前言:
之前就写完了,用了几天补一下项目总结,本文会从宏观上介绍整体项目构架和所应用的技术以及项目亮点,最后再加上我个人的感悟。本文适合打算开始写苍穹外卖的小伙伴阅读,提高对整体项目的认知。

往期项目日记:
【苍穹外卖】_我是一盘牛肉的博客-CSDN博客![]() https://blog.csdn.net/fckbb/category_12465202.html?spm=1001.2014.3001.5482
https://blog.csdn.net/fckbb/category_12465202.html?spm=1001.2014.3001.5482
项目介绍:
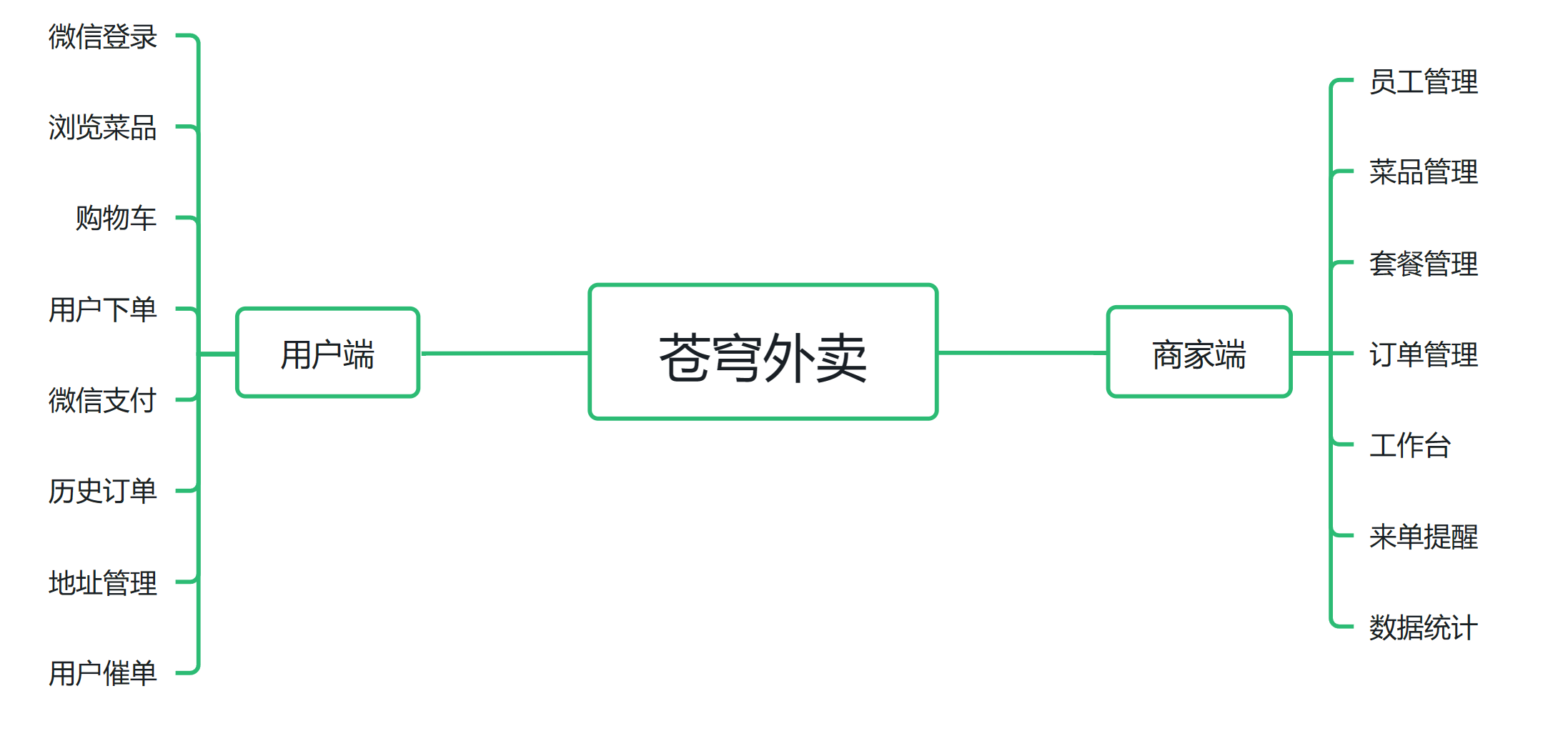
这是一款为餐饮类企业定制的软件产品,分为管理端和用户端。实现用户端点单,管理端处理订单的简易外卖软件
管理端
 用户端
用户端
业务板块介绍:
技术选型:
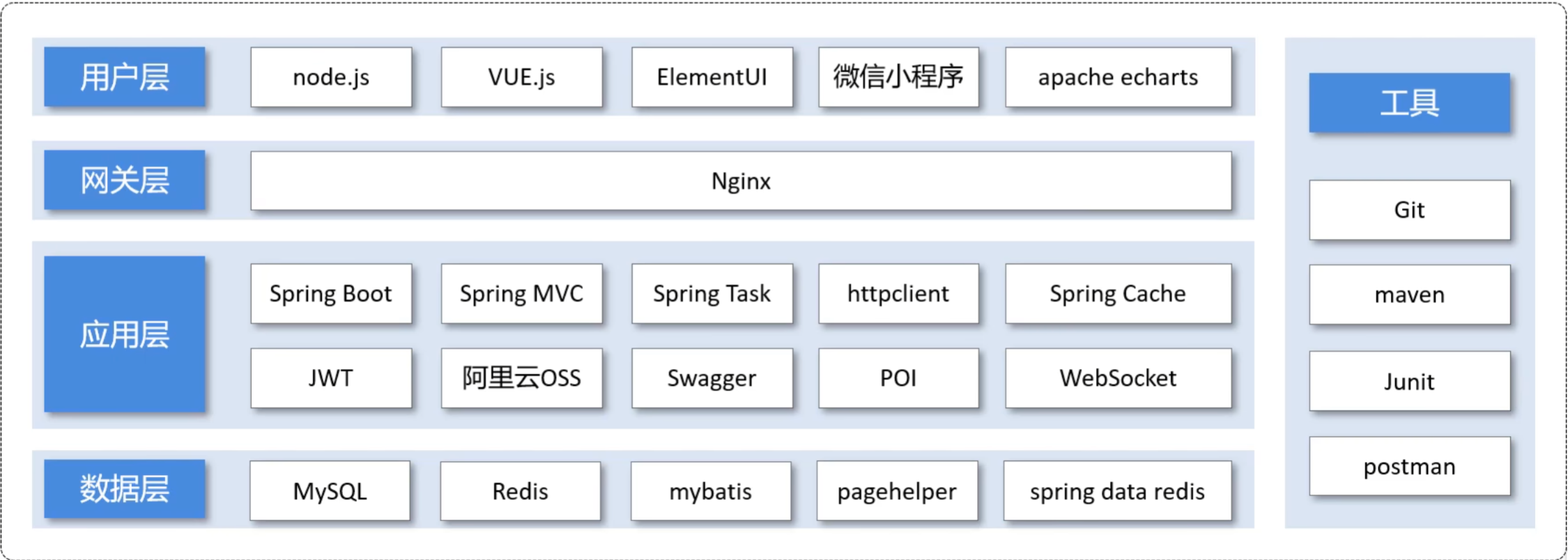
用户层:
商家端:
简单的网页,使用了前端三件套,以及ElementUI,apache echarts 等技术
用户端:
基于微信小程序进行开发,
网关层:
Nginx:
使用Nginx来部署前端。是一款高性能Web开源服务器,在大型项目中,我们可以使用Nginx的负载均衡来合理请求到多台服务器,减小后端服务器压力
应用层:
Spring boot:
基于Spring的开源框架,简化各项配置,使得开发人员专注于业务功能的实现
Spring MVC:
基于 MVC(Model-View-Controller)模式的 Web 应用程序开发框架。它提供了一种结构清晰、模块化的方式来构建可扩展的 Web 应用程序Spring Task:
定时任务依赖,完成相关配置,后端可以定时完成任务Httpclient:
HTTP开源的通信库,使得后端可以发送和处理后端请求,常用于后端请求各种接口时用到
Spring Cache:
缓存依赖,把数据存储到缓存中,如果前端再次请求相同数据,使得后端可以从缓存中拿数据,减少了对数据库的IO操作,降低了后端服务器的压力。
JWT:
令牌技术,校验用户身份。
阿里云OSS:
第三方云存储技术,后端调用阿里云OSS来存储菜品等图片。
Swagger:
开源框架,实现设计、构建和测试RESTful API的开源框架,但在本项目中,我们使用的是Swagger的优化版本Knife4j,它基于注解的方式注解在启动类上,在后端启动之后,在网页输入localhost 8080/doc.html就可以打开相关接口管理界面。
POI:
读取和写入Microsoft Office格式文件,如Word文档、Excel电子表格和PowerPoint演示文稿。
WebSocket:
一种通信协议,允许客户端与服务器进行持久化连接,并且区别于请求-响应模式,WebSocket协议实现了客户端与服务器的双向通信。
数据层:
MySQL:
关系型存储系统,基于表的形式对数据进行存储,直接存储数据到磁盘当中
Redis:
键值型存储系统,基于键值对的形式对数据进行存储,数据会被存储到缓存当中
Mybatis:
开源的持久层框架,简化了java与关系型数据的之间的操作
pagehelper:
分页框架,以注解的形式使用,简化分页查询中的分页查询操作spring data redis:
spring框架提供的与Redis数据库进行交互的模块,简化在java中使用Redis的操作步骤。
工具:
Git:
分布式文件管理工具,追踪管理文件变化,适用于多人开发
maven:
开源的项目管理工具,用于构建和管理Java项目。它提供了一种标准化的项目结构和构建过程,使得开发人员可以更容易地管理项目依赖、构建项目、运行测试和部署应用程序
Junit:
Java开源单元测试框架,可以对指定方法进行单元测试,简化开发人员测试流程
postman:
接口测试工具,可以便捷的代替前端对后端发送各种请求,测试接口运行效果。
后端初始环境介绍:
sky-common层:
| 包名 | 作用 |
| constant | 封装各种常量类,代替硬编码 |
| context | 封装基础上下文类 |
| enumeration | 封装各种枚举类 |
| exception | 封装各种异常类 |
| json | 处理json转换的类 |
| properties | 存放Spring boot的相关配置的类 |
| result | 封装各种返回结果的类 |
| utils | 封装各种工具类 |
sky-pojo层:
| 包名 | 作用 |
| dto | 提供实体,封装前端发送给后端的数据,方便后端处理 |
| entity | 提供各种实体类,例如员工类 |
| vo | 提供实体,封装后端发送给前端的数据,方便前端处理 |
sky-server层:
| 包名 | 作用 |
| annotation | 存放自定义注解 |
| aspect | 存放各种切面 |
| config | 存放各种配置类 |
| controller | 存放各种处理前端请求的方法,向下还细分为管理端,用户端,通用端 |
| handler | 封装和处理异步任务,事件或消息。 |
| interceptor | 存放拦截器,按照指定条件拦截前端请求 |
| mapper | 存放mapper,是Java与MySQL直接进行交互的包 |
| service | 存放各种业务功能的具体实现逻辑方法 |
| Task | 任务类,存放各种任务 |
| websocket | 封装websocket,简化websocket的使用。 |
数据库各张表的作用
| 表名 | 作用 |
| address_book | 存放用户下单地址 |
| category | 存放菜品类型 |
| dish | 存放菜品 |
| dish_flavor | 存放菜品口味 |
| employee | 存放管理端员工信息 |
| order_detail | 存放各个订单的明细 |
| orders | 存放各个订单 |
| setmeal | 存放套餐 |
| setmeal_dish | 存放套餐内的具体菜品 |
| shopping_cart | 购物车,方便前端购物车回显 |
| user | 用户表,存放用户账号密码 |
本数据库建表依据阿里巴巴开源手册
【依据】表名,字段必须时使用小写字母或数字,禁止出现数字开头。
【依据】表名不考虑复数形式,避免混意
此外,本项目的数据表在处理逻辑关系的时候,采用 使用逻辑外键,舍弃物理外键的形式。也就是说:我们的表之间的关系不通过物理外键的形式来进行关联,而是在代码层面使用代码逻辑的方式进行关联。
简单的讲:不在数据库中创建外键的方式构建表关系,而是在代码处理阶段,用代码逻辑来形成表关联,这样可以降低对数据库的访问压力,而且对数据库的修改也会轻松。
项目第一阶段技术:
JWT令牌加密技术:
JWT(JSON Web Token)是一种用于身份验证和授权的开放标准。它由三部分组成,分别是头部(Header)、载荷(Payload)和签名(Signature)。其中,签名是用于验证令牌的完整性和可信任性。
在JWT中,令牌可以通过进行加密来增加安全性。常见的JWT令牌加密技术包括对称加密和非对称加密。
- 对称加密:对称加密使用相同的密钥用于加密和解密令牌。发送方使用密钥将头部和载荷部分加密,并生成签名。接收方使用相同的密钥通过解密和验证签名来验证令牌的完整性和真实性。对称加密是较简单和高效的加密方式,但需要确保密钥的安全性。
- 非对称加密:非对称加密使用一对密钥,即公钥和私钥,用于加密和解密令牌。发送方使用私钥进行签名和加密,接收方使用公钥进行解密和验证签名。非对称加密提供了更高的安全性和可信任性,因为私钥是保密的。但与对称加密相比,非对称加密的计算开销更大。
使用JWT进行令牌加密可以确保令牌的安全性和完整性,防止被篡改或伪造。具体选择哪种加密方式取决于安全需求和性能要求,开发者可以根据具体场景选择合适的加密技术。同时,还需要注意保护私钥的安全,以防止密钥泄露导致令牌被篡改。
JWT技术最常见的应用就是给用户下发身份令牌,在本项目中,我们通过JWT来实现资源请求拦截思想。
如果没有JWT技术,我们只需要知道资源请求的路径,就可以向后端发送相关请求,因为一整个后端的处理逻辑是:接收前端请求,进行业务操作。
但这明显是一个很严重的缺陷,例如用户知道了我们的删除员工的请求路径是:http/xxx/delete/{id}。那他发送这个请求,后端只要接收到这请求,就会执行对应的操作。
而这种缺陷的解决思路也很简单,我们为已经登录的用户下发JWT令牌,后端拦截除了登录请求之外的所有请求,而前端每一次请求都要携带这个JWT令牌。后端对请求拦截后,要对请求中携带的JWT令牌进行处理,如果可以校验通过就放行请求,如果没有令牌或者解析错误,就返回登录界面。
验证登录的代码界面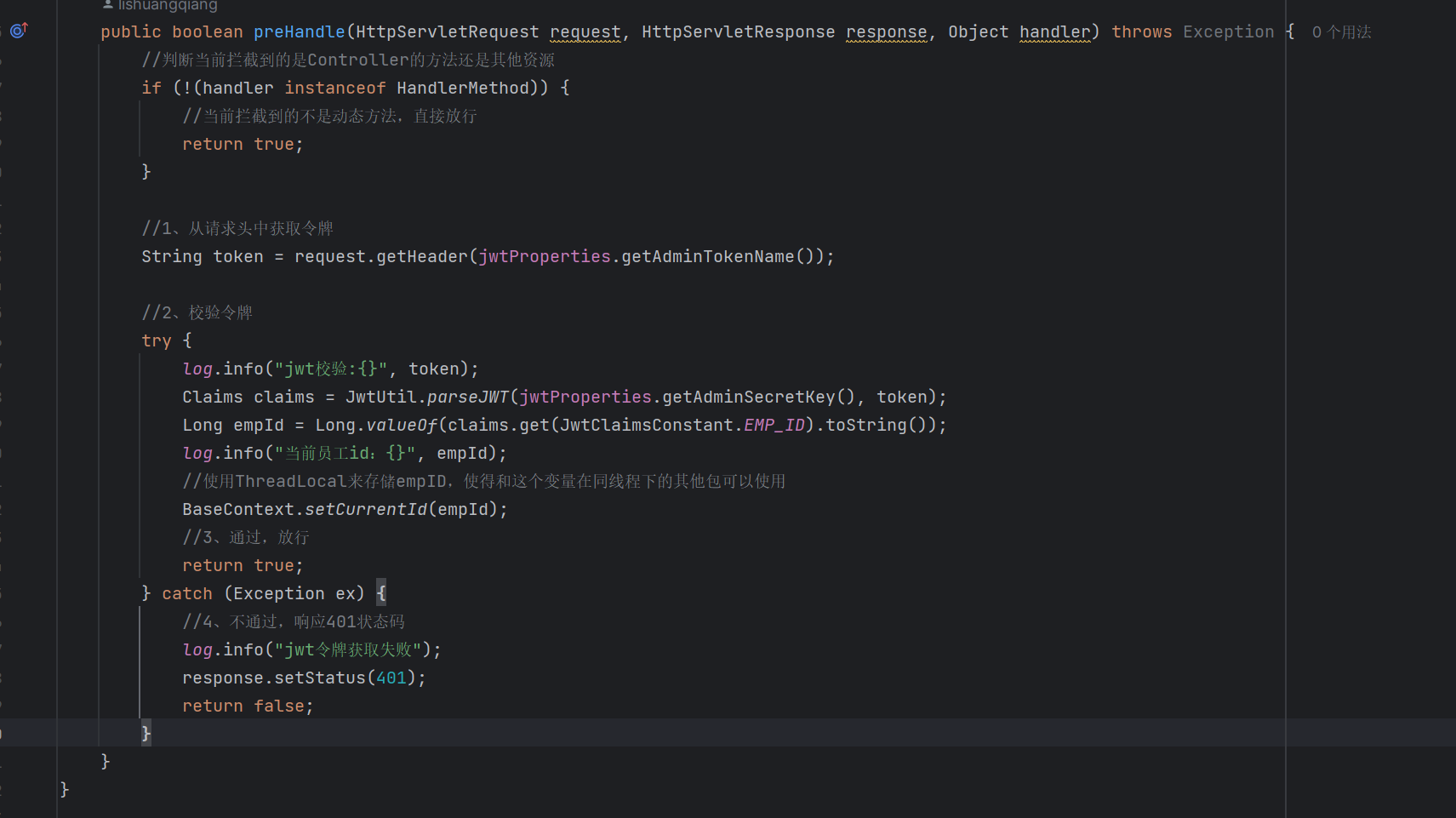
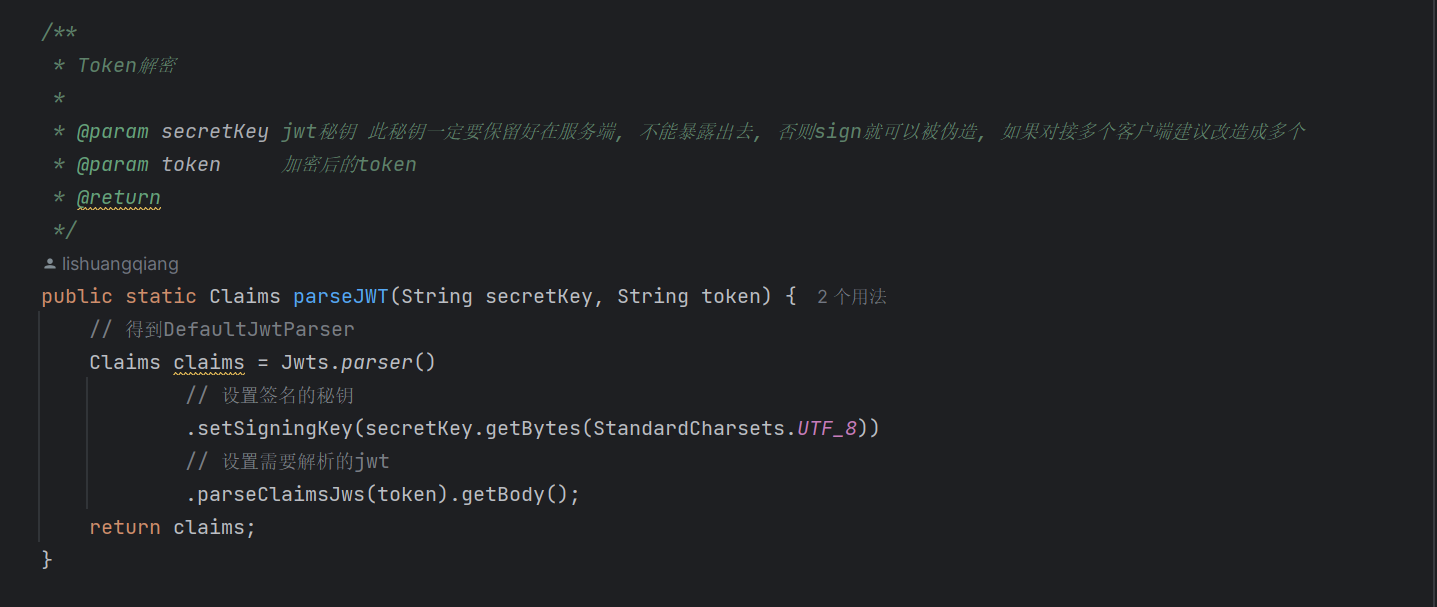
自定义JWT工具包内部 :
jwt加密:
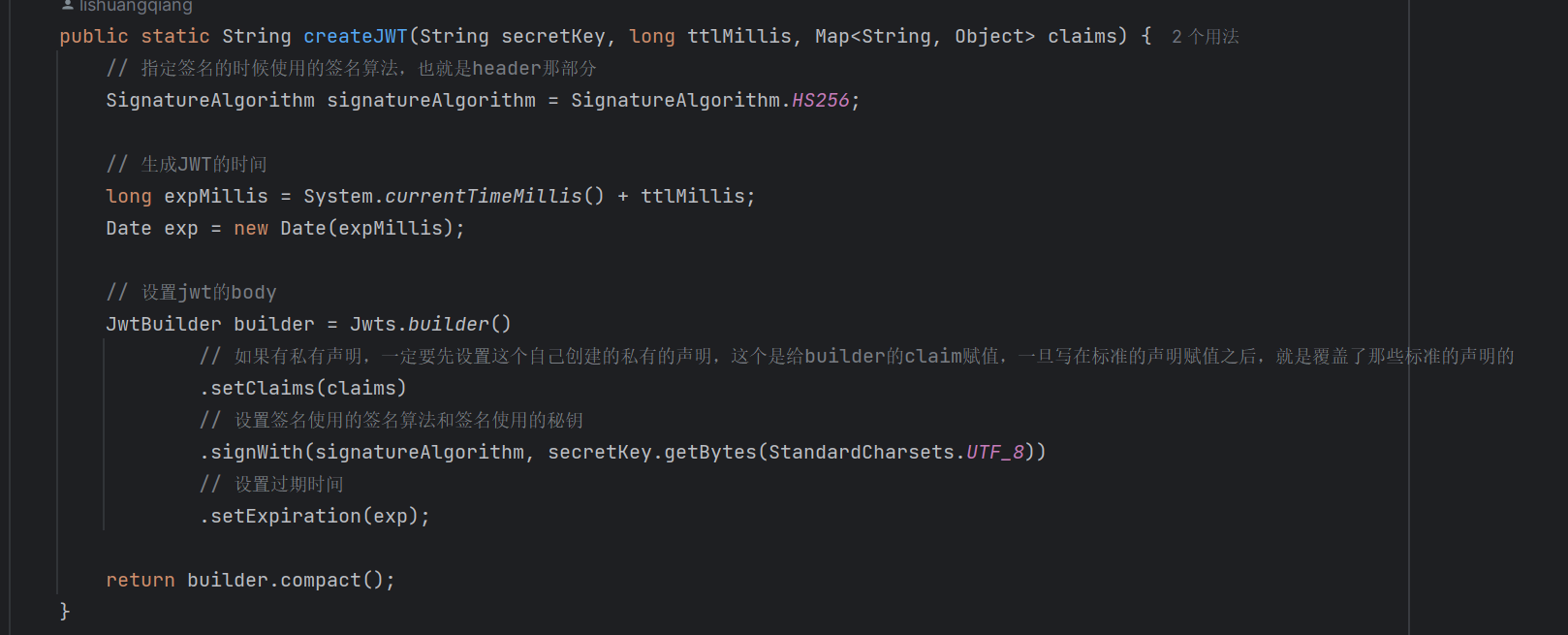
jwt解密:
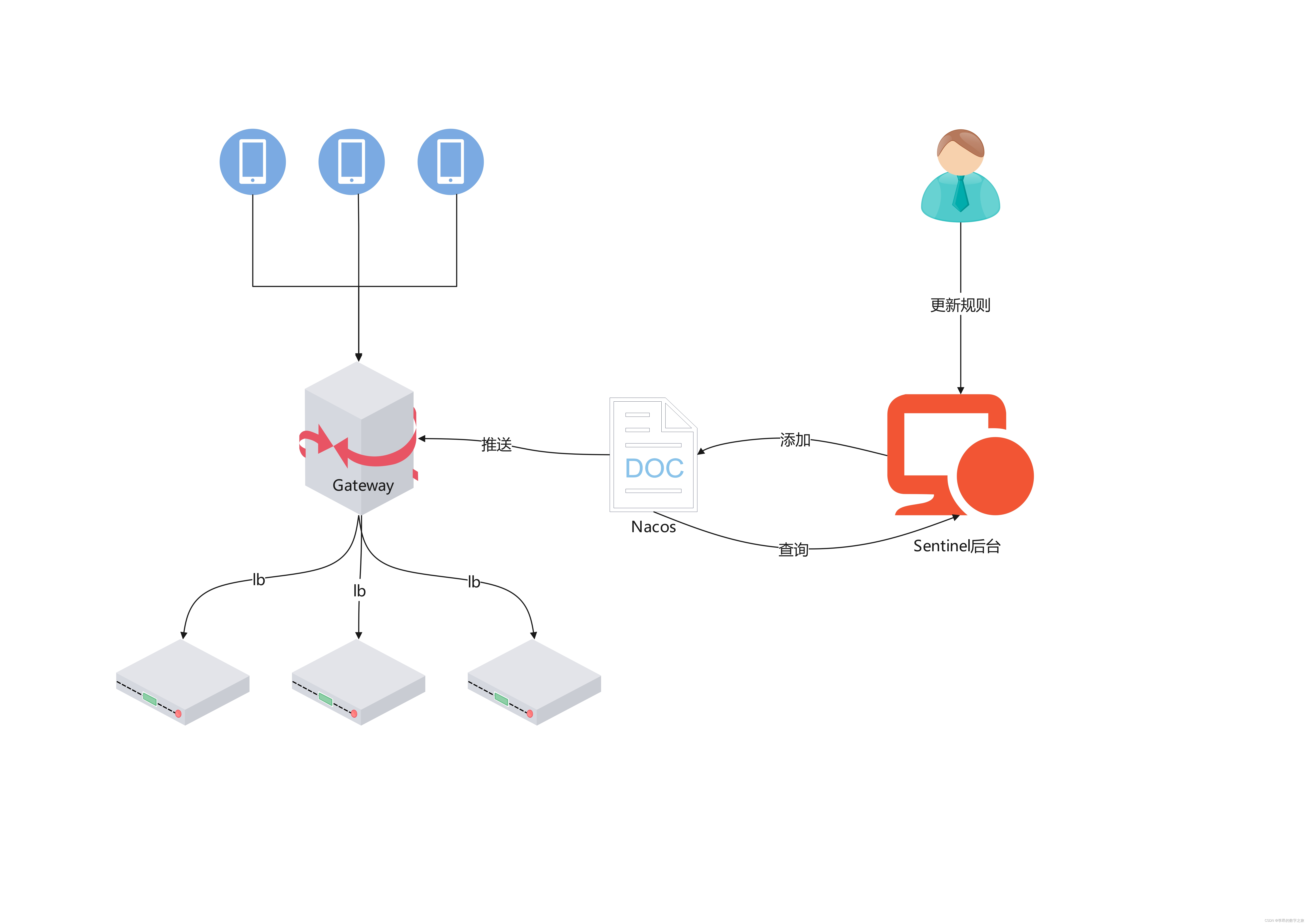
Nginx负载均衡和反向代理
负载均衡:
Nginx 的负载均衡功能允许将请求分发给多个应用服务器,以均衡负载和提高系统的可扩展性和可靠性。下面是一些常用的 Nginx 负载均衡配置方法:
-
轮询(Round Robin):这是默认的负载均衡策略。Nginx 将请求依次分发给每个后端服务器,确保每个服务器都能获得相同的请求数量。
-
IP 哈希(IP Hash):Nginx 使用客户端 IP 地址的哈希值来决定将请求发送给哪个后端服务器。这种方式可以确保同一客户端的请求始终发送到同一个后端服务器,适用于某些需要会话保持的场景。
-
加权轮询(Weighted Round Robin):可以为每个后端服务器设置权重,高权重的服务器将获得更多的请求。这种方式可以根据服务器的性能和处理能力来分配负载。
-
最少连接(Least Connections):Nginx 根据当前连接数来选择最空闲的后端服务器,将请求发送给它。这样可以确保负载更均衡,避免某些服务器过载。
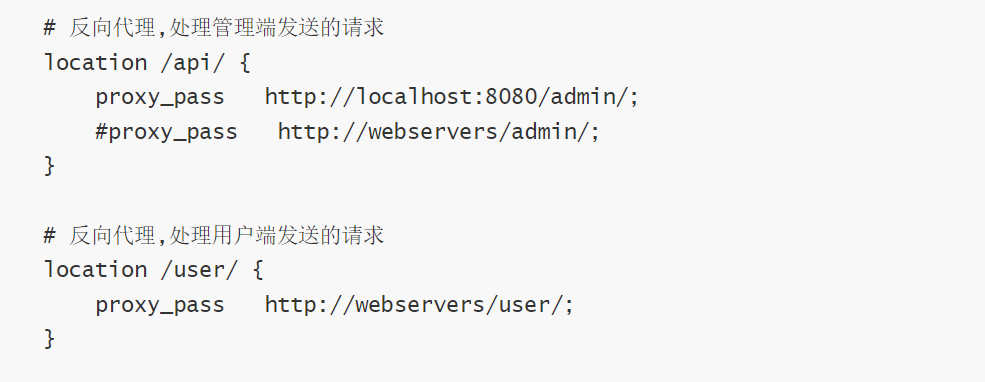
我们打开Nginx的conf配置文件就可以看见:

通过这个Nginx就可以把请求分发给指定的多台服务器,并且我们也设置了权重。不过因为本次演示的是单机项目,我们只有一台电脑,因此我们把第二个地址注释了起来。
反向代理:
有反向代理就有正向代理,而二者的区别很明显:反向代理隐藏服务器,正向代理隐藏客户端
- 正向代理是客户端发送请求后通过代理服务器访问目标服务器,代理服务器代表客户端发送请求并将响应返回给客户端。正向代理隐藏了客户端的真实身份和位置信息,为客户端提供代理访问互联网的功能。
- 反向代理是位于目标服务器和客户端之间的代理服务器,它代表服务器接收客户端的请求并将请求转发到真正的目标服务器上,并将得到的响应返回给客户端。反向代理隐藏了服务器的真实身份和位置信息,客户端只知道与反向代理进行通信,而不知道真正的服务器。
反向代理可以缓存后端响应,使得相同的请求不需要再次发送到服务器,有效降低了服务器的访问压力。
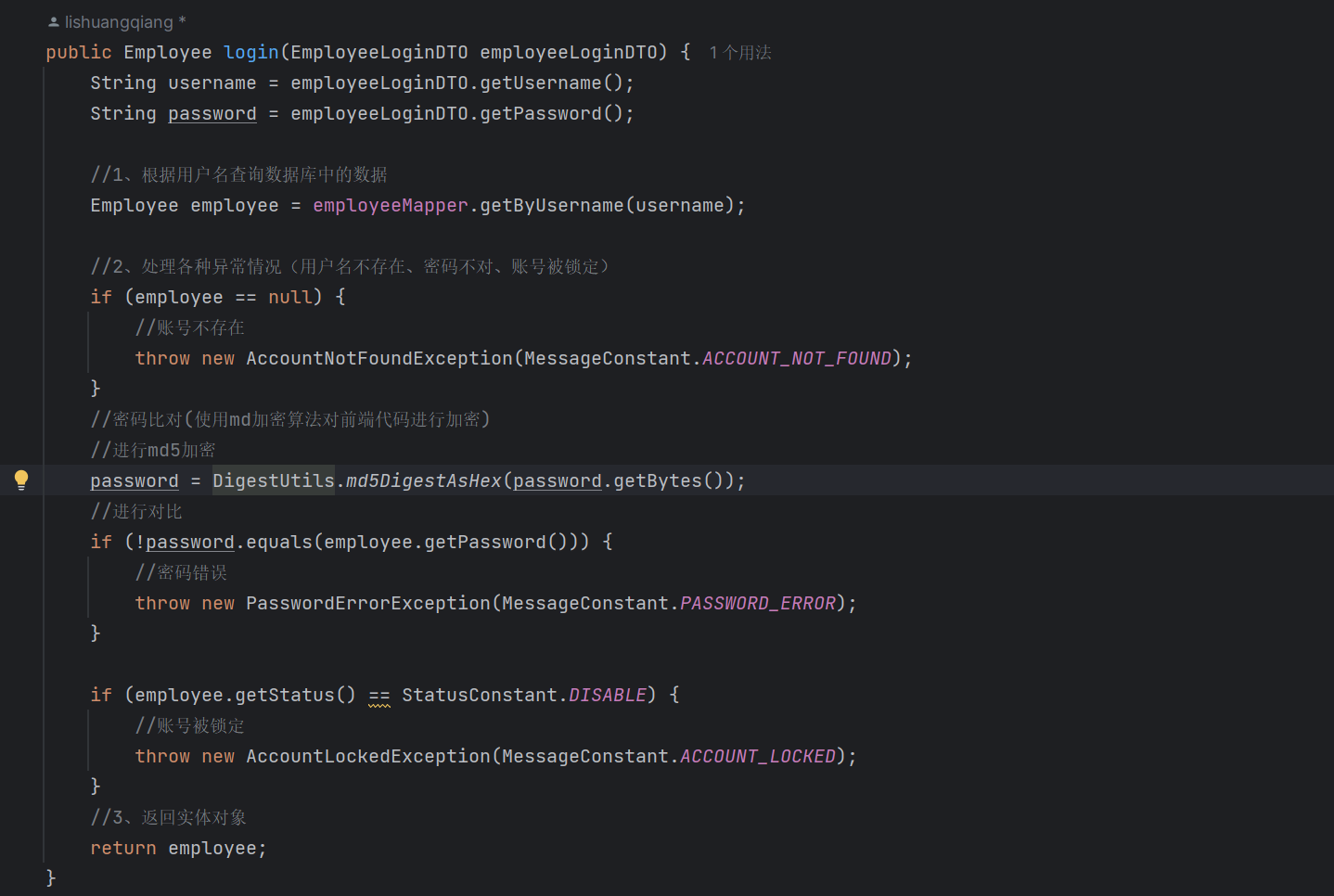
MD5加密登录:
为了防止数据库泄露带来的用户账号密码安全性问题,我们即使是在数据库中也不会进行明文存储密码,而是存储MD5加密方法加密后的一串字符串。
MD5在线加密/解密/破解—MD5在线 (sojson.com)
需要注意的是MD5加密属于不可逆性,用户无法通过某种算法来解密MD5加密后所得到的字符串来获取原始密码,这也在一定程度上降低了数据库泄露所带来的风险。
而基于MD5的特性,我们在验证用户密码是否正确的时候,思路是:把用户输入的密码与正确密码加密后得到的MD5字符串进行比较,如果相同则说明得到的是正确的密码。
现在很多的网站也提供了MD5的解密,但并不是说MD5的加密已经变的可逆了,而是他们提前存储了大量字符串经过MD5加密后的结果。他们的解密实际上就是按照结果找原字符串,而不是真正解密。
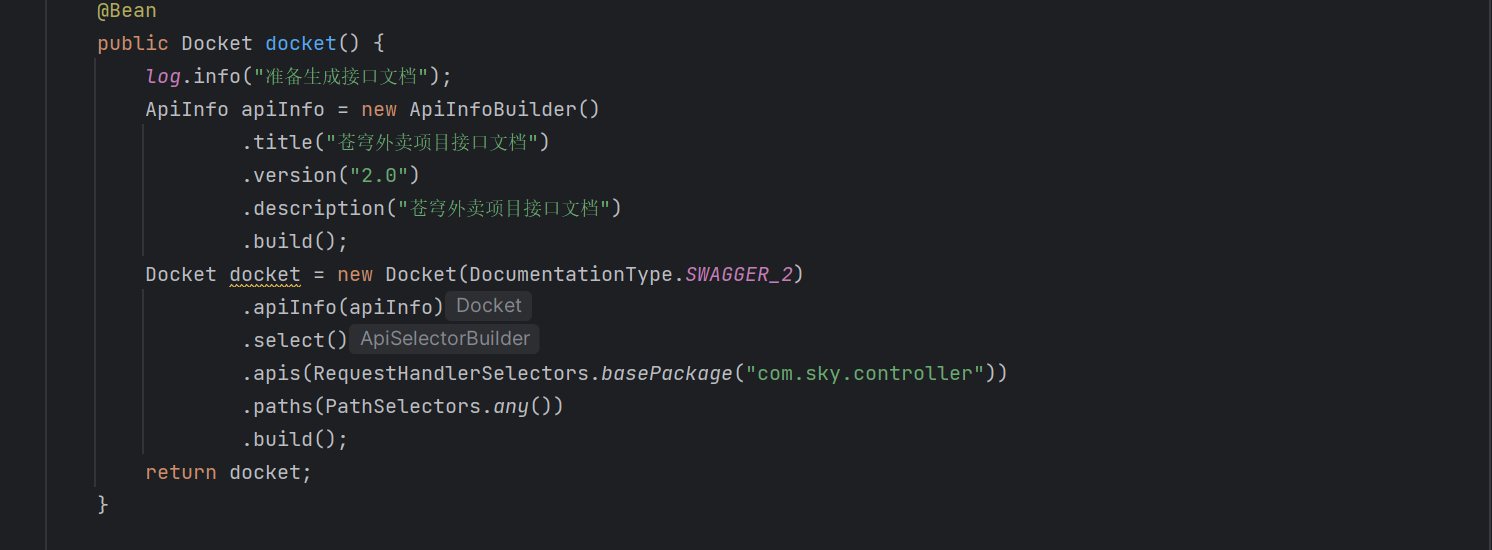
使用基于Swagger的Knife4j注解
Knife4j是Swagger的一个增强工具,是基于Swagger构建的一款功能强大的文档工具。它提供了一系列注解,用于增强对API文档的描述和可视化展示。
以下是一些常用的Knife4j注解介绍:
-
@Api:用于对Controller类进行说明和描述,可以指定Controller的名称、描述、标签等信息。 -
@ApiOperation:用于对Controller中的方法进行说明和描述,可以指定方法的名称、描述、请求方法(GET、POST等)等信息。 -
@ApiImplicitParam:用于对方法的参数进行说明和描述,可以指定参数的名称、描述、数据类型、是否必须等信息。 -
@ApiModel:用于对请求或响应的数据模型进行说明和描述,可以指定模型的名称、描述、属性等信息。 -
@ApiModelProperty:用于对模型的属性进行说明和描述,可以指定属性的名称、描述、数据类型、示例值等信息。 -
@ApiParam:用于对方法的参数进行说明和描述,可以指定参数的名称、描述、数据类型、是否必须等信息。
这些注解可以在Spring Boot项目中与Swagger集成使用,通过使用这些注解,可以在生成的API文档中提供更详尽的说明和描述。同时,Knife4j还提供了一些自定义配置。
项目中在webMvcConfiguration配置Knife4j:
再设置静态资源映射:
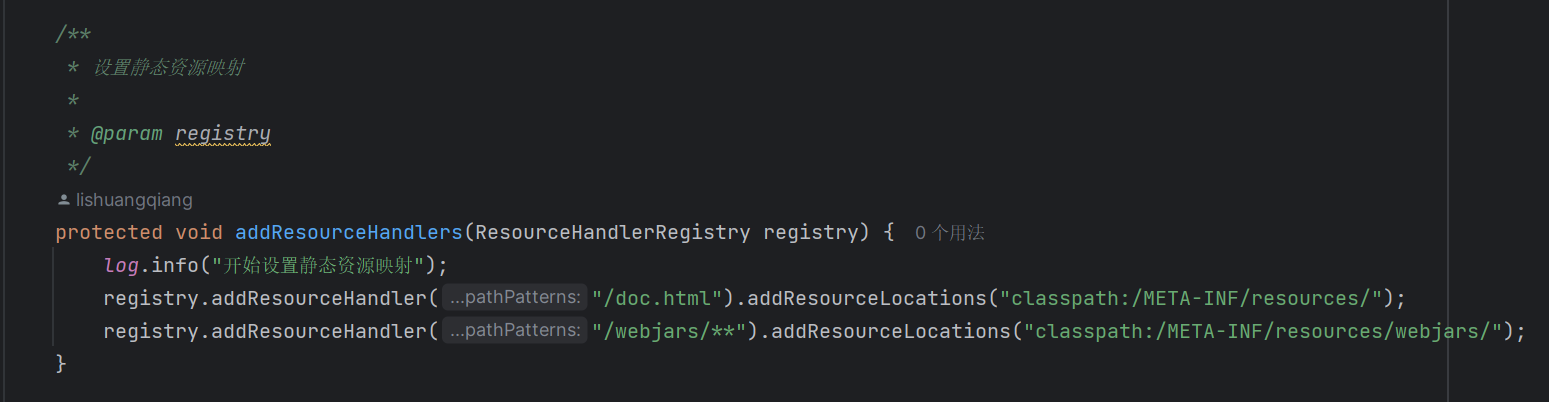
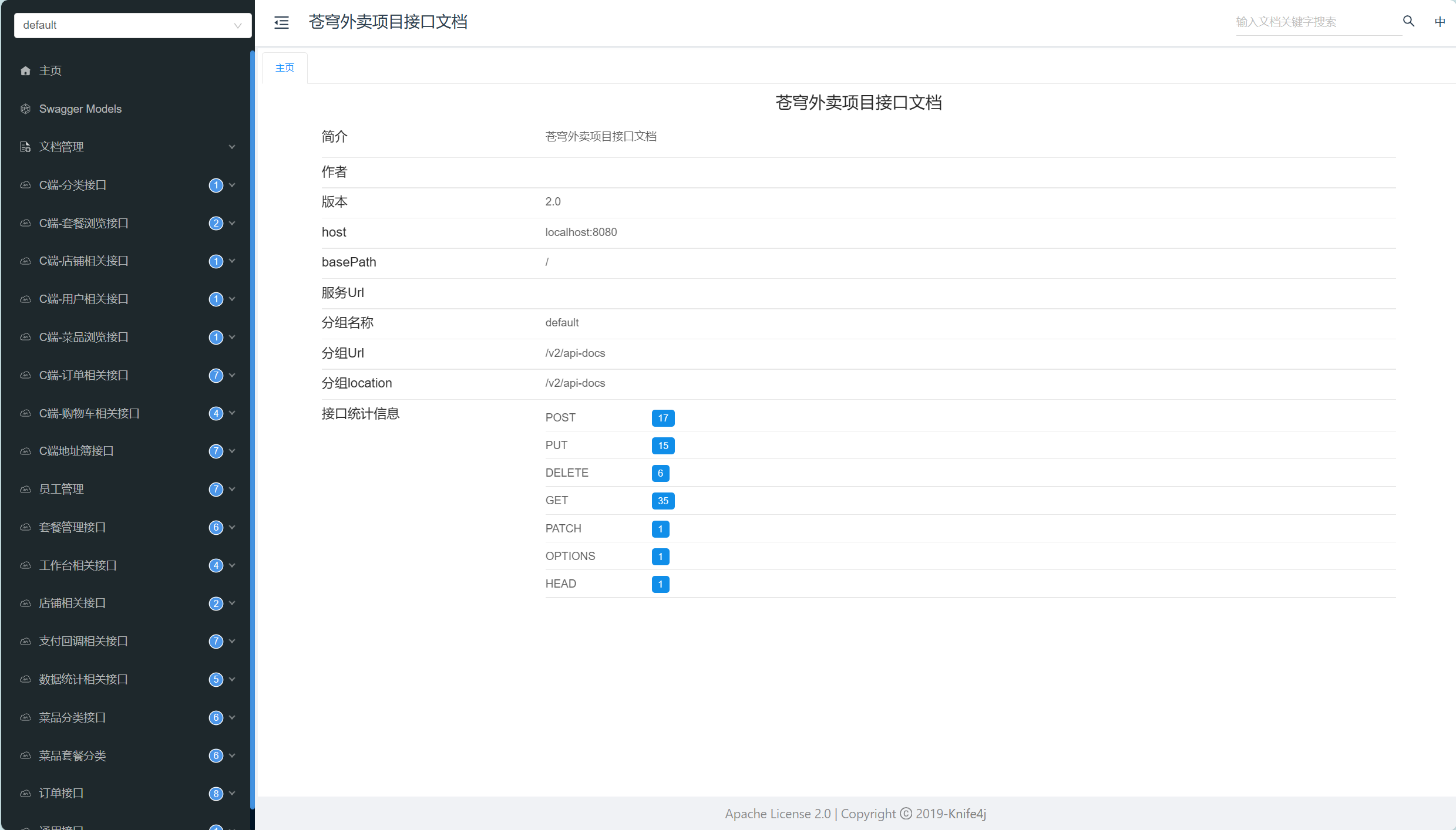
在配置完成之后,我们只要启动项目,就可以看到 Tomcat为我们开放的端口为8080:

那么我们只需要访问:
http://localhost:8080/doc.html#/home![]() http://localhost:8080/doc.html#/home
http://localhost:8080/doc.html#/home
就可以访问到对应的接口文档。
项目第二阶段技术:
ThreadLocal:
ThreadLocal是Java中的一个线程本地变量,它可以为每个线程提供一个独立的变量副本。线程本地变量意味着每个线程都拥有自己的变量副本,互不影响。
ThreadLocal的主要作用是在多线程环境下提供线程安全的变量访问。它常用于解决线程间数据共享的问题,特别是在并发编程中,当多个线程需要使用同一个变量时,可以使用ThreadLocal确保每个线程访问的都是自己的变量副本,从而避免了线程安全问题。
使用ThreadLocal的主要步骤如下:
- 创建ThreadLocal对象:可以通过
ThreadLocal的静态方法ThreadLocal.withInitial()来创建ThreadLocal对象,并初始化变量的初始值。 - 设置变量值:通过ThreadLocal对象的
set()方法可以设置当前线程的变量副本的值。 - 获取变量值:通过ThreadLocal对象的
get()方法可以获取当前线程的变量副本的值。 - 清除变量值:通过ThreadLocal对象的
remove()方法可以清除当前线程的变量副本的值,释放资源。
需要注意的是,ThreadLocal中存储的变量值只对当前线程可见,其他线程无法直接访问。这是由于ThreadLocal使用了线程间的隔离机制,每个线程都有自己的变量副本,互不干扰。但也因此需要注意合理使用ThreadLocal,避免对于内存的过度占用或泄露。
总结而言,ThreadLocal是Java中一种用于线程本地变量存储的机制,它提供了一种简单且线程安全的方式在多线程环境下共享变量。通过为每个线程提供独立的变量副本,ThreadLocal可以简化并发编程中的数据共享问题。
在本项目中,它的应用主要是在token解析的时候,存储这时员工的ID,方便后续其他包对员工ID的调用。
而我们把Thread的所有的方法都封装到了包中,放在了Context类下:
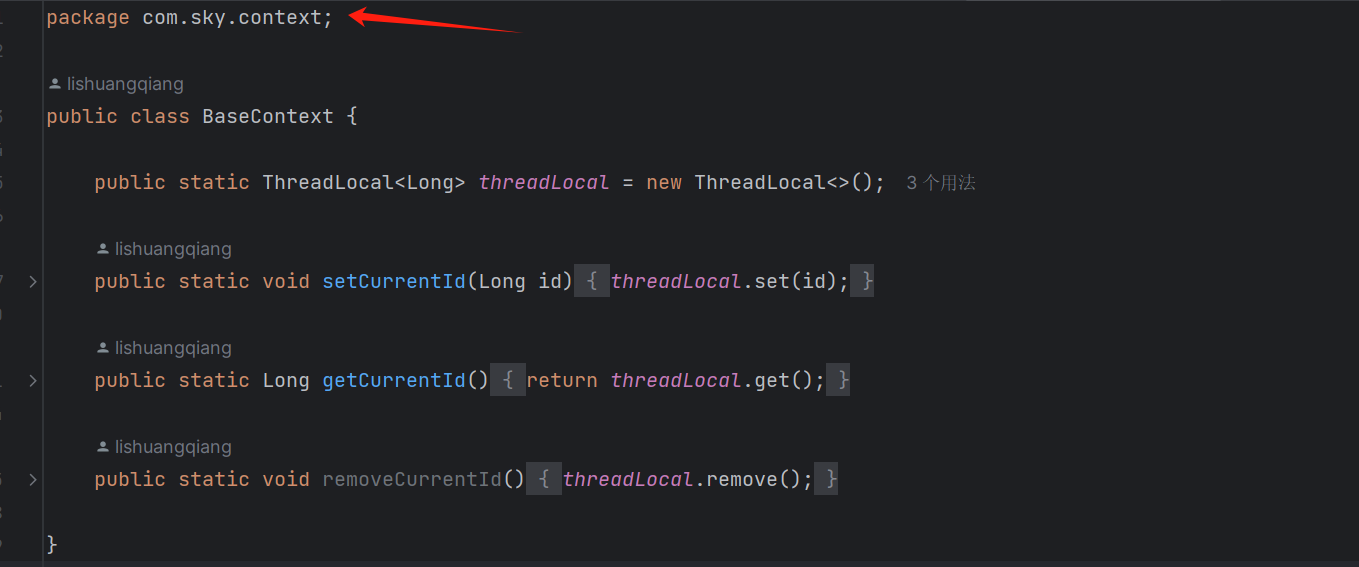
通过这个包,我们也可以更好的理解Context包的作用:存放可以操作和访问程序上下文的各种包和接口。
我们看一下在代码中我们是怎么实现的:
1.在拦截器拦截到请求并且下发令牌的时候,就利用ThreadLocal拿到当前登录员工的ID
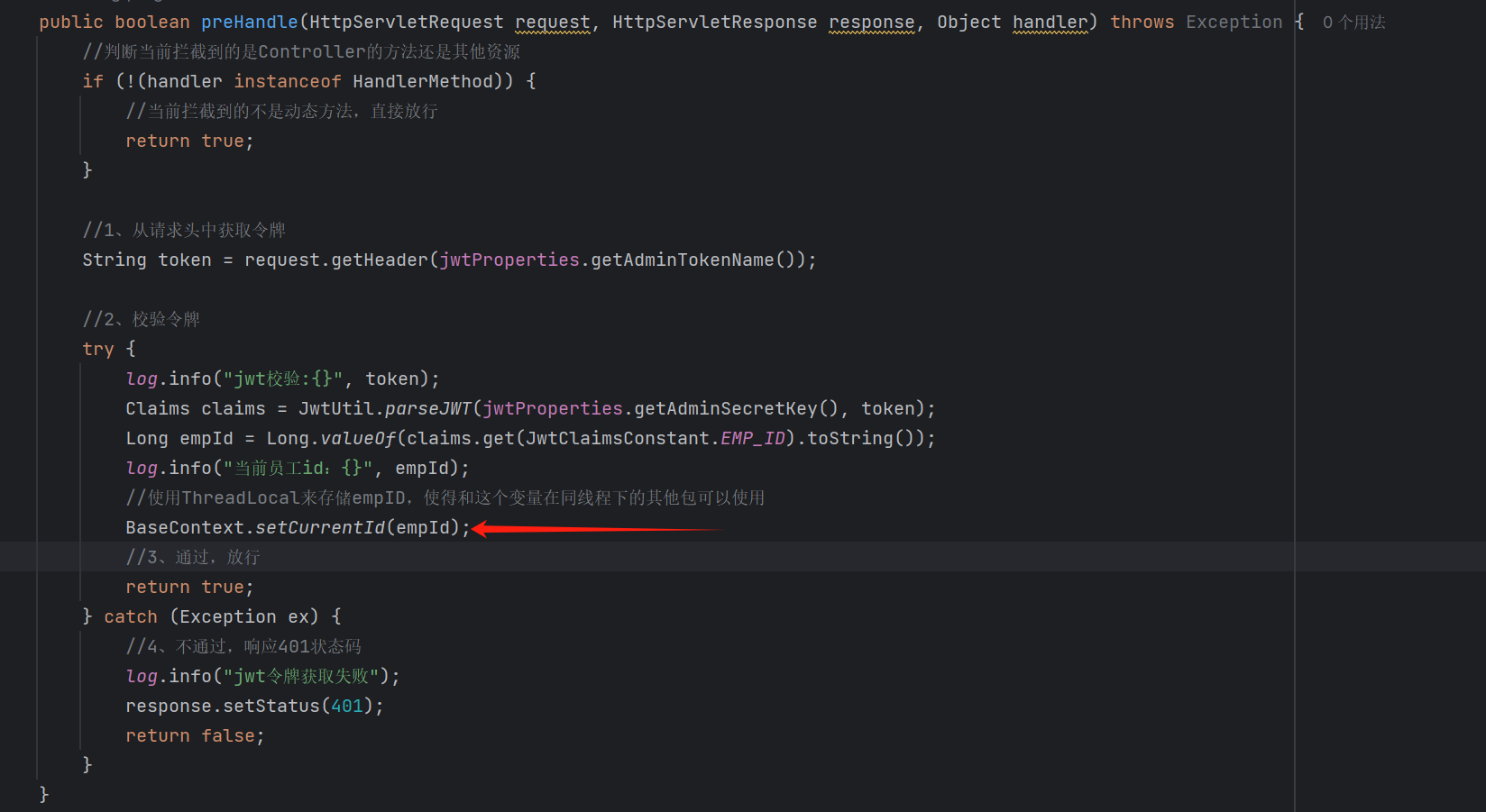
2.在需要使用的时候调用context包的接口

在这里我们就用到了封装了ThreadLocal的工具包BaseContext来拿当前登录的员工ID,这里被注释掉是因为我们在后面的业务中对这种填充字段方法进行了统一处理,因此被注释掉了。
基于消息转换器对时间进行格式化:
我们无法控制前端给我们传递过来的时间参数的格式,因此我们要对前端传递过来的时间参数进行格式化。
而进行格式化,如果时间参数少,我们可以使用 @JsonFormat(pattern="yyyy-MM-dd HH:mm:ss")来对某个属性指定格式:

但是如果时间参数过多,我们再一个一个标注就太麻烦了。因此我们选择在Spirng MVC中再扩展一个消息转换器,统一对前端的发送给后端的时间数据进行处理:
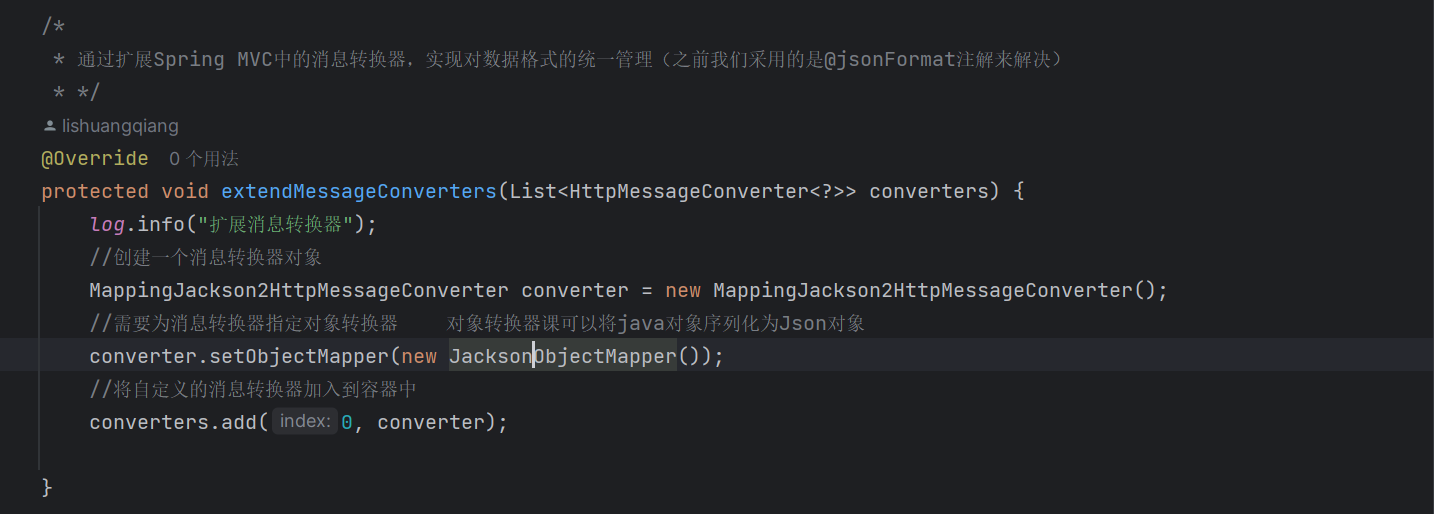
首先我们先来介绍一下什么是消息转换器:
消息转换器在Spring MVC中负责处理请求和响应的数据格式转换,例如将Java对象转换为JSON格式或者把JSON格式转换为Java。
我们先创建一个用来处理Json格式的消息转换器,之后我们再为这个消息转换器指定自定义的对象转换器(JacksonObjectMapper)。而这个对象转换器的作用是指定序列化和反序列化的格式。我们可以看一下指定的这个JacksonObjectMapper。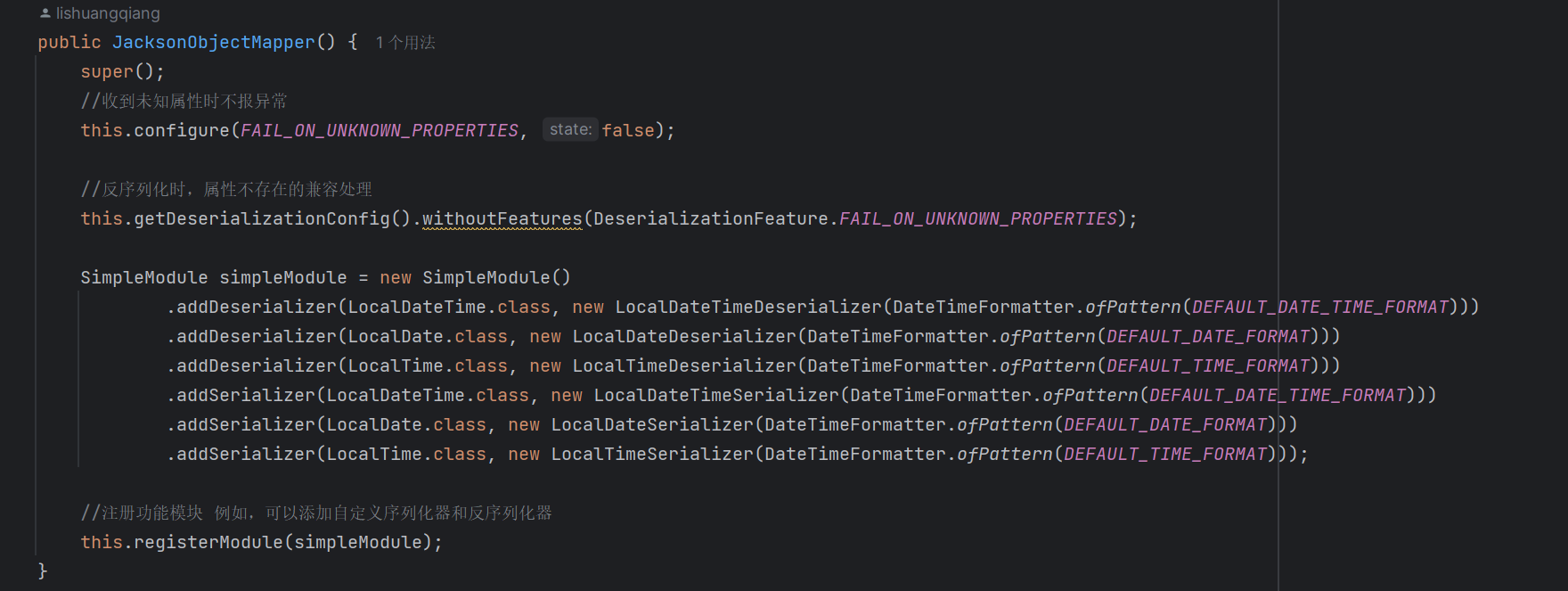
很明显,这个对象转换器为我们提供了标准的序列化和反序列化。
让我们回到原方法中,此时我们已经为消息转换器指定了一个对象转换器,可以按照我们的目的进行序列化和反序列化。
这个时候就到了最后一步:把自定义的消息转换器加入到容器中,而且是放到第一位。
这是因为我们的Spring MVC中有大量的消息转换器,而进行序列化和反序列化的时候,Spring MVC会依次用这些消息转换器去尝试,只要有一个尝试成功了,就不会在使用后面的消息转换器了。
而我们只有把我们自己定义的消息转换器放到第一位,才可以确保数据被正确的序列化和反序列化。
将JSON解析为Java对象的过程称为 [从JSON反序列化Java对象]
从Java对象生成JSON的过程称为 [序列化Java对象到JSON]
基于PageHelper的分页查询:
‘PageHelper是基于java的一个开源框架,用于在MyBatis等持久层框架中方便地进行分页查询操作。它提供了一组简单易用的API和拦截器机制,可以帮助开发者快速集成和使用分页功能。
PageHelper的主要功能包括:
- 分页查询支持:PageHelper提供了直接在SQL语句中添加分页相关的信息,如页码、每页记录数等,从而实现分页查询功能。
- 参数解析和设置:PageHelper可以解析传入的查询参数,并自动设置分页的相关参数,无需手动计算和设置。
- SQL拦截器:PageHelper通过自定义的SQL拦截器拦截和处理查询SQL,自动添加分页的SQL语句,实现分页查询。
- 排序支持:PageHelper还提供了对排序的支持,可以在分页查询中指定排序字段和排序方式。
- 分页信息返回:PageHelper会将查询结果封装在一个Page对象中,包含了分页的相关信息,如总记录数、总页数等。
PageHelper的底层原理是拦截,拦截需要进行分页查询的SQL请求,读取用户传入参数,自主构造分页SQL语句。
它的使用很便利,大大简化了分页查询的操作步骤,因此在企业开发中也比较常见,作为一名合格的开发者,我们要熟练的掌握基于PageHelper的分页查询操作。
首先先要在pom文件中引入PageHelper的maven坐标:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
</dependency>1.Controller层:
这一层没有什么好说的,因为他是最外层,不进行业务代码的编写,仅仅调用service层的代码。
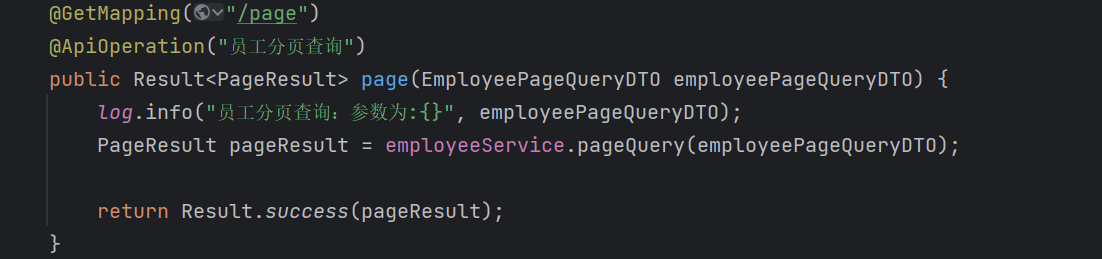
2.Server层:
先调用PageHelper的stratPage函数,传递要查询的页码以及每一页的数据条数
再调用pageQuery方法进行实际的分页查询操作。这里的employeeMapper是对应的Mybatis Mapper接口,pageQuery()方法是其中定义的一个查询方法,用于执行分页查询操作。
然后,通过page.getTotal方法获取查询结果的总数,即满足条件的数据总条数。
通过 方法获取当前页的数据列表,即符合分页条件的数据集合。
最后,将总数和当前页的数据列表封装成一个PageResult对象,并返回给调用方。

3.Mapper层:
mapper层是动态SQL,因此把SQL语句写到XML文件里面
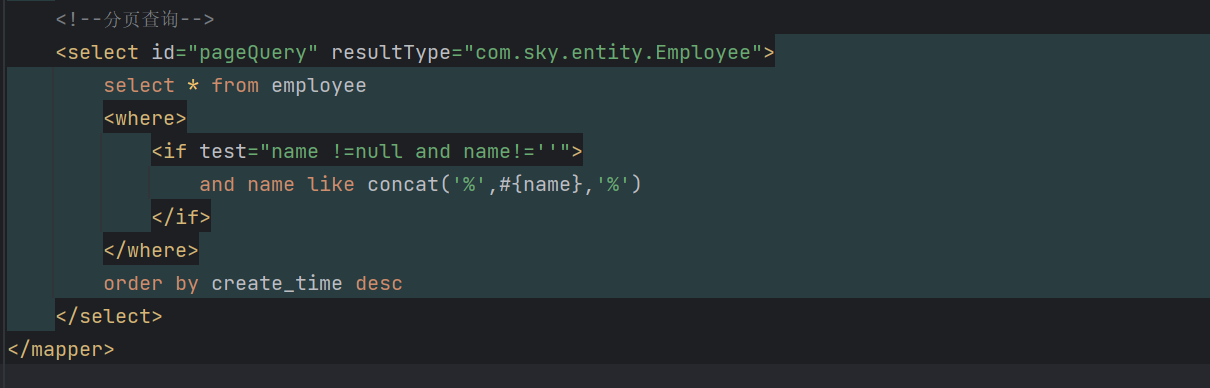
我们可以看到,PageHelper可以自动帮我们进行分页操作,大大简化了我们的代码量,是一个很不错的插件。
基于注解和AOP的公共字段填充:
在我们项目前期,会发现一个问题:我们的项目开发会涉及大量的数据表,而这些数据表中有一些重叠的字段,例如创建人,创建时间,修改人,修改时间。对这一部分字段的填充代码相同。这些填充部分的代码分布在整个项目的四处,不涉及核心功能,却影响了多个模块
而这不就是我们的AOP思想所专注于解决的问题。这里我们不再对AOP进行详细介绍,下面的链接是我以前的一篇AOP文章,如果不了解AOP的同学可以点击进去看看。
【Spring知识点介绍 | 第二篇】什么是AOP_我是一盘牛肉的博客-CSDN博客
聚焦到项目:我们的整体思路为:通过注解的方式标记方法,利用AOP思想创建一个切面,在切面中实现对标记方式中字段的填充,然后再运行原方法。这样就实现了在不改动原方法的前提下,实现了对代码的优化升级。
让我们基于整个项目了解一下基于AOP思想的注解开发:
首先先创建一个注解: AutoFill
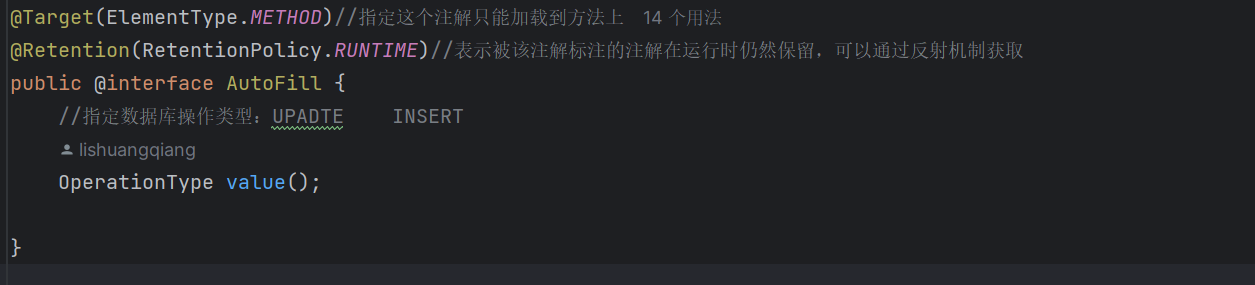
而这个注解的作用很明显:使用在mapper层,标记对数据库的操作类型。这里是因为公共字段的填充只有修改和新增这两个类业务。我们需要准确的拦截这两个数据库层面的操作,在切面中完成对公共字段的填充。
其次完成切面的代码:
先通过切入点表达式,拦截到带有AutoFill的注解,之后再写通知,本次我们采用的是前置通知。
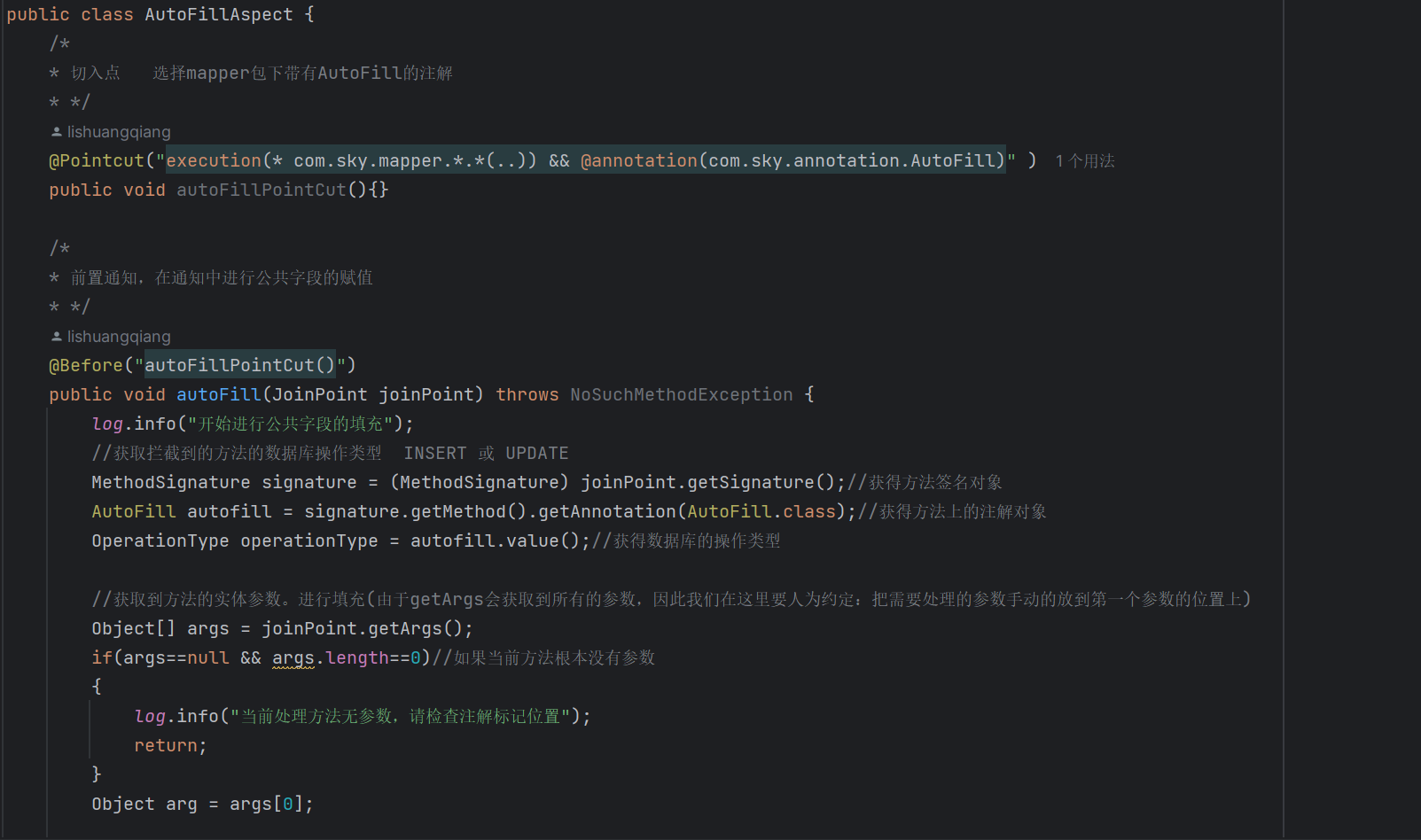
在上文我们已经拿到了目标方法的第一个参数(我们人为约定把需要填充的字段放在第一个字段上,主要是为了简化操作,不然我们就需要通过反射拿到所有的参数,再逐个判断哪一个是需要进进行填充的字段)
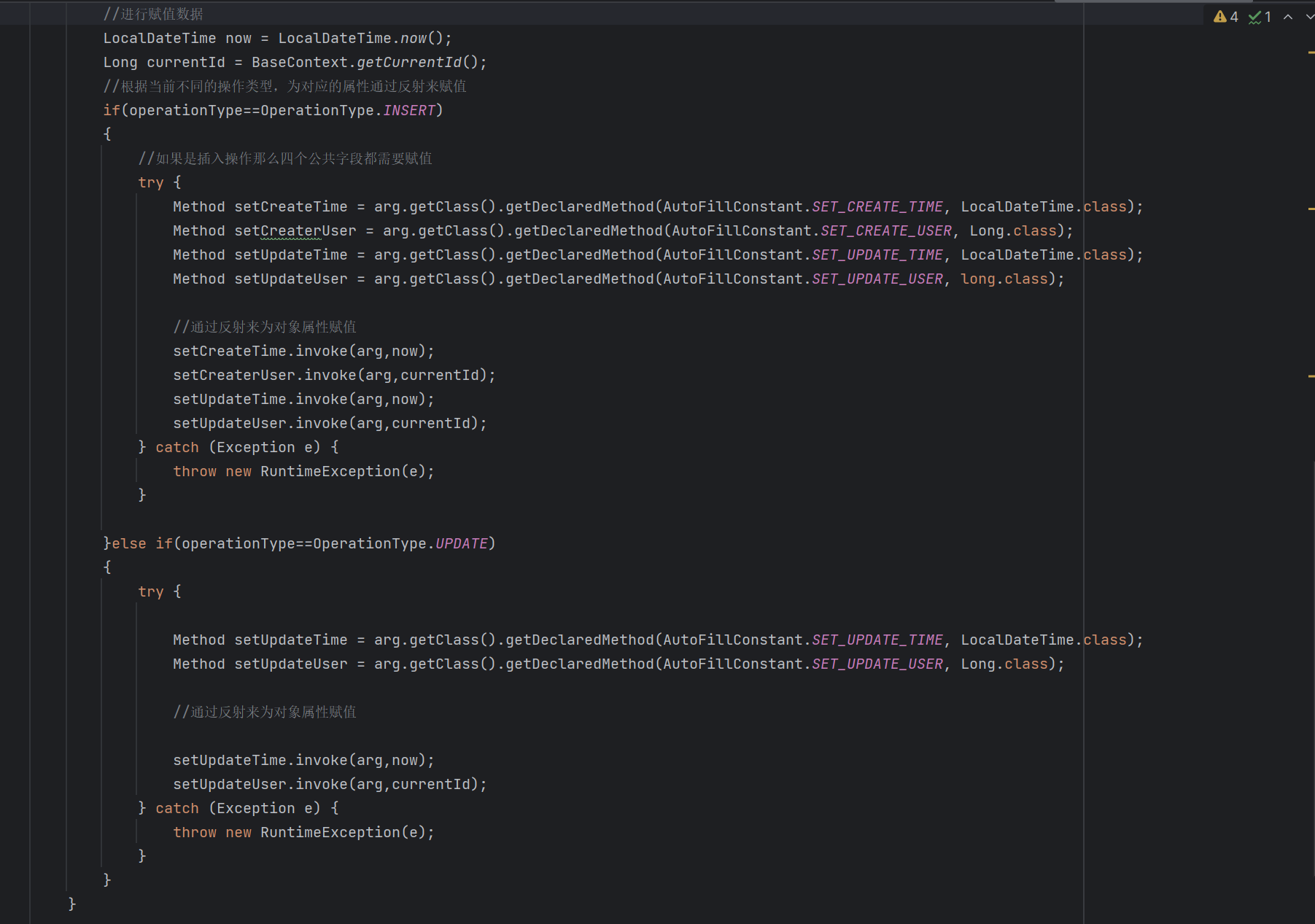
通过反射的思想进行字段赋值。
这样下来,我们就实现了公共字段的自动填充,我们回顾整个代码逻辑,可以把整个过程总结为两步
- 自定义注解(标记类型),通过注解快速标记目标方法
- 完成切面的逻辑代码,通过切入点表达式快速捕捉需要进行切入的方法,对这些方法进行处理
阿里云OSS云存储服务:
这是阿里巴巴为我们提供了一项云存储服务。我们通过这项技术来存储菜品,套餐,员工的图片。之所以不存到本地,这是因为前端无法回调服务器的本地图片,这也就造成我们只能存图片,无法回显图片的BUG,而我们如果调用阿里云的云存储服务,照片存储到阿里巴巴的云之后,会返送一个URL,我们通过这段URL就可以回调图片。
这块业务的代码可以不停的复用,因此我直接贴代码,就不贴图片了,方便我后面项目使用的时候cv
步骤为:先配置阿里云的各项配置
# application-dev.yml

#application.yml

#sky-common
@Component
@ConfigurationProperties(prefix = "sky.alioss")
@Data
public class AliOssProperties {
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
}
这段代码的意思是读取阿里云OSS的配置,这意味着当Spring Boot启动时,它会自动将以"sky.alioss"为前缀的配置项绑定到AliOssProperties对象中。
此时我们再来创建工具类对象:
#sky-common-utils
@Data
@AllArgsConstructor
@Slf4j
public class AliOssUtil {
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
/**
* 文件上传
*
* @param bytes
* @param objectName
* @return
*/
public String upload(byte[] bytes, String objectName) {
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
try {
// 创建PutObject请求。
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(bytes));
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
//文件访问路径规则 https://BucketName.Endpoint/ObjectName
StringBuilder stringBuilder = new StringBuilder("https://");
stringBuilder
.append(bucketName)
.append(".")
.append(endpoint)
.append("/")
.append(objectName);
log.info("文件上传到:{}", stringBuilder.toString());
return stringBuilder.toString();
}
}
此时我们就也有了阿里云OSS这个工具类。而需要注意的是OSS服务于整个server层,不独属于某一个方法或者类。因此我们应该把创建阿里云OSS的代码放到server的配置类中,也就是说全局只需要有server一个类。
#sky-server-config
/*
* 配置类:用来创建AliOssutil对象
* */
@Configuration//该注解表明下面的方法是一个配置类
@Slf4j
public class OssConfiguration {
@Bean
@ConditionalOnMissingBean//加上这个注解后,整个spring框架中就始终只会有一个aliOssUtil对象
public AliOssUtil aliOssUtil(AliOssProperties aliOssProperties) {
log.info("开始创建阿里云文件上传工具类对象{}",aliOssProperties);
return new AliOssUtil(aliOssProperties.getEndpoint(),
aliOssProperties.getAccessKeyId(),
aliOssProperties.getAccessKeySecret(),
aliOssProperties.getBucketName());
}
}
我们最后再来看看如何调用阿里云OSS这个工具类:
@RestController
@RequestMapping("/admin/common")
@Slf4j
@Api(tags = "通用接口")
public class CommonController {
@Autowired
private AliOssUtil aliOssUtil;
@ApiOperation("文件上传")
@PostMapping("/upload")
public Result<String> upload(MultipartFile file)//此处的参数名称要和前端的body中传递的参数名称一致
{
log.info("文件上传:{}", file);
//在这里的名字我们使用UUID生成,避免因为重名产生图片文件覆盖问题
try {
//获取原始文件名
String originalFilename = file.getOriginalFilename();
//截取原始文件名的后缀
String extensionobje= originalFilename.substring(originalFilename.lastIndexOf("."));
//利用UUID生成文件名
String objectName = UUID.randomUUID().toString() + extensionobje;
//返回一个指向文件的URL
String filePath = aliOssUtil.upload(file.getBytes(), objectName);
return Result.success(filePath);
} catch (IOException e) {
log.info("文件上传失败:{}",e);
}
return Result.error(MessageConstant.UPLOAD_FAILED);
}
}
这样我们就实现了阿里云OSS的云存储服务。
而在云存储服务中,还有两个小知识点:
1.使用UUID生成文件名
我们需要使用UUID来为上传到阿里云OSS的图片命名。而阿里云图片命名不允许重复,否则就会覆盖。因此我们使用UUID来生成一串随机数,这样就确保了文件不被新文件覆盖。
2.不要把配置类写死
在阿里云配置中我们可以最直观的看到,我们并不是直接把配置写到application.yml 而是在application-dev.yml 写具体配置,在application.yml中应用application-dev.yml的配置。这是因为一个大型项目落地的时候,需要经过很多的环境:开发环节-测试环境-生产环境。而这三个环境可能并不会通用一套数据库,oss等配置类,如果我们直接把配置写到application.yml中,那在切换环境的时候,就要在代码中逐个修改,这对于大型项目的体量而言,无疑是灾难性的。而我们在开发环境采用application-dev.yml 的配置,在测试环境采用application-tex.yml的配置,以此类比。这样是一种很好的开发习惯。我们在自己的练手项目中也应该这样写。
对方法开启事务:
随着业务操作的增加,对任何一张表的修改可能对会影响到其他的表,例如我们在插入dish中的菜品的时候,也应该一并插入dish_flavor中该菜品的对应的口味。
而这两张表的数据的插入,应该是确保都完成的,不可以出现只插入了菜品或者只插入了口味的情况。因此我们要把对这两张表的操作设置为一个事务。
而使用方式也非常简单:
1.在启动类上方添加@EnableTransactionManagement

开启事务注解之后,我们只需要在需要捆绑成为一个事务的方法上添加@Transactional
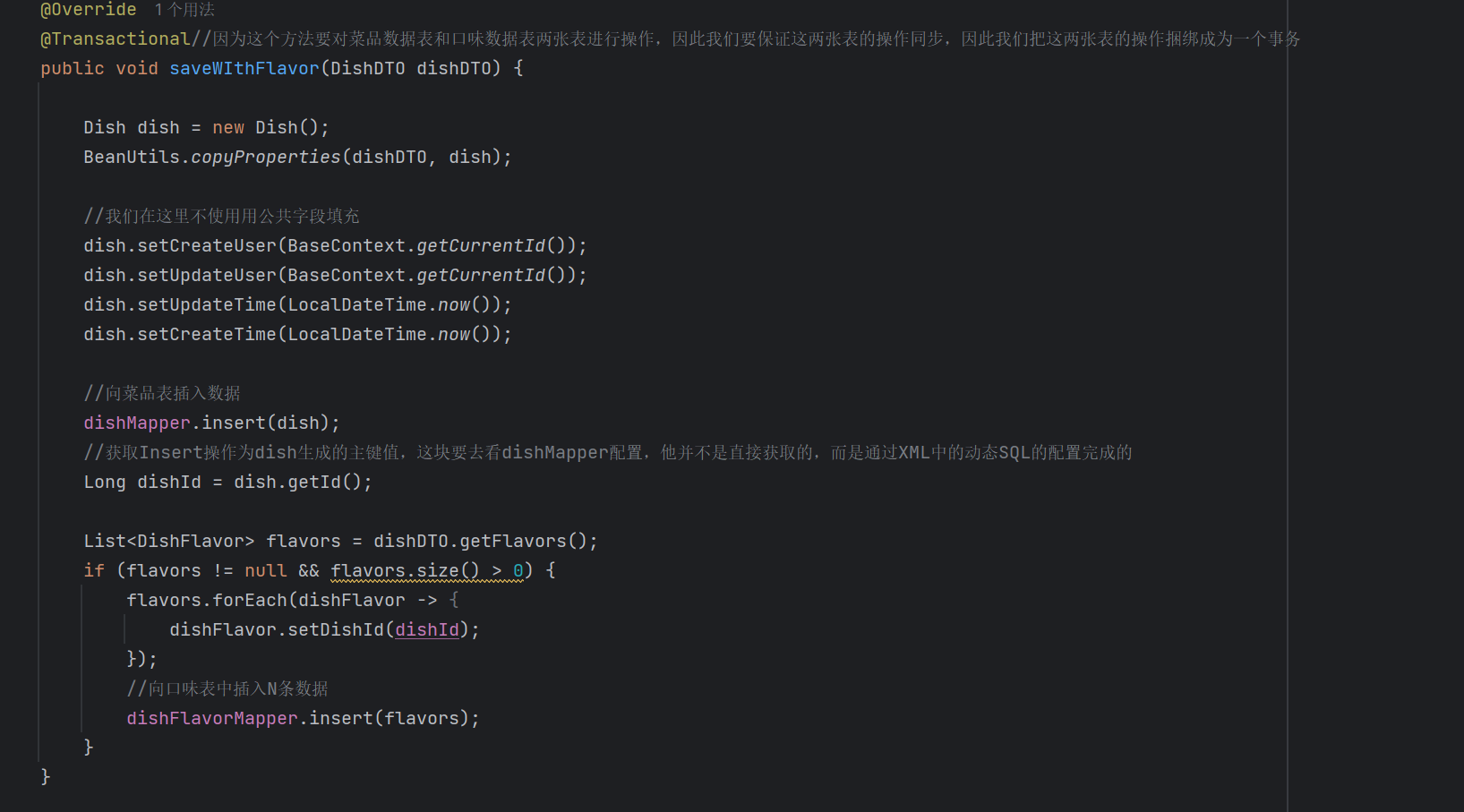 这样就把对两张表的操作捆绑成为了一个事务。
这样就把对两张表的操作捆绑成为了一个事务。
最后再介绍一些@Transactional 的常见属性
value:可以用于指定事务管理器的名称或ID,用来管理当前方法的事务。例如:@Transactional(value = "transactionManager")。readOnly:用于指定事务是否是只读的。如果将readOnly设置为true,则事务只能进行读操作,而不能进行写操作。默认值为false。timeout:用于指定事务的超时时间,单位为秒。在指定的时间内,如果事务还未提交或回滚,则事务将被强制回滚。isolation:用于指定事务的隔离级别。常见的隔离级别包括DEFAULT、READ_UNCOMMITTED、READ_COMMITTED、REPEATABLE_READ和SERIALIZABLE。propagation:用于指定事务的传播行为。常见的传播行为包括REQUIRED、REQUIRES_NEW、SUPPORTS、NOT_SUPPORTED、NEVER和MANDATORY。rollbackFor:用于指定需要回滚事务的异常类型数组。当方法抛出指定的异常时,事务将被回滚。noRollbackFor:用于指定不需要回滚事务的异常类型数组。当方法抛出指定的异常时,事务将不会被回滚。
隔离级别(Isolation Level)指的是在并发环境下,对于事务之间的数据访问与修改的隔离程度。常见的隔离级别包括:
DEFAULT:使用数据库默认的隔离级别。READ_UNCOMMITTED:最低的隔离级别,允许读取未提交的数据(脏读),可能导致数据不一致。READ_COMMITTED:要求一个事务只能读取其他已提交的数据,避免了脏读,但可能存在不可重复读和幻读的问题。REPEATABLE_READ:要求一个事务读取的数据集合在事务执行期间保持一致,避免了脏读和不可重复读,但可能存在幻读的问题。SERIALIZABLE:最高的隔离级别,要求读取数据时对其加锁,避免了脏读、不可重复读和幻读,但可能导致并发性能下降。传播行为(Propagation)指的是事务在不同方法间进行传播的行为。常见的传播行为包括:
REQUIRED:如果当前存在事务,则加入到当前事务中,如果没有事务,则创建一个新的事务。REQUIRES_NEW:无论当前是否存在事务,都创建一个新的事务,并挂起当前事务。SUPPORTS:如果当前存在事务,则加入到当前事务中,如果没有事务,则以非事务的方式执行。NOT_SUPPORTED:以非事务的方式执行,如果当前存在事务,则挂起该事务。NEVER:以非事务的方式执行,如果当前存在事务,则抛出异常。MANDATORY:要求当前必须存在事务,否则抛出异常。根据具体的业务需求和并发情况,需要选择适当的隔离级别和传播行为来实现对事务的控制和管理。需要注意的是,隔离级别越高,数据一致性的保证越好,但并发性能可能会降低。而传播行为可以用于定义事务在多个方法间的传递方式,以确保事务的一致性和完整性。
而传播行为确实是一个难点,很多同学都没有办法正确的理解,在这里我们举例子说明一下:
REQUIRED:假设有两个方法A和B,A方法被标记为@Transactional,而B方法没有。当在A方法中调用B方法时,如果当前已存在一个事务,B方法会加入到该事务中,如果没有事务,则会创建一个新的事务并将B方法放在这个新的事务中。
REQUIRES_NEW:同样假设有两个方法A和B,A方法和B方法都被标记为@Transactional。当在A方法中调用B方法时,无论A方法所处的上下文是否已经存在一个事务,B方法都会创建一个新的事务,并将A方法原有的事务挂起,B方法在创建的新事务中独立执行。
SUPPORTS:,假设有两个方法A和B,其中A方法被标记为@Transactional,而B方法没有。当在A方法中调用B方法时,如果当前已存在一个事务,B方法会加入到该事务中,以保证事务的一致性;如果没有事务,则B方法以非事务的方式执行,即没有事务的保护和控制。
NOT_SUPPORTED:假设有两个方法A和B,其中A方法被标记为@Transactional,而B方法没有。当在A方法中调用B方法时,无论当前是否存在事务,B方法都会以非事务的方式执行,即使A方法原本处于一个事务中,也会被挂起。
NEVER:假设有一个方法A被标记为@Transactional,而在A方法内部调用了一个被标记为@Transactional(propagation = Propagation.NEVER)的方法B。在这种情况下,如果在调用B方法时存在一个事务,那么会抛出异常,因为B方法不允许在事务
项目第三阶段技术:
初步引入Redis:
Redis(Remote Dictionary Server)是一个开源的内存存储系统,常用于构建高性能、高可扩展性的应用程序。它支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的操作命令,使开发人员能够快速、灵活地处理数据。
在这里我们不做详细介绍,我贴一下我之前写的Redis的文章,感兴趣的小伙伴可以看一下,都是一些简单介绍。
【从零开始学习Redis | 第一篇】快速了解Redis-CSDN博客
【从零开始学习Redis | 第二篇】Redis中的数据类型和相关命令-CSDN博客
【从零开始学习Redis | 第三篇】在Java中操作Redis-CSDN博客
这三篇快速介绍了Redis以及如何在java中操作Redis,看完之后基本就可以简单的应用。
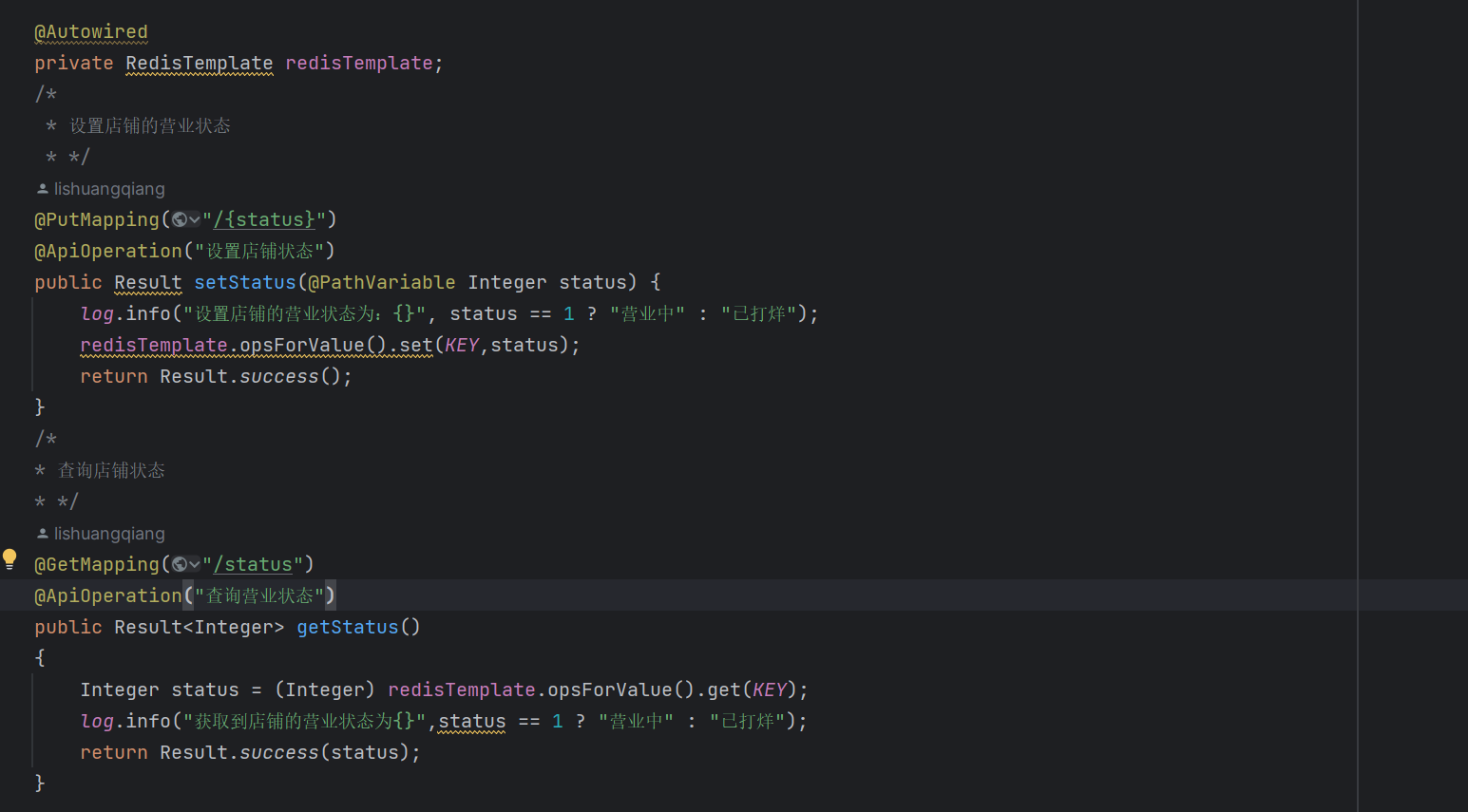
而我们的项目中引入Redis的地方是:查询店铺营业状态 ,像这种店铺营业状态,本项目无非就两个状态:营业中/打样。而且它属于高频查询。只要用户浏览到这个店铺,前端就要自动发送请求到后端查询店铺状态。
像这种存储信息少,查询频率高的信息,我看就没有必要拷打MySQL了,因为MySQL基于磁盘存储,高频的查询会给服务器造成不小的压力。
而Redis就刚好帮助我们解决了这个痛点。 正如我们前面介绍的:Redis是基于键值对进行存储的。
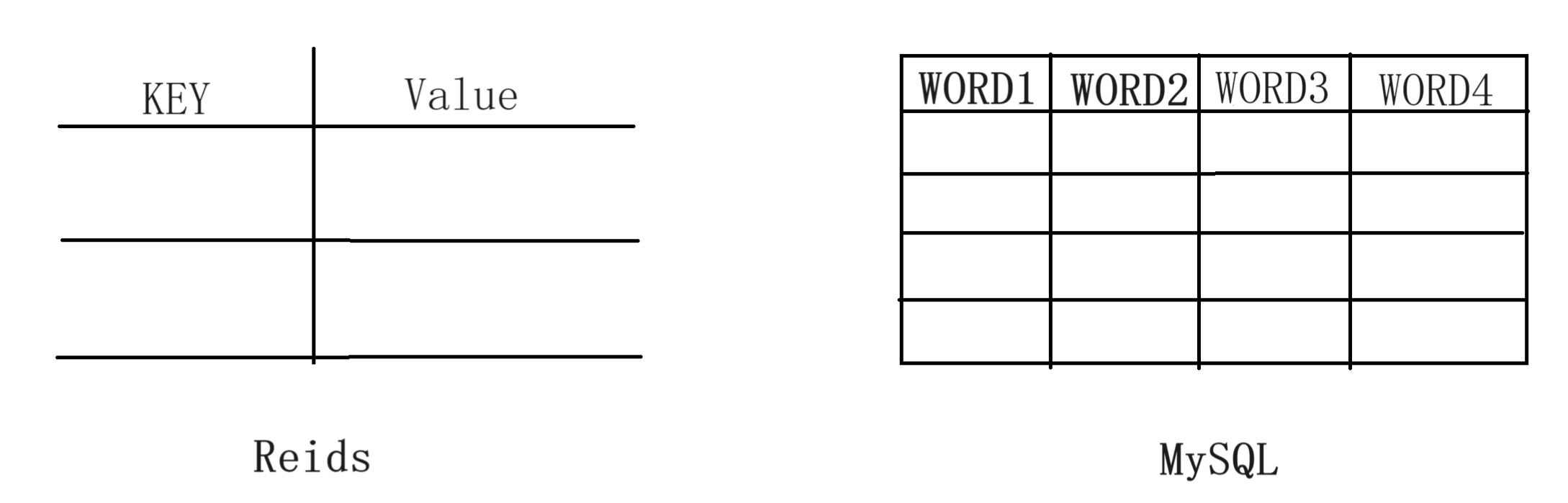
而键值对这种形式就符合我们对于店铺营业状态数据格式的理想存储状态,Redis也把数据放到缓存中,而不是磁盘,有效缓解了这种高频查询给磁盘带来的压力
明白了基本思路之后,我们来看一下思路如何转化为JAVA代码:
首先:在Java中,我们一般是通过Spring Data Redis来对 Redis进行操作。
首先,先要导入Spring Data Redis的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>其次,配置redis数据源:
spring:
redis:
host: 地址
port:端口号
password:密码3.编写配置类,创建RedisTemplate对象:
@Configuration
@Slf4j
public class RedisConfguration {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory)
{
log.info("开始创建redis模板对象....");
RedisTemplate redisTemplate = new RedisTemplate();
//设置redis的连接工厂对象
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置key的序列化器
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}4.使用RedisTemplate 对象操作Redis
---------------------------------------------------------------------------------------------------------------------------------这样我们就可以在Java中操作Redis了。
只需要创建一个Redis对象,利用Spring Data Redis 就可以对Redis进行操作。
利用Redis来对业务优化:
用户一旦点进店铺,店铺就需要向用户展示菜品,套餐等等数据。这种通过少量的操作可以调起大量后端操作的行为,是一个很危险的杠杆操作。而在高并发环境下,这无疑又是在拷打服务器。
而且这种重复查询的请求,正是我们要优化的目标。
我们的思路很简单:缓存请求相应内容,如果小程序又发送相同请求,那么我们就从缓存中直接返回相应内容。这样就减少了直接对后端的数据库的查询。
而这句话中,解决问题的重点两个字就可以概括:缓存!
这与我们上面讲到的Redis的职能岂不是相同嘛?我们在初识Redis的时候就说过:Redis是高性能的,基于键值对的,写入缓存的 内存存储系统。
那么对我们上述的思路进行细节化补充:在高频查询控制器上额外利用Redis缓存一份响应结果,等到后端接受到了相同的请求的时候,我们就查询Redis中有无对应的数据,如果有就从Redis中拿取,如果没有数据就进入server层,从数据库拿,拿了之后缓存到Redis中。
思路现在已经明确了,我们来看一下代码实现(我们以用户端查询菜品为例):
但是这种忽略数据库,从缓存中拿数据的方式存在问题:
如何保证数据库的数据与缓存的数据一致?
因为我们在添加redis作为缓冲区之后,如果缓冲区中存在数据,我们是直接从缓冲区拿数据的,如果我们更改了数据库,可能就会造成数据库与缓冲区数据不一致的情况。
- 读写双写(Write-through):在更新数据库时,同时更新Redis缓存。这意味着在写入数据库的同时,将相同的数据写入Redis缓存。这种方式确保了数据库和缓存中的数据始终保持一致。但是需要注意的是,双写操作会增加系统的写入负载和延迟,并且需要保证写入操作的原子性。
- 读写更新(Write-behind):在更新数据库时,延迟更新Redis缓存。这种方式先更新数据库,然后异步地更新Redis缓存,以提高写入的性能和响应速度。在这种情况下,可能会出现一小段时间内数据库和缓存数据的不一致,但后续的读取操作会从数据库中获取最新的数据并更新缓存。
- 缓存失效策略:通过在缓存中设置适当的过期时间或失效策略,确保缓存中的数据在一定时间后会过期并从数据库中重新加载。这样可以保证在数据更新或过期后,下一次读取操作将从数据库中获取最新的数据,并更新缓存。这种方式适用于数据变化不频繁、对数据实时性要求不高的场景。
- 发布订阅模式(Pub/Sub):使用Redis的发布订阅功能,当数据库中的数据发生变化时,通过发布消息的方式通知订阅者(Redis缓存)进行更新。这样可以保证在数据发生变化时,及时通知Redis缓存更新,以保持数据的一致性。
而Redis自身也存在问题
- 穿透(Cache Penetration):当一个不存在的键被频繁查询时,会导致缓存无效并且每次查询都需要访问数据库。这种情况下,恶意用户可以通过构造不存在的键来绕过缓存,直接请求数据库。这不仅浪费了数据库的资源,还可能导致数据库压力过大。为了解决穿透问题,可以使用布隆过滤器或者在查询得到空结果时也进行缓存,设置一个较短的过期时间。
- 击穿(Cache Breakdown):当一个热点键过期或被清除时,同时又有大量的请求访问该键,导致这些请求直接访问数据库,称为击穿。这种情况下,数据库会承受巨大的压力,可能导致宕机或性能下降。为了解决击穿问题,可以使用互斥锁或者分布式锁,保证只有一个请求能够访问数据库,并在请求获取到数据后更新缓存。
- 雪崩(Cache Avalanche):当大量的缓存键在同一时间失效,或者缓存服务器发生故障,导致大量的请求直接访问数据库,称为雪崩效应。这种情况下,数据库会承受巨大的压力,可能导致宕机或性能下降。为了解决雪崩问题,可以采用多级缓存架构,将请求分散到多个缓存服务器,或者使用热点数据预加载的方式,提前加载热门数据到缓存中。
而我们本项目解决Redis缓存的问题非常简单:只要有更新业务或者新建业务就清空对应的缓冲区。
利用Spring cache来对业务进行优化:
Spring Cache 是 Spring Framework 提供的缓存抽象和实现框架。它为应用程序提供了一种统一的缓存抽象,支持多种缓存技术的集成,并支持 AOP 机制实现基于方法的缓存,从而简化了缓存的使用和管理。
下面是 Spring Cache 的一些特点和常用功能:
-
缓存技术支持:Spring Cache 支持多种主流的缓存技术,包括 EHCache、Redis、Guava 等。
-
基于注解的缓存:Spring Cache 提供了基于注解的缓存,可以在方法上直接使用 @Cacheable、@CachePut、@CacheEvict 等注解,实现对方法结果的自动缓存和更新。
简单的说:它也是一种缓存技术,使得所用工具不局限于Redis。相比较于使用Redis的时候需要把相关代码内嵌到方法体种,Spring Cache是一种基于注解方式来达到内嵌代码相同的效果。
引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
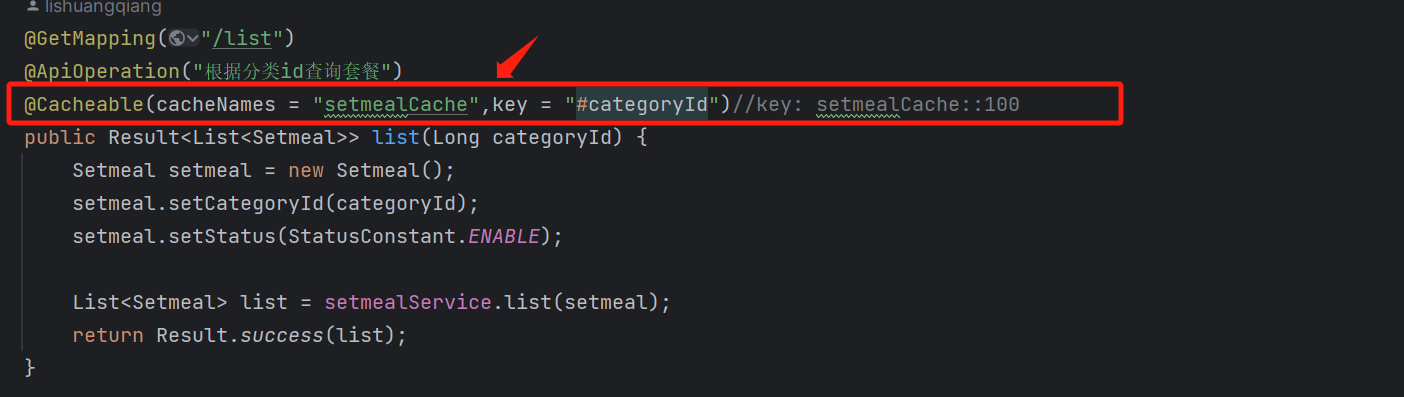
</dependency>然后我们就可以通过调用相关注解的方式来达到缓存套餐的功能:(在这里我们的底层缓存实现选择使用redis)
Httpclient:
Httpclient是一个服务器端进行HTTP通信的库,他使得后端可以发送各种HTTP请求和接收HTTP响应,使用HTTPClient,可以轻松的发送GET,POST,PUT,DELETE等各种类型的的请求
他是一个很常用的技术,因为很多第三方接口的使用方式就需要我们的后端发送请求到指定资源路径,这样才可以调用相关服务。例如我们下方的微信登录接口,后端在使用登录凭证校验接口的时候就需要发送指定请求到给定的URL中。
微信登录接口:
图片来自微信小程序开发文档开放能力 / 用户信息 / 小程序登录 (qq.com)https://developers.weixin.qq.com/miniprogram/dev/framework/open-ability/login.html
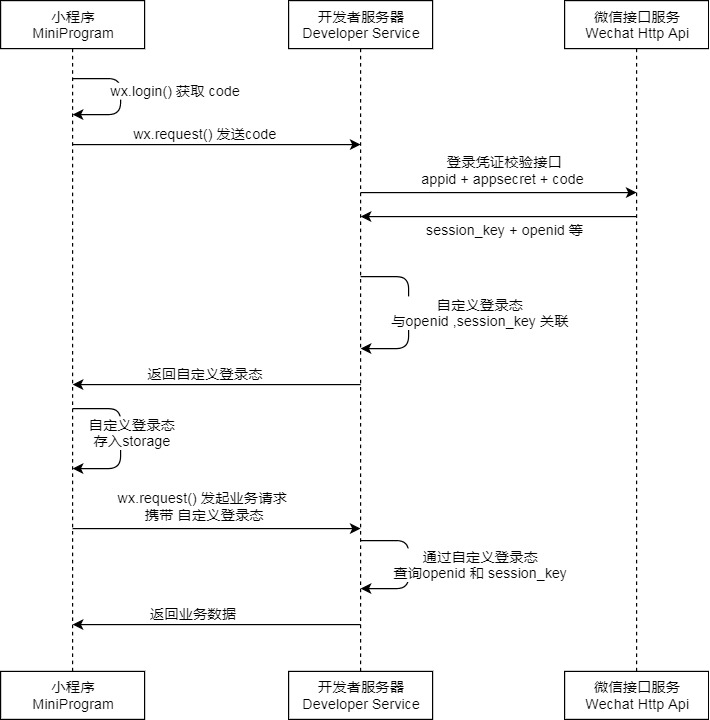
通过这张图,我们可以了解实现微信登录的基本流程
1.我们的小程序会调用wx.login()来获得一个code。该 code 的作用是用于后续的用户身份验证和获取用户信息。
2.小程序的wx.request会把code发送给后端,后端再打包自己的小程序ID(appid)和小程序密钥(appsecert) 最后加上小程序发送给自己的code,利用Httpclient从后端发送给微信接口服务。而微信接口服务会在校验之后返回session_key和openid
微信接口服务返回的session_key和openid具有以下用途:
用户身份识别:通过openid,可以唯一标识用户的身份。开发者可以将openid与用户在自己的系统中的账号进行关联,实现用户的登录、注册等功能。
数据加密解密:session_key是用于对用户敏感数据进行加密和解密的密钥。开发者可以使用session_key对用户的敏感数据进行加密,确保数据在传输过程中的安全性;同时,也可以使用session_key对加密后的数据进行解密,获取原始数据。
用户信息获取:通过openid和session_key,开发者可以向微信接口服务发送请求,获取用户的详细信息,如用户昵称、头像等。这些信息可以用于个性化展示、社交分享等功能
3.在后端获取到微信接口服务发送给自己的session_key和openid,自定义用户登录态,并且发送给小程序
自定义用户登录态指的是在用户登录时,后端根据一定的规则生成一个唯一的标识符(如token),并将其返回给前端。前端在接下来的请求中,需要带上这个标识符,以便后端可以识别当前请求的用户身份。
在微信小程序中,用户登录后,后端会返回一个
session_key和openid,这两个值可以用于生成一个唯一的标识符,作为用户的登录态。具体实现方式可以是将session_key和openid拼接起来,再进行加密处理,生成一个token,并将其返回给小程序。小程序在接下来的请求中,需要在请求头或者请求参数中携带该token,以便后端可以验证用户的身份。自定义用户登录态的好处是可以在后端实现用户身份验证和权限控制,保护系统的安全性。同时,由于token是由后端生成的,可以有效防止恶意攻击者伪造用户身份。
4.小程序把后端发送过来的自定义登录态存入到storge中。
---------------------------------------------------------------------------------------------------------------------------------
而此时小程序的微信登录就完成了。再往后的是解释一次小程序与服务器交互的过程。
wx.request()发送业务请求,携带自定义登录态,方便后端识别当前用户身份。后端根据前端发送过来的自定义登录态来查询openid和session_key。此时后端就可以识别当前用户身份。返回当前用户的个性化业务数据。
微信支付接口:
图片来自微信支付开发者文档
开发指引-小程序支付 | 微信支付商户平台文档中心 (qq.com)https://pay.weixin.qq.com/wiki/doc/apiv3/open/pay/chapter2_8_2.shtml
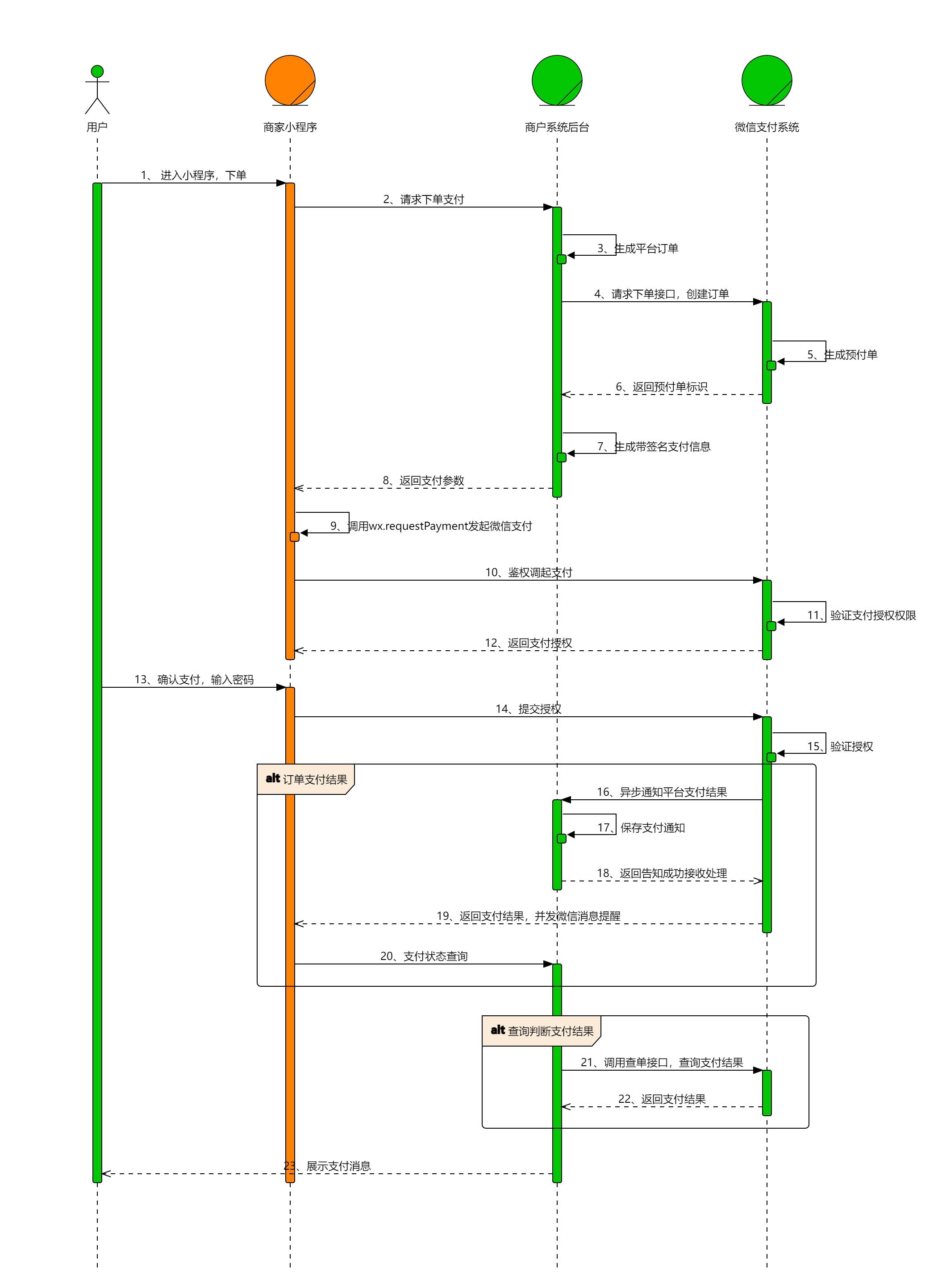
通过这张图,我们可以了解到小程序调用微信支付的基本流程
1.用户进入小程序下单 ,小程序会发送下单请求给商家系统后台,商家后端会生成平台订单,请求微信支付系统的下单接口,创建订单。微信支付系统接收到商家系统后台的请求后,会生成预付单,并且返回预付单标识给商家系统后台,此时商户系统后台利用算法生成带签名支付信息,并且把相关支付参数返回给商家小程序
2.当小程序接收到相关的参数之后,就会调用wx.requestPayment发起微信支付,此时小程序会先向微信支付系统发送请求,检查当前用户身份,微信支付系统在检验当前用户符合权限之后,会给小程序返回支付授权,允许小程序调起支付页面。
3.当小程序调起支付页面之后,用户输入密码确定支付,此时微信小程序会打包相关参数给微信支付系统,校验身份通过之后,就异步通知平台支付交易结果给商家后端,商家后端对其进行保存通知处理,并且在这同时返回支付结果,并且发送微信消息提醒。
异步通知是一种通信方式,用于在两个系统之间传递信息,其中发送方无需立即等待接收方响应的结果。它允许发送方继续执行其他任务,而不必阻塞并等待接收方的回应。
4.上述已经完整的介绍了一次微信小程序调用微信支付的具体过程。如果我们后续要查询判断微信支付结果,就在后端调用查寻订单接口,查询支付结果。而微信支付平台就会为商家后端返送支付结果,供我们进行各种判断。
内网穿透工具Cpolar:
在微信支付接口的流程中,当支付成功之后,微信后台要向我们的服务器后台返送支付结果,但是存在一个问题:我们的IP地址都是私有IP地址,微信后台根本访问不了,这样就接收不到支付结果,因此我们需要一个公有的IP地址
而我们给出的解决方案是使用内网穿透工具Capolar
简单的说:内网穿透就是在私有IP地址和公有IP地址之间建立一个临时的映射关系,使得我们的内网服务器暴漏到公网之中,这样我们就可以为微信后台提供一个可以在公网访问的地址,用于接收支付结果。
需要注意的是,在实际的项目开发中,我们的项目最后是会上线使用的,而这里是我们作为个人开发者,而该项目也只是简单的练手项目,因此我们才会使用内网穿透工具。
项目第四阶段技术:
Spring Task:
Spring Task 是 Spring 框架提供的一种任务调度工具,用于在应用程序中执行定时任务或者周期性任务。它基于线程池机制,可以创建并管理多个线程来执行任务。
通过 Spring Task,开发人员可以通过注解或者配置的方式定义需要执行的任务,并设置执行的时间间隔或者执行时间点。Spring Task 提供了灵活的任务调度能力,可以满足各种任务执行的需求,例如定时的数据同步、定时的报表生成、定时的缓存清理等。
简单的说:Spring Task为我们提供了一种基于注解的方式来使得我们的后端具有定时处理任务的能力,这项功能可以说是十分常见:我们CSDN的每日周报,就是定时任务。
而这项工具,在我们的项目中的主要作用是:处理异常订单
在我们的数据库中,总会有一些异常订单,例如用户一直未点击送达的订单,而我们需要对这些订单进行集中的处理。
需要注意的是,这个依赖他自己很小,小到并不会独立作为一个依赖包需要导入,而是属于 spring context 的一个附属依赖
接下来我们看一下他在代码中的使用步骤:
1.导入依赖:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>版本号</version>
</dependency>而设置定时任务的基本代码设计很简单
设置定时
----------------------------------------------------
具体定时任务
我们先直接贴一段代码给大家看一下:
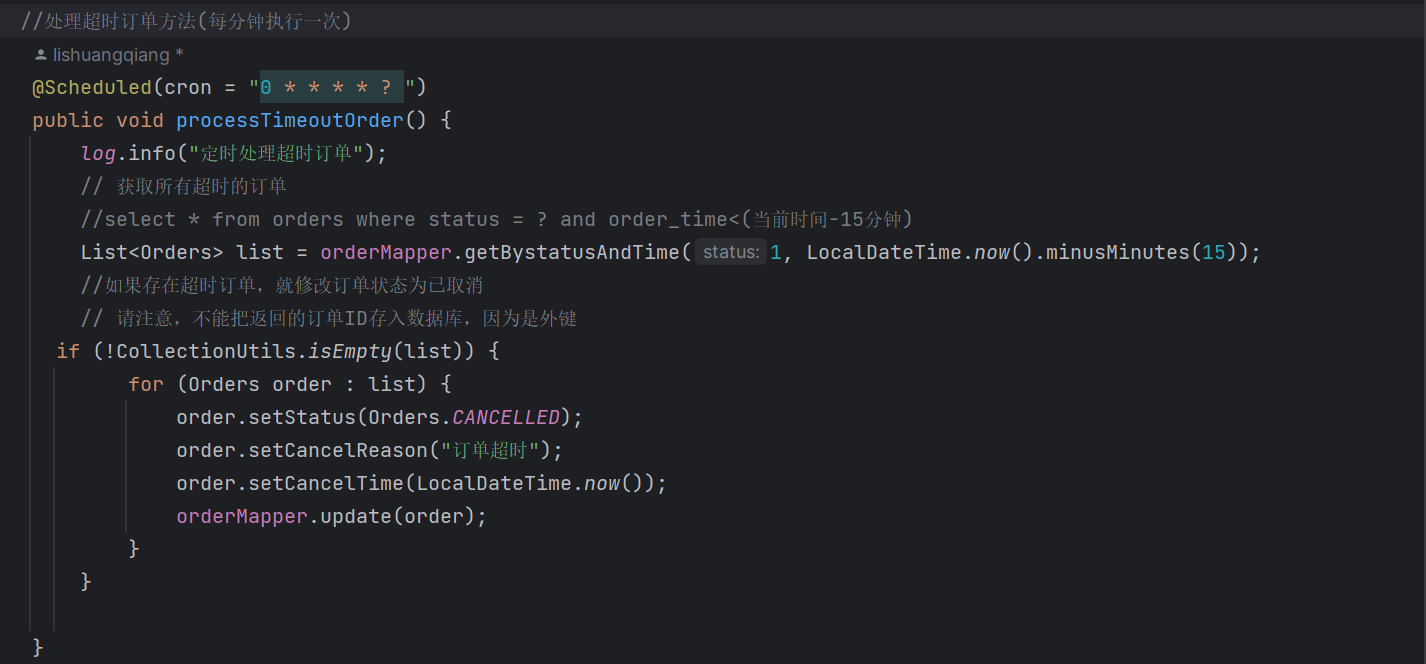
具体的定时任务很简单,就是简单的业务逻辑实现代码,而重点在这个注解@Scheduled
它是用来设置定时的注解,它里面采用的表达式叫做cron表达式,通过这个表达式,我们可以指定任务多久执行一次。
而Cron 表达式是一个字符串,由 6 个字段组成,每个字段表示不同的时间单位和限制条件
这几个字段从左到右分别为: 秒 分 时 天 周 月 年
之所以说是 六个字段是因为天和周不能同时出现。
而我们也不需要掌握如何书写Cron表达式,开源的互联网已经为我们提供了大量的Cron表达式,在这里我也贴一个:
在线Cron表达式生成器 (pppet.net)https://www.pppet.net/但是在设置一些任务的时候,还是要对定时上做好权衡,因为大量的查询数据库会造成数据库的高压力。
引入Websocket来实现用户端和商家端通信:
在项目中,有外卖催单和来单提醒这两个功能。
这两个业务功能的逻辑思路很简单:
用户端下单或者催单后,发送特定请求到后端,后端再发送请求到商家端,商家端再根据后端的请求判断是催单还是来单提醒。
在这种思路中我们发现最关键的就在于:后端如何与商家端建立链接,实现实时通信?
基于这样的一个问题,我们使用了:Websocket 来实现这关键点:
WebSocket 是一种在 Web 应用程序中实现双向通信的协议。它允许客户端和服务器之间建立持久的、双向的通信通道,使得服务器可以主动向客户端推送消息,而无需客户端发送请求。
传统的 HTTP 协议是一种请求-响应模式,客户端需要定期发送请求并等待服务器的响应。但在某些场景下,需要实时地将数据推送给客户端,如聊天应用、实时数据监控等。这时就可以使用 WebSocket 协议。
WebSocket 协议通过在客户端和服务器之间建立一个持久的连接,实现了双向通信。它使用 HTTP 升级请求来升级到 WebSocket 连接,并在连接建立后,使用轻量级的帧来传递数据。与 HTTP 相比,WebSocket 具有更低的开销和更高的性能。
使用 WebSocket,客户端和服务器之间可以实时地发送消息和接收消息,不需要频繁地发起请求。这样可以减少网络流量和延迟,并提供更好的用户体验。在开发中,可以使用各种编程语言和框架来实现 WebSocket,如Java中的Spring WebSocket、Node.js中的Socket.io等。
总之,WebSocket 提供了一种简单、高效的方式,使得 Web 应用程序可以实现实时的双向通信。它在很多场景下都能发挥重要作用,特别是需要实时数据传输和服务器主动推送的应用场景。
我们展示一下代码:
首先,我们要在webSocket配置类中注册一个webSocket
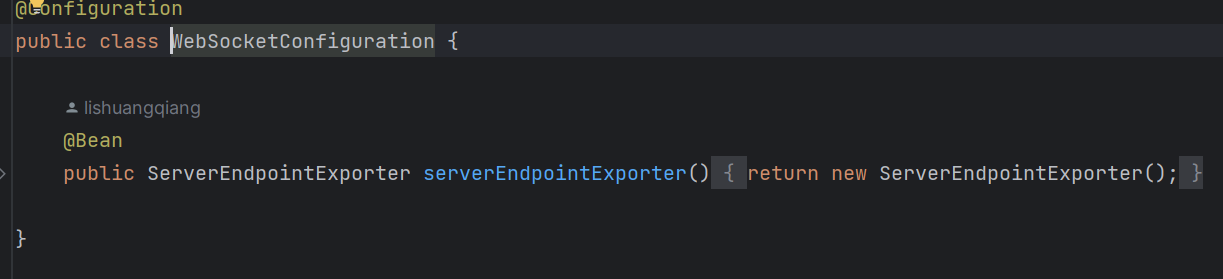
之后就可以用它与商家端进行实时通信:
实现用户催单后的商家提醒。
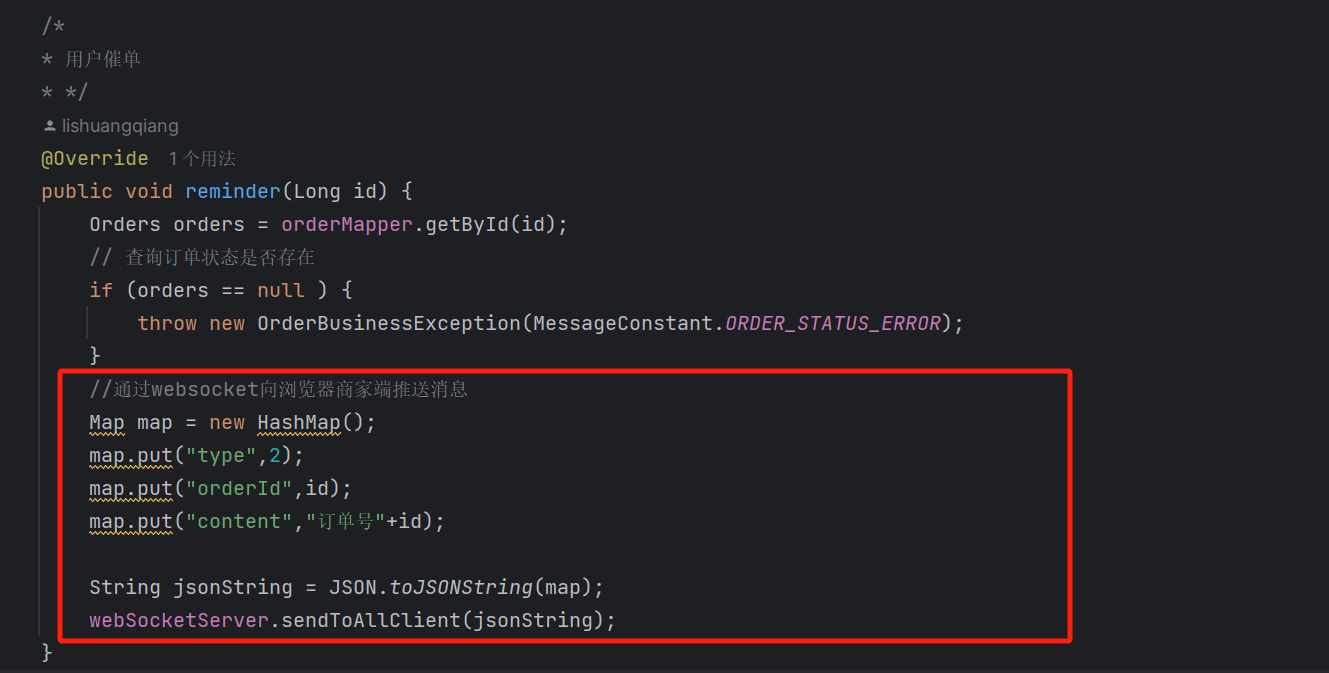
商家端效果:
而除了使用webSocket之外,我们可以使用SSE或长轮询技术:
SSE 是一种特殊的 HTTP 机制,它允许服务器向客户端推送数据,以实现服务器和客户端之间的实时通信。SSE 与 WebSocket 不同的是,它是基于 HTTP 协议的,不需要像 WebSocket 那样建立专门的协议和通信通道。
长轮询则是一种模拟实时通信的技术,它通过客户端向服务器发送一个请求并保持长时间的连接,在服务器端有新数据到达时返回响应,并在客户端接收到响应后再次发送请求继续保持连接。长轮询的实现方式类似于 SSE,但是相对于 SSE 而言,因为需要频繁的开启和关闭连接,长轮询会增加服务器的负担,同时也不如 SSE 和 WebSocket 那样实时和高效。
通过这里我们可以可以看到,长轮询并不是真正的双向通信,他只是不断延长请求响应的时间。
Apache POI技术实现导出文件:
Apache POI(Poor Obfuscation Implementation)是一个用于处理Microsoft Office格式文档的开源Java库。POI提供了一组可以读取、写入和操作各种Office文件的API,包括Word文档(.doc和.docx)、Excel电子表格(.xls和.xlsx)以及PowerPoint演示文稿(.ppt和.pptx)。
通过POI,开发者可以在Java应用程序中读取和编辑Office文档,实现对文档内容、样式、格式和元数据的操作。它提供了向现有文档添加新内容、修改现有内容、删除内容以及进行格式设置和样式调整等功能。
而在本项目中,我们并不使用ApachePOI建表,这样无疑是在拷打自己。我们的想法是直接就提供一张创建好的模板表,这样我们只需要使用ApachePOI来实现填充数据就好了。
代码太多,仅展示一部分: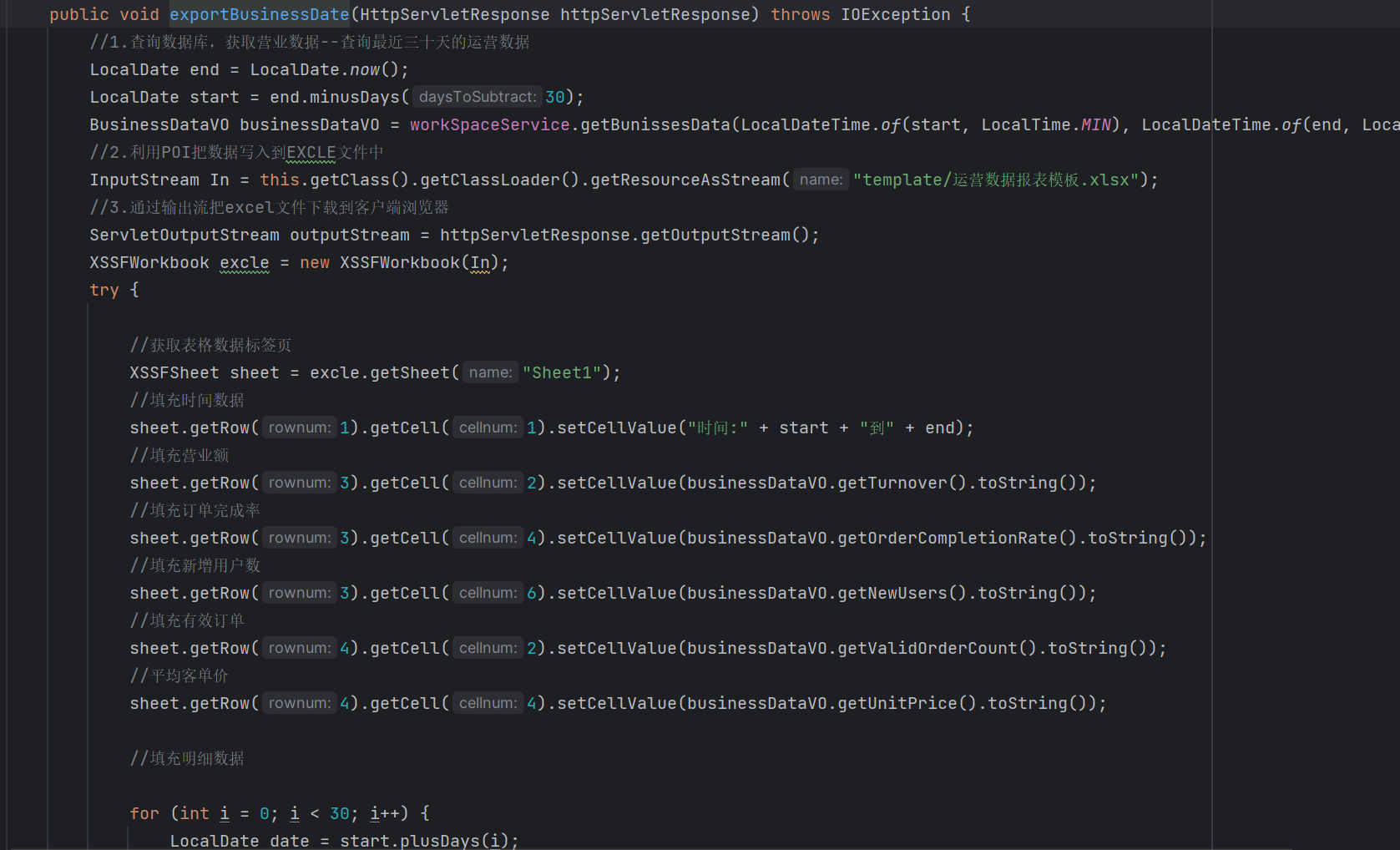
这项技术其实还属于应用类,会用就好了。
个人感悟:
(1)第一个感觉是思维的解放。
在这么多业务的练习中,我的对于业务的抽象能力大大提升,简单的讲:我认为代码的编写,实际上就是对业务需求的不断解构,拆分,细化。
例如:实现购物车接口。最初我还在想:如何让用户端购物车可以自动显示添加的菜品这些内容。因为没有办法把该业务抽象拆分为具体的代码思路而感到厌烦。而看了课之后就明白了,其实就是建立一张表,买了啥都记到表里面,所谓的添加商品可以实时看到,只不过是加了一个数据库查询之后回显给前端而已
这就是我想要说的,再复杂的业务也可以不断的进行抽离,拆分,最终变为一个个简单的逻辑代码,而谁的抽象拆分能力越强,谁就越可能成为一位合格的程序员。
(2)第二个感觉是思维的提升。
回头望去,原来自己学习到了这么多的知识点,并且也没有自己最开始认为的那么难。回顾整个项目,我认为作为初写项目的学生来讲,我面临的最大的问题是:缺乏宏观思想。我在写业务代码的时候,通常只能局限于仅仅实现当前业务,并没有思考代码复用性,业务通用性,逻辑顺畅性这些问题。导致写了很多的功能相同的代码。四个字总结:站位不高。
而这也是我尝试写项目总结的原因,项目总结让我脱离具体的业务板块,不再把思维聚焦在某一个功能的实现上,而是尝试聚焦整个业务整体。在我的眼里,实现项目是从小到大,我用一个一个业务去组成了这个大的项目。而写项目日记是从大到小,当我从一整个项目整体开始拆分业务的时候,我是切身实地的觉得我的站位变高了,因为我在真真切切的思考不同业务代码之间的逻辑关系。由于实现过整个业务,我可以让思维在不同的业务之间穿梭,不断的解构这些业务。尝试探寻更好的业务解决方案。
我认为:如果我可以在业务逻辑代码搭建阶段就有这种宏观思考的能力,那么整个项目的业务逻辑实现就会变的轻松很多。
最后,如果真的有能够看到这里得的朋友,我衷心的祝你可以对计算机一直保持热爱。我们下一个项目见!
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!