目录
1、Http 工具类
2、关于下载的关系类
2.1 展示下载信息
#下载信息展现线程类
#在主下载类中,进行调用上述线程类
2.2 文件的分块下载
#文件分块下载类
#文件按分块进行分别切分的方法
# 使用 LongAdder 类型,更改 DownLoadInfoThread 展现下载信息类
2.3 文件的合并以及临时文件的清除
#文件的合并
#临时文件的清除
#在主下载类中调用上述方法

前言:
一般都是在浏览器中进行点击即下载,这次使用代码结合多线程实现文件的下载操作
1、Http 工具类
在获取 HttpURLConnection 对象方法中,我们通过浏览器访问某个网站的时候,会将当前浏览器的版本,操作系统版本等信息的标识发送到网站所在的服务器中;所以当用程序代码去访问网站时,需要将自定义的标识发送过去
@Slf4j
public class HttpUtil {
/**
* 分块下载
* @param url 下载地址
* @param startPos 下载文件起始位置
* @param endPos 下载文件的结束位置
*/
public static HttpURLConnection getHttpURLConnection(String url, long startPos, long endPos) throws IOException {
HttpURLConnection httpURLConnection = getHttpURLConnection(url);
log.info("下载的区间是:{}-{}",startPos,endPos);
if (endPos != 0) {
httpURLConnection.setRequestProperty("RANGE","bytes="+startPos + "-" + endPos);
}else {
httpURLConnection.setRequestProperty("RANGE","bytes="+startPos + "-");
}
return httpURLConnection;
}
/**
* 获取 HttpURLConnection 连接对象
*/
public static HttpURLConnection getHttpURLConnection(String url) throws IOException {
URL httpUrl = new URL(url);
HttpURLConnection openConnection = (HttpURLConnection)httpUrl.openConnection(); //建立连接
//向文件所在服务器发送标识
openConnection.setRequestProperty("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1");
return openConnection;
}
/**
* 获取下载文件的名称
*/
public static String getHttpFileName(String url){
int index = url.lastIndexOf("/"); //获取文件路径中最后一个 “/”
return url.substring(index + 1);
}
/**
* 获取下载文件的大小
*/
public static long getHttpFileContentLength(String url) throws IOException{
int fileContentLength;
HttpURLConnection httpURLConnection = null;
try {
httpURLConnection = getHttpURLConnection(url);
fileContentLength = httpURLConnection.getContentLength();
}finally {
//释放资源
if(httpURLConnection!=null){
httpURLConnection.disconnect();
}
}
return fileContentLength;
}
}
2、关于下载的关系类
首先,我们先通过 IO 流 的方式进行文件下载操作
这里使用 try -- with -- resource 的形式进行文件的流输入输出,其特点就是在 try 中进行流操作后,后面不用进行 .close() 手动进行关闭,它会自动关闭流
public void my_DownLoad(String url) {
//1.获取文件名
String fileName = HttpUtil.getHttpFileName(url);
//2.与下载目录地址进行拼接,获取当前文件目标下载路径
String downLoadPath = Constant.DOWNLOAD_PATH + fileName;
//3.获取连接对象
HttpURLConnection httpURLConnection = null;
try {
httpURLConnection = HttpUtil.getHttpURLConnection(url);
} catch (IOException e) {
throw new RuntimeException(e);
}
//4.将文件读入内存中 【这里使用的是 try - with - resource 的形式】
try (
InputStream inputStream = httpURLConnection.getInputStream();
BufferedInputStream bis = new BufferedInputStream(inputStream);
FileOutputStream outputStream = new FileOutputStream(downLoadPath);
BufferedOutputStream bos = new BufferedOutputStream(outputStream)
){
//4.1 从连接对象中获取下载信息资源,将其下载到目标路径
int len = -1;
while ((len = bis.read())!=-1){
bos.write(len);
}
System.out.println("当前文件:<"+ fileName + "> ------【下载成功】, 下载目标地址:<" + downLoadPath + ">");
}catch (FileNotFoundException e){
log.error("下载的文件不存在{}",url);
} catch (Exception e) {
log.error("下载文件失败");
}finally {
if(httpURLConnection!=null) {
//释放连接资源
httpURLConnection.disconnect();
}
}
}
下载运行结果:

现在这样下载的效果不是很好,一般下载都会展现文件的下载速度或者文件大小等
这里可以每隔一段时间来获取文件的下载信息,比如间隔1秒获取一次,然后将信息打印到控制台;同时,文件下载是一个独立的线程,另外还需要再开启一个线程来间隔获取文件的信息java.util.concurrent. ScheduledExecutorService 类可以帮助我们来实现此功能
2.1 展示下载信息
-
#下载信息展现线程类
这里是定义的相关属性
//下载文件的总大小
private long httpFileContentLength;
//本次积累下载的大小
public volatile double downSize; //一个线程改,一个线程读 (本次积累下载减去前一次下载的大小,就等于这一秒内的下载速率)
//前一次或多次下载的大小
public double prevSize;
其中,downSize 使用 volatile 关键字进行修饰,其作用是确保多个线程能够正确地处理被修饰的变量
主要有两个方面的作用:
可见性:
volatile保证被修饰的变量对所有线程可见。当一个线程修改了volatile变量的值,这个变化对其他线程是立刻可见的。这有助于解决了线程之间的可见性问题,确保线程之间能够及时地感知到变量的更新。没有volatile修饰的变量,可能会被线程本地缓存,导致一个线程对变量的修改不会立即反映到其他线程中禁止指令重排序:
volatile修饰的变量,禁止编译器和处理器对其进行重排序。这确保了在访问volatile变量时,指令的执行顺序是固定的,不会出现意外的重排序导致的线程安全问题
在下载文件时显示剩余文件下载时间,有时可能会出现显示无限大的情况,这通常是因为在计算剩余下载时间时出现了问题或者没有足够的信息来进行准确的计算
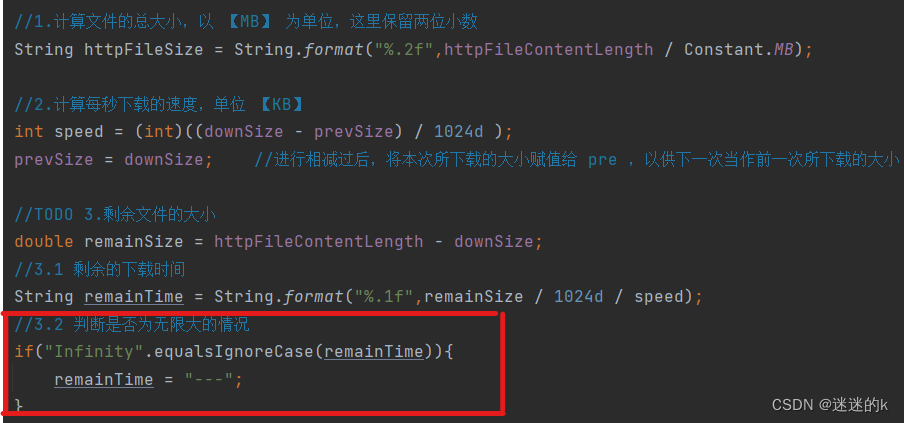
以下是一些可能导致显示无限大的原因:
不完整的数据: 如果你在下载文件的过程中无法获得文件的总大小(Content-Length),那么计算剩余下载时间就会变得困难;通常,剩余下载时间是通过已下载的数据量与总文件大小以及下载速度来计算的;如果缺少总文件大小的信息,就无法进行准确的计算
下载速度为零: 如果下载速度为零,计算剩余下载时间将导致除以零的操作,结果是无限大;这可能发生在下载速度非常慢或网络连接出现问题的情况下
不稳定的下载速度: 如果下载速度波动非常大,或者在某些时间段内下载速度为零,那么计算剩余下载时间可能会非常不准确;下载速度的不稳定性会影响计算的准确性
软件问题: 有时,显示剩余下载时间的软件可能存在bug或问题,导致不正确的计算
完整代码:
public class DownLoadInfoThread implements Runnable{
//下载文件的总大小
private long httpFileContentLength;
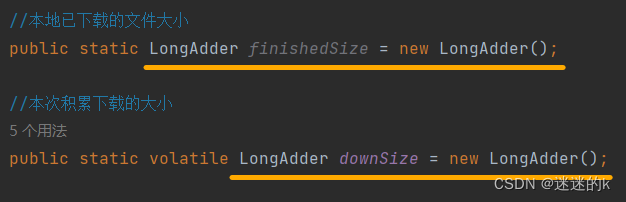
//本地已下载的文件大小
public static double finishedSize;
//本次积累下载的大小
public static double downSize; //一个线程改,一个线程读 (本次积累下载减去前一次下载的大小,就等于这一秒内的下载速率)
//前一次或多次下载的大小
public double prevSize;
public DownLoadInfoThread(Long httpFileContentLength) {
this.httpFileContentLength = httpFileContentLength;
}
@Override
public void run() {
//1.计算文件的总大小,以 【MB】 为单位,这里保留两位小数
String httpFileSize = String.format("%.2f",httpFileContentLength / Constant.MB);
//2.计算每秒下载的速度,单位 【KB】
int speed = (int)((downSize.doubleValue() - prevSize) / 1024d );
prevSize = downSize.doubleValue(); //进行相减过后,将本次所下载的大小赋值给 pre ,以供下一次当作前一次所下载的大小
//TODO 3.剩余文件的大小
double remainSize = httpFileContentLength - downSize.doubleValue();
//3.1 剩余的下载时间
String remainTime = String.format("%.1f",remainSize / 1024d / speed);
//3.2 判断是否为无限大的情况
if("Infinity".equalsIgnoreCase(remainTime)){
remainTime = "---";
}
//TODO 4.已下载的文件大小
String alreadyDownloadFileSize = String.format("%.2f", (downSize.doubleValue())/ Constant.MB);
String downInfo = String.format("已下载 %smb/%smb,速度 %skb/s,剩余时间 %ss", //下载信息
alreadyDownloadFileSize, httpFileSize, speed, remainTime);
System.out.print("\r");
System.out.print(downInfo);
}
}
-
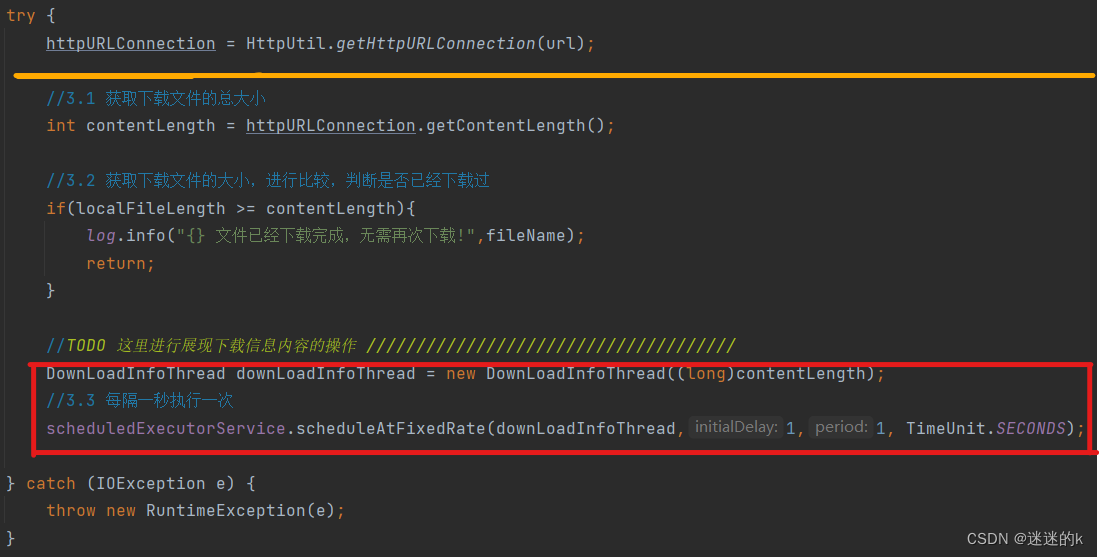
#在主下载类中,进行调用上述线程类
使用 ScheduledExecutorService 线程类 传入线程方法 FownLoadInfoThread 进行展示:
这里是 ScheduledExecutorService 线程类 的三种常用方法:
- schedule方法
该方法是重载的,这两个重载的方法都是有3个形参,只是第一个形参不同。
- Runnable / Callable<V> 可以传入这两个类型的任务
- long delay 时间数量
- TimeUnit unit 时间单位
该方法的作用是让任务按照指定的时间延时执行
- scheduleAtFixedRate方法
该方法的作用是按照指定的时间延时执行,并且每隔一段时间再继续执行
- Runnable command 执行的任务
- long initialDelay 延时的时间数量
- long period 间隔的时间数量
- TimeUnit unit 时间单位
倘若在执行任务的时候,耗时超过了间隔时间,则任务执行结束之后直接再次执行,而不是再等待间隔时间执行
- scheduleWithFixedDelay方法
该方法的作用是按照指定的时间延时执行,并且每隔一段时间再继续执行
- Runnable command 执行的任务
- long initialDelay 延时的时间数量
- long period 间隔的时间数量
- TimeUnit unit 时间单位
在执行任务的时候,无论耗时多久,任务执行结束之后都会等待间隔时间之后再继续下次任务
完整代码:
//...
public ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1); //启动一个线程
public void my_DownLoad(String url) {
//1.获取文件名
String fileName = HttpUtil.getHttpFileName(url);
//2.与下载目录地址进行拼接,获取当前文件目标下载路径
String downLoadPath = Constant.DOWNLOAD_PATH + fileName;
//获取本地磁盘中文件的下载大小
long localFileLength = FileUtils.getFileContentLength(downLoadPath);
//3.获取连接对象
HttpURLConnection httpURLConnection = null;
DownLoadInfoThread downLoadInfoThread = null;
try {
httpURLConnection = HttpUtil.getHttpURLConnection(url);
//3.1 获取下载文件的总大小
int contentLength = httpURLConnection.getContentLength();
//3.2 获取下载文件的大小,进行比较,判断是否已经下载过
if(localFileLength >= contentLength){
log.info("{} >>> 文件已经下载完成,无需再次下载!",fileName);
return;
}
//TODO 这里进行展现下载信息内容的操作 /
downLoadInfoThread = new DownLoadInfoThread((long)contentLength);
//3.3 每隔一秒执行一次
scheduledExecutorService.scheduleAtFixedRate(downLoadInfoThread,1,1, TimeUnit.SECONDS);
} catch (IOException e) {
throw new RuntimeException(e);
}
//4.将文件读入内存中 【这里使用的是 try - with - resource 的形式】
try (
InputStream inputStream = httpURLConnection.getInputStream();
BufferedInputStream bis = new BufferedInputStream(inputStream);
FileOutputStream outputStream = new FileOutputStream(downLoadPath);
BufferedOutputStream bos = new BufferedOutputStream(outputStream)
){
//4.1 从连接对象中获取下载信息资源,将其下载到目标路径
int len = -1;
byte[] bytes = new byte[Constant.BYTE_SIZE]; //防止 BufferedOutputStream 中的字节长度不够用
while ((len = bis.read(bytes))!=-1){
downLoadInfoThread.downSize += len; //为展现信息线程类中的【本次已下载的文件大小属性】赋值
bos.write(bytes,0,len);
}
}catch (FileNotFoundException e){
log.error("下载的文件不存在{}",url);
} catch (Exception e) {
log.error("下载文件失败");
}finally {
System.out.println("当前文件:<"+ fileName + "> ------【下载成功】, 下载目标地址:<" + downLoadPath + ">");
if(httpURLConnection!=null) {
//释放连接资源
httpURLConnection.disconnect();
}
//释放【展现下载信息的线程】资源
scheduledExecutorService.shutdownNow();
}
}
//...
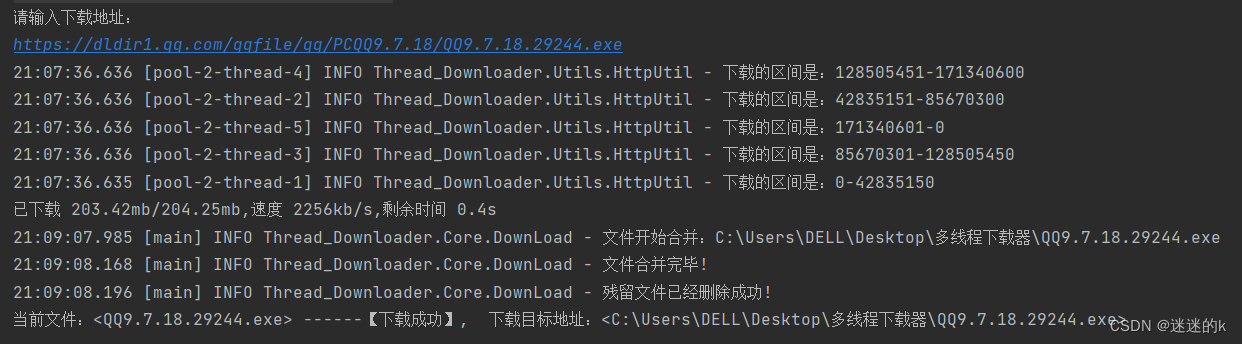
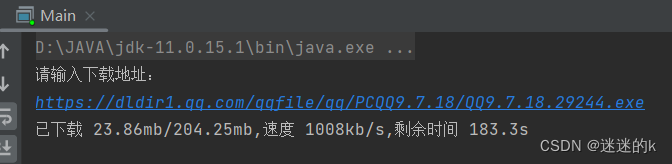
运行效果:
可见,效果给别人的感觉就是清晰明了(当然,这是实时动态的显示)
2.2 文件的分块下载
定义:文件分块下载有助于提高下载效率、降低成本,提供更好的用户体验,并增加网络资源的有效利用;这使其成为大型文件传输和分发的常见选择
基本思路:先将需要下载的文件进行切分 >>> 然后进行分块下载 >>> 最后将分好的块进行合并
#文件分块下载类
选择继承 Callable 接口的原因:
Callable接口通常与Future接口一起使用;Future接口表示一个未来可能完成的任务,并提供方法来检查任务的执行状态、取消任 务的执行以及获取任务的执行结果;通过Callable和Future的结合使用,可以实现异步执行任务,并在需要时获取任务的执行结果多线程编程:
Callable接口通常用于多线程编程,允许将任务提交给线程池或执行器框架,以并行执行多个任务。这可以提高程序的性能和响应性,特别是在需要执行耗时任务时
完整代码:
@Slf4j
public class DownLoadTask implements Callable<Boolean> {
private String url; //下载文件路径
private long startPos; //下载文件当前部分块起始位置
private long endPos; //下载文件当前部分块结束位置
private int part; //用来标识是哪一部分
public DownLoadTask(String url, long startPos, long endPos, int part) {
this.url = url;
this.startPos = startPos;
this.endPos = endPos;
this.part = part;
}
@Override
public Boolean call() throws Exception {
//1.获取文件名
String httpFileName = HttpUtil.getHttpFileName(url);
//1.1 分块的文件名
httpFileName = httpFileName + ".temp" + part;
//1.2 下载的路径
httpFileName = Constant.DOWNLOAD_PATH + httpFileName;
//2. 获取分块下载的连接对象
HttpURLConnection httpURLConnection = HttpUtil.getHttpURLConnection(url, startPos, endPos);
try (InputStream inputStream = httpURLConnection.getInputStream();
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream); //获取下载文件的大小
RandomAccessFile randomAccessFile = new RandomAccessFile(httpFileName,"rw"); )
{
//3. 进行分块读取信息
int len = -1;
byte[] bytes = new byte[Constant.BYTE_SIZE];
while ((len=bufferedInputStream.read(bytes))!=-1){ //当前循环在 1s 内进行统计多次数据
//3.1 在一秒内,使用原子性类型进行统计
DownLoadInfoThread.downSize.add(len);
randomAccessFile.write(bytes,0,len);
}
}catch (FileNotFoundException e){
log.error("下载的文件不存在:{}",url);
return false;
}catch (Exception e){
log.error("文件下载失败!");
return false;
}finally {
//释放资源
if(httpURLConnection!=null) {
httpURLConnection.disconnect();
}
}
return true;
}
}
#文件按分块进行分别切分的方法
这里分别进行定义线程池的核心线程数量、总线程数量、非核心线程数量、空闲时单位回收的时间以及阻塞队列;
它们的关系一般为:
总线程数量 = 核心线程数量 + 非核心线程数量
工作线程首先进入 核心线程数量,若 核心线程数量 已满,则进入 非核心线程数量 ;同理,非核心线程数量 已满,最后将放入阻塞队列(同时,空闲的线程会在指定的时间内被回收)
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(Constant.THREAD_NUM,Constant.THREAD_NUM,0,TimeUnit.SECONDS,
new ArrayBlockingQueue<>(Constant.THREAD_NUM)); //创建线程池
将需要下载的文件进行按条件分块处理,调用以上方法将当前对应的分块文件进行分别下载;并将分块后的块文件加入到 pool线程池 中进行管理,使用 Future 类型的集合进行保存
public void split(String url, ArrayList<Future> futures){
try {
//1.下载的文件大小
long httpFileContentLength = HttpUtil.getHttpFileContentLength(url);
//2.计算分块后的文件大小
long fileSize = httpFileContentLength / Constant.THREAD_NUM;
//3.计算分块的个数
for (int i=0;i<Constant.THREAD_NUM;i++){
//3.1每一次的文件的起始下载大小
long startPos = fileSize * i;
long endPos;
//3.2 若是最后一部分,则下载剩余部分
if(i == Constant.THREAD_NUM - 1){
endPos = 0;
}else {
//3.3 若不是,则该分块最后一部分为起始部分加上分块后的文件大小
endPos = startPos + fileSize;
}
//4.如果不是第一块,则起始位置加一,不然前一个部分的末位为后一部分的起始位,这显然不符合
if(startPos != 0){
startPos++;
}
//TODO 进行分块下载 /
DownLoadTask downLoadTask = new DownLoadTask(url, startPos, endPos, i);
//4.1将任务放到线程池中
Future<Boolean> future = poolExecutor.submit(downLoadTask);
futures.add(future);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
# 使用 LongAdder 类型,更改 DownLoadInfoThread 展现下载信息类
在展示下载信息类中,将原来的 double 类型更改为 LongAdder 原子性类型,即在执行期间不会被其他线程中断,从而保证了操作的完整性和线程安全性;该类型的主要作用有以下几点:
原子性操作:
LongAdder类是 Java 并发包中的一种实现,它专门用于在多线程环境下执行原子性的增减操作;与使用double类型属性并使用synchronized或volatile等关键字来进行同步相比,LongAdder可以更高效地执行并发增减操作避免竞争:在多线程环境中,使用
double类型属性时,多个线程可能同时访问和修改该属性,导致竞争和锁竞争;LongAdder内部采用分段的方式来减小竞争,每个线程在不同的段上执行增减操作,最后将结果累加起来。这可以减少竞争,提高性能减小锁粒度:使用
LongAdder可以避免大范围锁的使用;在某些情况下,使用synchronized或其他锁机制可能需要锁住整个对象,而LongAdder可以将锁粒度减小,只锁住各自的段,从而减小锁的竞争和开销高并发性:
LongAdder是为高并发环境设计的,它可以更好地应对大量并发线程的增减操作需求;这使它在需要频繁增减操作的场景中表现更优秀
2.3 文件的合并以及临时文件的清除
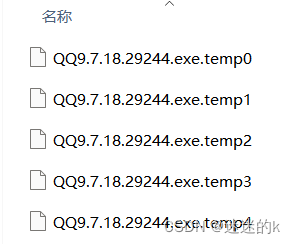
#文件的合并
将之前分块文件按末尾顺序依次进行合并,需要注意的是,其合并的顺序要从 0 开始(这里0为第一位)
public boolean merge(String fireName){
log.info("文件开始合并:{}",fireName);
byte[] bytes = new byte[Constant.BYTE_SIZE];
int len;
try (RandomAccessFile randomAccessFile = new RandomAccessFile(fireName,"rw")){
for (int i = 0;i<Constant.THREAD_NUM;i++){
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(fireName + ".temp" + i))){
while ((len = bis.read(bytes))!=-1){
randomAccessFile.write(bytes,0,len);
}
}
}
log.info("文件合并完毕!");
} catch (Exception e) {
e.printStackTrace();
return false;
}
return true;
}
#临时文件的清除
当合并完成后,需要将之前被分块出来的临时文件清除,只保留最后的文件下载结果文件
public boolean clearTemp(String fireName){
for (int i=0;i<Constant.THREAD_NUM;i++){
File file = new File(fireName + ".temp" + i);
file.delete();
}
log.info("残留文件已经删除成功!");
return true;
}
#在主下载类中调用上述方法
完整代码:
public ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1); //启动一个线程
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(Constant.THREAD_NUM,Constant.THREAD_NUM,0,TimeUnit.SECONDS,
new ArrayBlockingQueue<>(Constant.THREAD_NUM)); //创建线程池
public void my_DownLoad(String url) {
//1.获取文件名
String fileName = HttpUtil.getHttpFileName(url);
//2.与下载目录地址进行拼接,获取当前文件目标下载路径
String downLoadPath = Constant.DOWNLOAD_PATH + fileName;
//获取本地磁盘中文件的下载大小
long localFileLength = FileUtils.getFileContentLength(downLoadPath);
//3.获取连接对象
HttpURLConnection httpURLConnection = null;
DownLoadInfoThread downLoadInfoThread = null;
try {
httpURLConnection = HttpUtil.getHttpURLConnection(url);
//3.1 获取下载文件的总大小
int contentLength = httpURLConnection.getContentLength();
//3.2 获取下载文件的大小,进行比较,判断是否已经下载过
if(localFileLength >= contentLength){
log.info("{} >>> 文件已经下载完成,无需再次下载!",fileName);
return;
}
//TODO 这里进行展现下载信息内容的操作 /
downLoadInfoThread = new DownLoadInfoThread((long)contentLength);
//3.3 调用线程,每隔一秒执行一次
scheduledExecutorService.scheduleAtFixedRate(downLoadInfoThread,1,1, TimeUnit.SECONDS);
//TODO 进行文件分块下载的操作 //
ArrayList<Future> futures = new ArrayList<>();
split(url,futures);
//3.4 这里使用 get() 进行阻塞,以保证文件下载分块下载成功
futures.forEach(future -> {
try {
future.get();
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
});
//3.5 进行分块文件的合并并清除临时文件的操作
if(merge(downLoadPath)){
clearTemp(downLoadPath);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
System.out.println("当前文件:<"+ fileName + "> ------【下载成功】, 下载目标地址:<" + downLoadPath + ">");
//释放资源
if(httpURLConnection!=null){
httpURLConnection.disconnect();
}
scheduledExecutorService.shutdownNow();
poolExecutor.shutdown();
}
//4.将文件读入内存中 【这里使用的是 try - with - resource 的形式】
// try (
// InputStream inputStream = httpURLConnection.getInputStream();
//
// BufferedInputStream bis = new BufferedInputStream(inputStream);
// FileOutputStream outputStream = new FileOutputStream(downLoadPath);
// BufferedOutputStream bos = new BufferedOutputStream(outputStream)
// ){
// //4.1 从连接对象中获取下载信息资源,将其下载到目标路径
// int len = -1;
// byte[] bytes = new byte[Constant.BYTE_SIZE]; //防止 BufferedOutputStream 中的字节长度不够用
// while ((len = bis.read(bytes))!=-1){
// DownLoadInfoThread.downSize += len; //为展现信息线程类中的【本次已下载的文件大小属性】赋值
// bos.write(bytes,0,len);
// }
//
// }catch (FileNotFoundException e){
// log.error("下载的文件不存在{}",url);
// } catch (Exception e) {
// log.error("下载文件失败");
// }finally {
//
// System.out.println("当前文件:<"+ fileName + "> ------【下载成功】, 下载目标地址:<" + downLoadPath + ">");
//
// if(httpURLConnection!=null) {
// //释放连接资源
// httpURLConnection.disconnect();
// }
//
// //释放【展现下载信息的线程】资源
// scheduledExecutorService.shutdownNow();
// }
}
另外,这里可以使用 CountDownLatch 类中的 await() 方法进行代替,以保证在执行最后的文件合并以及临时文件的清除时,之前的线程执行状态为结束状态(使用时记得最后关闭数据流)

运行结果:
可见,文件合并成功且清除临时文件成功,收工