Hive通俗的特性
- 结构化数据文件变为数据库表
- sql查询功能
- sql语句转化为MR运行
- 建立在hadoop的数据仓库基础架构
- 使用hadoop的HDFS存储文件
- 实时性较差(应用于海量数据)
- 存储、计算能力容易拓展(源于Hadoop)
支持这些特性的架构
CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor)
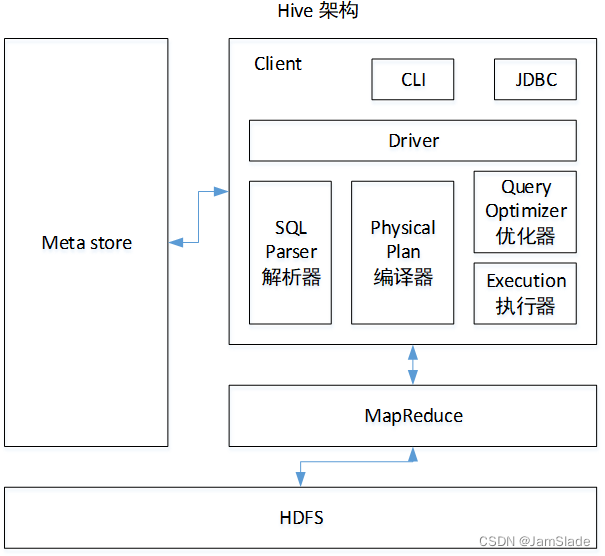
服务端
- Driver:包括了Complier、Optimizer和Executor。将Hive sql解析,编译,优化,生成执行计划
- Metastore:存储hive元数据(描述数据的数据,比如一行数据里面,单个数据的名字叫啥,类型是啥,注释是啥,以及表本身的框架) 解耦hive服务和metastore服务
- Thrift:可扩展且跨语言的服务的开发,hive集成服务支持不同编程语言调用hive的接口、
客户端
- CLI: 命令行接口
- Thrift客户端: hive架构的接口基于thrift客户端(如 JDBC, 面向java的连接; ODBC 开放数据连接)
- WEBGUI:网页访问Hive服务接口
Hive执行MR的过程
- User Interface用executeQuery接口,hql发送给Driver
- driver生成 session handle, 并发送给Compiler
- Compiler从metastore获取元数据
- 元数据检查类型后,对为此调整分区,生成计划
- Compiler生成DAG,每个stage都可能涉及M/R job, 元数据操作, HDFS文件操作
- 每个M/R中,查询结果以临时文件方式放在HDFS中,临时文件由Execution Engine从HDFS读取,作为Driver返回内容
特点
- Hive加载数据的时候不对数据检查(关系型是检查的,若加载数据不符合模式会拒绝执行,称之为写时模式),也不更改加载的数据文件,查询的时候检查数据格式(读时模式)
- 写时模式加载过程中索引,数据会压缩,加载数据较慢。数据加载好后查询较快
- 读时模式适用于数据非结构化,存储模式未知的情况
- hive不支持对特定行的操作,只支持覆盖原数据和追加数据
- hive不支持事务,索引
- hive的更新操作为:原表数据转化后存在新表
- hive支持和hbase集成,实现快速查询,但需要提供sql语法解析外壳
- hive可认为是MR的包装
Spark通俗的特性
兼容hive
组件
- SQLContext:封装spark关系型功能
- DataFrame:分布式,命名列阻止的数据集合,可转化为RDD,支持已有的RDD、结构化数据文件、JSON数据集、Hive表、外部数据库创建DF
sql运行架构
- sql语句进行解析,判断出表达式,projection,datasource等(projection可以理解为select的列的集合)
- sql语句和数据字典(列,table, view)绑定。
- 选出最优的执行计划
- 按Operation datasource result次序执行(可以不读取物理表读取缓冲池返回结果)
Hive on MR 与 SparkSql区别
两者基本相同,但sql解析器不一样(spark做了较多优化)
| Hive | spark | |
|---|---|---|
| 场景 | 离线,非实时 | 实时要求高,速度快的场景 |
| 速度 | 慢 | 快,比传统MR块10-100倍 |
表
表的元数据存储在什么地方
- 内存数据库derby,快,轻量,不稳定
- MySql数据库 持久化好
建表方式
- 直接分析
- 查询建表(通过select得到的结果生成新的表)
- like建表(无数据,结构一致)
表的分类
内部表,外部表
默认创建内部表,创建外部表,需要加上external关键字修饰,还可通过location指定Hive仓库的路径
区别
| 内部表 | 外部表 | |
|---|---|---|
| drop | 删除元数据和文件 | 只删除元数据 |
| load | 数据移动到指定路径 | 不移动到数据仓库目录下 |
优先使用外部表
- 不删除数据,方便数据恢复
- 不加载数据到hive,减少数据传输
- 不对HDFS数据修改
数据处理都用hql完成的话,选择内部表