目录
前言
标签 download
a 标签链接下载的实现
1. 整体流程
2. 实现步骤
3. 类图
4. 代码示例
download 使用注意点
1. 同源 URL 的限制
2. 不能携带 Header
Blob 转换
方法1. 用作 URL(blob:)
方法2. 转换为 base64(data:)
两种方法总结与对比
responseType
扩展阅读
1. Blob
2. URL.createObjectURL()
3. URL.revokeObjectURL()
4. FileReader.readAsDataURL()
前言
在中后台项目中,前端难免需要处理下载的逻辑,需要下载的内容包括但不限于图片、Excel表格、CSV文件、MP4文件、PDF文件、TXT文件、JSON文件、HTML文件等等。虽然下载的内容各式各样,但是下载的原理大同小异。下面来一起学习一下前端是如何处理下载的。
<a> 标签 download
这应该是最常见,最受广大人民群众喜闻乐见的一种下载方式了,搭配上 download 属性, 就能让浏览器将链接的 URL 视为下载资源,而不是导航到该资源。
如果 download 再指定个 filename ,那么就可以在下载文件时,将其作为预填充的文件名。不过名字中的 / 和 \ 会被转化为下划线 _,而且文件系统可能会阻止文件名中的一些字符,因此浏览器会在必要时适当调整文件名。
a 标签链接下载的实现
1. 整体流程
为了实现通过a标签链接下载文件,我们需要对a标签的href属性进行设置,使其指向文件的下载链接。具体步骤如下表所示:
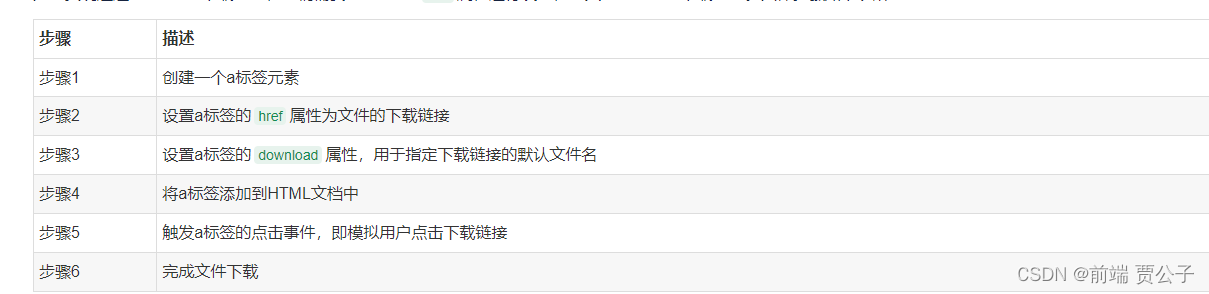
下面我们将逐步介绍每个步骤需要做的事情,并提供相应的代码和注释。
2. 实现步骤
步骤1:创建一个a标签元素
首先,我们需要使用document.createElement方法创建一个a标签元素,并将其赋值给一个变量,以便后续操作。
// 创建一个a标签元素
const downloadLink = document.createElement('a');步骤2:设置a标签的href属性为文件的下载链接
接下来,我们需要将下载链接赋值给a标签的href属性,以便浏览器能够正确地下载文件。
// 设置a标签的href属性为下载链接
downloadLink.href = ''步骤3:设置a标签的download属性,用于指定下载链接的默认文件名
如果我们想要指定下载链接的默认文件名,可以使用a标签的download属性。这样,当用户点击下载链接时,浏览器会自动将文件以指定的文件名保存到本地。
// 设置a标签的download属性为文件名
downloadLink.download = 'file.pdf'步骤4:将a标签添加到HTML文档中
我们需要将创建的a标签元素添加到HTML文档中的某个元素中,以便用户能够看到下载链接并进行下载操作。
// 将a标签添加到HTML文档中的某个元素中
document.body.appendChild(downloadLink);步骤5:触发a标签的点击事件,即模拟用户点击下载链接
为了触发文件的下载,我们需要模拟用户点击a标签的行为。可以使用click方法来触发a标签的点击事件。
// 触发a标签的点击事件,即模拟用户点击下载链接
downloadLink.click();步骤6:完成文件下载
通过以上步骤,我们已经成功地实现了通过a标签链接下载文件的功能。用户点击下载链接后,浏览器会自动下载文件到本地。
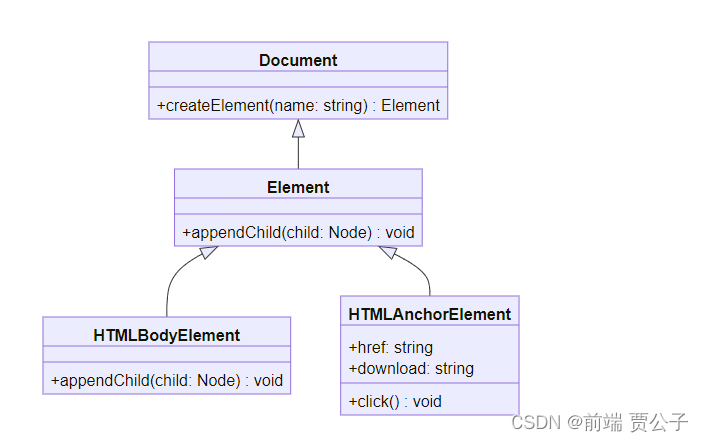
3. 类图
下面是本文所涉及的类的关系示意图:
4. 代码示例
// 创建一个a标签元素
const downloadLink = document.createElement('a');
// 设置a标签的href属性为下载链接
downloadLink.href = '
// 设置a标签的download属性为文件名
downloadLink.download = 'file.pdf';
// 将a标签添加到HTML文档中的某个元素中
document.body.appendChild(downloadLink);
// 触发a标签的点击事件,即模拟用户点击下载链接
downloadLink.click();
download 使用注意点
<a> 标签虽好,但还有一些值得注意的点:
1. 同源 URL 的限制
download 只在同源 URL 或 blob: 、 data: 协议起作用
也就是说跨域是下载不了的......(这种说法不全对,除非后端配置 Content-Disposition 为 attachment,后面会讲)
首先,非同源 URL 会进行导航操作。其次,如果非要下载,可以先将其转换为 blob: 或 data: 再进行下载
2. 不能携带 Header
使用 <a> 标签下载是带不了 Header 的,因此不能通过添加请求表头的形式来鉴权,但是可以将 sessionid 或 token 字段拼接到 URL 末尾来达到鉴权的目的。这里我们给出另一个解决方案:
- 先发送请求获取 blob 文件流,这样就能在请求时进行鉴权;
- 鉴权通过后再执行下载操作。
这样是不是就能很好的同时解决问题1和问题2带来的两个痛点了呢,而且下载的文件名也能自定义了
顺便提一下,location.href 和 window.open 也存在同样的问题。
Blob 转换
前文介绍到,在非同源请情况下可以将资源当成二进制的 blob 先拿到手,再进行 <a> 的下载处理。接下来,我们介绍两种 blob 的操作:
方法1. 用作 URL(blob:)
URL.createObjectURL 可以给 File 或 Blob 生成一个URL,形式为 blob:<origin>/<uuid>,此时浏览器内部就会为每个这样的 URL 存储一个 URL → Blob 的映射。因此,此类 URL 很短,但可以访问 Blob。
// 下载 Excel 方法
excel(data, fileName) {
this.download0(data, fileName, "application/vnd.ms-excel");
},
// 下载 Word 方法
word(data, fileName) {
this.download0(data, fileName, "application/msword");
},
// 下载 Zip 方法
zip(data, fileName) {
this.download0(data, fileName, "application/zip");
},
// 下载 Html 方法
html(data, fileName) {
this.download0(data, fileName, "text/html");
},
// 下载 Markdown 方法
markdown(data, fileName) {
this.download0(data, fileName, "text/markdown");
},
download0(data, fileName, mineType) {
// 创建 blob
let blob = new Blob([data], { type: mineType });
// 创建 href 超链接,点击进行下载
window.URL = window.URL || window.webkitURL;
let href = URL.createObjectURL(blob);
let downA = document.createElement("a");
downA.href = href;
downA.download = fileName;
downA.click();
// 销毁超连接
window.URL.revokeObjectURL(href);
},不过它有个副作用。虽然这里有 Blob 的映射,但 Blob 本身只保存在内存中的。浏览器无法释放它。
在文档退出时(unload),该映射会被自动清除,因此 Blob 也相应被释放了。但是,如果应用程序寿命很长,那这个释放就不会很快发生。
因此,如果我们创建一个 URL,那么即使我们不再需要该 Blob 了,它也会被挂在内存中。
不过,URL.revokeObjectURL 可以从内部映射中移除引用,允许 Blob 被删除并释放内存。所以,在即时下载完资源后,不要忘记立即调用 URL.revokeObjectURL。
方法2. 转换为 base64(data:)
作为 URL.createObjectURL 的一个替代方法,我们也可以将 Blob 转换为 base64-编码的字符串。这种编码将二进制数据表示为一个由 0 到 64 的 ASCII 码组成的字符串,非常安全且“可读”。
更重要的是 —— 我们可以在 “data-url” 中使用此编码。“data-url” 的形式为 data:[<mediatype>][;base64],<data>。我们可以在任何地方使用这种 url,和使用“常规” url 一样。
FileReader 是一个对象,其唯一目的就是从 Blob 对象中读取数据,我们可以使用它的 readAsDataURL 方法将 Blob 读取为 base64。请看以下示例:
let blob = new Blob([res.data]); // res.data是后台返回的文件
let reader = new FileReader();
reader.readAsDataURL(blob);
reader.onload = (e) => {
// 转换完成,创建一个a标签用于下载
let a = document.createElement('a');
a.download = fileName;
a.href = e.target.result;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
}在上述例子中,我们先实例化了一个 fileReader,用它来读取 blob。
一旦读取完成,就可以从 fileReader 的 result 属性中拿到一个data: URL 格式的 Base64 字符串。
最后,我们给 fileReader 注册了一个 onload 事件,在读取操作完成后开始下载。
两种方法总结与对比
URL.createObjectURL(blob) 可以直接访问,无需“编码/解码”,但需要记得撤销(revoke);
而 Data URL 无需撤销(revoke)任何操作,但对大的 Blob 进行编码时,性能和内存会有损耗。
总而言之,这两种从 Blob 创建 URL 的方法都可以用。但通常 URL.createObjectURL(blob) 更简单快捷。
responseType
export const fetchFile = async (params) => {
return axios.get(api, {
params,
responseType: "blob"
});
};最后,我们回头说一下请求的注意点:如果你的项目使用的是 XHR (比如 axios)而不是 fetch, 那么请记得在请求时添加上 responseType 为 'blob'。
responseType 不是 axios 中的属性,而是 XMLHttpRequest 中的属性,它用于指定响应中包含的数据类型,当为 "blob" 时,表明 Response 是一个包含二进制数据的 Blob 对象。
除了 blob 之外,responseType 还有 arraybuffer、json、text等其他枚举字符串值。
扩展阅读
1. Blob
Blob 全称为 binary large object ,即二进制大对象,它是 JavaScript 中的一个对象,表示原始的类似文件的数据。下面是 MDN 中对 Blob 的解释:
Blob 对象表示一个不可变、原始数据的类文件对象。它的数据可以按文本或二进制的格式进行读取,也可以转换成 ReadableStream 来用于数据操作。
实际上,Blob 对象是包含有只读原始数据的类文件对象。简单来说,Blob 对象就是一个不可修改的二进制文件。
(1)Blob 创建
可以使用 Blob() 构造函数来创建一个 Blob:
new Blob(array, options);
其有两个参数:
array:由ArrayBuffer、ArrayBufferView、Blob、DOMString等对象构成的,将会被放进Blob;options:可选的BlobPropertyBag字典,它可能会指定如下两个属性type:默认值为 "",表示将会被放入到blob中的数组内容的 MIME 类型。endings:默认值为"transparent",用于指定包含行结束符\n的字符串如何被写入,不常用。
常见的 MIME 类型如下:

下面来看一个简单的例子:
const blob = new Blob(["Hello World"], {type: "text/plain"});这里可以成为动态文件创建,其正在创建一个类似文件的对象。这个 blob 对象上有两个属性:
size:Blob对象中所包含数据的大小(字节);type:字符串,认为该Blob对象所包含的 MIME 类型。如果类型未知,则为空字符串。
下面来看打印结果:
const blob = new Blob(["Hello World"], {type: "text/plain"});
console.log(blob.size); // 11
console.log(blob.type); // "text/plain"注意,字符串"Hello World"是 UTF-8 编码的,因此它的每个字符占用 1 个字节。
到现在,Blob 对象看起来似乎我们还是没有啥用。那该如何使用 Blob 对象呢?可以使用 URL.createObjectURL() 方法将将其转化为一个 URL,并在 Iframe 中加载:
<iframe></iframe>
const iframe = document.getElementsByTagName("iframe")[0];
const blob = new Blob(["Hello World"], {type: "text/plain"});
iframe.src = URL.createObjectURL(blob);2. URL.createObjectURL()
URL.createObjectURL() 静态方法会创建一个 DOMString,其中包含一个表示参数中给出的对象的 URL。这个 URL 的生命周期和创建它的窗口中的 document 绑定。这个新的 URL 对象表示指定的 File 对象或 Blob 对象。
备注: 此特性在 Web Worker 中可用
备注: 此特性在 Service Worker 中不可用,因为它有可能导致内存泄漏。
语法
objectURL = URL.createObjectURL(object);
参数 :object:用于创建 URL 的 File 对象、Blob 对象或者 MediaSource 对象。
返回值 :一个DOMString包含了一个对象 URL,该 URL 可用于指定源 object的内容。
内存管理
在每次调用 createObjectURL() 方法时,都会创建一个新的 URL 对象,即使你已经用相同的对象作为参数创建过。当不再需要这些 URL 对象时,每个对象必须通过调用 URL.revokeObjectURL() 方法来释放。
浏览器在 document 卸载的时候,会自动释放它们,但是为了获得最佳性能和内存使用状况,你应该在安全的时机主动释放掉它们。
3. URL.revokeObjectURL()
URL.revokeObjectURL() 静态方法用来释放一个之前已经存在的、通过调用 URL.createObjectURL() 创建的 URL 对象。当你结束使用某个 URL 对象之后,应该通过调用这个方法来让浏览器知道不用在内存中继续保留对这个文件的引用了。
你可以在 sourceopen 被处理之后的任何时候调用 revokeObjectURL()。这是因为 createObjectURL() 仅仅意味着将一个媒体元素的 src 属性关联到一个 MediaSource 对象上去。调用revokeObjectURL() 使这个潜在的对象回到原来的地方,允许平台在合适的时机进行垃圾收集。
备注: 此特性在 Web Worker 中可用
语法:window.URL.revokeObjectURL(objectURL);
参数: 一个 objo'b'jDOMString,表示通过调用 URL.createObjectURL() 方法产生的 URL 对象。
返回值 undefined
4. FileReader.readAsDataURL()
readAsDataURL 方法会读取指定的 Blob 或 File 对象。读取操作完成的时候,readyState 会变成已完成DONE,并触发 loadend 事件,同时 result 属性将包含一个data:URL 格式的字符串(base64 编码)以表示所读取文件的内容
语法
readAsDataURL(blob)参数 blob即将被读取的 Blob 或 File 对象。
例子
<input type="file" onchange="previewFile()" /><br />
<img src="" height="200" alt="Image preview..." />
function previewFile() {
var preview = document.querySelector("img");
var file = document.querySelector("input[type=file]").files[0];
var reader = new FileReader();
reader.addEventListener(
"load",
function () {
preview.src = reader.result;
},
false,
);
if (file) {
reader.readAsDataURL(file);
}
}
![[C++随笔录] 红黑树](https://img-blog.csdnimg.cn/d0b5d8ae5e924023b4a115816862b588.png)