1.关系型数据库(MySQL)和非关系型数据库(nosql)区别
存储方式:关系型以表的形式 非关系型以键值对形式
应用场景:关系型一致性要求较高,非关系型并发性要求较高
2. Mysql如何实现的索引机制?
MySQL中索引分三类:B+树索引、Hash索引、全文索引
Hash辅助查询 系统自动生成
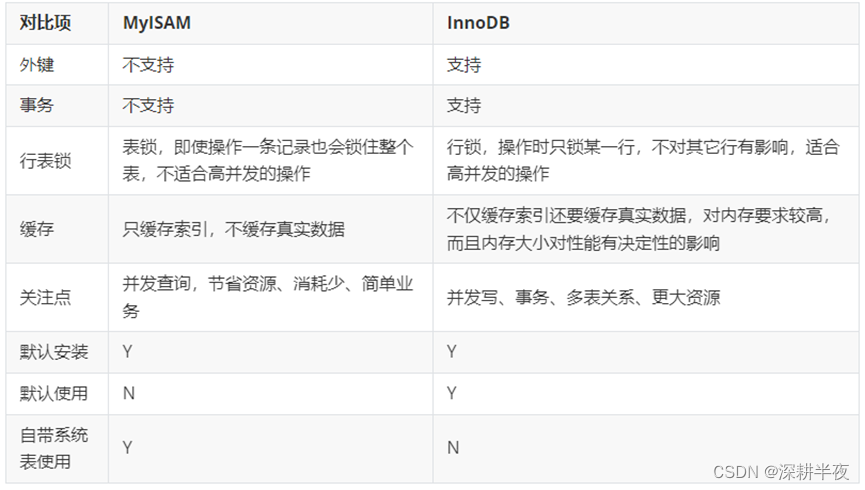
3. InnoDB索引与MyISAM索引实现的区别是什么?
InnoDB中包含聚簇索引 MyISAM都是非聚簇索引(以非主键列作为搜索条件)
InnoDB 数据和索引存储在一起 ;MyISAM 索引和数据分开存储
因此在进行查询时在InnoDB存储引擎中,我们只需要根据主键值对聚簇索引进行一次查找就能找到对应的记录,而在MyISAM中却需要进行一次回表操作(根据查询到的主键 去聚簇索引中查找对应值)
4.一个表中如果没有创建索引,那么还会创建B+树吗?
会
如果有主键会创建聚簇索引
如果没有主键会生成rowid作为隐式主键
5. 聚簇索引与非聚簇索引b+树实现有什么区别?
5.1聚簇索引:
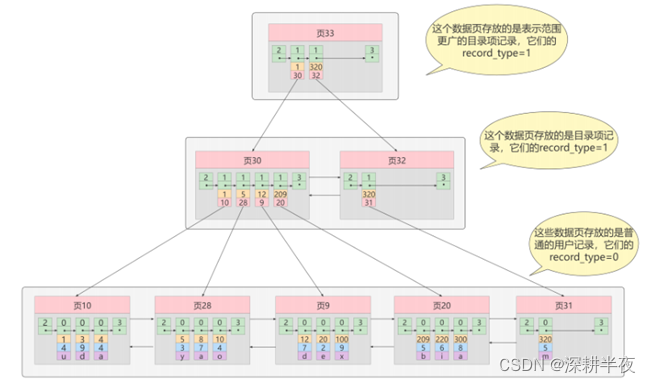
- 数据和索引存储在一个B+树
- 页内的记录是按照主键的大小顺序排成一个单向链表 。
- 页和页之间也是根据页中记录的主键的大小顺序排成一个双向链表 。
- 非叶子节点存储的是记录的`主键+页号`。
- 叶子节点存储的是`完整的用户记录`。
优点:
- 数据访问更快 ,因为索引和数据保存在同一个B+树中,因此从聚族索引中获取数据比非聚族索引更快。
- 聚簇索引对于主键的排序查找和范围查找速度非常快
- 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于 数据都是紧密相连,数据库可以从更少的数据块中提取数据,节省了大量的IO操作。
缺点
- 插入非自增数据比较麻烦 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能.因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于lnnoDB表,我们一般定义 主键为不可更新。
5.2非聚簇索引
(二级索引、辅助索引)
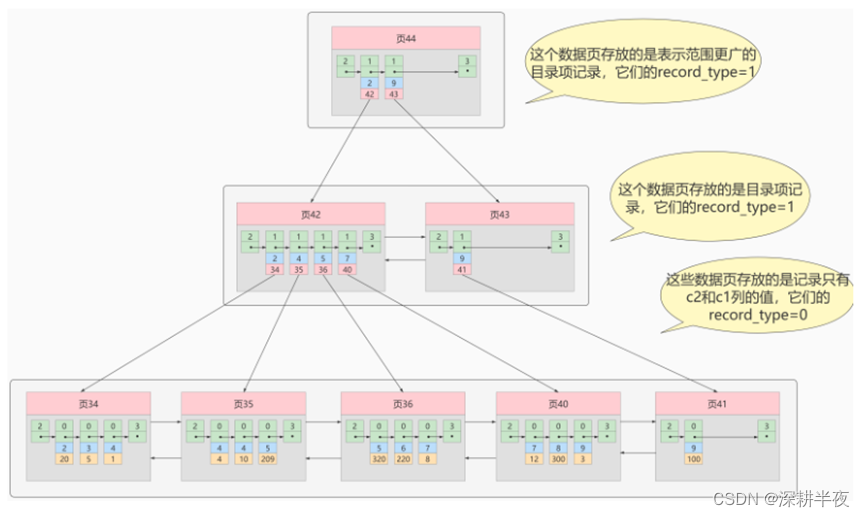
聚族索引,只能在搜索条件是主键值时才发挥作用,因为B+树中的数据都是按照主键进行排序的,如果我们想以别的列作为搜索条件,那么需要创建非聚簇索引。
不同:
叶子节点存储的并不是完整的用户记录,而只是c2列+主键这两个列的值;
查询到对应主键后再去另一个聚簇索引找;
一张表可以有多个非聚簇索引;
聚簇索引优点:
聚簇索引范围,排序查找效率高,因为是有序的;
非聚簇索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据
非优点:
1.相对于聚簇索引 非聚簇索引避免全表扫描
2.聚簇索引插入新值比采用非聚簇索引插入新值的速度要慢很多,因为插入要保证主键不能重复
6.使用B+树存储的索引crud执行效率如何?
新增 删除 稍微麻烦 查找修改 特别方便
7. 索引的优缺点是什么?
优点:
顺序读写更快
范围快速查找
缺点
占用空间:每一个索引都会创建一个B+树 B+树的每个页都会占用16KB
8. 什么是覆盖索引?
覆盖索引方法:将被查询的字段,建立到联合索引里去
age,name -> index
select age from user where age >20 and name like"张%" ; (age,name覆盖了查询的age)
优点:
覆盖索引不会回表查询,查询效率也是比较高的
9. 为什么要回表查询?直接存储数据不可以吗?
为了控制非聚簇索引的大小; ( 非聚簇索引如果也存储数据 数据会多拷贝一份 且在修改的时候也会多一倍 IO会变高)
10. 什么是联合索引,组合索引,复合索引?
为c2和c3列建立联合索引,如下所示:
c2,c3 - > index
where c2=? and c3=?; 全职匹配
where c2=?; 最左前缀 或者C2
where c3=? ; 不可查 因为需要先C2在C3
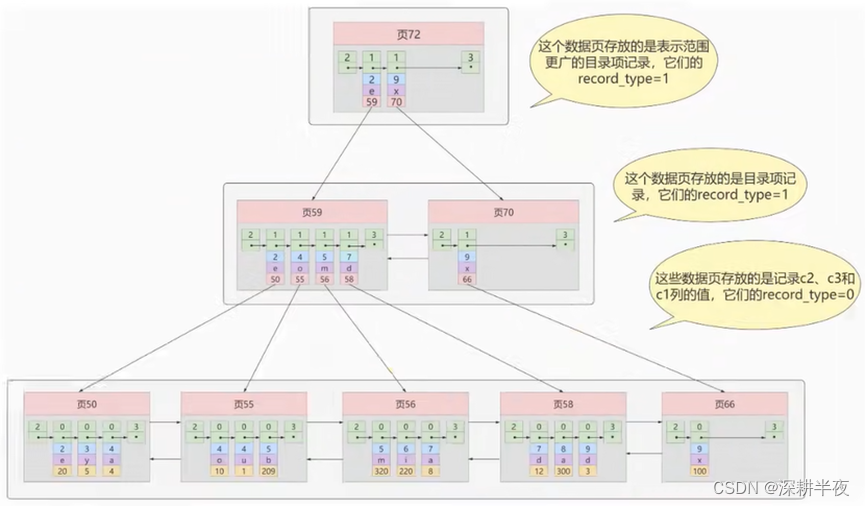
11.什么是唯一索引?
唯一索引:索引列值必须唯一,允许有NULL值,且NULL可能会出现多次。
与聚簇索引区别:聚簇索引不允许为空
12.什么时候使用唯一索引?
业务需求唯一字段的时候,一般不考虑性能问题(学号 身份证号)
13.什么时候适合创建索引,什么时候不适合创建索引?
适合创建索引
- 频繁作为where条件语句查询字段
- 关联字段需要建立索引
- 排序字段可以建立索引
- 分组字段可以建立索引(因为分组前提是排序)
- 统计字段可以建立索引(如.count(),max())
不适合创建索引
- 频繁更新的字段不适合建立索引
- where,分组,排序中用不到的字段不必要建立索引
- 可以确定表数据非常少不需要建立索引
- 参与mysql函数计算的列不适合建索引
创建索引时避免有如下极端误解:
1)宁滥勿缺。认为一个查询就需要建一个索引。
2)宁缺勿滥。认为索引会消耗空间、严重拖慢更新和新增速度。
3)抵制惟一索引。认为业务的惟一性一律需要在应用层通过“先查后插”方式解决。









![[C++随笔录] 红黑树](https://img-blog.csdnimg.cn/d0b5d8ae5e924023b4a115816862b588.png)