照片
奥坎·耶尼贡
由Pierre Bamin在Unsplash上拍摄
一、说明
也许数据科学或机器学习问题研究中要求最高的阶段是数据预处理阶段,其目的是最终创建有用的数据集。如果说处理很酷的机器学习模型是阿喀琉斯的热门,那么数据预处理就是被诅咒的西西弗斯。

资料来源:维基百科
数据集通常包含缺失数据。原因通常因数据集的性质、问题或收集方式而异。如果是通过调查获得的,则某些问题可能无法得到解答。或者,如果它是从数据流中收集的,则在某些情况下该流可能存在问题。如果数据是从系统中获取的,那么有些特征在某些情况下可能没有数据,等等。
我们必须处理缺失值。因为缺失值直接影响模型的成功。此外,许多机器学习模型不适用于包含缺失值的数据集。
缺失值的分布可能是随机的,也可能遵循某种模式。在某些情况下,缺失值实际上可能是另一个讲述故事的独特数据。因此,应该探索它们的结构和模式,如果可以的话,应与领域知识相结合。例如,假设调查的第一个问题是“你有工作吗?”,第二个问题是“你的薪水是多少?”。只有当第一个问题的答案为“是”时,参与者才能回答第二个问题,否则,应用程序将不允许她/他回答。在这种情况下,工资列中的缺失数据不是随机的,而是遵循一定的模式。
二、缺失数据模式
我们可以对缺失数据分布在哪个结构中进行分类。我们可以列出 3 个广义类别:MCAR、MAR 和 MNAR。
2.1 MCAR:完全随机缺失
数据丢失的概率对于所有情况都是相同的,并且与可观察和不可观察参数无关。在这种情况下,信息会因缺失值而丢失,但是,它不会增加模型的复杂性。考虑一个电池即将耗尽的电视遥控器。有时它会改变频道,有时则不会。当它不起作用时,那就只是运气不好。
如果缺失的数据无法填写,可以将其删除。因为即使信息丢失,它也不会增加额外的复杂性。
2.2 三月:随机失踪
缺失仅取决于我们实际观察到的数据。不同组内的缺失概率相同,但不同组之间的缺失概率不同。假设我们不小心损坏了上述遥控器。下部按键损坏。上下键之间不起作用的概率会有所不同。然而,组内的密钥仍然具有随机性。
由于各组在其内部表示相同的行为,而在彼此之间表示不同的行为,因此可以应用插补。
2.3 MNAR:并非随机缺失
缺失背后有一个机制。这取决于未观察到的数据。在这种情况下,最好处理数据集并收集新数据来克服 MNAR。
三、检测
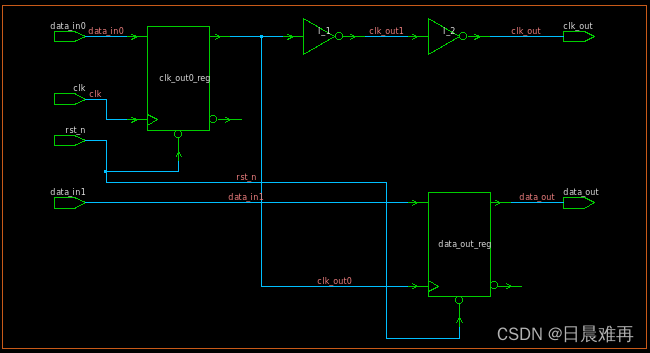
我将使用经典的泰坦尼克号数据集来演示探索数据集中缺失值的方法。
df.isnull()
#True if the cell is missing.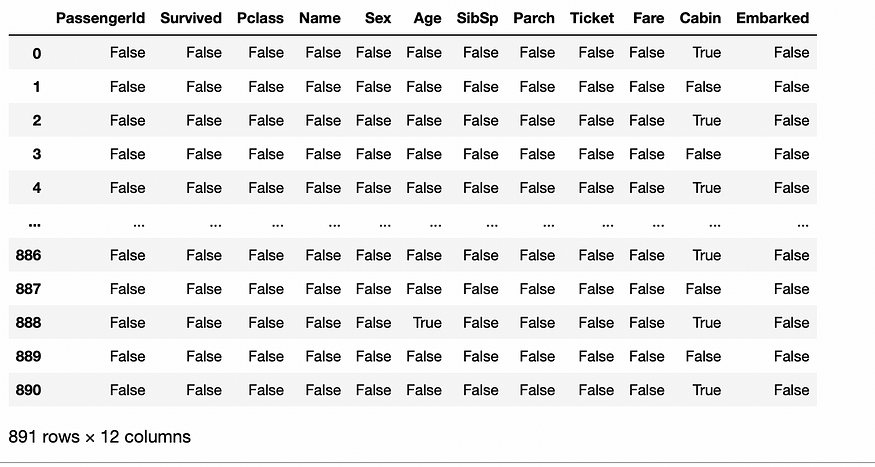
每个特征的缺失值总数。
df.isnull().sum()
-----------
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64可视化
我们可以使用可视化技术来发现缺失值。热图适合可视化。每行表示一行中缺失的数据。
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='YlGnBu')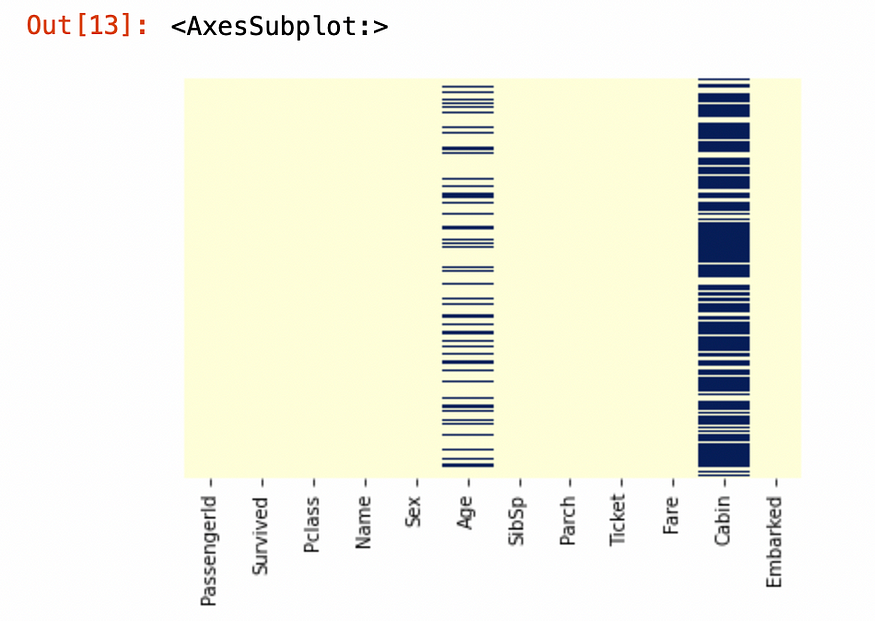
我们还可以使用Missingno库来实现此目的。
import missingno as msno
msno.matrix(data)
我们也可以更改行的顺序。
msno.matrix(df.sort_values('Ticket'))
四、处理程序方法
缺失数据可以通过多种方法处理。这些方法可分为以下几类:
- 删除列或行
- 插补——填充一个值
- 创建新功能
- 使用估计器
4.1 移动
最简单但效果最差的解决方案。如果大部分列或行丢失(一定太多了!),我们可以考虑将其删除。请记住,删除列比删除行要糟糕得多,因为列是一项功能,因此我们可能会丢失大量信息。
#removing all of the missing rows
print(df.shape)
df.dropna(inplace=True)
print(df.shape)
-------
(891, 12)
(183, 12)如您所见,删除了太多行。
#removing columns with nan values
print(df.shape)
df.dropna(axis='columns',inplace=True)
print(df.shape)
-----------
(891, 12)
(891, 9)年龄、船舱和登船列均被删除。
另一种方法是设置阈值以删除某些列或行。例如,如果缺失的百分比大于 75%,我们可以删除列。
#removing columns if missing val ratio is bigger than .75
df = df.loc[:, df.isnull().mean() < .75]
print(df.shape)
---------
(891, 11)或者,我们可以通过给出最小数量的非缺失值来删除行。这次,一行必须至少填充 90%,否则,它将被删除。
thres_val = df.shape[1] * 0.9
df.dropna(thresh=thres_val, inplace=True)
------
(733, 12)4.2 插补
我们可以用另一个值替换缺失值。这可以以不同的方式应用于数值和分类值。
可以为数值特征分配一个常数值。关于常数值是什么的信息应该来自域。例如,只有在领域知识支持的情况下,我们才可以将Age列中的缺失值设置为 18。
df["Age"].fillna(18,inplace=True)同样,我们可以在分类特征中分配一组新的类别。例如,我们可以将缺失的数据替换为新类别“缺失”。
df["Embarked"].fillna("Missing",inplace=True)使用聚合值是另一种选择。数值特征的平均值可以用Nans代替。对于小型数据集,使用平均值是一种简单的方法,并且可能效果很好,但对于大型数据集则效果不佳。如果特征中存在异常值,则总体上可能会损害模型的质量,因为均值将是偏态值。由于这些原因,应事先检查特征偏度。
df["Age"] = df["Age"].fillna(df["Age"].mean())如果特征有偏差,可以使用中值代替平均值。
df["Age"] = df["Age"].fillna(df["Age"].median())类似地,分类特征可以用众数来估算。它也适用于数字特征。如果特征不平衡(类不平衡问题),则用众数填充缺失值可能会给数据带来偏差。
df["Cabin"] = df["Cabin"].fillna(df["Cabin"].mode()[0])另一种可用于分类特征的方法是为缺失数据创建新特征。这个新特征可以是一个布尔值,如果数据存在于引用的特征中则为真,否则可以设置为假。因此,丢失数据提供的信息不会丢失。
df["Cabin_MV"] = df["Cabin"].isnull()缺失的数据可以用上一行或下一行的数据填充。如果观测值之间存在顺序关系,则可以应用此方法。
#forward
df["Cabin"] = df["Cabin"].fillna(method ='ffill')
#back
df["Cabin"] = df["Cabin"].fillna(method ='bfill')4.3 简单输入器
from sklearn.impute import SimpleImputer
class sklearn.impute.SimpleImputer(*, missing_values=nan, strategy='mean', fill_value=None, verbose=0, copy=True, add_indicator=False)[source]它是 sklearn 的自动输入器类。它需要的参数;
缺失值:int、float、str、np.nan、None、默认=np.nan
缺失值的类型。在 pandas 数据框中,它们的类型是 np.nan
策略:str,默认='mean'
{'平均值', '中位数', '最频繁', '常量'}
插补策略。
fill_value:字符串或数字,默认=无
如果策略设置为常量,则使用常量值。
复制:布尔值,默认=True
Imputer 创建给定X的副本。
add_indicator:布尔值,默认=False
如果启用,估算器可以在进行插补的情况下解释缺失情况。
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer = imputer.fit(df[["Age"]])
df["Age"] = imputer.transform(df[["Age"]])4.4 插值法
插值是一种估计序列中缺失数据的数学技术。它获取观察结果并根据它们调整函数。函数的范围空间与数据一样广泛。这就是为什么它被称为插值,如果我们从范围进一步估计数据,那就是外推法。插值法尤其适用于时间序列问题,因为它很可能用以前的值来填充缺失值。
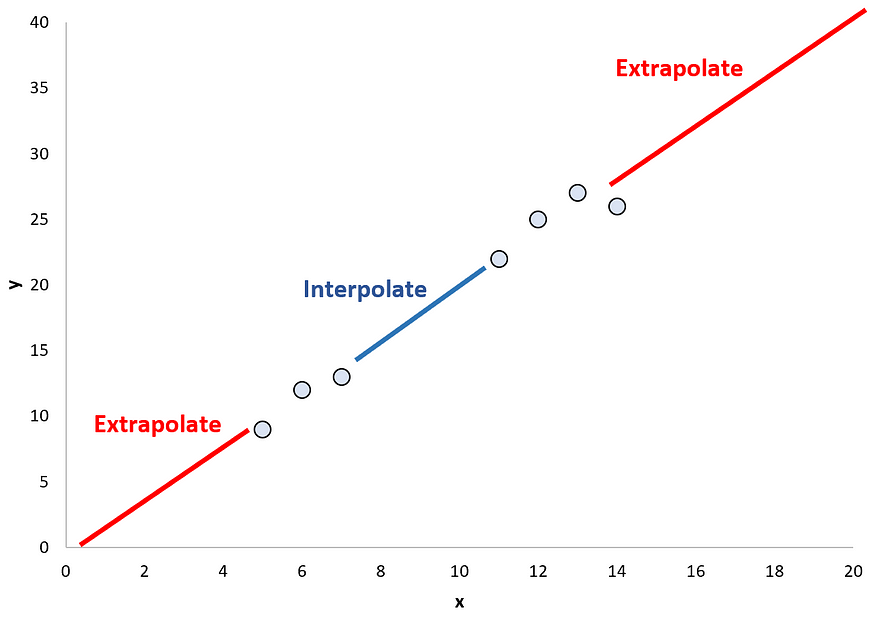
插值法与外推法 来源:statology
DataFrame.interpolate(method='linear', axis=0, limit=None, inplace=False, limit_direction=None, limit_area=None, downcast=None, **kwargs)[source]方法:str,默认='线性'
{ '线性'、'时间'、'索引'、'值'、'垫'、'最近'、'零'、'线性'、'二次'、'三次'、'样条'、'重心'、'多项式”、“krogh”、“分段多项式”、“样条”、“芯片”、“akima”、“三次样条”、“from_derivatives”}
线性插值是默认方法。它将点按顺序连接成直线,并按照与之前相同的顺序估计未知值。连接点时它不使用索引。它根据数字的值对数字进行排序。如果时间间隔设置相等的话,时间 插值也是一样的,都是以时间间隔为基础的。
索引 和值使用索引的实际值。可应用于顺序数据。Pad使用前一个或下一个非缺失数据。
最近的很明显。零、线性、二次和三次分别是样条插值的零阶、一阶、二阶或三阶。
重心是多项式插值的一种变体。它将问题视为有理函数插值的特例。我们在线性插值中使用直线。但如果数据不是线性的而是多项式的,那么我们应该使用多项式插值。Krogh是另一种特殊的多项式插值方法。如果我们有大量的点,那么多项式插值可能会出现问题,在这种情况下,您应该采用更高的阶数,但这一次会出现振荡问题。这就是piecewise_polynomial发挥作用的地方。from_derivatives是piecewise_polynomial的一种特殊方法。

多项式插值。资料来源:维基百科
样条是分段多项式的特例。它们是一组低阶多项式。因此,您可以使用 9 个低阶三次多项式,而不是给出高阶多项式。Chip、anima和三次样条方法是样条插值的特殊情况。
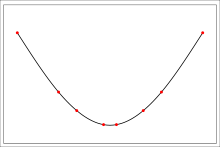
样条线。资料来源:维基百科
轴:{0或'索引,1或'列,无},默认=无
限制:整数,可选(>0)
您可以设置连续填充的最大限制。
limit_direction: {'向前','向后','两者'}, 默认=无
如果方法选择为 'pad','ffil' => 方向必须为正向。否则,方法选择为“backfill”、“brill”,且方向必须为向后。
limit_area : {无, '内部', '外部'}, 默认=无
内部:插值;外:推断。
4.5 KNN:K 最近邻
KNN 是一种用于分类和回归问题的监督机器学习方法。它计算数据点(大多数时候是欧几里德)和彼此接近的组之间的距离。在应用 KNN 插补之前,必须对数值特征进行缩放,并且必须对分类特征进行转换。
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=3)
df = pd.DataFrame(imputer.fit_transform(df),columns = df.columns)4.6 其他预测模型
线性或逻辑回归可分别用于填充数值和分类特征。使用包含非缺失值的数据帧子集来训练模型。该模型预测包含缺失值的数据帧的另一个子集的结果。
from sklearn.linear_model import LinearRegression
train = df[df['Age'].isnull()==False]
test = df[df['Age'].isnull()==True]
model = LinearRegression()
y= train["Age"]
train.drop(['Age'],axis=1,inplace=True)
test.drop(['Age'],axis=1,inplace=True)
model.fit(train,y)
y_pred = model.predict(test)任何机器学习模型都可以用上述逻辑来实现。
4.7 MissForest
from missingpy import MissForest它是一种基于机器学习的插补,使用随机森林模型。它不关心数据是否分类,并且您不需要像 KNN 那样调整数据。这是一种迭代方法,每次迭代后都会变得更好。
missForest(xmis, maxiter = 10, ntree = 100, variablewise = FALSE,
decreasing = FALSE, verbose = FALSE,mtry = floor(sqrt(ncol(xmis))), replace = TRUE,classwt = NULL, cutoff = NULL, strata = NULL,
sampsize = NULL, nodesize = NULL, maxnodes = NULL,
xtrue = NA, parallelize = c('no', 'variables', 'forests'))您可以在此处获取参数。
4.8 MICE:通过链式方程进行多元插补
在这种方法中,我们使用各种估计器对剩余特征上缺失数据的特征进行建模。数据的随机子集被输入到多个模型中,并返回平均结果作为结果。
//pseudocode for mice
//Algorithm: multiple imputation filling missing values in dataset
//for each iteration
// for each f<-feature
s <- subset data
train model with s
do replace missing values4.9 迭代输入器
Sklearn 的多元输入器
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputerestimator:估计器对象,默认=BayesianRidge()
将估计器提供给输入器。
缺失值:int 或 np.nan,默认=np.nan
数据集中缺失值的类型。
Sample_Postterior:布尔值,默认=False
当模型产生输出分布(而不是单个预测)时,设置 True。在此过程中获得多个估算数据集,并从中提取样本。
max_iter:整数,默认=10
最大插补轮次。
tol:浮动,默认=1e-3
可以定义停止的容差值。
n_nearest_features:整数,默认=无
并非所有功能都会被使用,相反,您可以定义它们的子集。根据每对特征之间的绝对相关系数来选择特征。
初始策略:str,默认='mean'
{'平均值', '中位数', '最频繁', '常量'}
与 SimpleImputer 相同
imputation_order:str,默认='升序'
{'升序', '降序', '罗马', '阿拉伯语', '随机'}
要填充的特征的顺序。'上升';首先处理缺失最少的特征。“罗马”是从左到右,“阿拉伯”是从右到左。
Skip_complete:布尔值,默认=False
如果许多特征没有缺失值,则将其设置为 True 以节省计算。
min_value:浮点数或形状数组(n_features,),默认=np.inf
您可以定义要估算的最小可能值。
max_value:浮点数或形状数组(n_features,),默认= np.ing
与上面的逻辑相同。
add_indicator:布尔值,默认=False
与 SimpleImputer 相同。
imputer = IterativeImputer()
train_mice['Age'] = df.fit_transform(train_mice[['Age']])五、结论
为了使机器学习模型正常工作并提高其准确性,必须首先优化数据集。这种预处理工作往往是整个工作中漫长且困难的部分,有时甚至比模型本身更重要。由于多种原因,数据集中可能存在缺失值。许多机器学习模型在缺少值的数据集中也会失败或无法正常工作。因此,我们需要处理缺失值。在这篇博客中,我尝试总结可以使用哪些方法来处理缺失值。