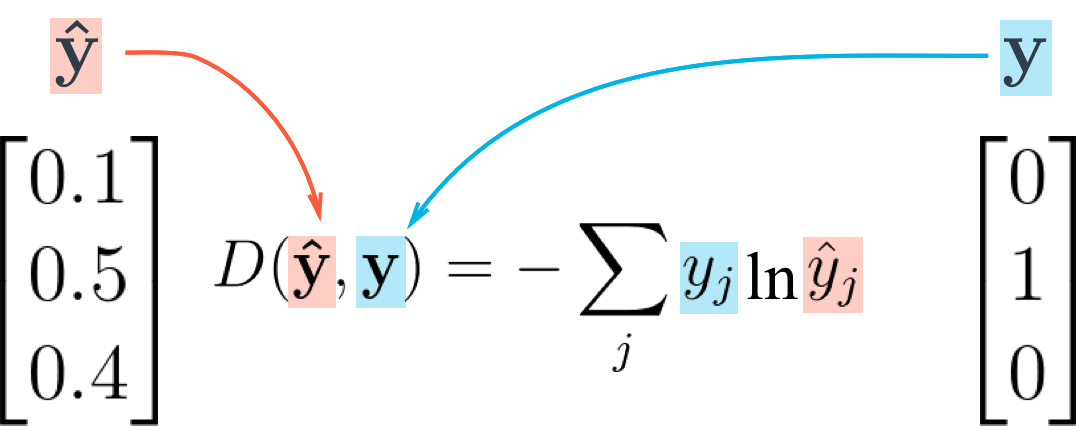
目录
前言
一、了解磁盘
1、磁盘结构
2、磁盘划分
3、inode与文件名的关系
二、软链接与硬链接
1、如何创建软连接与硬链接文件
2、理解软连接
3、理解硬链接
三、动态库与静态库
1、静态库
(1)静态库的制作
(2)静态库的使用
2、动态库
(1)动态库的制作
(2)动态库的使用
前言
前面我们介绍了关于内存中的文件,本章主要介绍磁盘文件、软硬连接与动静态库相关知识;
一、了解磁盘
1、磁盘结构
磁盘是我们计算机中的一种硬件,主要用于存储数据,与内存不同,内存掉电易失,而磁盘不会;而从速度来看,磁盘远远不如内存,但是价格却相当实惠;因此在许多互联网公司中仍选择使用磁盘;以下为网上找来的几组磁盘图片;

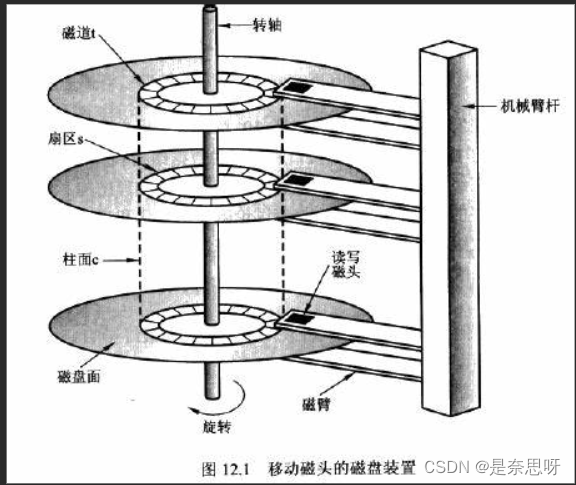
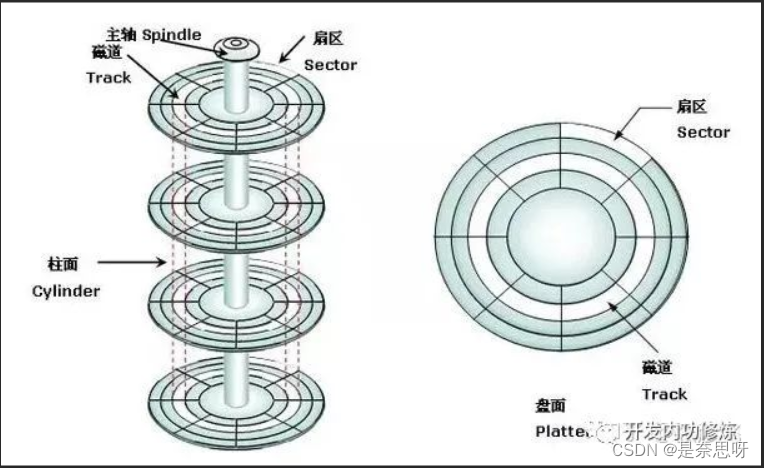
以上图片为百度搜索;上图中,我们需要了解最关键的几个概念分别是磁道、扇区、盘面的概念;也就是这几个信息,可以帮我们定位磁盘中指定的某个位置;
磁道:把我们的磁盘划分为一个又一个同心圆,每个同心圆就是一个磁道;
柱面:一个磁盘绝不仅仅只有一个盘片,实际上是由多个盘片叠加在一起,如图二和图三,我们把同一磁道的多个磁盘合起来称为一个柱面;
扇区:我们将一个盘片上多个同心圆像且蛋糕一样切成多个区域,每个区域就是一个扇区;
盘面:正如图所示,一个盘片的一面我们称之为盘面;
我们通过盘面可以确定在那一面,就可以确定用哪个磁头定位;然后通过旋转磁盘找到是哪一个扇区,最后可以通过磁臂偏移找到是哪个磁道,这样就可以找到磁盘中某块扇区的位置;这种寻址方式我们称之为CHS寻址方式;
在操作系统看来,我们可以将所有扇区排序,抽象称一个数组,那么我们只要通过数组下标就可以找到某个扇区,这种寻址方式我们称之为 LBA ;然后我们通过特定的算法,将LBA地址转换成CHS地址;这样我们就可以将软件操作系统与硬件磁盘结合起来了;
补充:通常一个扇区的大小为512Byte,而我们操作系统读取磁盘数据的单位一般为4KB;
2、磁盘划分
通常一块磁盘的大小由256G、512G、1T等;那么我们的磁盘是如何管理这么大的区域呢?首先,我们会将一块磁盘进行分区,就像我们window下各个盘符,C盘、D盘等;

接着我们只要能管理好某个区,是不是所有的区我们就都可以管理好了?没错!就是如此,我们下面以D区为例;我们可以将一个分区划分为一个Boot Block(启动块)和若干个分组,如下图所示;

我们又将每个Block Group 划分为如下结构;
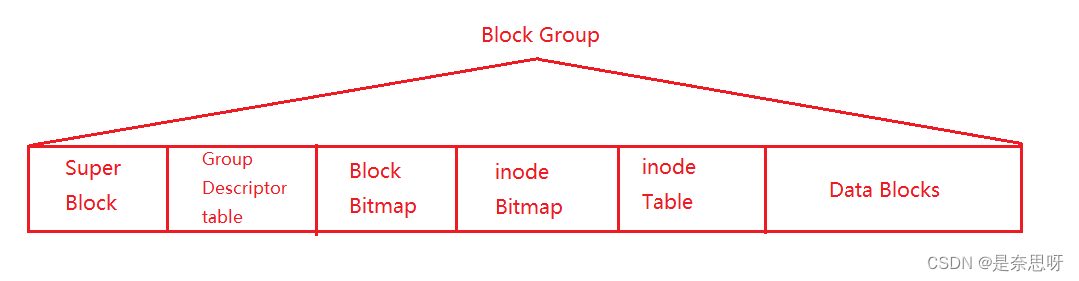
Super Block:这里存放文件系统相关信息,如 block 和 inode 总量等,每个分组都有相同的信息,后续中的Block Group不一定有这个分块,但如果有就作为备份;
Data Blocks:这里有多个数据块,用来存放文件信息;
inode Table:这里存放文件属性,每个文件都有一个inode结构体,这个结构体中有文件相关信息,如inode编号(唯一标识)、文件大小等;
inode Bitmap:也称inode位图,记录每个inode是否已经被使用,若被使用则用1标识,若未被使用用0标识;
Block Bitmap:也称块位图,也是记录每个块是否被使用,标记方法与inode位图相同;
Group Descriptor Table:用来记录当前组相关信息,如inode从哪开始,Block又从哪开始;
补充:
1、我们的操作系统是以4KB作为单位进行IO,我们的磁盘的扇区大小为512Byte,因此我们每个块的大小为4KB,也就是8个扇区;
2、一个文件要对应有一个 inode ,却可能对应多个Block,那么如何通过 inode 找到对应的Block呢?
inode为文件属性,其中除了有inode编号,还有其块编号,如下所示,我们可以这样表示一个inode;
struct inode
{
// 文件大小
// inode编号
// 文件时间等
int blocks[15]; // 该文件block编号
};这样我们就可以通过 inode 找到存储文件内容的 block 块,有的小伙伴可能有疑惑了,假如一个文件有几GB升值几十GB,那么数组大小这才15是不是不够用,实际上,我们可以通过 inode 中 blocks 数组找到对应的块,然后在块中我们不存放文件内容,而是作为二级索引,此时我们可以用一个4KB大小的内存来指向另一个块,这时就可以完美解决这个问题了;
3、inode与文件名的关系
我们以前学习文件权限是了解过文件可以分为很多类;其中有一类就是目录;所以说目录也是文件中的一种;而以前,我们也说过目录的x权限决定我们是否可以进入一个目录,w权限决定我们是否可以在该目录下创建/删除文件,r权限决定我们是否可以查看当前目录有哪些权限;接下来,我通过上面磁盘文件的知识带着大家更深层次理解这些内容;
问题:目录文件的内容是什么?
前面我们说过,目录是文件,那么目录肯定有自己的inode,inode中存放该目录下的各种属性,如权限、时间等;而目录的内容,其 data block 中记录的是该目录下所有文件的文件名与 其inode 的映射关系;而且,每个目录下,文件名不可以重名,因此无需担心映射关系错误;这就不难理解我们目录的 r 权限了,对于普通文件来说,文件里的数据就是文件内容,r 权限限制阅读其内容,而对于目录来说,目录下的文件映射是其内容,故 r 权限限制查看目录下文件情况;w 权限同样也很好理解了,我们在目录下创建/删除文件不就是在目录下添加映射关系吗?而映射关系不就是目录文件的内容吗?
问题:我们创建文件时,做了那些事情?
首先,我们创建一个文件,我们必须要申请一个inode,并填充该文件相关属性信息,接着我们要修改 inode Bitmap 上对应的位置修改为1,标识该inode已经被使用了;若文件还有内容,我们需要修改 block Bitmap 上对应的位置,并在inode中记录block块编号;最后我们在当前目录下,建立文件名与inode编号对应关系的映射;
问题:那我们删除文件呢?又会做哪些事情?
首先,我们通过当前目录文件的文件内容,即文件名与inode编号映射关系找到对应的inode,接着通过inode结构体中block块编号数组得知属于当前文件的block编号,然后再Block Bitmap 上将对应编号置为0;接着再将inode Bitmap 中对应的位置也置为0;最后删除当前目录下文件名与inode编号对应关系即可;
问题:那么我们删除的文件还能进行恢复吗?
这个还真是有可能的,我们经常看到电影里,警察拿着磁盘想恢复磁盘数据,得到坏人的行凶证据;我们直到删除的原理就是修改对应的bitmap,使其对应的 block 与 inode 为无效,若我们删除文件后,其原来的inode与block并未被使用,我们只要找到被删除文件的inode,就可以在这个inode上找到对应的block编号,最后不就将整个文件恢复了吗?
二、软链接与硬链接
1、如何创建软连接与硬链接文件
创建软连接文件:ln -s 目标文件名 形成软连接文件名
创建硬链接文件:ln 目标文件名 形成硬链接文件名
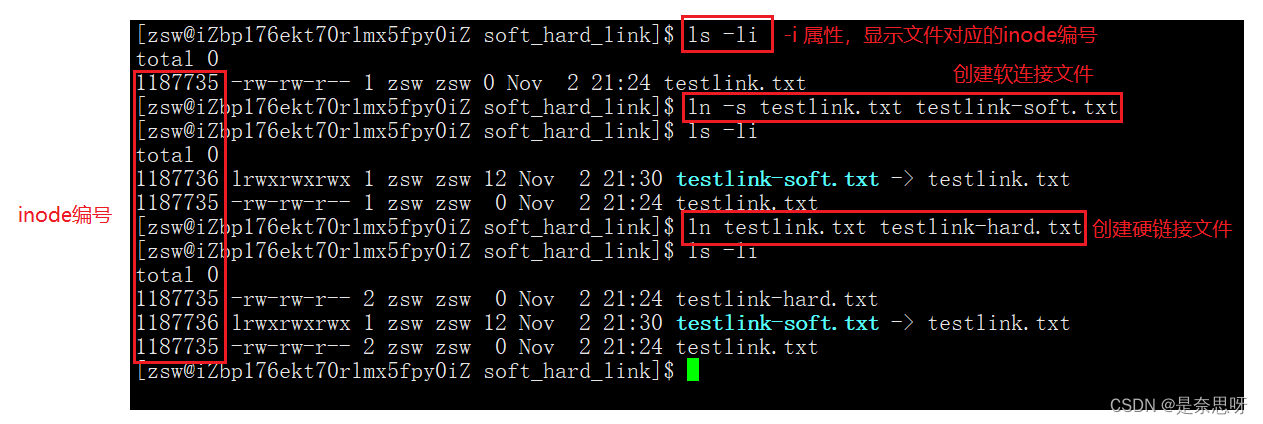
2、理解软连接
我们仔细观察软连接的 inode 编号与原文件的 inode 编号,我们发现两者的编号是不同的,说明我们的软连接是一个单独独立的文件,但是其文件内容为指向原文件的路径;软连接更像我们window下的快捷方式;
3、理解硬链接
我们仔细观察上图,硬链接文件的 inode 编号与源文件的 inode 编号是一样的!但是读写权限后面的那一项的数字由 1 变成了 2;这个数字就是我们硬链接文件的个数;初始值为1;这个属性记录在 inode 结构体里,每当我们创建一个硬链接文件,这个数字都会加1;那么硬链接的本质到底是什么呢?
首先我们要清楚,我们创建一个硬链接文件做了什么?当我们创建一个硬链接文件时,实际上,我们仅仅只是在当前目录下增加一对由文件名到 inode 编号的映射关系;这也就是硬链接的本质!
硬链接的应用:
前面我们学习软连接,发现软连接的主要作用就是快捷方式;而我们的硬链接呢?我们通过目录来学习硬链接的应用;我们首先在当前目录创建一个dir目录;如下所示;

我们发现 dir目录 的硬链接数就是2,我们还没有自己手动创建硬链接呢?这怎么就变成2了呢?不知道大家还是否记得我们创建一个目录时,默认会有两个文件,一个是当前目录.(点),另一个是上级目录..(点点),其实点文件就是当前目录的硬链接,点点文件就是上级目录的硬链接;我们进入dir目录,查看其 inode 编号;如下所示;

果然如我们所料,点点文件我就不带着大家一起验证了,有兴趣可以自己下去验证;相对路径的使用就是我们硬链接的使用场景!
三、动态库与静态库
关于动静态库的相关概念已经在前面介绍了,这里就不详细谈了,默认大家已经掌握,如果这里有疑问可以看下面这篇文章,关于静态链接与动态链接部分;
Linux | gcc/g++的使用-CSDN博客
1、静态库
我们知道链接静态库的本质就是将静态库的代码进行拷贝操作;那么我们如何制作一个静态库呢?
(1)静态库的制作
首先,我们得知道,若对于多个文件来说,如下图所示;

其中,main.c中存放主代码,add.c中存放相加函数的定义,add.h中存放相加函数的声明,print.c中存放打印函数的定义,print.h中存放打印函数的声明,如下所示;
// add.h 文件
#pragma once
extern int add(int x, int y);// add.c文件
#include "add.h"
int add(int x, int y)
{
return x + y;
}// print.h文件
#pragma once
#include <stdio.h>
extern void print(const char* str);// print.c文件
#include "print.h"
void print(const char* str)
{
printf("%s\n", str);
}// main.c文件
#include <stdio.h>
#include "print.h"
#include "add.h"
int main()
{
print("hello world");
int ret = add(10, 20);
printf("ret:%d\n", ret);
return 0;
}问题来了,假如我们将上述print.c和add.c编译成.o文件,那么我们可以把它们的.o文件和.h文件给别人直接用吗?
当然可以,我们一旦有了.o目标文件和.h头文件,我们就可以在我们的main.c链接时找到对应函数所对应的文件;
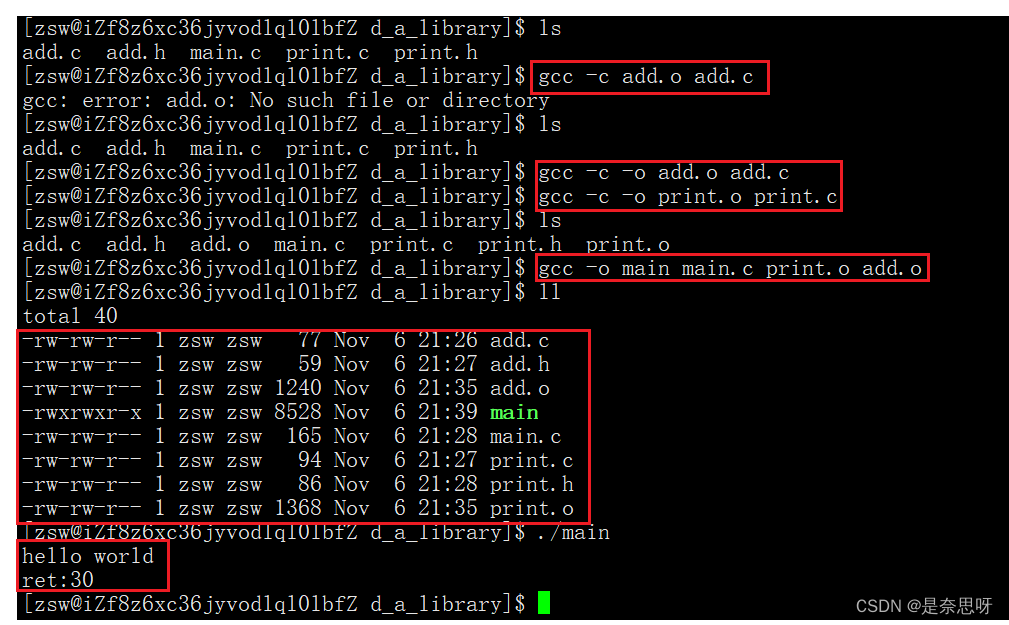
我们发现,我们只要有目标文件和头文件,我们就可以使用该文件中的方法;那么静态库也是类似原理,只不过会将目标文件进行归档;归档指令如下;
ar -cr lib静态库名.a 归档文件列表
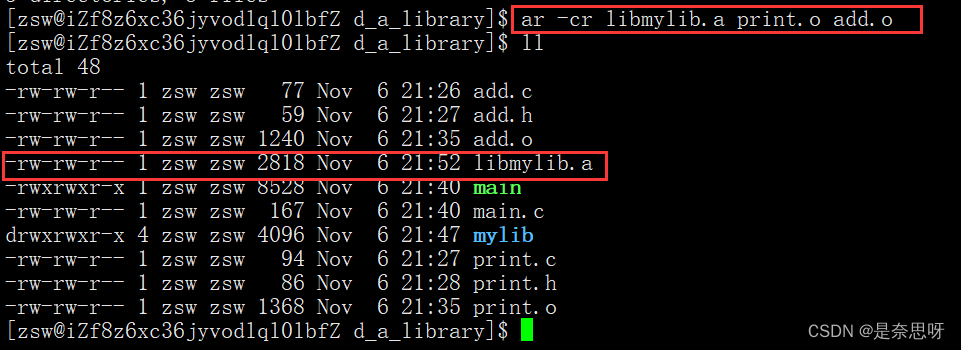
我们将头文件移动到mylib/include 文件夹中,库文件移动到 ./mylib/lib 文件夹中;

我们再创建要给uselib的目录,并将main.c移动到uselib文件夹中,我们将在这个目录下编译main.c,使用我们自己的静态库;
(2)静态库的使用
前面,我们学会了制作静态库,那么静态库应该如何使用呢?这里将介绍三种方法;
方法一:将我们写的静态库拷贝一份到系统默认搜索路径中;头文件的默认搜索路径为 /usr/include ,库文件的默认搜索路径为 /lib64 or /usr/lib64
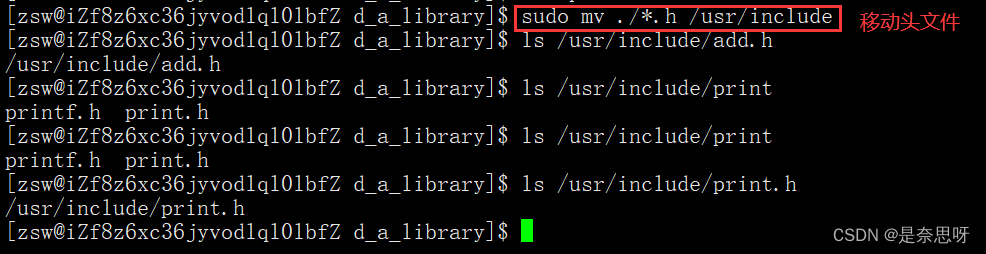

接下来我们直接编译main.c文件;

我们发现我们还是无法编译,报错说找不到print和add函数,这是因为我们自己写的库是第三方库,我们需要指定我们要用哪个库,因此我们需要使用 -l + 库名 指定我们要用哪个库,之所以我们C语言、C++不需要指定是因为我们的gcc、g++编译器就是基于这些语言而写出来的编译器,故无需增加这个选项;我们假如 -l 选项后编译运行如下图;(注意-l中的 l 是L的小写,库名要去掉前缀lib与后缀)

方法二:使用gcc提供选项;我们可以加上 -I 头文件路径 -L 库文件路径 -l库文件名 ,通过这三个选项来找到静态库并编译;(注意第一个选项是大写的 i,第三个选项是小写的 L)

2、动态库
(1)动态库的制作
在学习制作动态库之前,我们需要了解我们只有使用动态链接时才会使用动态库,动态链接的原理是将我们的动态库也加载进内存中,并映射到需要该动态库的进程地址空间中的共享区,当有另外一个进程也想使用这个动态库时,我们仅需增加页表映射关系即可,如下图所示;

使用动态库的优势很明显,节省内存,我们整个内存中仅需一份动态库代码即可,但是随之也带来了不少问题;
其一,我们动态库文件只要出了问题,所有需要动态库文件的可执行程序都不能运行了;
其二,我们在编译阶段我们就会存在地址的概念,而若我们使用编译出绝对地址,也就意味着我们要在进程地址空间预保留这个空间的地址;这显然造成了极大的浪费,因此我们必须生成的地址为与位置无关的地址;也就是偏移地址;这时才能保证我们在与进程地址空间建立页表映射时,映射到共享区的任意位置;
有了上面的只是铺垫,我们要制作一个动态库就要先生成与位置无关的目标文件;我们要学习gcc中的一个新选项;
-fPIC:生成与位置无关的目标文件;

此时我们需要将这些目标文件进行打包,封装成一个动态库;我们这里使用gcc的选项即可;
-shared:生成共享库(动态库);

(2)动态库的使用
我们依然将这个动态库放到 mylib/lib 目录下;然后在use中编译main.c来使用这个动态库;动态库的使用依然有很多方法,这里不一一演示了;
方法一:将头文件和库文件放到系统默认查找的目录下;头文件放到 /usr/include 目录下,库文件放到 /lib64 或 /usr/lib64 目录下;跟静态库一样,这里就不演示这种方法了;
方法二:gcc 选项来使用动态库,这里也与上面使用静态库相同;但是这里有一个细节,虽然我们可以编译通过,但是我们无法成功运行;关于这个问题,我们在方法三进行介绍;
方法三:修改环境变量
这里我们要修改三个全局变量,如下所示;
LIBRARY_PATH:在链接时库文件搜索路径!
LD_LIBRARY_PATH:在运行时动态库文件搜索路径!
C_INCLUDE_PATH:在编译时,头文件搜索路径(针对C语言,C++用 CPLUS_INCLUDE_PATH)

注意,这里我们可通过env指令查看我们的环境变量是否添加有误;

这时可能就有小伙伴疑惑了,我们为什么还要指定运行时搜索环境变量的路径呢?这个也就是我们直接使用方法二遗留下的问题;首先我们要明确的在使用gcc编译时,我们 -I 选项是为了告诉gcc我们头文件应该在哪找,-L选项告诉gcc编译器我们的库文件在哪里找,-l 告诉gcc我们的库文件名是什么?而我们的操作系统并不知道进程对应第三方库文件在哪?
为什么我们操作系统要知道我们第三方库在哪呢?我们回顾动态链接的过程,我们写的程序代码和数据要加载进内存,我们的动态库文件也要加载进内存!既然我们要知道第三方库的位置,我们告诉操作系统,所以这里要添加 LD_LIBRARY_PATH 这个环境变量;
但是我们通过export导入的环境变量只是局部的,只存在当前shell下,那么我们想要我们的环境变量持久化怎么办呢?
1、修改家目录中的 .bashrc 文件(持久化环境变量)

这样每次登录时,会自动执行我们添加的指令;修改完成后,我们需要执行下述命令;
source ~/.bashrc
2、修改 /ect/ld.so.conf.d 目录下文件
我们仅仅只需要在这个目录下自己创建一个文件,然后将动态库路径放到这,我们运行时就可以找到这个动态库了;

写完以后记得使用以下指令更新我们的配置文件;
sudo ldconfig

编译后运行,我们可以看到正确结果,并且我们也可以通过ldd指令查找到

我们也可以再次实验,将我们刚才在 /ect/ld.so.conf.d 目录下创建的文件删除,看是否还可以正常运行;