大型语言模型(LLM)的日益普及引爆了向量数据库赛道,向量搜索技术也越发受到开发者关注。目前,主流的向量搜索技术提供者包括向量数据库 Milvus 和 Zilliz Cloud,向量搜索库 FAISS,以及与传统数据库集成的向量搜索插件。
与此同时,向量搜索日益成为检索增强生成(retrieval augmented generation,RAG)中的一个重要组件。RAG(https://zilliz.com.cn/use-cases/llm-retrieval-augmented-generation) 这一类的问答应用是一种重要的生成式 AI 的企业级用例。在 RAG 应用中, LLM 可以轻松访问知识库,并将其用作上下文来回答问题。而实现这一应用的关键就在向量数据库。Milvus 是一款高度可扩展的开源向量数据库,专为此应用而设计。
01.构建 RAG
在构建高效的 RAG 式 LLM 应用程序时,我们有许多可以优化的配置,不同配置的选择极大影响了检索质量。可以选择的配置包括:
向量数据库的选择
-
数据选择
-
Embedding 模型
-
索引类型
找到高质量、能精准符合需求的数据非常关键。如果数据不够准确,检索可能返回无关的结果。选择好相关数据之后,还要考虑使用的 Embedding 模型。因为选择的模型对检索质量也有很大影响。如果 Embedding 模型无法理解特定领域内容的语义,不论使用什么数据库,检索器都有可能给出错误的结果。上下文相关度是衡量检索质量的一个关键指标,而向量数据库的选择极大地影响了这个指标结果。
最后,索引类型可以显著影响语义搜索的效率。索引类型的选择在大型数据集面前尤其重要。不同的索引类型允许用户在召回率、速度和资源需求之间进行权衡。Milvus 支持多种索引类型,比如 FLAT、乘积量化(product quantization)索引和基于图(graph-based)的索引。
检索参数的选择
-
检索到的上下文数量(top-K)
-
分块大小
当进行检索时,top-K 是一个重要参数,它控制检索到的上下文分块数量。更高的 top-K 意味着检索到所需信息的可能性越高。但是,过高的 top-K 也会导致回答中带入不相关的信息。因此,对于简单的问题,一般情况下推荐较低的 top-K 值,这样检索性能和结果都更佳。
分块大小控制检索上下文的大小。对于相对复杂的问题而言,分块大小越大,检索效果越好。对于较为简单的问题,由于只需要很小一部分信息即可回答,因此分块较小时效果最好。
那是否存在一套绝对的解决方案和配置能够帮助我们应对所有情况呢?答案是没有。不同的数据类型和规模、语言模型、向量数据库组合会产生不同的性能结果。因此我们需要根据自己的使用场景和需求,用评估工具来评价不同的配置选择在具体用例中的质量。在评估时,就会用到 TruLens。
02.TruLens 用于语言模型应用跟踪和评估
TruLens 是一个用于评估语言模型应用(如 RAG)的性能的开源库。通过 TruLens,我们还可以利用语言模型本身来评估输出、检索质量等。
构建语言模型应用时,多数人最关心的问题是 AI 幻觉(hallucination)。RAG 通过为语言模型提供检索上下文来确保信息准确性,但始终无法百分百保证提供完全准确的信息。因此,应用不会产生幻觉是评估验证重点的一个重要指标。TruLens 提供了 3 项测试:
-
上下文相关度
-
答案准确性
-
答案相关度
接下来,让我们逐一来看一下这三项测试:
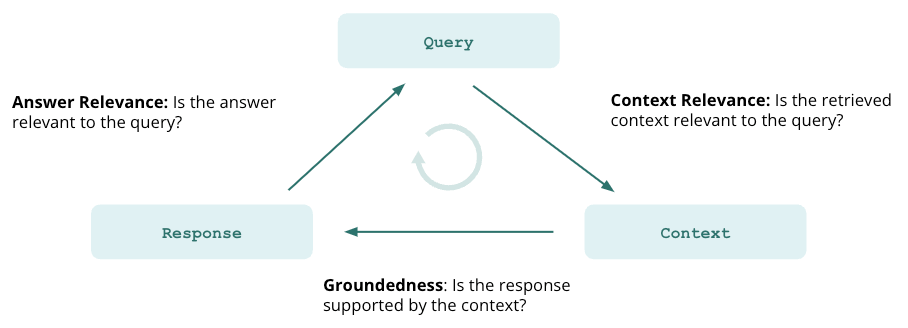
上下文相关度
所有 RAG 应用第一步是检索。为验证检索质量,要确保每个上下文块与输入查询相关。因为语言模型将使用该上下文生成答案,所以上下文中的任何不相关信息都可能导致 LLM 出现幻觉。
答案准确性
在检索上下文后,LLM 生成答案。一些情况下, LLM 往往会偏离事实,对正确的答案进行夸张或扩展。为验证回答的准确性,我们应将回复分为独立语句,并在检索上下文中独立查证每个语句的出处来源。
答案相关度
最后,我们的回复仍须解答原始问题,可以通过评估最终回复与用户输入提问的相关度来验证这一点。
如果上述三项指标结果均令人满意,那我们可以说,在经过知识库验证后,消除了 RAG 幻觉。换言之,如果向量数据库包含的信息十分准确,则 RAG 提供的答案也准确。
03.具体案例
如前所述,RAG 配置选择可能对消除幻觉产生重大影响。下文中将基于城市百科文章构建问答 RAG 应用并展示不同的配置选择是如何影响应用性能的。在搭建过程中,我们使用 LlamaIndex 作为该应用的框架。大家可以在 Google Colab( https://colab.research.google.com/github/truera/trulens/blob/main/trulens_eval/examples/expositional/vector-dbs/milvus/milvus_evals_build_better_rags.ipynb) 中所有代码。
从百科加载数据
首先需要加载数据。这里,我们使用 LlamaIndex 中的数据加载器直接从百科加载数据。
from llama_index import WikipediaReader
cities = [
"Los Angeles", "Houston", "Honolulu", "Tucson", "Mexico City",
"Cincinatti", "Chicago"
]
wiki_docs = []
for city in cities:
try:
doc = WikipediaReader().load_data(pages=[city])
wiki_docs.extend(doc)
except Exception as e:
print(f"Error loading page for city {city}: {e}")
设置评估器
接着,设置评估器,我们会使用前面提到的三项测试。
TruLens 提供一组使用特定模型(如 OpenAI、Anthropic 或 HuggingFace)的提示评估器或反馈功能。
# Initialize OpenAI-based feedback function collection class:openai_gpt4 = feedback.OpenAI()
设置模型后,我们先测试查询语句相关度。在每项评估中,用思维链(chain-of-thought)来更好地了解评估结果。具体请见后缀 1_with_cot_reason 表示的反馈函数。
此时,我们还需选择传递给反馈函数的文本。首先 TruLens 序列化应用,然后生成一个类 JSON 结构的索引,用此索引选择文本。TruLens 提供一系列的帮助函数来简化此操作:
-
on_input()自动找到传给 LlamaIndex 应用的主输入,作为传给反馈函数的第一个文本。 -
TruLlama.select_source_nodes()标识 LlamaIndex 检索中使用的源节点。
最后,将每个上下文相关度整合为一个分数值。本例中,我们使用最大值衡量相关度,大家在上手过程中也可使用其他指标,如平均值或最小值。
# Question/statement relevance between question and each context chunk.
f_context_relevance = Feedback(openai.qs_relevance_with_cot_reason, name = "Context Relevance").on_input().on(
TruLlama.select_source_nodes().node.text
).aggregate(np.max)
准确性设置类似,整合过程略有不同。这里,我们取每个语句准确性的最高分和各语句准确性的的平均分。
grounded = Groundedness(groundedness_provider=openai_gpt4)
f_groundedness = Feedback(grounded.groundedness_measure_with_cot_reason, name = "Groundedness").on(
TruLlama.select_source_nodes().node.text # context
).on_output().aggregate(grounded.grounded_statements_aggregator)
答案相关度的反馈函数最容易设置,因为它仅依赖输入/输出。我们可以使用新的 TruLens 帮助函数 .on_input_output()。
# Question/answer relevance between overall question and answer.f_qa_relevance = Feedback(openai.relevance_with_cot_reason,
name = "Answer Relevance").on_input_output()
定义配置空间
在完成加载数据和设置评估器后,便可以开始构建 RAG。在此过程中,我们构建一系列具有不同配置的 RAG,并评估每种选择配置的性能,得出最佳配置。
在此案例中,我们测试了不同索引类型、 Embedding 模型、Top-K 和分块大小。当然,大家也可以测试其他配置,如不同相似度类型(distance metric)和搜索参数。
迭代我们的选择
定义配置空间后,我们用 itertools 尝试每种组合并进行评估。此外,Milvus 的覆盖参数也提供了便利,帮助我们可轻松迭代不同配置。否则如果使用其他向量数据库,我们可能需要重复缓慢的实例化过程。
每次迭代,我们将索引参数选择传给 MilvusVectorStore 和使用存储上下文的应用。将 Embedding 模型传给服务上下文,然后创建索引。
vector_store = MilvusVectorStore(index_params={
"index_type": index_param,
"metric_type": "L2"
},
search_params={"nprobe": 20},
overwrite=True)
llm = OpenAI(model="gpt-3.5-turbo")
storage_context = StorageContext.from_defaults(vector_store = vector_store)
service_context = ServiceContext.from_defaults(embed_model = embed_model, llm = llm, chunk_size = chunk_size)
index = VectorStoreIndex.from_documents(wiki_docs,
service_context=service_context,
storage_context=storage_context)
然后,我们可用该索引构建查询引擎 —— 定义top_k:
query_engine = index.as_query_engine(similarity_top_k = top_k)
构建后,我们用 TruLens 包装应用。这里,我们用易识别的方式命名,将配置记录为应用元数据。随后,定义反馈函数用于评估。
tru_query_engine = TruLlama(query_engine,
app_id=f"App-{index_param}-{embed_model_name}-{top_k}",
feedbacks=[f_groundedness, f_qa_relevance, f_context_relevance],
metadata={
'index_param':index_param,
'embed_model':embed_model_name,
'top_k':top_k
})
这个 tru_query_engine 将像原查询引擎一样运行。
最后,用少量测试提示进行评估,调用应用响应每个提示。由于需要短时间内快速连续调用 OpenAI API,Tenacity 可帮助我们通过指数回退的策略避免速率限制问题。
@retry(stop=stop_after_attempt(10), wait=wait_exponential(multiplier=1, min=4, max=10))def call_tru_query_engine(prompt):
return tru_query_engine.query(prompt)
for prompt in test_prompts:
call_tru_query_engine(prompt)
结果
-
哪种配置表现最佳?


-
哪种配置表现最差?


-
发现了哪些错误类型?
可以观察到,一种错误类型是检索到错误的城市信息。可以从下面的思维链反馈中看到,RAG 检索到了 Tucson 而不是 Houston 的上下文。

同样,我们也遇到 RAG 回答正确城市但回答与输入问题不相关、无关上下文被检索的情况。

基于无关的上下文,语言模型开始出现幻觉。需要区分的是,幻觉不一定是错误的事实,它仅指模型在无证据支持下作答。

此外,我们还发现 RAG 返回不相关回答的情况:

04.深入了解性能
索引类型
本例中,索引类型对查询速度、token 用量或评估没有明显影响。这可能是因为数据量较小的关系。索引类型对较大语料库可能更重要。
Embedding 模型
text-embedding-ada-002 在准确性(0.72,平均 0.60)和答案相关度(0.82,平均0.62)上优于 MiniLM Embedding 模型。两者在上下文相关度上表现一致。这个结果可能是 OpenAI Embedding 更适合百科信息的缘故。
相似度 top-K
top-k 的增加可以略微提高检索质量(通过上下文相关度测量)。检索的文本块越多,检索器获取高质量上下文的可能性越大。
top-K 的增加也改善了准确性(0.71,平均 0.62)和答案相关度(0.76,平均0.68)。检索更多上下文文本块可以为语言模型提供更多支持其结论的内容。但是更高的 top-K 意味着更高的 token 使用成本(每次调用平均需要额外使用 590 个 token)。
分块大小
分块大小越大,包含与输入问题无关的文本越多,检索准确性越低。但是分块越大,为回答提供的支持内容越多。
也就是说,LLM 返回结果时,分块大小越大,可以获得的上下文越多。
分块增大,需要额外增加使用 400 个 token。
本文中,我们学习使用各种配置和参数(包括索引类型、 Embedding 模型、 top-K 和分块大小)构建 RAG。我们的测试得益于 Milvus ,Milvus 拥有各种配置且允许覆盖参数。通过 TruLens 来评估每种配置和参数组合,我们能够快速寻找到性能最佳的参数配置。
如果大家想要尝试探索,可以先安装开源工具 TruLens 和开源向量数据库 Milvus 或全托管的 Milvus 服务 Zilliz Cloud。
本文最初发布于 The New Stack,已获得转载许可。
本文由 mdnice 多平台发布