fastspar
简介
fastspar是基于Sparcc通过C编写的,速度更快,内存消耗更少。sparcc是基于OTU的原始count数,通过log转换和标准化去除传统相对丰度的天然负相关(因为所有OTU之和为1,某些OTU丰度高另外一些自然就少,导致最后出现正相关少负相关多的假象)。
FastSpar是SparCC算法的C++实现,比原来的Python2版本快几千倍,并且使用的内存少得多。FastSpar的实现提供了线程支持和一个P值估计器,该估计器考虑了重复数据排列的可能性(进一步的细节见本文)。
FastSpar目前正在开发中,可能缺乏完整程序中预期的某些功能。虽然FastSpar的工作一般没有问题,但必须特别注意确保提供正确格式的输入数据。
安装
Conda
To install through conda, use:
conda install -c bioconda -c conda-forge fastspar
使用
1.相关性推断
要运行FastSpar,你必须有BIOM tsv格式文件(没有元数据)中的绝对OTU计数。fake_data.tsv(来自最初的SparCC实现)将作为一个例子。
- 输入文件:fake_data.tsv(fastspar/tests/data/fake_data.tsv,63k):制表符分隔,行为OTU,列为样本号
- header(
第一行第一列一定是#OTU ID,否则报错)


计算相关性
(base) [yutao@myosin data]$ mkdir out; time fastspar --otu_table fake_data.tsv --correlation out/median_correlation.tsv --covariance out/median_covariance.tsv -t 30 &>1.log&
# 耗时2.4s
# -t <int>, --threads <int> Number of threads (default: 1)
-c <path>, --otu_table <path>
OTU input OTU count table
-r <path>, -correlation <path>
Correlation output table
-a <path>, --covariance <path>
Covariance output table
-i <int>, --iterations <int>
Number of interations to perform (default: 50)
- median_correlation.tsv
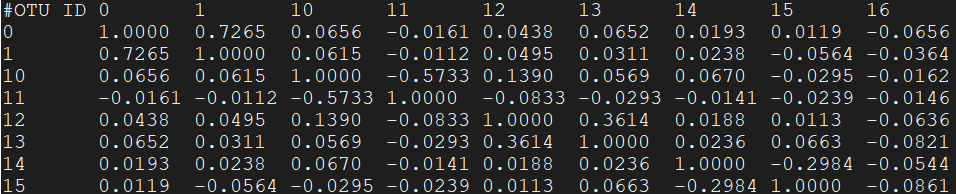
结果是一个相关系数对称矩阵,对角线是自身的相关系数为1,其他例如1行2列表示OTU0 vs OTU1相关系数为0.7265 - median_covariance.tsv

迭代次数(SparCC相关性估计的轮次)和排除迭代次数(发现和排除高度相关的OTU对的次数)也可以进行调整。
fastspar --iterations 50 --exclude_iterations 20 --otu_table tests/data/fake_data.tsv --correlation median_correlation.tsv --covariance median_covariance.tsv
进一步,可以增加排除相关OTU对的最小阈值
fastspar --threshold 0.2 --otu_table tests/data/fake_data.tsv --correlation median_correlation.tsv --covariance median_covariance.tsv
2.精确P值的计算
有几种方法可以计算推断出的相关关系的p值。在这里,我们选择使用基于稳健互换的方法。这个过程包括从原始OTU计数数据的随机排列中推断出相关关系。每个p值的大小与随机排列的数据中观察到的更极端的相关性的频率有关。在下面的例子中,我们从1000个自举相关性中计算出p值。
1.首先我们生成1000个自举计数。
mkdir bootstrap_counts
(base) [yutao@myosin data]$ mkdir bootstrap_counts; fastspar_bootstrap --otu_table tests/data/fake_data.tsv --number 1000 --prefix bootstrap_counts/fake_data
# 耗时1s
# --number 迭代次数
# -t 线程
- 会在out下生成1000个重抽样列表
(base) [yutao@myosin data]$ ls out/
fake_data_0.tsv fake_data_326.tsv fake_data_552.tsv fake_data_779.tsv
fake_data_100.tsv fake_data_327.tsv fake_data_553.tsv fake_data_77.tsv
fake_data_101.tsv fake_data_328.tsv fake_data_554.tsv fake_data_780.tsv
fake_data_102.tsv fake_data_329.tsv fake_data_555.tsv fake_data_781.tsv
2.然后推断每个自举计数的相关性(在所有可用进程中并行运行)。
这里使用parallel进行并行计算
mkdir bootstrap_correlation
parallel fastspar --otu_table {} --correlation bootstrap_correlation/cor_{/} --covariance bootstrap_correlation/cov_{/} -i 5 ::: bootstrap_counts/*
# 1000次计算耗时14s
# bootstrap_correlation/cor_{/},bootstrap_correlation/cov_{/} 表示输出文件名是cor_,cov_加输入文件名
(base) [yutao@myosin data]$ ls bootstrap_correlation
cor_fake_data_0.tsv cor_fake_data_701.tsv cov_fake_data_400.tsv
cor_fake_data_100.tsv cor_fake_data_702.tsv cov_fake_data_401.tsv
cor_fake_data_101.tsv cor_fake_data_703.tsv cov_fake_data_402.tsv
cor_fake_data_102.tsv cor_fake_data_704.tsv cov_fake_data_403.tsv
cor_fake_data_103.tsv cor_fake_data_705.tsv cov_fake_data_404.tsv
cor_fake_data_104.tsv cor_fake_data_706.tsv cov_fake_data_405.tsv
cor_fake_data_105.tsv cor_fake_data_707.tsv cov_fake_data_406.tsv
- 注意,此步骤需要有足够的存储,1278 * 85(大小400k)的矩阵产生了24G的中间结果
3.根据这些相关性,然后计算出p值
fastspar_pvalues --otu_table tests/data/fake_data.tsv --correlation median_correlation.tsv --prefix bootstrap_correlation/cor_fake_data_ --permutations 1000 --outfile pvalues.tsv
# 耗时2s
-c/--otu_table <path>
OTU input table used to generated correlations
-r/--correlation <path>
Correlation table generated by FastSpar
-p/--prefix <str>
Prefix output of bootstrap output files
-n/--permutations <int>
Number of permutations/ bootstraps
-o/--outfile <path>
Output p-value matrix filename
线程
如果FastSpar是用OpenMP编译的,线程可以通过在命令行中调用–threads <thread_number>来使用几个工具。
fastspar --otu_table tests/data/fake_data.txt --correlation median_correlation.tsv --covariance median_covariance.tsv --iterations 50 --threads 10
解析成长表
# ++++++++++++++++++++++++++++
# flattenCorrMatrix
# ++++++++++++++++++++++++++++
# cormat : matrix of the correlation coefficients
# pmat : matrix of the correlation p-values
library(Hmisc) # 生成相关性/P-value矩阵,测试使用
library(dplyr) # 合并数据
setwd("C:/北大真菌细菌互作/互作")
tax <- read.table('Taxonomy_info.txt', header = T)
# 解析两个对角线矩阵,cormat是fastspac的相关性矩阵,pmat是fastspac的p-value矩阵
flattenCorrMatrix <- function(cormat, pmat){
ut <- upper.tri(cormat)
data.frame( row = rownames(cormat)[row(cormat)[ut]],
column = rownames(cormat)[col(cormat)[ut]], cor =(cormat)[ut], p = pmat[ut] )
}
r <- read.table('median_correlation.tsv', header = T, row.names = 1,
check.names = F, comment.char = "", sep = "\t") #忽略注释字符
View(head(r))
pv <- read.table('pvalues.tsv', header = T, row.names = 1,
check.names = F, comment.char = "", sep = "\t") #忽略注释字符
View(head(pv))
res <- flattenCorrMatrix(r, pv)
View(head(res))
write.table(res, 'Correlation_result.tsv', quote = F)
dim(res)
filter <- subset(res, res$p < 0.05)
dim(filter)
# 添加分组信息
View(head(tax))
r1 <- left_join(filter, tax, by = c('row' = 'ID'))
r1 <- left_join(r1, tax, by = c('column' = 'ID'))
# 添加互作类型
r1$Type <- 'null'
r1$Type[r1$Kingdom.x == "Fungi" & r1$Kingdom.y == "Fungi"] <- "FF"
r1$Type[r1$Kingdom.x == "Bacteria" & r1$Kingdom.y == "Bacteria"] <- "BB"
r1$Type[r1$Kingdom.x == "Fungi" & r1$Kingdom.y == "Bacteria"] <- "FB"
r1$Type[r1$Kingdom.x == "Bacteria" & r1$Kingdom.y == "Fungi"] <- "FB"
# 保留细菌vs真菌
write.table(r1, 'All_Correlation_result.tsv', quote = F, sep = "\t")
data <- read.table('Bacteria_and_fungi_for_sparcc.tsv', header = T, row.names = 1,
comment.char = "", sep = '\t' )
cor.test(as.matrix(data[1,]), as.matrix(data[2760,]), method = 'spearman')
#举个栗子
# res3 <- rcorr(as.matrix(mtcars[,1:7]))
# res <- flattenCorrMatrix(res3$r, res3$P)
报错
- error while loading shared libraries: libmkl_rt.so
(base) [yutao@myosin data]$ fastspar_bootstrap --help
fastspar_bootstrap: error while loading shared libraries: libmkl_rt.so: cannot open shared object file: No such file or directory
解决
(base) [yutao@myosin data]$ conda install -c intel mkl
- libc++abi: terminating with uncaught exception of type std::invalid_argument: stof: no conversion;Abort trap: 6
要求输入的OTU表格为数值数据,除首行和首列外,其他均为数值,不能出现NA,对输入的大表数据可以先通过数据筛选确认符合上述情况。
Citation
fastspac github
If you use this tool, please cite the FastSpar paper and original SparCC paper:
Watts, S. C., Ritchie, S. C., Inouye, M., & Holt, K. E. (2018). FastSpar: rapid and scalable correlation estimation for compositional data. Bioinformatics. doi: 10.1093/bioinformatics/bty734
Friedman, J. & Alm, E.J. (2017). Inferring correlation networks from genomic survey data. PLoS Comput. Biol. 8, e1002687.