SQL客户端与DDL操作
- Flink SQL
- SQL客户端
- 1.启动Flink
- 2.启动Flink的SQL客户端
- 3.HELP命令
- 4.验证连接
- 5.结果显示模式
- 6.执行配置
- 数据库操作
- 1.创建数据库
- 2.查询数据库
- 3.修改数据库
- 4.删除数据库
- 表操作
- 1.创建表
- 表列属性
- 表Watermark属性
- 列PRIMARY KEY属性
- 列PARTITIONED BY属性
- 列WITH选项属性
- 列LIKE属性
- 列AS select_statement属性
- 创建一张基于 Print的简单表
- 2.查看表
- 3.修改表
- 4.删除表
- 其他
- 动态表
- 将流转换成动态表
- 连续查询
- 将动态表转换为流
- 时间属性
- 处理时间
- 事件时间
Flink SQL
Flink SQL是Apache Flink框架中的一种查询语言,用于对数据流和批处理作业执行SQL查询和转换操作。它提供了一种声明性的方式来处理数据,使得开发人员能够使用熟悉的SQL语法来操作流式和批处理数据。
Flink的Table API和SQL是流批统一的API,具有相同的语义。
Table API是用于Scala和Java语言的查询API,它可以用一种非常直观的方式来组合使用选取、过滤、join等关系型算子。
Flink SQL是基于Apache Calcite来实现的标准SQL,这两种API中的查询对于批(DataSet)和流(DataStream)的输入有相同的语义,也会产生同样的计算结果。
SQL客户端
Flink的Table & SQL API可以处理SQL语言编写的查询语句,但是这些查询需要嵌入用Java或Scala编写的表程序中。此外,这些程序在提交到集群前需要用构建工具打包。这或多或少限制了Java/Scala程序员对Flink的使用。
SQL客户端的目的是提供一种简单的方式来编写、调试和提交表程序到Flink集群上,而无需写一行Java或Scala代码。SQL客户端命令行界面(CLI)能够在命令行中检索和可视化分布式应用中实时产生的结果。
SQL 客户端捆绑在常规 Flink 发行版中,因此可以直接运行。它仅需要一个正在运行的 Flink 集群就可以在其中执行表程序。
1.启动Flink
# 基于独立模式的会话模式部署
./bin/start-cluster.sh
# 基于YARN运行模式的会话模式部署
./bin/yarn-session.sh -d
2.启动Flink的SQL客户端
SQL Client 脚本也位于 Flink 的 bin 目录中。用户可以通过启动嵌入式 standalone 进程或通过连接到远程 SQL Gateway 来启动 SQL 客户端命令行界面。
# SQL客户端默认使用embedded模式
./bin/sql-client.sh
# 显式使用embedded 模式
./bin/sql-client.sh embedded
# 使用gateway模式
./bin/sql-client.sh gateway --endpoint <gateway address>
# 基于YARN运行模式的embedded模式
./bin/sql-client.sh embedded -s yarn-session
# 启动时,指定sql文件
./bin/sql-client.sh embedded -s yarn-session -i ./sql-client-init.sql
3.HELP命令
命令行界面启动后,使用 HELP 命令列出所有可用的 SQL 语句
HELP 打印可用命令的帮助信息。
QUIT/EXIT 退出 SQL CLI 客户端。
CLEAR 清除当前终端的内容。
SET 设置会话配置属性。语法:"SET '<key>'='<value>';". 使用 "SET;" 列出所有属性。
RESET 重置会话配置属性。语法:"RESET '<key>';". 使用 "RESET;" 重置所有会话属性。
INSERT INTO 将 SQL SELECT 查询的结果插入到指定的表中。
INSERT OVERWRITE 将 SQL SELECT 查询的结果覆盖插入到指定的表中,覆盖现有数据。
SELECT 在 Flink 集群上执行 SQL SELECT 查询。
EXPLAIN 描述给定名称的查询或表的执行计划。
BEGIN STATEMENT SET 开始一个语句集合。语法:"BEGIN STATEMENT SET;"
END 结束一个语句集合。语法:"END;"
ADD JAR 将指定的 jar 文件添加到提交的作业类加载器中。语法:"ADD JAR '<path_to_filename>.jar'"
REMOVE JAR 从提交的作业类加载器中移除指定的 jar 文件。语法:"REMOVE JAR '<path_to_filename>.jar'"
SHOW JARS 显示用户指定的 jar 依赖列表。该列表受到 --jar 和 --library 启动选项以及 ADD/REMOVE JAR 命令的影响。
4.验证连接
输入第一条 SQL 查询语句并按 Enter 键执行,可以验证设置及集群连接是否正确
[root@node01 flink]# ./bin/sql-client.sh
▒▓██▓██▒
▓████▒▒█▓▒▓███▓▒
▓███▓░░ ▒▒▒▓██▒ ▒
░██▒ ▒▒▓▓█▓▓▒░ ▒████
██▒ ░▒▓███▒ ▒█▒█▒
░▓█ ███ ▓░▒██
▓█ ▒▒▒▒▒▓██▓░▒░▓▓█
█░ █ ▒▒░ ███▓▓█ ▒█▒▒▒
████░ ▒▓█▓ ██▒▒▒ ▓███▒
░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░
▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒
███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒
░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒
███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░
██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓
▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒
▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒
▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█
██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █
▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓
█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓
██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓
▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒
██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒
▓█ ▒█▓ ░ █░ ▒█ █▓
█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░
█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█
██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓
▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██
░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓
░▓██▒ ▓░ ▒█▓█ ░░▒▒▒
▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░
______ _ _ _ _____ ____ _ _____ _ _ _ BETA
| ____| (_) | | / ____|/ __ \| | / ____| (_) | |
| |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_
| __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __|
| | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_
|_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__|
Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit.
Command history file path: /root/.flink-sql-history
Flink SQL>
输入SQL:SELECT 'Hello World';,该查询不需要 table source,并且只产生一行结果。CLI 将从集群中检索结果并将其可视化。按 Q 键退出结果视图。

5.结果显示模式
CLI为维护和可视化结果提供三种模式。默认table,还可以设置为tableau、changelog
1.表格模式(table mode)
在内存中实体化结果,并将结果用规则的分页表格可视化展示出来。
执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'table';
执行SQL:
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
name cnt
Alice 1
Greg 1
Bob 2
2.变更日志模式(changelog mode)
不会实体化和可视化结果,而是由插入(+)和撤销(-)组成的持续查询产生结果流。
SET 'sql-client.execution.result-mode' = 'changelog';
op name cnt
+I Bob 1
+I Alice 1
+I Greg 1
-U Bob 1
+U Bob 2
3.Tableau模式(tableau mode)
更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同:
SET 'sql-client.execution.result-mode' = 'tableau';
+----+--------------------------------+----------------------+
| op | name | cnt |
+----+--------------------------------+----------------------+
| +I | Bob | 1 |
| +I | Alice | 1 |
| +I | Greg | 1 |
| -U | Bob | 1 |
| +U | Bob | 2 |
+----+--------------------------------+----------------------+
Received a total of 5 rows
6.执行配置
执行环境默认streaming,也可以设置batch
SET execution.runtime-mode=streaming;
设置默认并行度
SET parallelism.default=1;
设置状态TTL
SET table.exec.state.ttl=1000;
数据库操作
1.创建数据库
根据给定的表属性创建数据库。若数据库中已存在同名表会抛出异常。
CREATE DATABASE [IF NOT EXISTS] [catalog_name.]db_name
[COMMENT database_comment]
WITH (key1=val1, key2=val2, ...)
IF NOT EXISTS:若数据库已经存在,则不会进行任何操作。
WITH OPTIONS:数据库属性一般用于存储关于这个数据库额外的信息。 表达式 key1=val1 中的键和值都需要是字符串文本常量。
Flink SQL> CREATE DATABASE db_flink;
[INFO] Execute statement succeed.
2.查询数据库
查询所有数据库
Flink SQL> SHOW DATABASES;
+------------------+
| database name |
+------------------+
| default_database |
| db_flink |
+------------------+
2 rows in set
查询当前数据库
Flink SQL> SHOW CURRENT DATABASE;
+-----------------------+
| current database name |
+-----------------------+
| default_database |
+-----------------------+
1 row in set
切换数据库
USE database_name;
3.修改数据库
在数据库中设置一个或多个属性。若个别属性已经在数据库中设定,将会使用新值覆盖旧值。
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)
4.删除数据库
根据给定的表名删除数据库。若需要删除的数据库不存在会抛出异常 。
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
IF EXISTS:若数据库不存在,不执行任何操作。
RESTRICT:当删除一个非空数据库时,会触发异常。(默认为开)
CASCADE:删除一个非空数据库时,把相关联的表与函数一并删除。
Flink SQL> DROP DATABASE db_flink;
[INFO] Execute statement succeed.
表操作
1.创建表
根据指定的表名创建一个表,如果同名表已经在 catalog 中存在了,则无法注册。
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name
(
{ <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> }[ , ...n]
[ <watermark_definition> ]
[ <table_constraint> ][ , ...n]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (key1=val1, key2=val2, ...)
[ LIKE source_table [( <like_options> )] | AS select_query ]
表列属性
1.物理/常规列
physical_column_definition:定义物理列,其定义了物理介质中存储的数据中字段的名称、类型和顺序
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING
) WITH (
...
);
2.元数据列
metadata_column_definition: 定义元数据列
例如:元数据列可用于从 Kafka 记录中读取和写入时间戳,以进行基于时间的操作。简单说就是将Kafka数据中的一个时间戳作为表的一个字段
创建一个带有引用元数据字段的附加元数据列的表timestamp
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
`record_time` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' -- reads and writes a Kafka record's timestamp
) WITH (
'connector' = 'kafka'
...
);
# 如果自定义的列名称和定义metadata字段的名称一样, FROM子句可省略
`timestamp` TIMESTAMP_LTZ(3) METADATA
# 如果自定义列的数据类型和定义的metadata字段的数据类型不一致,程序运行时会自动强转,但是要求两种数据类型是可以强转
-- 将时间戳强转为 BIGINT
`timestamp` BIGINT METADATA
3.计算列
computed_column_definition:定义计算列,将一些列经过自定义运算生成的新列,在物理上并不存储在表中,只能读不能写。
`money` AS price * quanitity
表Watermark属性
WATERMARK定义了表的事件时间属性,其形式为 :
WATERMARK FOR rowtime_column_name AS watermark_strategy_expression
rowtime_column_name:把一个现有的列定义为一个为表标记事件时间的属性。该列的类型必须为 TIMESTAMP(3),且是 schema 中的顶层列,它也可以是一个计算列。
Flink SQL提供了几种 WATERMARK 生产策略:
1.严格升序:
Flink任务认为时间戳只会越来越大,也不存在相等的情况,只要相等或者小于之前的,就认为是迟到的数据。
WATERMARK FOR rowtime_column AS rowtime_column
2.递增:
一般基本不用这种方式。如果设置此类,则允许有相同的时间戳出现。
WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL '0.001' SECOND
3.有界无序:
用于设置最大乱序时间,此类Watermark 生成策略通常用于有数据乱序的场景,实际场景中,数据也都是会存在乱序,所以使用此类策略。
WATERMARK FOR rowtime_column AS rowtime_column – INTERVAL 'string' timeUnit
假如设置为WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL '5' SECOND ,则生成的是运行 5s 延迟的Watermark。
CREATE TABLE Orders (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH ( . . . );
列PRIMARY KEY属性
主键约束表明表中的一列或一组列是唯一的,并且它们不包含NULL值。主键唯一地标识表中的一行,只支持 not enforced。
键可以和列的定义一起声明,也可以独立声明为表的限制属性,不管是哪种方式,主键都不可以重复定义,否则 Flink 会报错。
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
PARYMARY KEY(user_id) not enforced
)
列PARTITIONED BY属性
创建分区表
根据指定的列对已经创建的表进行分区。若表使用 filesystem sink ,则将会为每个分区创建一个目录。
列WITH选项属性
创建表的表属性,表属性用于创建 table source/sink ,一般用于寻找和创建底层的连接器。用于指定外部存储系统的元数据信息。配置属性时,表达式key1=val1的键和值都应该是字符串字面值。
一般with中的配置项由Flink SQL 的 Connector(链接外部存储的连接器) 来定义,每种 Connector 提供的with 配置项都是不同的。
具体参考:Table & SQL Connectors
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
列LIKE属性
LIKE子句可以基于现有表的定义去创建新表,并且可以扩展或排除原始表中的某些部分。
还可以使用该子句,重用(或改写)指定的连接器配置属性或者可以向外部表添加 watermark 定义,
CREATE TABLE Orders (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'scan.startup.mode' = 'earliest-offset'
);
CREATE TABLE Orders_with_watermark (
-- 添加 watermark 定义
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
-- 改写 startup-mode 属性
'scan.startup.mode' = 'latest-offset'
)
LIKE Orders;
结果表 Orders_with_watermark 等效于使用以下语句创建的表:
CREATE TABLE Orders_with_watermark (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'scan.startup.mode' = 'latest-offset'
);
列AS select_statement属性
通过查询的结果创建和填充表。CTAS是使用单个命令创建数据并向表中插入数据的最简单、最快速的方法。
CREATE TABLE my_ctas_table
WITH (
'connector' = 'kafka',
...
)
AS SELECT id, name, age FROM source_table WHERE mod(id, 10) = 0;
结果表 my_ctas_table 等效于使用以下语句创建表并写入数据:
CREATE TABLE my_ctas_table (
id BIGINT,
name STRING,
age INT
) WITH (
'connector' = 'kafka',
...
);
INSERT INTO my_ctas_table SELECT id, name, age FROM source_table WHERE mod(id, 10) = 0;
注意CTAS 有如下约束:
暂不支持创建临时表
暂不支持指定列信息
暂不支持指定 Watermark
暂不支持创建分区表
暂不支持主键约束
创建一张基于 Print的简单表
Print连接器允许将每一行写入标准输出流或者标准错误流。
CREATE TABLE print_table (
f0 INT,
f1 INT,
f2 STRING,
f3 DOUBLE
) WITH (
'connector' = 'print'
)
也可以通过 LIKE子句 基于已有表的结构去创建新表
CREATE TABLE print_table
WITH ('connector' = 'print')
LIKE source_table (EXCLUDING ALL)
2.查看表
查看所有表
展示指定库的所有表,如果没有指定库则展示当前库的所有表。另外返回的结果能被一个可选的匹配字符串过滤。
SHOW TABLES [ ( FROM | IN ) [catalog_name.]database_name ] [ [NOT] LIKE <sql_like_pattern> ]
注意:如果没有指定数据库,则从当前数据库返回表。
LIKE子句中 sql 正则式的语法与 MySQL 方言中的语法相同
% 匹配任意数量的字符, 也包括0数量字符, \% 匹配一个 % 字符
_ 只匹配一个字符, \_ 匹配一个 _ 字符
Flink SQL> SHOW TABLES;
+-------------+
| table name |
+-------------+
| print_table |
+-------------+
1 row in set
查看表信息
{ DESCRIBE | DESC } [catalog_name.][db_name.]table_name
Flink SQL> DESC print_table;
+------+--------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+------+--------+------+-----+--------+-----------+
| f0 | INT | TRUE | | | |
| f1 | INT | TRUE | | | |
| f2 | STRING | TRUE | | | |
| f3 | DOUBLE | TRUE | | | |
+------+--------+------+-----+--------+-----------+
4 rows in set
3.修改表
修改表名
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
修改表属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
4.删除表
DROP [TEMPORARY] TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
其他
动态表
动态表是Flink的支持流数据的Table API和SQL的核心概念。与表示批处理数据的静态表不同,动态表是随时间变化的。可以像查询静态批处理表一样查询它们。查询动态表将生成一个 连续查询 。一个连续查询永远不会终止,结果会生成一个动态表。查询不断更新其(动态)结果表,以反映其(动态)输入表上的更改。本质上,动态表上的连续查询非常类似于定义物化视图的查询。
注意:
连续查询的结果在语义上总是等价于以批处理模式在输入表快照上执行的相同查询的结果。
流、动态表和连续查询之间的关系:
1.将流转换为动态表
2.在动态表上计算一个连续查询,生成一个新的动态表
3.生成的动态表被转换回流

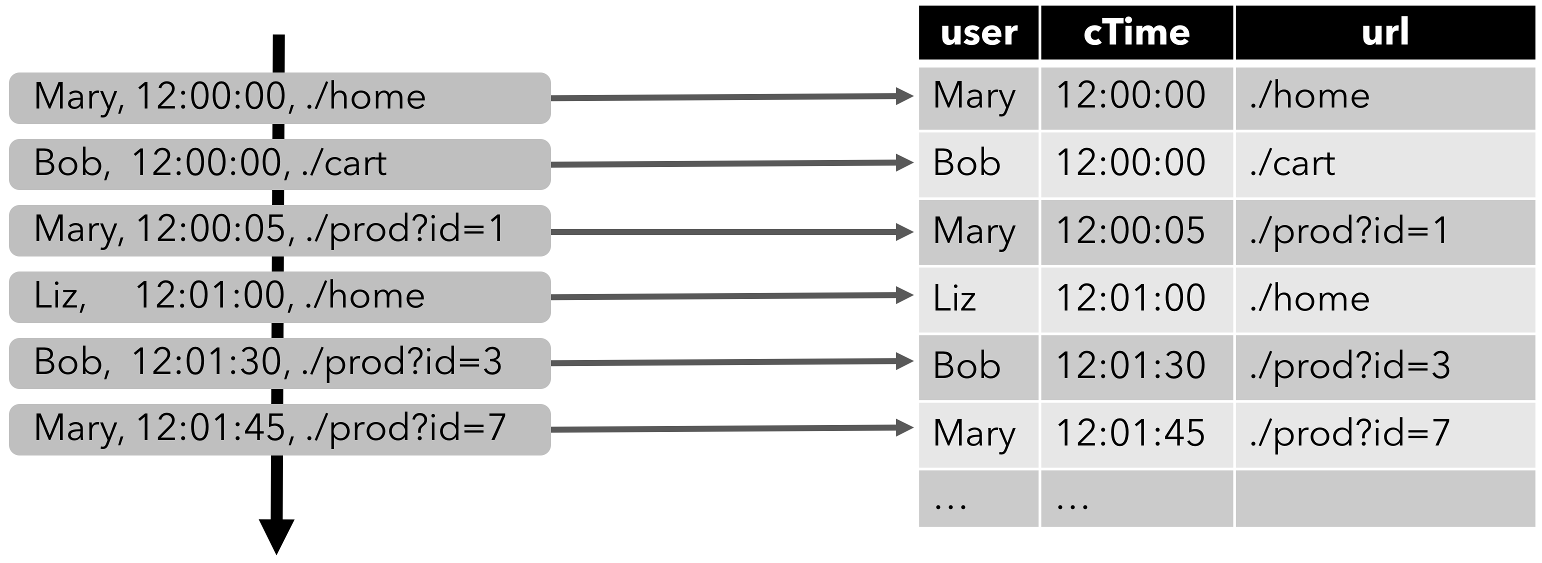
将流转换成动态表
为了使用关系查询处理流,必须将其转换成 Table。流的每条记录都被解释为对结果表的 INSERT 操作
如下:单击事件流转换为表。当插入更多的单击流记录时,结果表将不断增长。
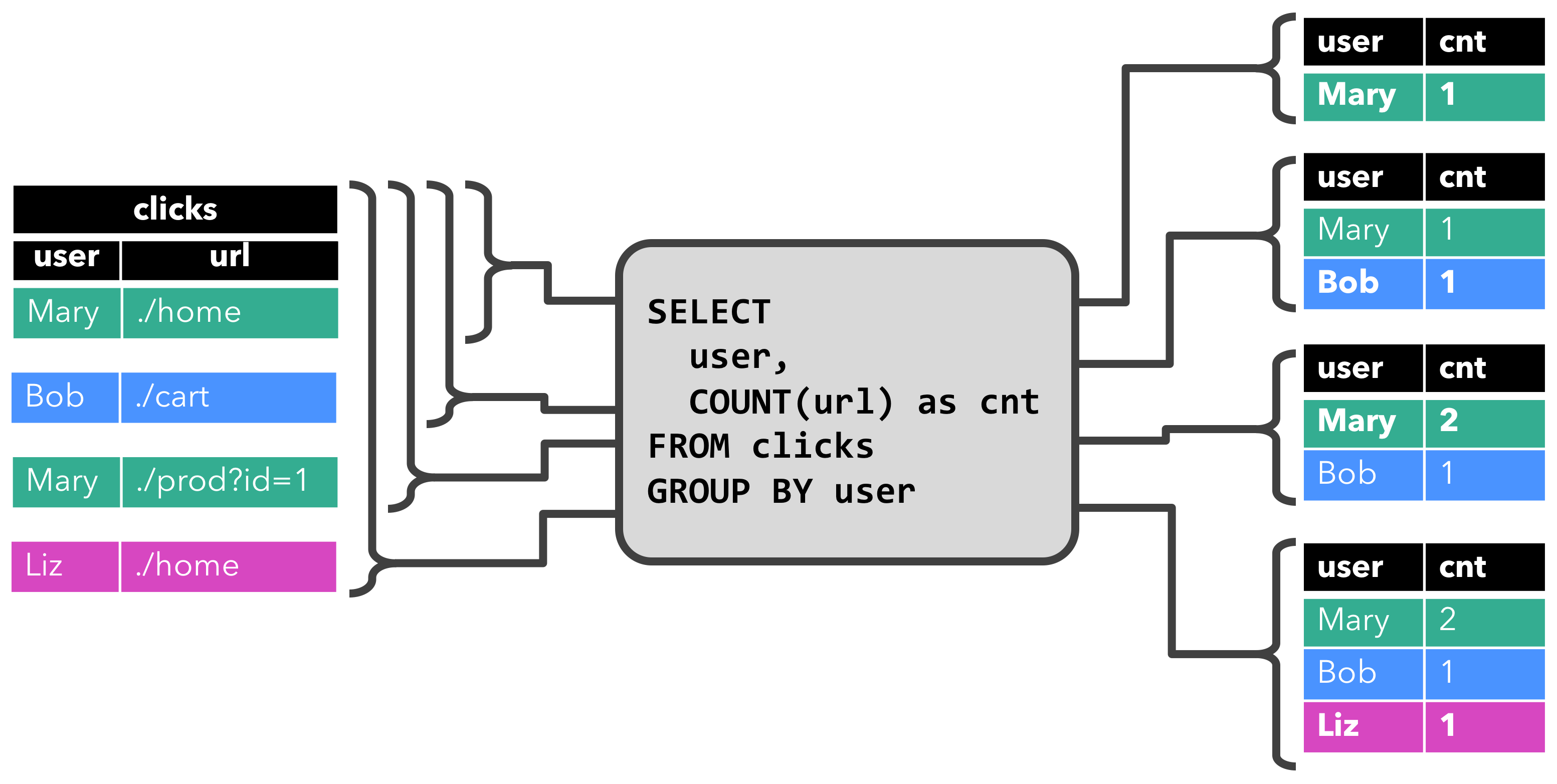
连续查询
在动态表上计算一个连续查询,并生成一个新的动态表。
与批处理查询不同,连续查询从不终止,并根据其输入表上的更新更新其结果表。
在任何时候,连续查询的结果在语义上与以批处理模式在输入表快照上执行的相同查询的结果相同。
1.更新查询
当原始动态表不停地插入新的数据时,查询得到的结果表会持续地进行更改。
这里的更改操作可以是简单的插入,也可以是对之前数据的更新。这种持续查询被称为更新查询
2.追加查询
上述查询过程用到分组聚合,结果表中就会产生更新操作。
如果执行一个简单的条件查询,结果表中就会像原始表一样,只有插入操作。
那么这样的持续查询,就被称为追加查询,它定义的结果表的更新日志流中只有INSERT操作。
将动态表转换为流
动态表可以通过插入、更新和删除操作,进行持续的更改。在将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码,通过发送编码消息的方式告诉外部系统要执行的操作。
Flink的 Table API 和 SQL 支持三种方式来编码一个动态表的变化:
1.仅追加流 Append-only
仅通过INSERT插入更改来修改的动态表,可以直接转换为仅追加流。这个流中发出的数据,其实就是动态表中新增的每一行。
2.撤回流 Retract
撤回流是包含两类消息的流,添加消息和撤回消息。
INSERT插入操作编码为add消息
DELETE删除操作编码为retract消息
UPDATE更新操作则编码为被更改行的retract消息和更新后行(新行)的add消息。
这样通过编码后的消息指明所有的增删改操作,一个动态表就可以转换为撤回流。
将动态表转换为 retract 流的过程。
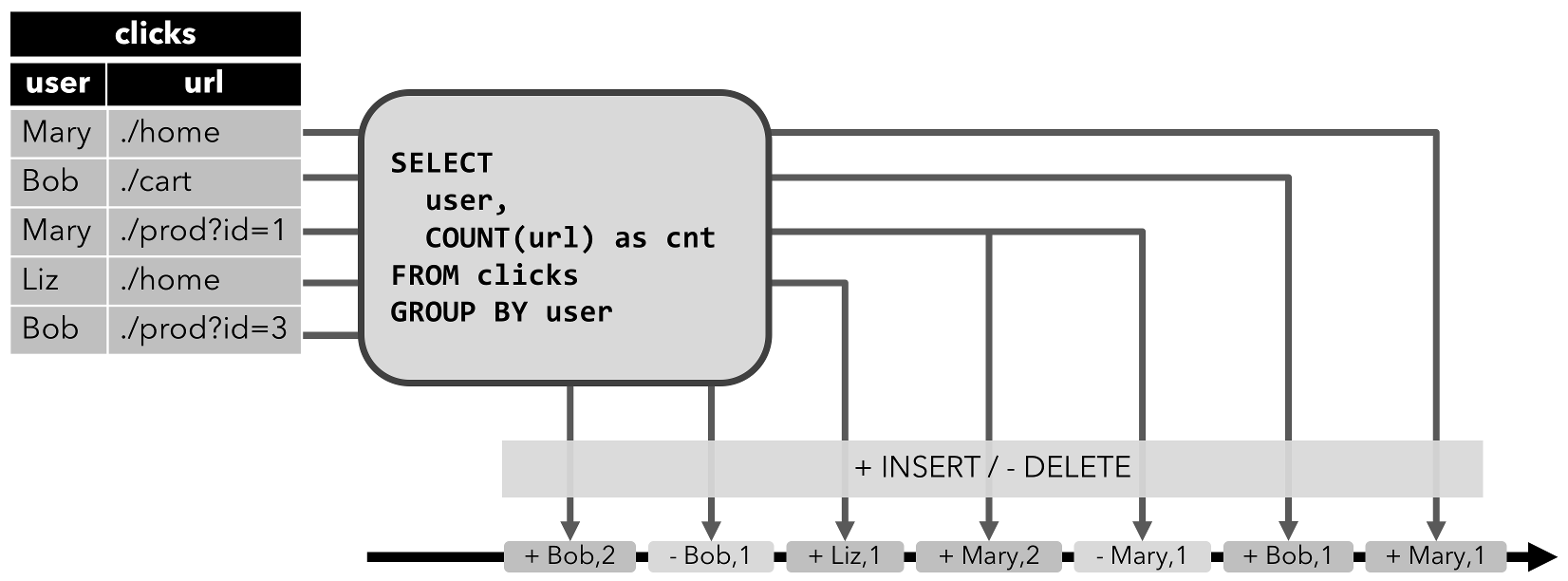
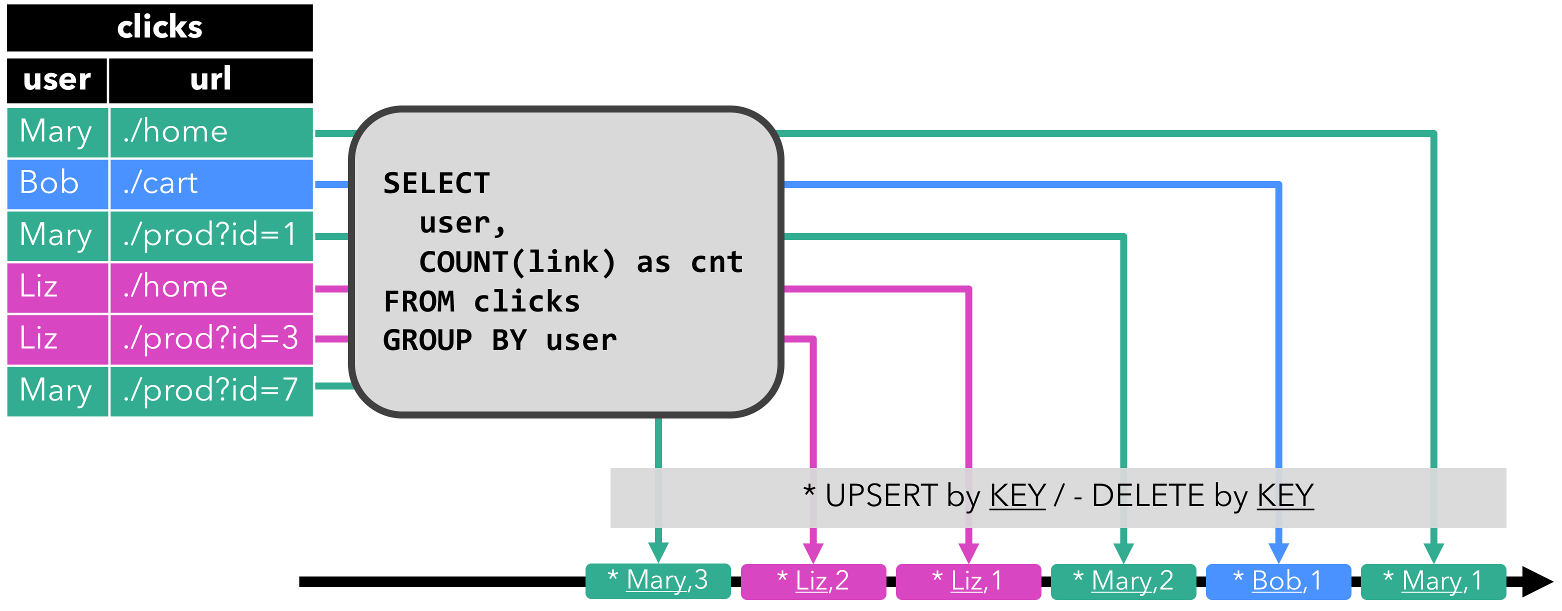
3.更新插入流 Upsert
更新插入流中只包含两种类型的消息:更新插入消息和删除消息。
对于更新插入流来说,INSERT插入操作和UPDATE更新操作,统一被编码为upsert消息,而DELETE删除操作则被编码为delete消息。
时间属性
Flink 可以基于几种不同的 时间 概念来处理数据。
处理时间 指的是执行具体操作时的机器时间
事件时间 指的是数据本身携带的时间。这个时间是在事件产生时的时间
摄入时间 指的是数据进入 Flink 的时间;在系统内部,会把它当做事件时间来处理
处理时间
处理时间是基于机器的本地时间来处理数据,它是最简单的一种时间概念,但是它不能提供确定性。它既不需要从数据里获取时间,也不需要生成 watermark。
1.在创建表的DDL中定义
处理时间属性可以在创建表的 DDL 中用计算列的方式定义,用 PROCTIME() 就可以定义处理时间,函数 PROCTIME() 的返回类型是 TIMESTAMP_LTZ 。
CREATE TABLE user_actions (
user_name STRING,
data STRING,
user_action_time AS PROCTIME() -- 声明一个额外的列作为处理时间属性
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
2.在DataStream到Table转换时定义
处理时间属性可以在 schema 定义的时候用 .proctime 后缀来定义。时间属性一定不能定义在一个已有字段上,所以它只能定义在 schema 定义的最后。
DataStream<Tuple2<String, String>> stream = ...;
// 声明一个额外的字段作为时间属性字段
Table table = tEnv.fromDataStream(stream, $("user_name"), $("data"), $("user_action_time").proctime());
WindowedTable windowedTable = table.window(
Tumble.over(lit(10).minutes())
.on($("user_action_time"))
.as("userActionWindow"));
3.使用TableSource定义
逻辑的时间属性会放在 TableSource 已有物理字段的最后
// 定义一个由处理时间属性的 table source
public class UserActionSource implements StreamTableSource<Row>, DefinedProctimeAttribute {
@Override
public TypeInformation<Row> getReturnType() {
String[] names = new String[] {"user_name" , "data"};
TypeInformation[] types = new TypeInformation[] {Types.STRING(), Types.STRING()};
return Types.ROW(names, types);
}
@Override
public DataStream<Row> getDataStream(StreamExecutionEnvironment execEnv) {
// create stream
DataStream<Row> stream = ...;
return stream;
}
@Override
public String getProctimeAttribute() {
// 这个名字的列会被追加到最后,作为第三列
return "user_action_time";
}
}
// register table source
tEnv.registerTableSource("user_actions", new UserActionSource());
WindowedTable windowedTable = tEnv
.from("user_actions")
.window(Tumble
.over(lit(10).minutes())
.on($("user_action_time"))
.as("userActionWindow"));
事件时间
事件时间允许程序按照数据中包含的时间来处理,这样可以在有乱序或者晚到的数据的情况下产生一致的处理结果。它可以保证从外部存储读取数据后产生可以复现的结果。
事件时间属性也有类似于处理时间的三种定义方式:
1.在DDL中定义
2.在DataStream到Table转换时定义
3.用TableSource定义
1.在DDL中定义
事件时间属性可以在创建表DDL中定义,增加一个字段,通过WATERMARK语句来定义事件时间属性。WATERMARK 语句在一个已有字段上定义一个 watermark 生成表达式,同时标记这个已有字段为时间属性字段。
CREATE TABLE user_actions (
user_name STRING,
data STRING,
user_action_time TIMESTAMP(3),
-- 声明 user_action_time 是事件时间属性,并且用 延迟 5 秒的策略来生成 watermark
WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
时间戳类型必须是 TIMESTAMP 或者TIMESTAMP_LTZ 类型。但是时间戳一般都是秒或者是毫秒(BIGINT 类型),这种情况可以通过如下方式转换
ts BIGINT,
time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
2.在DataStream到Table转换时定义
在从 DataStream 到 Table 转换时定义事件时间属性有两种方式。取决于用 .rowtime 后缀修饰的字段名字是否是已有字段,事件时间字段可以是:
在schema的结尾追加一个新的字段
替换一个已经存在的字段
// Option 1:
// 基于 stream 中的事件产生时间戳和 watermark
DataStream<Tuple2<String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 声明一个额外的逻辑字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user_name"), $("data"), $("user_action_time").rowtime());
// Option 2:
// 从第一个字段获取事件时间,并且产生 watermark
DataStream<Tuple3<Long, String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 第一个字段已经用作事件时间抽取了,不用再用一个新字段来表示事件时间了
Table table = tEnv.fromDataStream(stream, $("user_action_time").rowtime(), $("user_name"), $("data"));
// Usage:
WindowedTable windowedTable = table.window(Tumble
.over(lit(10).minutes())
.on($("user_action_time"))
.as("userActionWindow"));
3.使用TableSource定义
// 定义一个有事件时间属性的 table source
public class UserActionSource implements StreamTableSource<Row>, DefinedRowtimeAttributes {
@Override
public TypeInformation<Row> getReturnType() {
String[] names = new String[] {"user_name", "data", "user_action_time"};
TypeInformation[] types =
new TypeInformation[] {Types.STRING(), Types.STRING(), Types.LONG()};
return Types.ROW(names, types);
}
@Override
public DataStream<Row> getDataStream(StreamExecutionEnvironment execEnv) {
// 构造 DataStream
// ...
// 基于 "user_action_time" 定义 watermark
DataStream<Row> stream = inputStream.assignTimestampsAndWatermarks(...);
return stream;
}
@Override
public List<RowtimeAttributeDescriptor> getRowtimeAttributeDescriptors() {
// 标记 "user_action_time" 字段是事件时间字段
// 给 "user_action_time" 构造一个时间属性描述符
RowtimeAttributeDescriptor rowtimeAttrDescr = new RowtimeAttributeDescriptor(
"user_action_time",
new ExistingField("user_action_time"),
new AscendingTimestamps());
List<RowtimeAttributeDescriptor> listRowtimeAttrDescr = Collections.singletonList(rowtimeAttrDescr);
return listRowtimeAttrDescr;
}
}
// register the table source
tEnv.registerTableSource("user_actions", new UserActionSource());
WindowedTable windowedTable = tEnv
.from("user_actions")
.window(Tumble.over(lit(10).minutes()).on($("user_action_time")).as("userActionWindow"));