导读:欢迎来到 StarRocks 源码解析系列文章,我们将为你全方位揭晓 StarRocks 背后的技术原理和实践细节,助你逐步了解这款明星开源数据库产品。本期 StarRocks 技术内幕将主要介绍 StarRocks 统计信息和 Cost 估算。
1.背景
在学习本文之前,首先需要对 Optimizer 有一定的背景知识,这里可以参考StarRocks优化器代码导读 。其次本文是基于 StarRocks branch-2.2 的,后面版本的新增功能不在本文范围之内。
统计信息和 Cost 估算是 Optimizer 中的重要部分,准确的统计信息和 Cost Model 可以帮助优化器判断不同执行计划的代价,从而在有限的时间内选择出最优的执行计划。
本文将介绍 StarRocks 统计信息的收集、计算,以及 Optimizer 如何利用统计信息计算 cost,从而找到 cost 最小的 plan。
2.整体流程
我们首先来看统计信息收集和读取的整体流程,帮助你先有个整体性的了解,也能更深入地学习后面的细节知识。
统计信息(Statistics Class) 描述了表中数据的详细信息,包含表的行数和每一列的数据分布:最大/最小值,不同值的个数(NDV),NULL 值个数和列的平均大小(Average Row Size)。 因此整体流程可以大致分为两部分,分别是统计信息的收集和统计信息的读取计算。
下图描述了统计信息的收集和读取计算的整体流程:
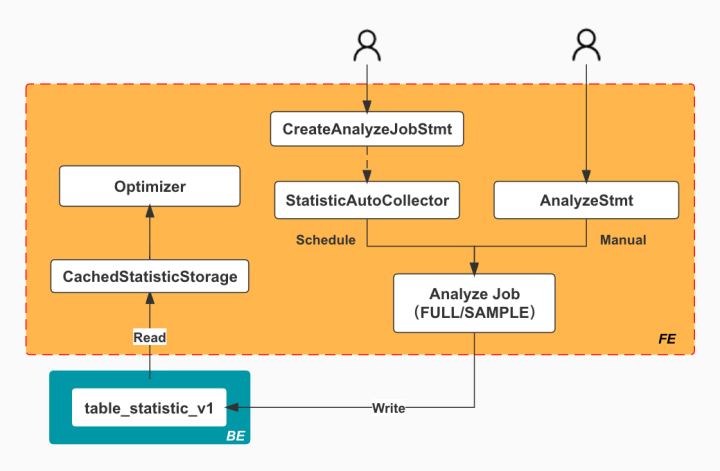
统计信息的收集包括手动和定期任务这两种触发方式,对应了图中的两种 Statement :CreateAnlyzeJobStmt(创建 Analyze 定期任务)和 AnalyzStmt(手动执行 Analyze 命令)。两种方式都会创建一个 AnalyzeJob,由它负责具体的统计信息的收集,收集的类型包含全量(FULL)和抽样(SAMPLE)两种。
而收集到的统计信息会存储在 BE 的 _statistics_.table_statistic_v1 表中。其中记录了不同 table 每一列的统计信息,如下图所示:

读取的整体流程比较简单,Optimzier 会首先从 CachedStatisticStorage 中读取,如果 cache 中没有对应的统计信息,则会从 table_statistic_v1 表中读取对应列的信息。
Optimizer 对统计信息的计算过程比较复杂,接下来将会详细介绍。但大体流程就是利用统计信息计算每个执行计划的 cost,从而从中选择出最优的执行计划。
3.代码导读
接下来我们就通过下文的介绍,来进一步理解 StarRocks 中统计信息的收集、计算以及 Cost 的计算、裁剪过程,并最终找到 Cost 最小的 Plan。
统计信息和 cost 的相关代码分别在 sql/optimizer/statistics 和 sql/optimizer/cost 的目录下,供你查看与参考。
3.1 统计信息的收集
统计信息的收集的流程并不复杂,首先看之前提到的两种 Statement:
-
CreateAnalyzeStmt 通过 StatisticAutoCollector 周期性地调度 AnalyzeJob,周期间隔由statistic_collect_interval_sec 决定。
-
AnalyzeStmt 会立即触发一次 AnalyzeJob 的执行,且只执行一次。
还需注意的是,StatisticAutoCollector 不仅包含用户通过 CreateAnalyzeStmt 创建的 AnalyzeJob,还包括为所有表创建一个默认的抽样任务,用于定期更新统计信息。
如下图所示,我们细化了上一小节整体流程图中的 AnalyzeJob 任务。AnalyzeJob 在执行具体的收集任务时,首先会创建多个 TableCollect Job。而每个 TableCollect Job 又会负责收集对应 Table 的统计信息,收集过程中还会使用 StatisticsExecutor 来负责实际的统计信息的写入。如下图所示:
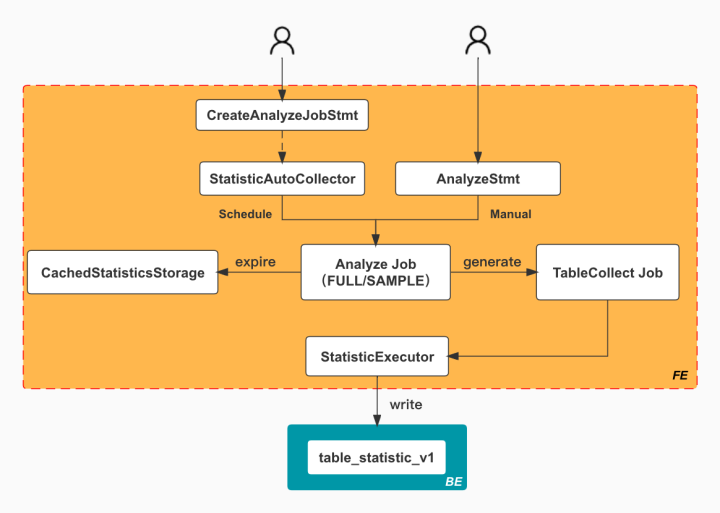
这里要注意的是,StatisticsExecutor 可以简单理解为生成对应表的 Insert into select 语句并执行,下面是生成 SQL 语句时的模板。执行该语句时,会将对应的 Table 的列统计信息记录在 table_statistic_v1 表中:
private static final String INSERT_STATISTIC_TEMPLATE = "INSERT INTO " + Constants.StatisticsTableName;
private static final String INSERT_SELECT_FULL_TEMPLATE =
"SELECT $tableId, '$columnName', $dbId, '$tableName', '$dbName', COUNT(1), "
+ "$dataSize, $countDistinctFunction, $countNullFunction, $maxFunction, $minFunction, NOW() "
+ "FROM $tableName";3.2 统计信息的计算
Optimizer 的统计信息计算是在 Memo Optimize 阶段计算的,Memo 中 Group 的优化主要依靠不同task 的调度,统计信息的计算则依赖于 DeriveStatsTask。这个 task 的执行流程可以参考 ORCA【1】的统计信息获取过程,下图描述了 T1 join T2 on a=b 时的获取过程:
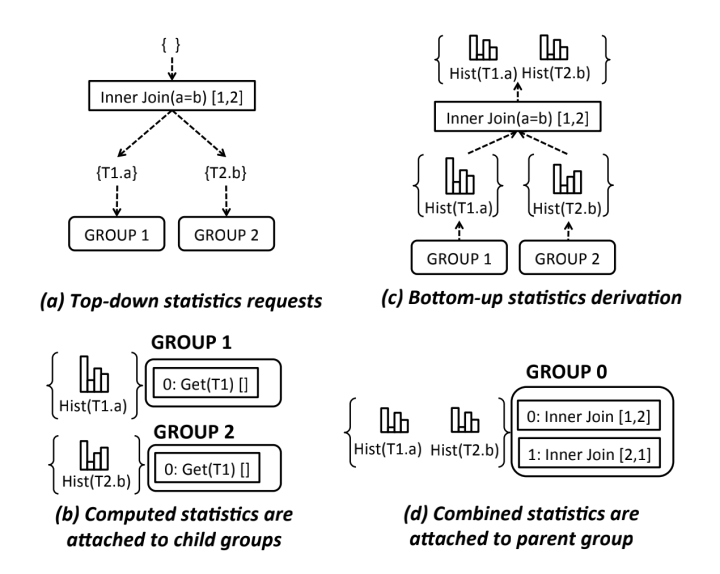
可以看出,整个过程是自顶向下来请求统计信息:先计算孩子节点的统计信息,然后结合孩子节点的统计信息,自底向上计算 Parent 节点的统计信息,并将计算结果记录在自身的 Group 中。
DeriveStatsTask 任务会使用 StatisticsCalculator 计算不同节点的统计信息,例如下图,就是计算如下 SQL 的统计信息过程:
Select count(1) from t0 group by k1; 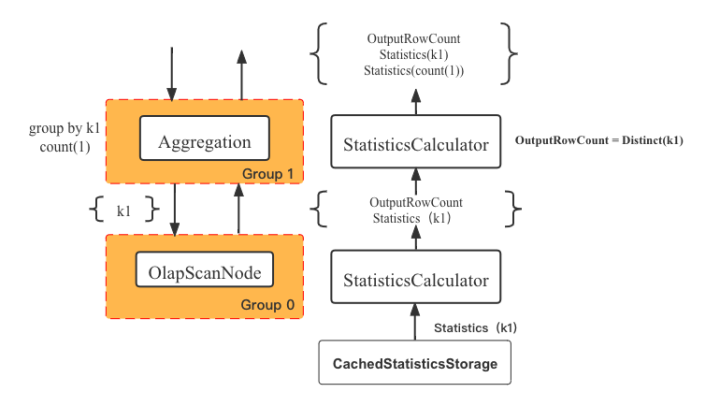
自上而下的请求统计信息,再自底向上的计算每个 Group 的统计信息,大致流程如下:
-
首先,OlapScanNode 的列统计信息需要 StatisticsCalculator 访问 CacheStatisticsStorage 获取,如果该 cache 中不包含,则从 table_statistic_v1 获取;
-
其次,OlapScanNode 的统计信息包含 t0 表的行数与 k1 列;
-
最后,Aggregation 节点需要在 StatisticsCalculator 中计算聚合后的 OutputRowCount,以及 k1 和count(1) 的列统计信息,其中 OutputRowCount 等于 k1 列的 NDV。
可以看到,StatisticsCalculator 中包含所有节点的统计信息的计算方式,该类中表达式统计信息使用 ExpressionStatisticCalculator 计算,对过滤条件的估计则使用 PredicateStatisticsCalculator 计算。
3.3 Cost 的计算
3.3.1 Cost 计算公式
通过上述计算,我们完成了每一个 GroupExpression 的统计信息。在 EnforceAndCostTask 中,我们则需要计算每个 GroupExpression 的 Cost,从而计算出当前 Group 代价最低的 GroupExpression,并记录在 Group 中。
我们可以在 CostModel 中完成不同节点的 Cost 的计算,Cost 的计算公式比较简单:
CalculateCost = CpuCost * cpuCostWeight + MemoryCost * memoryCostWeight + NetworkCost * networkCostWeight
其中 CpuCost、MemoryCost 和 NetworkCost 目前使用 Statistics computeSize 计算。需要说明的是,我们可以把 Statistics computeSize 简单理解为该节点需要处理的数据量(行数 * 列大小),需要处理的数据量越大,节点的CPU开销、内存占用和数据 shuffle 的代价越大。
Statistics ComputeSize = Output RowCount * sum(column_size)
不同节点的 CpuCost、MemoryCost 和 NetworkCost 都是不同的,这主要需要考虑节点的实际开销代价。比如 OlapScanNode 需要计算 CpuCost,而无需计算 NetworkCost,但是 Exchange节点(在Memo 里叫做 PhysicalDistribution)则主要需要计算 NetworkCost。
由于 CPU 计算和内存占用,网络数据传输的实际开销差距很大,这就需要我们通过 cpuCostWeight、memoryCostWeight 和 networkCostWeight 来调整 Cost 结果,尽可能地和实际代价开销相似。
这里需要补充的是,Optimizer 计算的 Cost 结果,只是一个相对值,而非绝对值。因为它是通过比较 Cost 值从 Memo 中抽取出 Cost 最小的执行计划,并不代表实际执行开销。一个好的 Cost Model,是执行计划的 Cost 排序尽量和实际执行开销的排序相同【2】。
3.3.2 GroupExpression Cost 计算
介绍完了每个节点自身该如何计算 cost,接下来我们就开始介绍 Optimizer 是如何使用 Memo 计算 cost,并记录 cost 最低的 GroupExpression 的。需要预先说明一下,接下来的介绍中不会提及 Property 概念,主要是帮助你更容易理解。
不过在详细介绍前,我还需要介绍一下 Cascades 优化框架的基本原则,它利用了 DP 的思想,选出来的最优计划中每个子部分(sub-plan)都是最优的,每个 Group 只需要记录 cost 最小的GroupExpression,计算过的 group 无需重复计算。
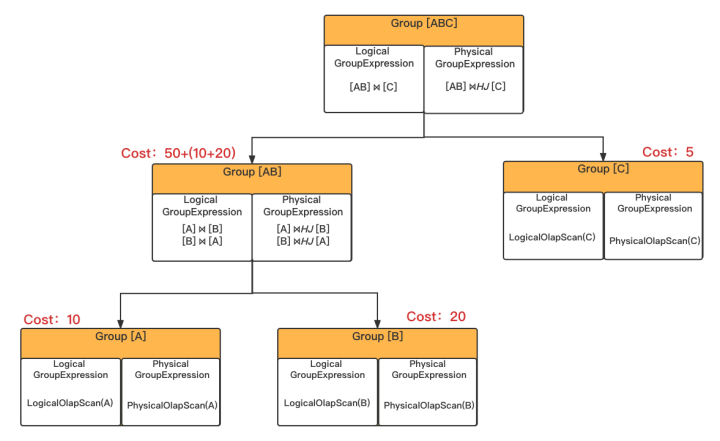
上图是表示的是 A、B、C 三表 join 时的 Memo 中的 Group,每个 Group 中都包含 LogicalGroupExpression 和 PhysicalGroupExpression,我们也将使用该图介绍 GroupExpression 的 Cost 计算。
例如 Group[AB] 的 LogicalExpression 包含 [A]⨝[B]和[B]⨝[A],这是通过使用 TansformRule JoinCommutativity 进行逻辑等价变换生成的,两个 LogicalExpression [A]⨝[B]和[B]⨝[A] 是逻辑等价的,Optimizer 使用 ImplementRule 将 [A]⨝[B] 和 [B]⨝[A] 转换成对应的 PhysicalGroupExpression [A]⨝HJ[B]和[B]⨝HJ[A],HJ 则表示 HashJoin。
Memo 中会记录所有 Group 的 cost 最小的 GroupExpression,避免重复计算。我们用下面的的表格来表示,方便理解。
| Group | Best GroupExpression | Cost |
| [ABC] | ||
| [AB] | [A]⨝HJ[B] | 80 |
| [A] | PhysicalScan(A) | 10 |
| [B] | PhysicalScan(B) | 20 |
| [C] | PhysicalScan(C) | 5 |
每个节点会计算自身的 Cost,一个 GroupExression 的 cost,就是自身节点的 cost 加上孩子节点的cost。
在 EnforceAndCostTask 中,会对每个 PhysicalGroupExpression 计算 cost。当计算上层节点的 cost 时,首先需要计算出孩子节点的 cost。先计算出 group[A] 和 Group[B] 的 cost,是因为只有一个PhysicalGroupExpression,那么 Best GroupExpression 和对应的 cost 也就很好确定了。
Group[AB] 包含 [A]⨝HJ[B]和[B]⨝HJ[A],需要分别计算其 cost,并记录这 Memo 中。这里需要注意,在计算 [A]⨝HJ[B] 时,会计算出 group[A] 和 group[B] 的 cost;在计算 [B]⨝HJ[A] 时,可以直接使用 Memo 中记录的 group[A] 和 group[B] 结果,避免重复计算。
我们假设 [A]⨝HJ[B] 的 cost 更小,从而可以将其计算出的 cost 值 :50(自身节点 cost ) + 10(左孩子 cost )+20(右孩子 cost )记录在 Memo 中。group[c] 和 A、B 同理,不再叙述。
Group[ABC] 找到 cost 最低的 GroupExpression 时,还需探索更多的 Group,后面我们会结合 Cost 裁剪进行更详细的介绍。
3.4 Cost 裁剪
在优化器中,对于复杂 SQL 的 plan 搜索空间会很巨大,而 cost 裁剪可以有效地对搜索空间进行裁剪,提升优化器搜索 plan 的性能。
基于 Cascades 的优化器可以自顶向下地探索 plan 空间,使用 Upper bound 对 cost 进行裁剪,该方法在 columbia【3】中叫做 Simple Pruning,从而避免对无效的 GroupExpression 进行探索。
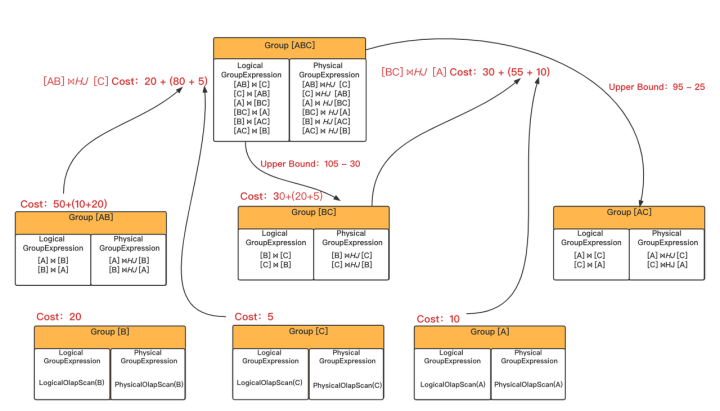
上图接着3.3中介绍的示例,描述了多个 Group 的 Cost 计算和 Cost 裁剪过程。
在计算 Group[ABC] 时,之前的 GroupExression [AB] ⨝HJ[C] 已经计算出其 cost 为20(自身)+80+5 (左右孩子)。其实到这里,我们已经得到了一个可以执行的 Physical Plan 及其 Cost,那么可以使用这个 cost 值,作为后续探索的 Upper Bound。超过这一值时可以直接结束 task,不再进行探索。
而 Upper Bound 的值也可以进行更新,例如 [BC] ⨝HJ[A] 的 cost 值小于 Upper Bound,那么我们将使用更小的 cost 值作为 Upper Bound。
在探索 Group[BC] 时,将使用之前 [AB] ⨝HJ[C] 计算出的 Upper Bound - [BC] ⨝HJ[A] join 节点的 cost,作为孩子节点 Group[BC] 的 UpperBound。假如 [BC] ⨝HJ[A] 经过探索得到了更小的 cost,更新 Uppper Bound,并在探索 Group[AC] 时将使用更小的Upper Bound 70。
假如 Group[AC] 的 join 节点类型是 Cross Join,其 cost 值为200,大于上层节点要求的 Upper Bound,则可以直接结束 Group[AC] 的 EnfocceAndCostTask,而且上层 GroupExpression [AC] ⨝HJ[B] 的 Task 也可以直接结束,无需探索 Group[B]。
最后,Group[ABC] 只记录 cost 值最小的 [BC] ⨝HJ[A],其中 group[AC] 因为被 Upper Bound 裁剪了,没有记录 Best GroupExresssion,因此这里就用 null 表示。如下表所示:
| Group | Best GroupExpression | Cost |
| [ABC] | [BC] ⨝HJ[A] | 95 |
| [AB] | [A]⨝HJ[B] | 80 |
| [BC] | [B]⨝HJ[C] | 55 |
| [AC] | null | null |
| [A] | PhysicalScan(A) | 10 |
| [B] | PhysicalScan(B) | 20 |
| [C] | PhysicalScan(C) | 5 |
当 Root Group 完成了探索时,整个 Memo 优化就结束了。后续 extractBestPlan 的时候就可以依据上面的记录,从 Root Group 开始,抽取出代价最小的 Physical Plan。
4.总结
在本文我们介绍了如何通过 Analyze 任务来收集统计信息,如何自底向上地计算各个节点的统计信息,也介绍了 Optimizer 是如何使用 Memo 计算 Cost,以及是如何在 Plan 的探索过程中利用 Cost Upper Bound 进行裁剪,并最终选择出代价最小的 Plan。
参考资料
【1】Soliman M A, Antova L, Raghavan V, et al. Orca: a modular query optimizer architecture for big data[C]//Proceedings of the 2014 ACM SIGMOD international conference on Management of data. 2014: 337-348.
【2】Gu Z, Soliman M A, Waas F M. Testing the accuracy of query optimizers[C]//Proceedings of the Fifth International Workshop on Testing Database Systems. 2012: 1-6.
【3】Xu Y. Efficiency in the Columbia database query optimizer[D]. Portland State University, 1998.
本期 StarRocks 源码解析到这就结束了,好学的你肯定学会了一些新东西,又产生了一些新困惑,不妨留言评论或者加入我们的社区一起交流(StarRocks 小助手微信号)。下一篇 StarRocks 源码解析,我们将为你带来 StarRocks 如何添加一个优化规则。