赖于交互式可更改元素的数据,以使 UI 尽可能高效。对于迁移学习,我们使用标准模型(即在 ImageNet 上训练的 Inception-V1)的权重进行初始化,这些权重是通过 Lucid 库 [OMS17] 获得的。对于对抗性微调,我们使用了 Tsipras 等人的开源实现。 [TSE*19]。没有层被冻结用于迁移学习。对于这两个微调模型,我们使用了0.003的学习速率,批量大小为128,并且我们一直训练直到模型达到大约0.5的前5个训练误差,这大约花费了50K次对抗微调和90K次Stylized-ImageNet 微调。
为了生成特征可视化,我们采用了 Lucid [OMS17] 库提供的实现。对于每个模型,我们从最相关的层(即前三个卷积层和每个混合块末尾的串联层)生成 5808 个神经元的特征可视化。在微调过程中,我们获得了 17 个对抗性微调检查点和 7 个 Stylized-ImageNet 微调检查点的特征可视化。对于每个神经元,我们使用两种参数化方法计算特征可视化——朴素像素或傅立叶基 [OMS17](参见表 1)。第二个在傅里叶空间中执行梯度上升,导致频率分布更均匀,从而产生更自然的特征可视化。除了这两种方法之外,我们还使用变换稳健性 [OMS17]。如果没有傅里叶基参数化,模型之间的差异在视觉上会更加明显(表 1 顶行)。在一台配备两个 NVIDIA GTX 1070 GPU 的机器上,计算所有 ∼300K 生成的特征可视化大约需要一个月的时间。
3D场景的操作,基于渲染图像的模型推理,以及激活地图的计算都在web浏览器中实时执行。客户端在3D场景渲染和CNN推理上都依赖于GPU加速。对于这些任务,我们分别使用基于webglbasic的库Three.js和TensorFlow.js [STA∗19]。前端GUI是基于React.js的。基于后处理效果的输入扰动被实现为使用自定义GLSL着色器的多个顺序渲染通道。对于模型推理,我们使用Tensorflow.js [STA∗19],它支持快速的gpu加速CNN推理。Tensorflow.js 还用于计算对抗性攻击。
Pertuber 的一个主要要求是可以立即观察到输入扰动的影响 (R3)。为了评估需求R3,我们测量了客户机的性能,很明显,客户端的GPU对帧速率有很大的影响。应用程序性能还取决于启用的可视化,预测视图(第 3.3 节)比显示四个实时激活图(第 3.4 节)的计算成本更高。当使用功能较弱的客户端计算机时,用户可以有选择地关闭视图。
探索场景:纹理-形状冲突
为了展示 Pertuber 的功能,我们选择了鲁棒性的一个重要方面:形状和纹理对 CNN 分类结果的影响。研究表明,CNN 偏向于纹理,这会影响鲁棒性 [GRM19]。在这种情况下,我们首先旨在调查是否可以使用 Pertuber 发现这种效应。其次,我们的目标是定性验证使用 Stylized-ImageNet [GRM19] 进行微调的更稳健的模型变化是否可以改善这种偏差。
对于我们的第一次分析,我们通过形状和纹理扰动探索纹理-形状提示冲突。图 6 说明仅形状扰动不会导致标准模型预测猫的品种。然而,当改变纹理时,模型预测会切换到猫的品种——即使物体形状保持不变。这是模型确实对纹理比对形状扰动更敏感的第一个指标。

为了进一步研究标准模型的纹理敏感性,我们复制了Zhang和Zhu的补丁改组实验[ZZ19]。使用 Pertuber,我们可以在这个实验中检查单个神经元的激活。我们在图 7 中展示了对一个精心挑选的神经元的观察,该神经元被向左看的狗脸强烈激活。注意这个神经元是如何被强烈的纹理对比激活的,尤其是在狗嘴周围。包含耳朵的图像区域不会激活这个特定的神经元。对于这个场景,标准模型仍然可以预测最多 k = 7 个随机打乱的图像块的狗品种。这说明分解形状对模型预测的影响确实很小。
在下一步中,我们分析标准模型是否确实比在 StylizedImageNet [GRM*19] 上通过逐渐去除主要对象的纹理进行微调的模型对纹理更敏感。图 8 中的预测证实,即使在没有纹理的情况下,StylizedImageNet 训练的模型也能一致地预测狗的品种。另一方面,标准模型似乎更多地依赖于纹理。使用 Stylized-ImageNet 训练的模型对补丁洗牌也更敏感,这也表明它比标准模型更少依赖纹理信息(有关图像示例,请参阅补充文档中的 A 节)。


最后,我们比较了两个模型之间的形状敏感性。为此,我们结合各种场景扰动来生成狗的轮廓图像。然后我们逐渐改变狗的姿势。图 9 显示了标准模型和使用 Stylized-ImageNet 微调的模型的预测。显然,标准模型的预测是不稳定的,特别是当狗直接面对相机时。然而,使用StylizedImageNet训练的模型,可靠地预测出了高概率的白狼。相关神经元的激活表明,基于stylizedimagenet的模型学习了一个更稳定的狗的头部正面的表征,它也会被剪影图像激活。

这些例子说明Perturber提供了灵活的方法来探索和更好地理解鲁棒性的潜在威胁,例如CNN的纹理-形状冲突。补充文档的A部分包含了更多的探索场景。
案例研究
虽然前面的场景研究了一个已知的漏洞,但我们进一步探讨了Perturber是否可以通过与机器学习专家的案例研究来帮助发现未知的鲁棒性威胁。
观察和反馈
用户称赞 Pertuber 是“实时”工作的,因此可以进行临时探索性分析。他们喜欢Perturber允许使用简单的例子来快速找到模式并形成假设。一般来说,探索性分析的主要焦点是试图识别输入扰动,在那里模型会作出意想不到的响应。一位用户将这个过程描述为试图回答以下问题:“我如何打破一个模型?我需要做什么才能使预测结果是错误的?”例如,三名用户惊讶地发现,对抗训练的模型在某些几何变化(如缩放或旋转)面前是多么脆弱。两个用户还发现对抗训练的模型对背景修改的高度敏感性,如图10所示。实时的方法在没有明确的事实基础的情况下尤其受到赞扬,例如对象变形(图6)。如果没有对人体进行研究,就不可能对这种情况进行定量评估。能够快速生成假设,然后在更受控的环境中进行正式测试被认为非常有用。

我们还观察到有迹象表明Perturber实际上有助于视觉确认。例如,使用模型预测和选定神经元的激活,一个用户验证了对抗性攻击只影响标准模型。他还观察了标准模型中与动物相关的神经元在攻击目标类“獾”时是如何被激活的(图11)。并不是所有的假设都得到了证实。例如,一位用户认为在 Stylized-ImageNet 上训练的模型比标准模型更容易受到图像模糊的影响。出乎意料的是,模型对模糊的反应并不比标准模型对所选输入场景的反应更敏感(见补充文档中的A部分)。

最后,一名用户指出,玩弄Perturber可以让非专业人士直观地感受到CNN是多么容易被愚弄。例如,一位用户演示了标准模型在翻译狗的时候是如何迅速改变预测的。另一位专家证明,狗沿着z轴旋转,结合不寻常的背景(街道),足以干扰敌对训练的模型。因此,他表示,Perturber可以为“担心人工智能将接管世界的人们”提供信息。
总的来说,在我们的案例研究中,导致最有趣的观察结果的最经常执行的扰动是1)几何变换,如物体旋转、缩放和平移,2)背景修改,3)(1)和(2)的组合,以及4)物体变形。预测视图被认为能够提供即时的、易于解释的和有用的反馈。因此,它是观察模型行为的主要视图。特征可视化被认为有助于描述模型之间的差异。参与者将对抗训练模型的特征可视化描述为与相应标准模型的神经元相比更“直观”或“卡通”。一位参与者发现特征可视化有时难以解释。因此,一个建议是额外地显示来自数据集的强烈激活的自然图像示例。
用户观察的定量评估
我们进行了定量测量,看看用户在视觉上观察到的东西是否可以超越给定的输入场景、合成的输入图像和Inception-V1网络架构。为了测试用户观察的泛化性,我们使用不同于在线工具中使用的模型进行了定量测量。具体来说,我们使用 PyTorch [PGM19] 的 torchvision 库中预训练的 ResNet50 作为标准模型。为了进行比较,我们使用了鲁棒性库 [EIS19](ResNet50 ImageNet L2-norm ε 3/255)中同一模型的对抗训练版本的权重。
首先,我们研究了对抗训练模型对背景变化的敏感性,这是由案例研究中的两名用户报告的。为了验证,我们采用了Xiao等人[XEIM20]提出的背景挑战(Background Challenge),使用(自然图像)敌对背景对模型进行测试。对抗训练模型在背景变化下只能正确预测12.3%。标准模型的准确率达到22.3%。使用这个测试数据集,随机猜测将产生11.1%的准确性[XEIM20]。
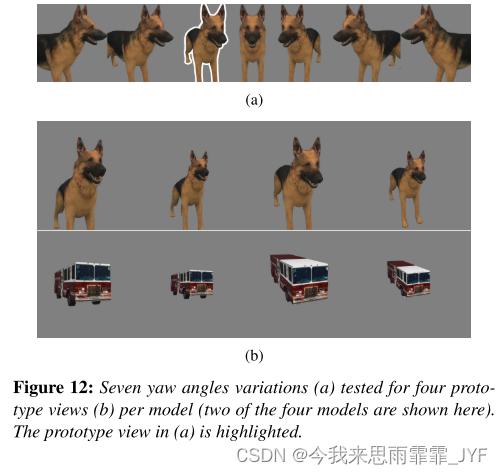
其次,我们测试对抗训练的模型是否确实比标准模型(由3个用户报告)对几何场景转换更敏感。特别是,我们研究了相机旋转。我们生成了一个合成数据集,在这里我们从7个偏航角度渲染了扰动器中提供的4个3D模型,范围从-70◦到70◦(图12a),两个俯仰角度,以及相机到物体的两个距离,如图12b所示。我们总共为四个3D模型生成了28个视图。为了比较预测的波动程度,我们为四种俯仰/距离组合和 3D 模型中的每一种选择了偏航角为 -23.3° 的原型视图(图 12b)。换句话说,波动分数衡量的是前10个原型类在旋转后的输入图像中的对数差异有多强烈。图13显示了所有28个原型视图的平均波动得分。在四个三维模型中,有三个模型的波动分数相对于对抗训练模型要高得多。这证实了对抗性训练的模型确实更容易受到主对象旋转的影响。
讨论与结论
我们表明,结合实时激活的交互扰动可以是一种有效的方法,以探索CNN的潜在漏洞,并对更鲁棒的模型变化进行定性评估。在探索场景中,我们可以通过多个扰动示例复制已知的纹理-形状冲突[GRM∗19]。参与我们案例研究的机器学习专家观察到了各种已知但也意想不到的网络行为。他们可以使用我们的合成输入场景成功复制已知的 CNN 属性,例如模型对对抗性攻击或补丁洗牌的不同敏感性。此外,我们对选定的用户观察的定量研究后实验可以使用不同的网络结构和自然图像复制他们的观察结果。通过这些实验,我们证明了对抗训练模型对背景修改和主要对象的偏航旋转的脆弱性,据我们所知,这在机器学习社区中还没有讨论过。
我们的用户报告的大多数见解都是基于对模型预测在扰动图像时如何变化的观察。这意味着实时输入扰动的原理也可以用于纯黑盒模型。为了更好地了解哪些图像特征对模型的最终决策有影响,我们的探索场景表明,神经元激活也是必不可少的。但由于大量的逻辑神经元单元分布在多层结构中,因此要找到一组最终受到输入扰动强烈影响的神经元是非常耗时的。因此,在未来,我们计划研究在神经元激活视图中选择显示神经元的替代方法。此外,支持发现潜在有害干扰因素的视觉指导也会有所帮助。然而,传统的引导机制可能需要昂贵的计算,这将阻碍交互性(R3)。因此,有效的指导机制可以被认为是未来有趣的工作。未来工作的另一个有趣的方面是支持编码器-解码器架构,主要用于语义分割和图像翻译任务等。这可以通过将预测视图替换为不断更新的生成图像显示来实现。
读后感: 介绍了Perturber网页交互工具,对用户生成的3D图像,可实时输出模型预测,通过激活视图、特征可视化来探索扰动对模型的影响。文中还提到:经过对抗训练的模型比未经过对抗训练的模型在某些方面(敌对背景、主对象旋转)更容易受到扰动。