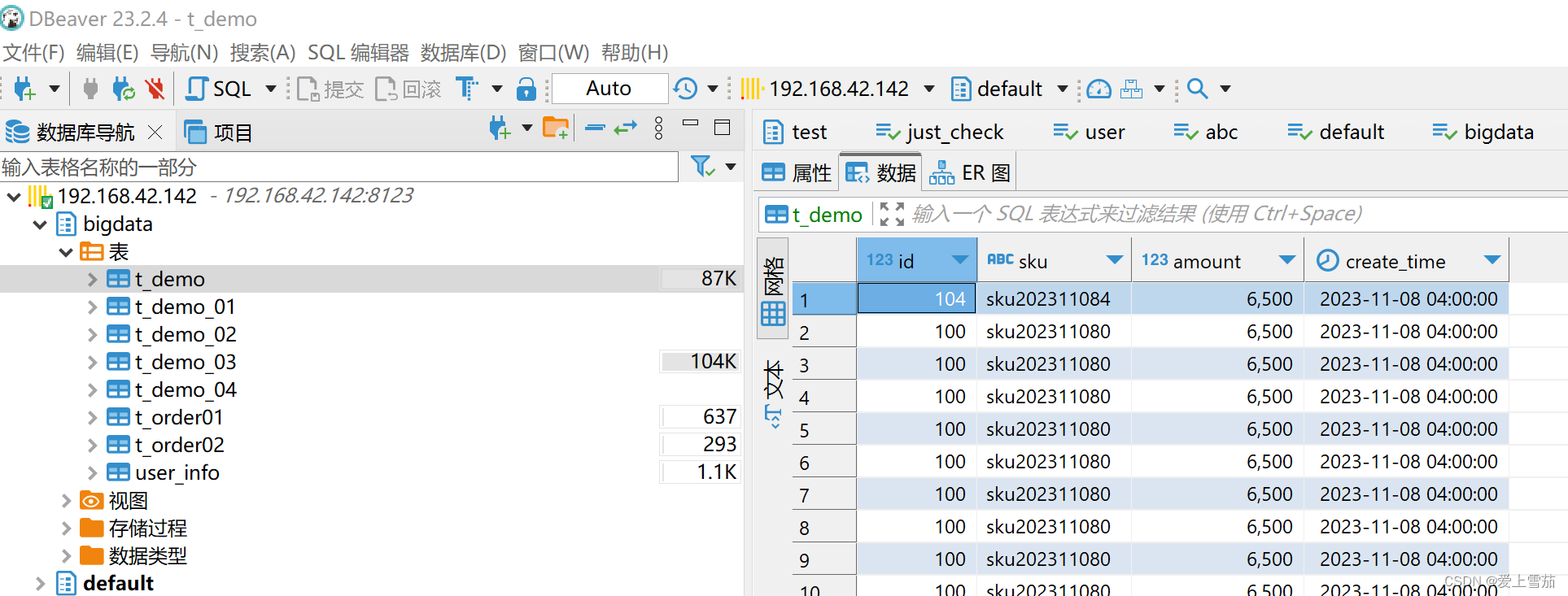
目录
前言
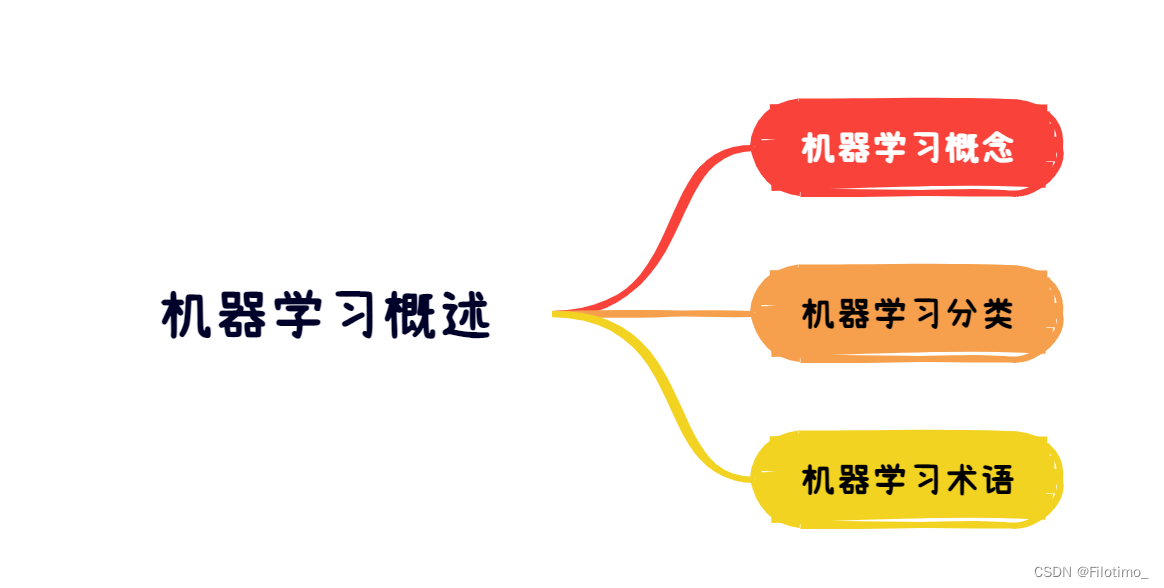
一、机器学习概念
二、机器学习分类
三、机器学习术语
🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。
💡本文由Filotimo__✍️原创,首发于CSDN📚。
📣如需转载,请事先与我联系以获得授权⚠️。
🎁欢迎大家给我点赞👍、收藏⭐️,并在留言区📝与我互动,这些都是我前进的动力!
🌟我的格言:森林草木都有自己认为对的角度🌟。


前言
当今社会,机器学习已经成为一项引人注目且深具影响力的技术。随着大数据、云计算和强大的计算能力的快速发展,机器学习正在改变我们的生活方式、商业模式以及整个产业链。无论是在自动驾驶汽车、智能助理还是个性化推荐系统中,机器学习的应用正变得越来越广泛。
希望通过本博客的阅读,您能够对机器学习有一个最基本的了解。机器学习的发展潜力巨大,我们期待您与我们一同探索这个充满可能性和创新的领域。让我们一起踏上机器学习之旅吧!
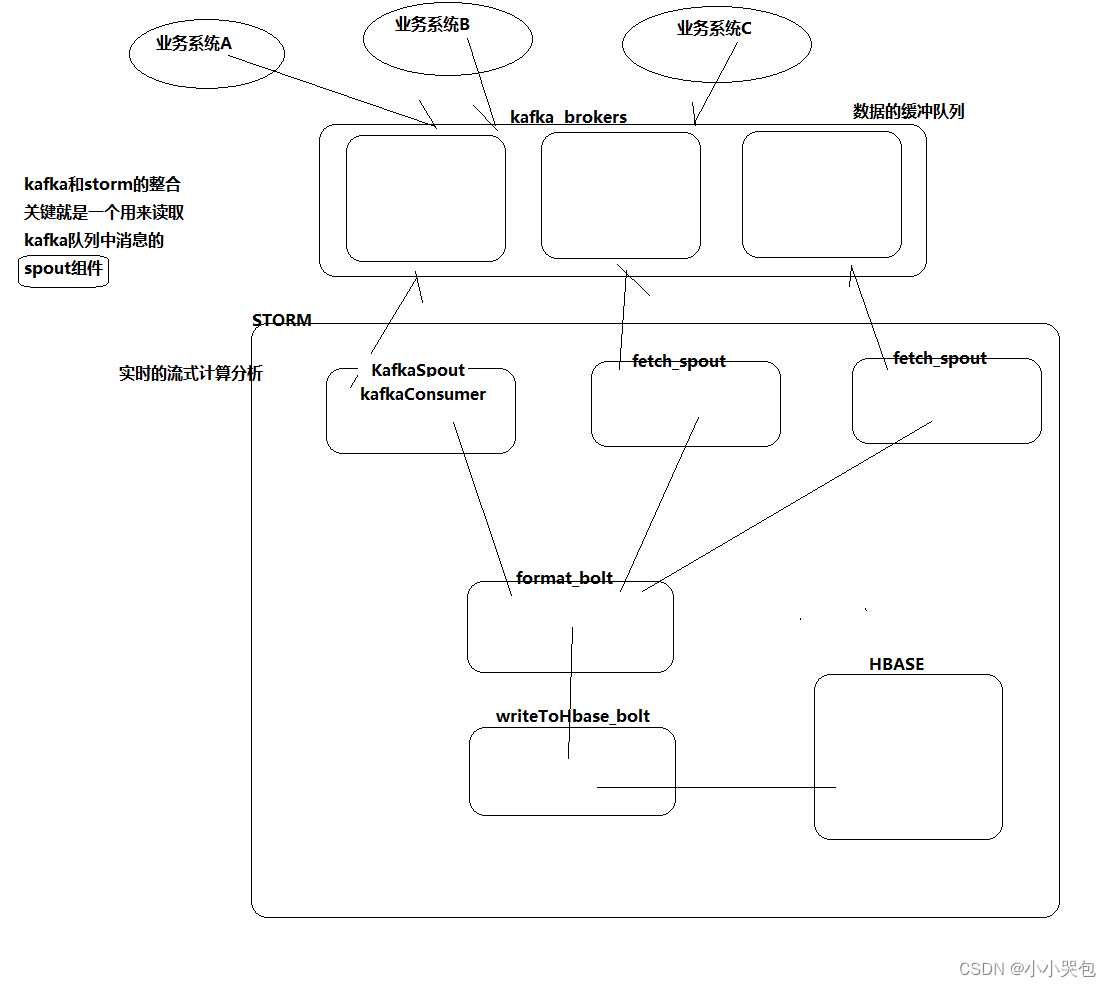
这是本篇文章的脉络图:
一、机器学习概念
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
人工智能,机器学习,深度学习三者之间的关系:
人工智能(Artificial Intelligence,简称AI)是指使计算机能够展示出人类智能的一门学科。
机器学习(Machine Learning)是AI的一个分支,它利用数据和统计概念,使机器能够通过学习和改进经验,给出准确的预测和决策,而无需明确地进行编程。
深度学习(Deep Learning)是机器学习的一种特殊形式,它模仿人脑神经网络的结构和功能。深度学习使用人工神经网络来模拟和学习大规模数据,通过多层次的神经元堆叠,可以自动提取和学习数据的高级特征。
因此,三者之间为包含关系,即人工智能包含机器学习,而机器学习又包含深度学习。
常见的机器学习定义:
1. "机器学习是一种人工智能的分支,它使计算机能够从数据中学习并自动改进无需明确编程"。这个定义强调了机器学习的能力,即通过算法和模型从数据中学习,并自动提高性能。
2. "机器学习是一门研究如何使计算机从经验中自动改善性能的科学"。这个定义将机器学习看作是一门科学,关注的是如何利用数据和经验改进计算机系统的性能。
3. "机器学习是一种能够让计算机通过从数据中学习来推断规律,并应用这些规律进行预测和决策的技术"。这个定义强调了机器学习的应用性质,即通过学习数据中的规律来进行预测和决策。
4. "机器学习是一种通过建立数学模型和算法,使计算机能够识别和理解数据,并根据数据进行预测和决策的方法"。这个定义强调了机器学习的数学建模和算法设计的重要性,以及通过这些方法进行数据分析和应用的能力。
机器学习三要素:
机器学习方法=模型+策略+算法
1. 模型:模型是机器学习的核心组成部分,它用来表示输入数据和输出结果之间的关系。模型可以是线性模型、决策树、神经网络等,用来学习数据的特征和规律。
2. 策略:策略定义了机器学习算法的目标和学习的方法。比如,最小化预测误差或最大化预测准确率。策略可以使用各种不同的评估指标和优化方法。
3. 算法:算法是实现机器学习方法的具体步骤和计算过程。它包括数据预处理、特征选择、模型训练和模型评估等步骤。常见的机器学习算法包括线性回归、决策树、支持向量机、深度学习等。
二、机器学习分类
2.1 按任务类型分类
1.回归问题
回归问题的目标是根据输入数据的特征,预测一个连续的数值输出。回归算法通过建立输入特征与输出之间的关系模型来进行预测。例如,给定房屋的大小、位置、房间数量等特征,我们可以使用回归算法来预测房屋的价格。回归问题的评估通常使用均方误差、或平均绝对误差、等指标。
2.分类问题
分类问题的目标是将输入数据分为不同的类别或标签。分类算法通过学习不同类别之间的特征和决策边界来进行预测。例如,给定一组电子邮件,我们可以使用分类算法来判断它们是垃圾邮件还是正常邮件。分类问题的评估通常使用准确率、精确率和召回率等指标。
3.聚类问题
聚类问题的目标是将输入数据分为不同的群组,每个群组内部的样本相似度较高,而不同群组之间的相似度较低。聚类算法通过计算样本之间的相似性和距离来进行分组。例如,根据用户的购买历史和行为特征,我们可以使用聚类算法将用户分成不同的群组,以便个性化推荐。聚类问题的评估通常使用轮廓系数和Calinski-Harabasz指数等指标。
4.降维问题
降维问题的目标是将高维数据转化为低维数据,同时保留重要的特征信息。降维算法通常通过某种方式减少数据的维度,以便更好地进行可视化或更高效地进行后续处理。常见的降维方法包括主成分分析(PCA)和线性判别分析(LDA)。例如,通过应用PCA,我们可以从包含多个特征的数据中提取最重要的几个特征,从而减少数据的维度。降维问题的评估通常使用保留的方差比例或信息损失等指标。
2.2 按学习方式分类
1.有监督学习
有监督学习是指机器学习中的一类任务,其中算法从标记的训练数据中学习输入数据与输出标签之间的关系。在有监督学习中,训练数据包含输入特征和相应的标签或输出值,模型的目标是通过学习这些训练样本来对新的未标记数据进行预测。常见的有监督学习算法包括线性回归、决策树、支持向量机和神经网络。例如,给定一组带有房屋特征(如面积、位置、房间数量)和相应销售价格的数据,我们可以使用有监督学习算法来构建一个模型,该模型可以根据输入特征预测房屋的价格。
2.无监督学习
无监督学习是指机器学习中的一类任务,其中算法从无标签的训练数据中学习数据背后的隐含结构和模式。在无监督学习中,训练数据只包含输入特征,没有相应的标签或输出值。无监督学习的目标是发现数据中的聚类、关联或降维等模式,以获得对数据的更深入理解。常见的无监督学习算法包括聚类算法(如k均值聚类、层次聚类)、关联规则挖掘和主成分分析(PCA)。例如,通过对一组顾客购买历史的无标签数据进行聚类分析,我们可以发现不同的购买行为模式,从而更好地了解顾客的购买习惯。
3.半监督学习
半监督学习是介于有监督学习和无监督学习之间的一类学习方式。在半监督学习中,算法使用一小部分标记的训练数据和大量无标记的训练数据进行学习。有标签的训练数据用于指导模型的学习,无标签的数据用于发现数据的潜在结构和模式。半监督学习的目标是通过利用无标签数据的信息来提高模型的性能和泛化能力。常见的半监督学习算法包括标签传播算法、自训练和生成模型。例如,在图像分类任务中,我们可以使用带有标签的图像以及大量无标签的图像来训练模型,提高分类的准确度。
4.强化学习
强化学习是一种机器学习方式,其中算法通过与环境的交互来学习最佳的行动策略。在强化学习中,算法以代理的方式与环境进行交互,并根据执行的动作获得奖励或惩罚。通过通过试错过程,算法逐步学习选择最佳的行动以最大化累计奖励。强化学习常用于需要进行序列决策的任务,例如游戏策略、机器人控制和自动驾驶。强化学习算法包括Q-learning、深度强化学习和策略梯度等。例如,在训练自动驾驶汽车时,强化学习算法可以学习最佳的驾驶策略以确保行驶
三、机器学习术语
1. 属性或特征:在机器学习中,属性或特征是指用来描述样本的相关信息或特征,比如图像中的像素值、文本中的单词频率、声音中的频率等等。属性既可以是数值型的,也可以是类别型的,例如一个人的身高和性别就是数值型和类别型的属性。
2. 属性值:属性值是指某个样本在某个属性上的取值,例如一个人的身高属性可能取值为175 cm,性别属性可能取值为“男”。
3. 示例或样本:在机器学习中,示例或样本是指用来训练或测试模型的数据单位,通常由一组属性和对应的属性值构成。例如在手写数字识别任务中,一个示例可以是一张图片,图片中的像素值和标识出的数字就是该样本的属性和属性值。
4. 数据集:数据集是指存储和组织示例和属性的集合,它常用于机器学习算法的训练和测试。数据集包含多个示例或样本,每个示例有多个属性。
5. 样本空间或属性空间:样本空间或属性空间是指所有可能的示例组成的空间,它包含了数据集中所有示例和属性,但不包括标记或输出。
6. 空间特征向量:空间特征向量是指将样本在属性空间中的属性值按照一定顺序组成的向量,它是描述和表示样本的一种方式,通常用于机器学习算法的训练和测试。
7. 标记空间或输出空间:标记空间或输出空间是指所有可能标记或输出的集合,它包含了机器学习任务中需要预测的结果或输出。例如在手写数字识别任务中,标记空间可以是数字1~9和空白,即每个示例需要被预测为这些标记中的一个。
总结
从医疗领域的疾病诊断、药物研发到金融领域的风险评估、投资分析,机器学习正在为我们的生活带来巨大的改变。在电子商务中,个性化推荐系统已经成为了提升用户体验和销售额的重要工具。而在智能交通领域,自动驾驶技术正在推动着出行方式的革新。
然而,我们也意识到机器学习所面临的一些挑战和限制。其中之一是数据隐私和安全问题。由于机器学习算法需要大量的数据来进行训练,我们必须确保用户数据的安全,并遵守相关的法律法规。
尽管机器学习面临着一些挑战和限制,但我们相信,在社会各界的共同努力下,这些问题可以得到解决。机器学习将继续发展,为我们的生活带来更多的便利和创新。