论文标题: Scalable diffusion models with transformers
论文链接:https://openaccess.thecvf.com/content/ICCV2023/html/Peebles_Scalable_Diffusion_Models_with_Transformers_ICCV_2023_paper.html
代码:https://github.com/facebookresearch/DiT/blob/main/README.md

引用:Peebles W, Xie S. Scalable diffusion models with transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 4195-4205.
导读
本文探索了一种基于 transformer 体系结构的新型扩散模型。作者使用Transformer来训练图像的潜在扩散模型,取代了通常使用的U-Net骨干网络,这个Transformer操作在潜在图像块上。研究还分析了这种新模型的可伸缩性,通过Gflops(每秒十亿次浮点运算)来衡量前向传播复杂性。研究发现,具有更高Gflops的Diffusion Transformers(DiTs)——通过增加Transformer的深度/宽度或增加输入标记的数量——通常具有更低的FID(Frechet Inception Distance)。此外,研究中最大的DiT-XL/2模型在类别条件的ImageNet 512x512和256x256基准上表现出色,取得了后者的最先进 FID 成绩为2.27。
本文贡献
提出了一种新的扩散模型架构,称之为Diffusion Transformers(DiTs)。这一架构基于Transformers,用于图像生成任务。
研究表明,传统的扩散模型架构中常用的U-Net骨干并不是性能的关键因素。他们成功地将U-Net替换为标准的Transformer架构,这意味着扩散模型可以采用更通用的设计,如Transformers,而不受限于特定的架构。
通过使用DiTs架构,研究者在 ImageNet 生成基准上实现了显著的性能提升,将FID(Frechet Inception Distance)降低到2.27,达到了最新的最先进水平。
预备知识
扩散模型的基本理论
高斯扩散模型假设了一个前向噪声过程,并逐渐将噪声应用于真实数据:
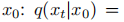
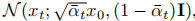
通过应用重新参数化的技巧,我们可以进行采样:
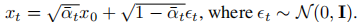
扩散模型的训练是为了学习反向过程,即将前向过程中的损坏恢复成原始数据的过程:
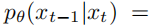
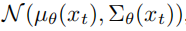
训练反向过程模型时,使用了变分下界(variational lower bound)来估计x0的对数似然:
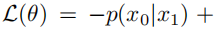
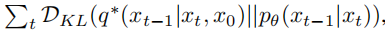
通过将µθ重新参数化为噪声预测网络 εθ,该模型可以使用预测噪声
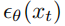
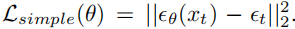
但是,为了用学习到的反向过程协方差
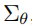
无分类器引导
条件扩散模型将额外信息作为输入,如类别标签c。在这种情况下,反向过程变为:
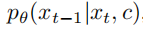
在这种情况下,可以使用无分类器的指导来鼓励采样程序找到x,从而使 log p(c|x) 变高。根据贝叶斯规则:
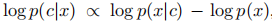
因此,
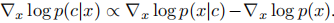
所以在想要条件的概率较大,就可以将条件的梯度增加到优化目标里,最终可以表示成如下形式:
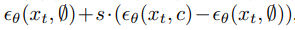
无分类器引导已被广泛认为能够显著提高样本生成的质量,而这一趋势在DiTs模型中同样有效。
潜在扩散模型(Latent diffusion models)
直接在高分辨率像素空间中训练扩散模型在计算上是代价高昂的。潜在扩散模型(LDMs)通过一个两阶段的方法来解决这一问题:首先,学习一个自编码器,将图像压缩为具有学习编码器E的较小空间表示;其次,训练表示z = E(x)的扩散模型,而不是图像x的扩散模型(E是冻结的)。然后,可以通过从扩散模型中采样表示z,然后使用学习的解码器进行解码,生成新的图像x = D(z)。如图2所示,潜在扩散模型在使用像ADM这样的像素空间扩散模型的Gflops的一小部分的情况下实现了良好的性能。因为作者关注计算效率,这使得它们成为架构探索的吸引人的起点。

本文方法
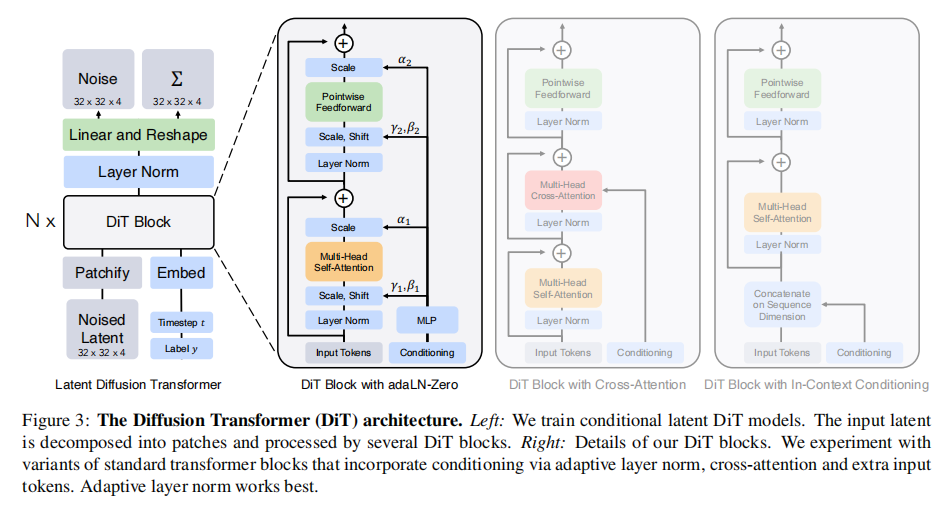
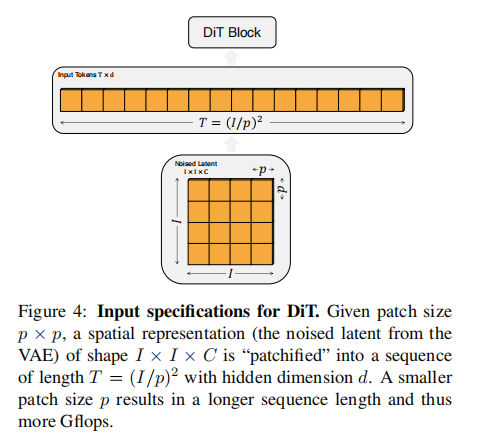
Patchify: DiT的输入是一个空间表示z(对于256x256x3的图像,z的形状为32x32x4)。DiT的第一层是“patchify”,它通过线性嵌入输入中的每个图像块,将空间输入转换为T个维度为d的标记序列。随后,我们对所有输入标记应用标准的ViT基于频率的位置嵌入(正弦-余弦版本)。通过patchify创建的标记数量T由补丁大小的超参数p确定。
如图4所示,将p减半会使T增加四倍,从而至少使总的Transformer Gflops增加四倍。尽管对Gflops有显著影响,但需要注意的是,更改p对下游参数数量没有实际影响。
作者将p设置为2、4和8。
DiT块设计:在经过patchify之后,输入标记由一系列Transformer块进行处理。除了噪声图像输入,扩散模型有时还处理额外的条件信息,如噪声时间步t、类别标签c、自然语言等。研究者探索了四种不同处理条件输入的Transformer块变体。这些设计对标准的ViT块设计进行了小而重要的修改。所有块的设计都在图3中显示(经过实验分析最终作者选择了adaLN块)。下面介绍这四种块。
In-context Conditioning:这种方法简单地将t和c的向量嵌入作为两个额外的标记附加在输入序列中,对待它们与图像标记没有区别。这类似于ViTs中的cls标记,它允许我们在不进行修改的情况下使用标准的ViT块。在最后一个块之后,将条件化标记从序列中删除。这种方法对模型引入了几乎可以忽略的新Gflops开销。
Cross-Attention Block:这种方法将t和c的嵌入连接成一个长度为 2 的序列,与图像标记序列分开。Transformer块进行了修改,包括多头自注意力块之后的多头跨注意力层,跨注意力块为模型添加的Gflops最多,大约增加了15%的开销。
Adaptive Layer Norm (adaLN) Block:这种方法基于GANs和具有UNet骨干的扩散模型中广泛使用的自适应标准化层,将Transformer块中的标准规范层替换为自适应规范(adaLN)。与直接学习γ和β等参数不同,它们从t和c的嵌入向量之和中回归得出。在作者研究的三种块设计中,adaLN添加的Gflops最少,因此计算效率最高。这也是唯一一种将相同函数应用于所有标记的条件化机制。
adaLN-Zero Block:之前的研究发现,将每个残差块初始化为恒等函数是有益的。为了实现这一目标,作者探索了adaLN DiT块的修改版本,该版本与之前类似。除了回归γ和β,他们还回归了应用于DiT块内的任何残差连接之前的维度缩放参数α。他们将MLP初始化为对所有α输出零向量,从而将整个DiT块初始化为恒等函数。与普通的adaLN块一样,adaLN-Zero对模型添加的Gflops几乎可以忽略不计。
Transformer decoder:在DiT架构的最后一个DiT块之后,需要将图像标记序列解码为输出的噪声预测和对角协方差预测。这两个输出的形状与原始的空间输入相同。为了实现这一目标,作者使用了标准的线性解码器,将最后的层规范(如果使用adaLN,则为自适应)应用于每个标记,并线性解码为一个p x p x 2C张量,其中C是DiT输入中的通道数。最后,将解码后的标记重新排列成原始的空间布局,得到了噪声和协方差的预测。
实验
实验结果
不同扩散模型的效果对比如下:
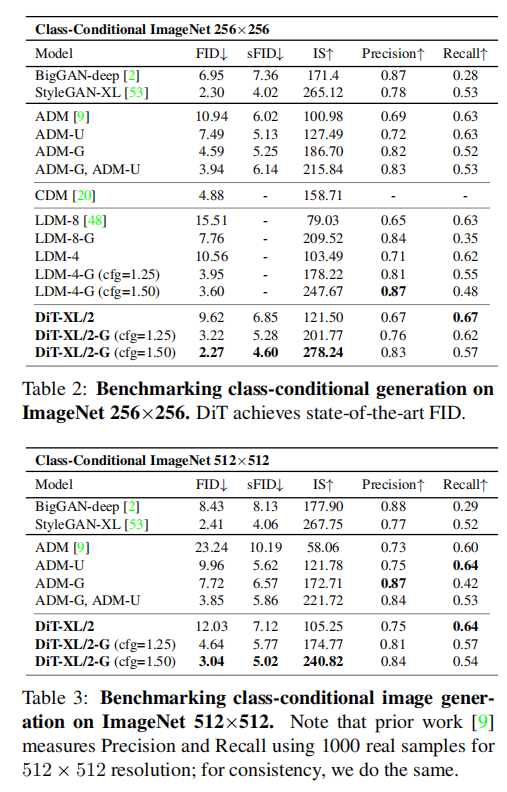
从下图可以看出adaLN-Zero方法明显好于cross-attention和in-contenxt,所以实验中均采用adaLN-Zero方法进行上下文交互:
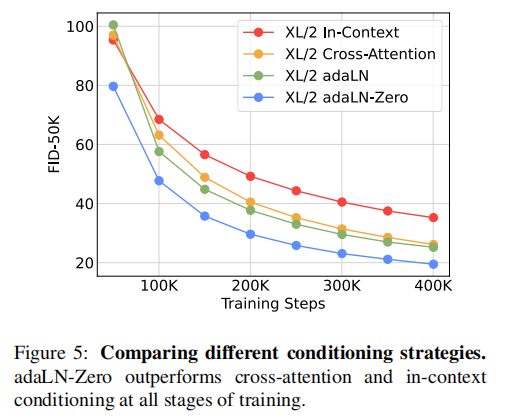
缩放DiT模型可以提高训练的所有阶段的FID:
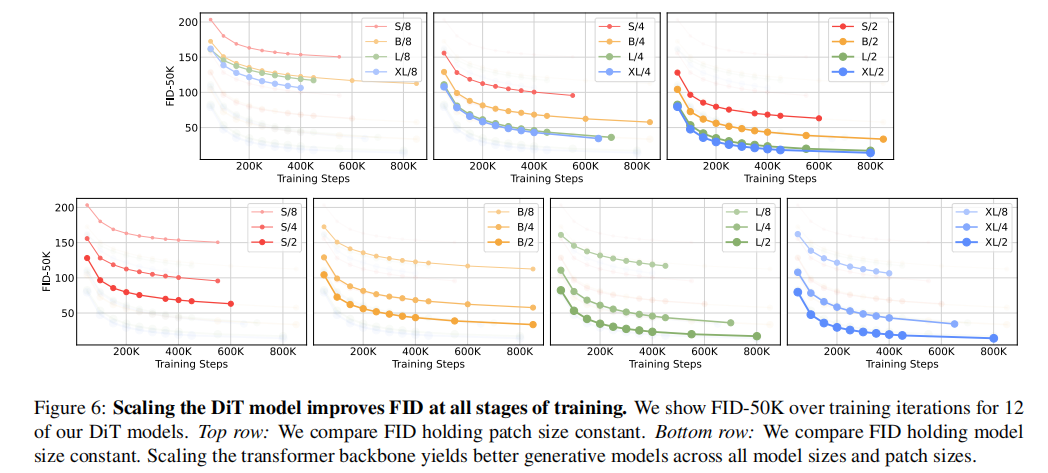
模型越大、patch size越小生成图像质量越好:

结论
文章提出DiTs结构进行扩散模型图像生成,在Gflops与Stable Diffusion相当的DiTs-XL/2的结构上,把ImageNet 256×256数据集上的FID指标优化到了2.27,达到了SOTA的水平。未来将进一步探索更大的DiTs模型和token数量。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓