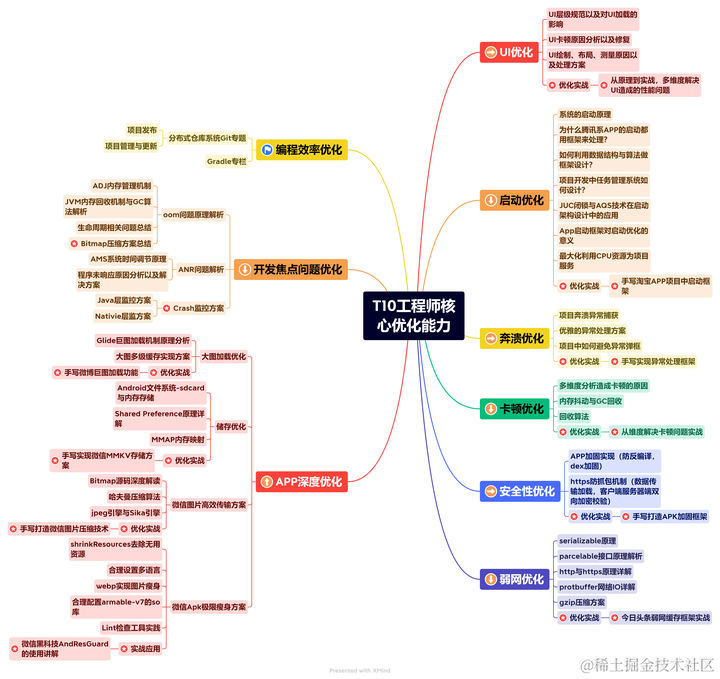
推荐基于稳定扩散(stable diffusion) AI 模型开发的自动纹理工具: DreamTexture.js自动纹理化开发包 - NSDT
稳定扩散是潜在扩散模型的一个版本。潜在空间用于获得数据的低维表示的好处。之后,使用扩散模型和添加和去除噪声的方法根据文本生成图像。在接下来的章节中,我将更详细地描述潜在空间以及扩散模型的功能方式,我将提供一个有趣的示例,说明模型可以根据给定文本生成的图像。
潜在空间
简单地说,伪装的潜在空间是压缩数据的表示。数据压缩被定义为通过使用比原始表示中更小的位对信息进行编码的过程。让我们想象一下,我们必须使用 20 维向量呈现一个 10 维向量。通过降低维度,我们正在丢失数据。但是,在这种情况下,这并不是一件坏事。降低维度使我们能够过滤不太重要的信息,只保留最重要的信息。
简而言之,假设我们想要使用全连接卷积神经网络来训练对图像进行分类的模型。当我们说模型正在学习时,我们的意思是它正在学习神经网络每一层的特定属性。例如,这些是边缘、特定角度、形状等。每当模型必须使用数据(已存在的图像)进行学习时,图像的尺寸都会在恢复到原始大小之前减小。最后,该模型使用解码器从压缩数据中重建图像,同时事先学习所有相关信息。因此,空间变小,以便最重要的属性被解救和保留。这就是为什么潜在空间适用于扩散模型的原因。有一种方法可以从包含许多细节的大量图像的训练集中挑选出最重要的属性,并且这些属性可用于对相同或不同类别中的两个任意对象进行分类,这非常有用。
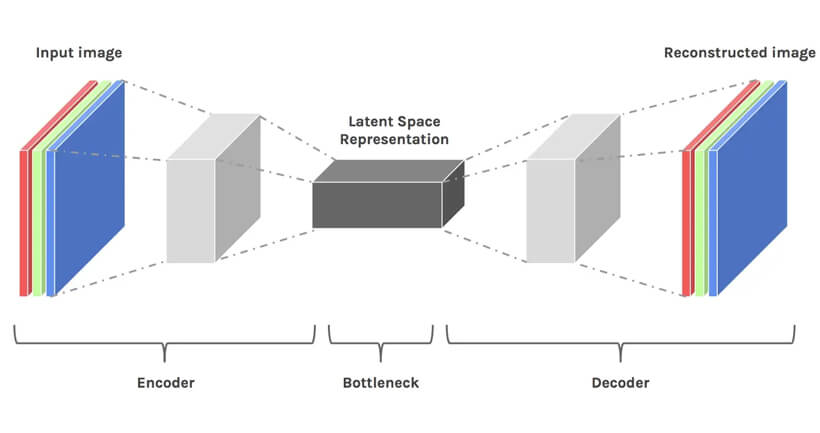
使用卷积神经网络解救最重要的属性
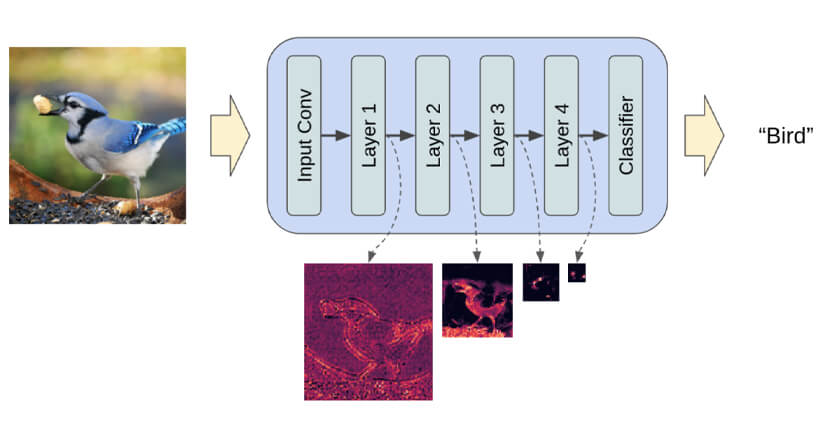
使用卷积神经网络解救最重要的属性
扩散模型
扩散模型是生成模型。它们用于生成与训练它们所依据的数据相似的数据。从根本上说,扩散模型的功能是通过迭代添加高斯噪声来“破坏”训练的数据,然后它们学习如何通过消除噪声来恢复数据。

高斯噪声
前向扩散过程是将越来越多的噪声添加到图像中的过程。因此,拍摄图像并以 t 个不同的时间步长添加噪声,其中在 T 点中,整个图像只是噪声。与前向扩散过程相比,后向扩散是一个相反的过程,在前向扩散过程中,来自时间步长t的噪声在时间步长t-1中被迭代去除。重复这个过程,直到使用U-Net卷积神经网络从图像中去除整个噪声,该网络除了在机器学习和深度学习中的所有应用外,还经过训练来估计图像上的噪声量。

从左到右,图片演示了噪声的迭代添加,从右到左,它展示了噪声的迭代去除。
为了估计和消除噪声,最常使用U-Net。有趣的是,神经网络的架构让我们想起了字母U,这就是它的名字。U-Net 是一个全连接的卷积神经网络,这使得它对图像处理非常有用。U-Net的特点是能够以图像为入口,通过减少采样来找到该图像的低维表示,这使得它更适合处理和查找重要属性,然后通过增加采样将图像恢复到第一维。

更详细地说,去除噪声,即从时间步骤 t-1 中的任意时间步骤 t 过渡,其中 t 编号是 T0(没有噪声的图像)和最终数字 TMAX(总噪声)之间的数字,其方式如下:输入是时间步长 t 中的图像,在该时间步长中,图像上存在特定的噪声。使用U-Net神经网络,可以预测噪声的总量,然后在时间步长t中从图像中去除总噪声的“部分”。这就是在噪声较少的时间步长 t-1 中获取图像的方式。

从数学上讲,将这种方法进行 T 次比尝试消除整个噪声更有意义。通过重复这种方法,噪音将逐渐消除,我们将获得更“干净”的图像。一个简化的过程如下:有一个带有噪声的图像,我们试图通过在初始位置添加完整的噪声并迭代地去除它来预测没有噪声的图像。

稳定扩散
为什么要稳定扩散?扩散模型最大的问题是,在时间和计算方面,它们非常“昂贵”。考虑到U-Net的功能,稳定扩散克服了上述问题。如果我们想生成尺寸为 1024x1024 的图像,U-Net 应该使用 1024x1024 大小的噪点,然后从中制作图像。对于一个扩散步骤来说,这可能是一种昂贵的方法,特别是如果该方法在t甚至可以达到一百个时重复。在以下示例中,时态步长数为 45。稳定的扩散模型在大约 6 秒内为给定的步骤数生成两张图像,而其他一些扩散模型甚至需要 5 到 20 分钟,具体取决于 GPU 规格和图像大小。最有趣的部分是,即使有 8 GB 的 VRAM 内存,也可以在本地成功启动稳定的扩散模型。到目前为止,这个问题已经通过在 256x256 大小的较小图像上进行训练来解决,然后使用额外的神经网络来生成更高分辨率的图像(超分辨率扩散)。潜在扩散模型有不同的方法。概念潜在扩散模型不直接在图像上操作,而是在潜在空间中操作!初始图像实际上是在更小的空间中编码的,因此通过使用 U-Net 在图像的低维表示上添加和删除噪声。

稳定扩散模型的最终架构
可能性
考虑到该模式的复杂架构,稳定扩散可以通过使用文本提示“从头开始”生成图像,其中可以描述应该显示或遗漏哪些元素。此外,也可以使用文本提示在现有图像上添加新元素。最后,我想给大家举一个例子——在网站 huggingface.co 上,有一个空间,你可以用一个稳定的扩散模型来尝试不同的东西。以下是在提示中写下文字“A pikachu fine dining with a view to the Eiffel Tower”时的结果:

与空间的直接联系:https://huggingface.co/spaces/stabilityai/stable-diffusion
在过去的几个月里,Stable Diffusion获得了巨大的宣传。其原因是源代码可供所有人使用,并且稳定扩散不对生成的图像拥有任何权利,并且它还允许人们发挥创造力,这可以从该模型创建的大量令人难以置信的已发布图像中看出。我们可以自由地说,生成模型每周都会开发和改进,跟踪它们的未来进展将非常有趣。
转载:什么是稳定扩散,它是如何工作的? (mvrlink.com)