文章目录
- 摘要
- 1、简介
- 2、相关研究
- 2.1、用于更好性能的架构设计
- 2.2、结构重参数化
- 2.3、权重重参数化方法
- 3、重参数化的重聚焦卷积
- 3.1、深度RefConv
- 3.2、普通的RefConv
- 3.3、重聚焦学习
- 4、实验
- 4.1、在ImageNet上的性能评估
- 4.2、与其他重参数化方法的比较
- 4.3、目标检测和语义分割
- 4.4、消融实验
- 4.5、REFCONV减少通道冗余
- 4.6、RefConv 平滑损失景观
- 5、结论
- Appendix A: RefCONV强化了核心骨架
- 附录B:在其他数据集上对RefConv的性能评估
- 附录C:RefConv的训练动态
- 附录D:仅使用部分训练数据重聚焦学习
- 附录E:PyTorch中的代码
摘要
论文链接:http://arxiv.org/pdf/2310.10563.pdf
我们提出了一种可重参数化的重新聚焦卷积(RefConv),作为常规卷积层的替代品,它是一种即插即用的模块,可以在不引入任何推理成本的情况下提高性能。具体而言,给定一个预训练模型,RefConv将可训练的重新聚焦变换应用于从预训练模型继承的基核,以在参数之间建立连接。例如,深度方向的RefConv可以将卷积核的特定通道的参数与另一个核的参数关联起来,即让它们重新聚焦到模型的其他部分,而不是仅关注输入特征。从另一个角度来看,RefConv利用预训练参数中编码的表示作为先验,重新聚焦它们以学习新的表示,从而增强了现有模型结构的先验,进一步增强了预训练模型的表示能力。实验结果表明,RefConv可以在不引入任何额外推理成本或改变原始模型结构的情况下,显着提高多种基于CNN的模型的性能(在ImageNet上最高提高1.47%的top-1准确率),用于图像分类、目标检测和语义分割。进一步的研究表明,RefConv可以减少通道冗余并平滑损失景观,这解释了其有效性。
1、简介
卷积神经网络(CNN)确实是用于各种计算机视觉任务的主要工具。提高CNN性能的主流方法是精心设计模型结构,包括宏观模型架构[19; 23; 36]和微观即插即用组件[22; 47; 34]。CNN的成功部分归功于操作的局部性。对于空间维度,一个典型的例子是卷积的滑动窗口机制,它利用图像的局部先验。对于通道维度,逐深度卷积(简称为DW conv)使用独立的2D卷积核在每个输入通道上操作,与常规密集卷积相比,大大减少了参数和计算量(这意味着每个输出通道关注每个输入通道,即组数是1)。
本文提出从另一个角度来提高CNN的性能-增强现有结构的先验。例如,可以将DW conv视为多个相互独立的2D卷积核(称为核通道)的连接,特定核通道的唯一输入是特征图的相应通道(称为特征通道),这可能会限制模型的表示能力。我们希望在不改变模型的定义或引入任何推理成本的情况下添加更多先验(例如,让核通道与其他特征通道一起操作将使操作不再是DW conv),因此我们提出了一种重新参数化技术,通过使模型的参数关注其他结构的参数来增强模型结构的先验。
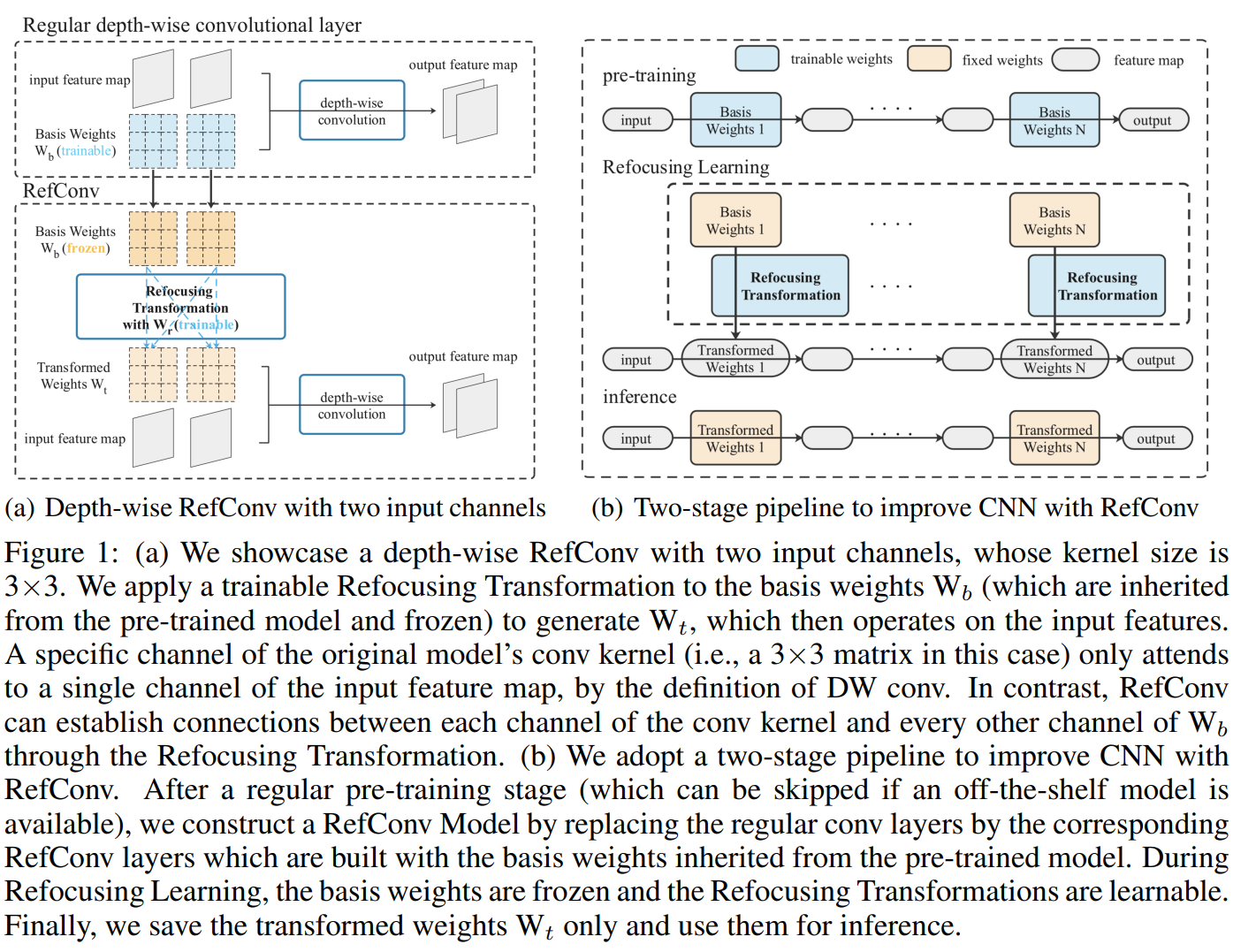
具体来说,我们提出了一种名为“重参数化重聚焦”的技术,在现有结构参数之间建立了联系。给定一个预训练的CNN,我们用我们提出的重参数化重聚焦卷积(RefConv)替换其卷积层,如图1所示。 再次以深度卷积为例,预训练CNN的DW conv将被替换为RefConv,其中冻结预训练的卷积核作为基础权重 W b W_b Wb,并对 W b W_b Wb应用一个可训练的操作,称为重聚焦变换T(·),以生成新的DW conv核,称为变换后的权重 W t W_t Wt。我们使用重聚焦权重 W r W_r Wr来表示由Refocusing Transformation引入的可训练参数,这样 W t W_t Wt= T( W b W_b Wb, W r W_r Wr)。然后我们使用 W t W_t Wt而不是原始参数来对输入特征进行操作。换句话说,我们使用了卷积核的不同参数化。通过适当设计的重聚焦变换,我们可以将特定核通道的参数与其它核通道的参数联系起来,即让它们聚焦于模型的其它部分(而不仅仅是输入特征)以学习新的表示。由于后者与其他特征通道一起训练,因此它们编码了由其他特征通道浓缩的表示,这样我们就可以间接地建立特征通道之间的联系,而不能直接实现(根据DW conv的定义)。经过构建模型(RefConv模型)的训练过程(称为重聚焦学习)后,我们使用训练后的重聚焦权重和冻结的基础权重生成最终的变换后权重,并将其保存仅用于推理。最终,所得模型(重参数化的RefConv模型)将提供比原始模型更高的性能,同时保持相同的推理成本。此外,由于RefConv中的重聚焦变换是在基础权重而不是训练示例批次的基础上进行的,因此重聚焦学习过程具有计算效率高和内存节省的特点。
除了DW conv之外,RefConv可以很容易地推广到其他形式,例如分组和密集卷积。作为一个通用的设计元素,RefConv可以应用于具有不同结构的任何现成CNN模型。我们的实验结果表明,RefConv可以在图像分类、目标检测和语义分割等多个ConvNets上实现明确的性能提升。例如,RefConv将MobileNetv3 [20]和ShuffleNetv2 [38]的性能提高了1.47%和1.26%,这是在ImageNet上实现的最高精度。需要强调的是,实现这样的性能提升不需要额外的推理成本或更改原始模型结构。我们进一步寻求解释RefConv的有效性,并发现RefConv可以增大核通道对之间的KL散度,这表明RefConv可以通过关注其他通道来减少通道相似性和冗余[56; 46]。这使得RefConv能够学习更多样化的表示,并增强模型的代表性能力。
此外,观察发现,具有RefConv的模型具有更平滑的损失景观,表明其具有更好的泛化能力[33]。
我们的贡献总结如下。
- 我们提出了重参数化的重聚焦,通过与学习到的核建立连接来增强现有结构的先验。因此,重参数化的核可以学习更多样化的表示,从而提高训练CNN的表示容量。
- 我们提出了RefConv来替换原始卷积层,并通过实验验证RefConv可以在没有额外推理成本或改变模型结构的情况下,明显提高各种主干模型在ImageNet上的性能。此外,RefConv还可以改进ConvNets在目标检测和语义分割方面的性能。
- 我们证明了RefConv可以减少通道冗余并平滑损失景观,从而解释了其有效性。
2、相关研究
2.1、用于更好性能的架构设计
用于更好性能的CNN结构的设计包括特定的宏观架构和通用的微观组件。宏观架构的代表包括VGGNet [43]、ResNet [19]等。微观组件,例如SE block [22]、CBAM block [47]等,通常是架构无关的[9],可以融入各种模型并带来通用优势。然而,所有这些模型设计都改变了预定义的模型结构。相比之下,RefConv关注卷积核的参数,并打算增强现有结构的先验。由于RefConv不改变模型结构,它是架构或组件设计进步的补充。
2.2、结构重参数化
结构重参数化[9; 10; 11; 13; 7; 12]是一种代表性的重参数化方法,用于将结构参数化为从另一个结构转换而来的参数。通常,它在训练过程中为模型添加额外的分支来提高性能,然后等效地将训练结构简化为与原始模型相同的结构进行推理。例如,ACNet [9]在训练时构建两个额外的垂直和水平卷积分支,并在推断时将它们转换为原始分支。RepVGG [13]在训练期间构建与3 \times 3卷积平行的恒等映射,并在推断时将快捷方式转换为3 \times 3分支。与上述结构空间中的设计类似,结构重参数化构建了额外的分支来处理特征图,这在训练期间带来了相当大的额外计算和内存成本。相比之下,RefConv中的额外转换仅应用于基权重,与结构重参数化相比,计算效率更高,内存更节省。
2.3、权重重参数化方法
作为代表性的权重重参数化方法,DiracNet [50]将卷积核编码为归一化核和恒等张量的线性组合。权重归一化包括标准归一化[41]、中心归一化[25]和正交归一化[24],它们归一化权重以加速和稳定训练。这些权重重参数化方法是独立于数据的。动态卷积[54; 4],例如CondConv [49]和ODConv [30],可以视为数据依赖的权重重参数化,因为它使用专门设计的过度参数化的超网络[37; 16],这些超网络将数据作为输入并为特定数据生成特定权重。然而,由于对输入数据的依赖,这样的额外超网络在推理中不能被移除,从而在训练和推理中引入了大量的额外参数和计算成本。
Refocusing Learning使用一些元权重(而不是数据)派生出新的权重,然后利用新权重进行计算,因此它可以归类为数据独立的权重重参数化方法。
3、重参数化的重聚焦卷积
在本节中,我们首先详细阐述RefConv的设计,作为常规深度卷积的替代方案,然后描述如何将其推广到分组或密集情况。
3.1、深度RefConv
将输入通道数记为 C i n C_{i n} Cin,输出通道数记为 C o u t C_{out} Cout,并将组数记为g。深度卷积的配置为 C = C i n = C o u t = g C=C_{in}=C_{out}=g C=Cin=Cout=g。假设核大小为K,因此基权重和变换权重可以表示为 W b , W t ∈ R C × 1 × K × K \mathrm{W}_{b}, \mathrm{~W}_{t} \in \mathbb{R}^{C \times 1 \times K \times K} Wb, Wt∈RC×1×K×K。请注意,我们希望不改变模型的推理结构,因此 W t W_t Wt的形状应该与 W b W_b Wb相同。
我们希望对重聚焦变换T进行适当的设计,将冻结的 W b W_b Wb变换为 W t W_t Wt。对于 W t W_t Wt的特定通道,这样的函数T应该建立它与 W b W_b Wb每个通道之间的连接。在本文中,我们建议使用密集卷积作为T,这样重聚焦变换就可以通过密集卷积的核张量参数化,即 W r ∈ R C × C × k × k \mathrm{W}_{r} \in \mathbb{R}^{C \times C \times k \times k} Wr∈RC×C×k×k。默认情况下,我们使用k=3,因此需要填充=1以确保 W t W_t Wt具有与 W b W_b Wb相同的形状。直观地说,这样的操作可以看作是用一个由 W r W_r Wr参数化的3×3滑动窗口扫描基础权重,以提取表示来构建所需的核,就像我们用常规卷积核来扫描特征图以提取模式一样。由于这样的卷积是密集的,所以建立了通道间的连接,使得 W t W_t Wt的每个通道都与 W b W_b Wb的所有通道相关联,如图1(a)所示。正如这个比喻所表明的,可以将 W b W_b Wb视为Refocusing Transformation的输入“特征图”,并可以借鉴模型结构设计文献中的新思想来更仔细地设计它。例如,我们可以采用非线性或更高级的操作,可能会获得更好的性能。在本文中,我们使用单个卷积,因为它简单、直观且足够有效。我们计划在未来改进重聚焦变换的实现。
首先,虽然MCIS通常在计算成像社区[22,1]中用于捕获系统PSF或获取成对图像数据,但大多数商品显示器缺乏高动态范围,这是模拟UDC系统中真实的衍射伪影所必需的。因此,他们使用的PSF具有不完整的旁瓣,并且图像的伪影较轻,例如模糊、雾和眩光。在我们的工作中,我们考虑在数据生成和PSF测量中使用HDR,以便我们能够正确处理实际场景。其次,作者在他们的设置中使用手动覆盖相机的常规OLED,而不是实际的刚性UDC组件,并对准分子数据进行实验和评估。因此,显示相对于传感器平面的任何微小移动、旋转或倾斜都会导致可变的PSF,从而阻止他们的网络在不了解PSF内核的情况下处理可变的退化。为了最小化领域差距,我们使用了世界上第一台生产UDC设备之一进行数据收集、实验和评估。最后,尽管作者在数据合成中捕获并使用了PSF,但他们通过简单的UNet将UDC图像恢复问题形式化为盲去卷积问题,而没有明确利用PSF作为有用的领域知识。相反,我们将PSF作为重要支持信息用于我们提出的DISCNet中。
此外,受到残差学习的启发[19],我们希望Refocusing Transformation能够学习相对于基础权重的增量,而不是原始映射,就像我们在ResNets中使用残差块来学习相对于基础特征图的增量一样。因此,我们添加了一个类似的“恒等映射”,使得
W
t
=
W
b
∗
W
r
+
W
b
,
(1)
\mathrm{W}_{t}=\mathrm{W}_{b} * \mathrm{~W}_{r}+\mathrm{W}_{b}, \tag{1}
Wt=Wb∗ Wr+Wb,(1)
这里 * 表示卷积操作符。
3.2、普通的RefConv
在处理一般的密集或分组RefConv时,我们将基础权重和变换后的权重表示为 W b , W t ∈ R C o u t × C i n g × K × K \mathrm{W}_{b}, \mathrm{~W}_{t} \in \mathbb{R}^{C_{o u t} \times \frac{C_{i n}}{g} \times K \times K} Wb, Wt∈RCout×gCin×K×K ,我们对为深度RefConv设计的Refocusing Transformation进行了泛化。就像深度RefConv将 C out C_{\text {out }} Cout 基础核通道转换为 C out C_{\text {out }} Cout 变换核通道一样,在一般情况下,我们将 C out C_{\text {out }} Cout 基础核切片(每个具有 C in g \frac{C_{\text {in }}}{g} gCin 通道)转换为 C out C_{\text {out }} Cout 变换核切片。我们仍然使用卷积作为Refocusing Transformation,因此需要将其配置为输出通道 = 输入通道 = C out × C i n g C_{\text {out }} \times \frac{C_{i n}}{g} Cout ×gCin ,如果 \mathrm{W}_{b} 是密集的(g=1),则这可能很大。为了减少此类Refocusing Transformation的参数,我们将其进行分组,并引入组数 G 作为超参数,这样它的参数数量就是 C o u t 2 C i n 2 k 2 g 2 G \frac{C_{o u t}^{2} C_{i n}^{2} k^{2}}{g^{2} G} g2GCout2Cin2k2 。
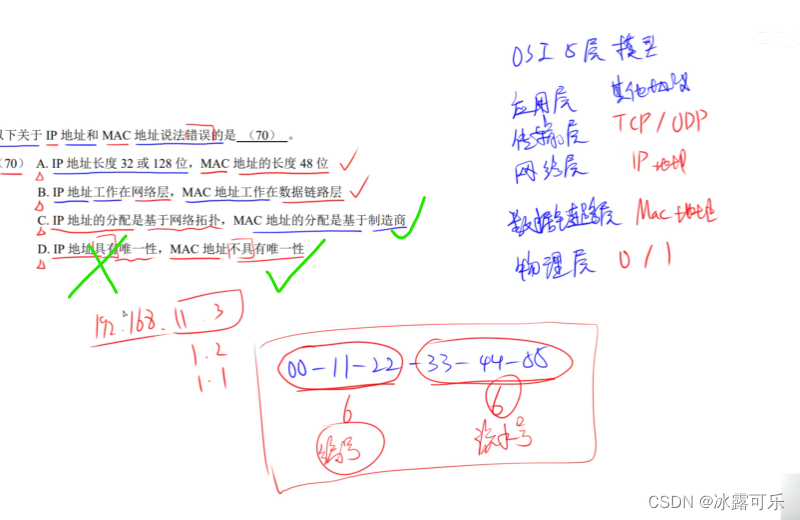
我们提出一个公式来确定 G:
G
=
C
o
u
t
C
i
n
g
2
(2)
G=\frac{C_{o u t} C_{i n}}{g^{2}} \tag{2}
G=g2CoutCin(2)
这种设计使Refocusing Transformation成为原始卷积的补充:较大的 g g g 表示原始卷积较稀疏,需要更多的跨通道连接由Refocusing Transformation建立;根据方程2,较大的 g g g 会导致较小的 G G G ,这正好符合这样的需求。
例如,如果 W b \mathrm{W}_{b} Wb 是密集的,我们有 G = C o u t C i n G=C_{out} C_{in} G=CoutCin 和 W r ∈ R ( C o u t C i n ) × 1 × k × k \mathrm{W}_{r} \in \mathbb{R}^{(C_{out} C_{in}) \times 1 \times k \times k} Wr∈R(CoutCin)×1×k×k ,这是一个具有 C o u t C i n C_{out} C_{in} CoutCin 个核通道的深度卷积,因此它只聚合跨越空间维度的学习表示,而不执行跨通道重新组合(由于 W b \mathrm{W}_{b} Wb 可以自己跨越特征通道而不期望这样做)。相反,如果 W b \mathrm{W}_{b} Wb 是深度卷积核,我们会有 G = 1 G=1 G=1 和 W r ∈ R C o u t × C i n × K × K \mathrm{W}_{r} \in \mathbb{R}^{C_{out} \times C_{in} \times K \times K} Wr∈RCout×Cin×K×K ,这正是第3.1节中讨论的密集卷积核,它会完全建立所需的跨通道连接。
我们想指出的是,RefConv在训练过程中只增加了少量的额外计算。假设特征图的大小为 B × C_{in} × H × W ,原始卷积的FLOPs为
B
H
W
C
i
n
C
o
u
t
K
2
g
\frac{B H W C_{in} C_{out} K^{2}}{g}
gBHWCinCoutK2 ,而Refocusing Transformation的FLOPs仅为
K
2
C
o
u
t
2
C
i
n
2
k
2
g
2
G
=
K
2
k
2
C
i
n
C
o
u
t
\frac{K^{2} C_{out}^{2} C_{in}^{2} k^{2}}{g^{2} G}=K^{2} k^{2} C_{in} C_{out}
g2GK2Cout2Cin2k2=K2k2CinCout ,与批次大小 B 无关。例如,假设
B
=
256
,
H
=
W
=
28
,
C
i
n
=
C
o
u
t
=
g
=
512
,
K
=
3
B=256,H=W=28,C_{in}=C_{out}=g=512,K=3
B=256,H=W=28,Cin=Cout=g=512,K=3(在ImageNet上训练的常规CNN中DW层的常见情况),原始卷积的FLOPs为
925
M
925 \mathrm{M}
925M ,而Refocusing Transformation的FLOPs仅为
21
M
21 \mathrm{M}
21M 。包括恒等映射和必要的重塑操作的详细计算在图2中有说明。
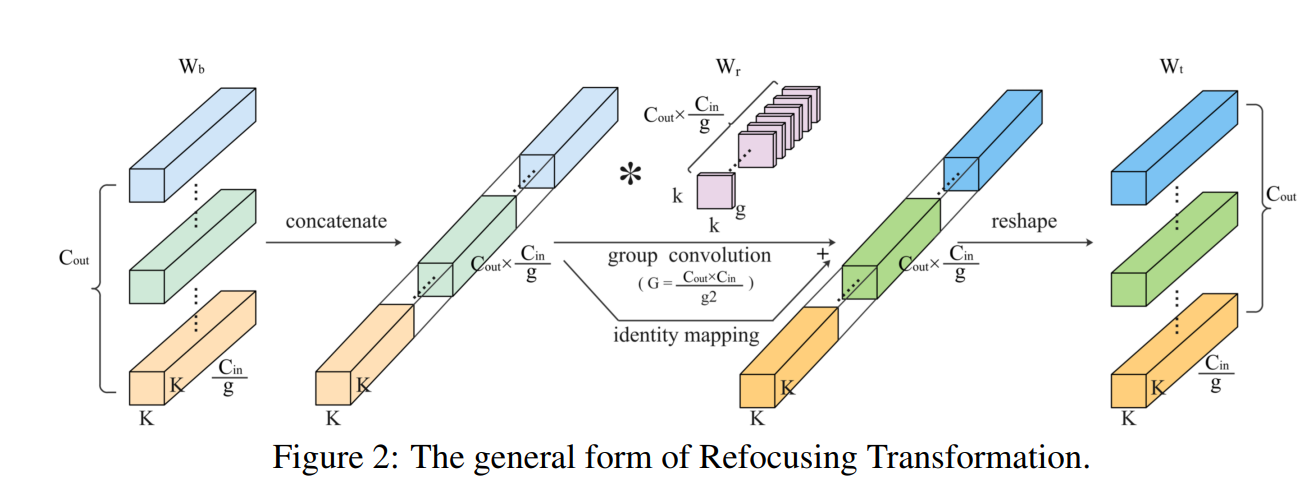
3.3、重聚焦学习
重聚焦学习以给定的预训练CNN开始,该CNN可以通过常规预训练阶段获得(如果我们没有可用的现成模型)。我们通过用相应的RefConv层替换常规卷积层来构建RefConv模型。我们不替换1x1卷积层,因为它们在通道上是密集的,不编码空间模式,因此没有必要建立跨通道连接或从中提取空间表示。RefConv层使用从预训练模型继承的 W b W_b Wb和用Xavier随机初始化初始化的 W r W_r Wr构建。此外, W r W_r Wr可以初始化为零,使初始模型与预训练模型等效(因为每个RefConv的 W t W_t Wt= W b W_b Wb),这在第4.4节中进行了测试。
在重聚焦学习期间,RefConv层计算变换后的权重 W t = T ( W b , W r ) W_t=T(W_b,W_r) Wt=T(Wb,Wr),其中 W b W_b Wb是固定的, W r W_r Wr是可学习的,并使用 W t W_t Wt对输入特征进行操作。因此,梯度将通过 W t W_t Wt反向传播到 W r W_r Wr,这样 W r W_r Wr将由优化器更新,就像常规参数化模型的训练过程一样。
在重聚焦学习后,我们使用 W b W_b Wb和训练的 W r W_r Wr计算最终变换后的权重。我们只保存最终变换后的权重,并使用它们作为原始CNN的参数进行推理。这样,推理时的模型将与原始模型具有完全相同结构。
4、实验
4.1、在ImageNet上的性能评估
数据集和模型。首先,我们在ImageNet上进行大量实验,以验证RefConv在提高CNN的表示能力和性能方面的有效性[40]。ImageNet是计算机视觉领域最广泛使用但最具挑战性的实际基准数据集之一,由1000个类别的128万张图像组成,用于训练,5万张图像用于验证。我们测试了多个具有代表性的CNN架构,涵盖不同类型的卷积层(即DW conv、group-wise conv和dense conv)。测试的CNN包括MobileNetv1、v2、v3 [21;42;20],MobileNeXt [55],HBONet [31],EfficientNet [44],ShuffleNetv1、v2 [53;38],ResNet [19],DenseNet [23],FasterNet [1]和ConvNeXt [36]。
配置。对于训练基准模型,我们采用具有0.9动量的SGD优化器、批量大小为256和权重衰减为4 × 10^{-5},按照常见的做法[12]。我们使用具有5个epoch预热的可变学习率调度,初始值为0.1,并在100个epoch内使用余弦退火。数据增强使用随机裁剪和水平翻转。输入分辨率为224 × 224。对于重聚焦学习,我们使用Xavier随机初始化来初始化重聚焦变换的权重[14],并冻结从相应预训练模型继承的基础权重。重聚焦学习使用与基准相同的优化策略。此外,我们对最终模型架构没有任何影响。
性能改进。表1显示了实验结果。可以看出,RefConv可以显著提高各种基准模型的表现,并且提升幅度相当明显。例如,RefConv将MobileNetv3-S(DW Conv)、ShuffleNetv2(group-wise conv)和FasterNet-S(DW和dense conv)的top-1准确率提高了1.47%、1.26%和1.15%。
参数数量。表1还显示了训练过程中的总参数数量。基准模型的训练参数与推理阶段相同,而RefConv模型在训练过程中具有额外的参数。但是,由于我们仅在推理时使用转换后的权重,因此Re-parameterized RefConv模型的推理参数数量与基准相同,完全没有引入额外的推理成本。
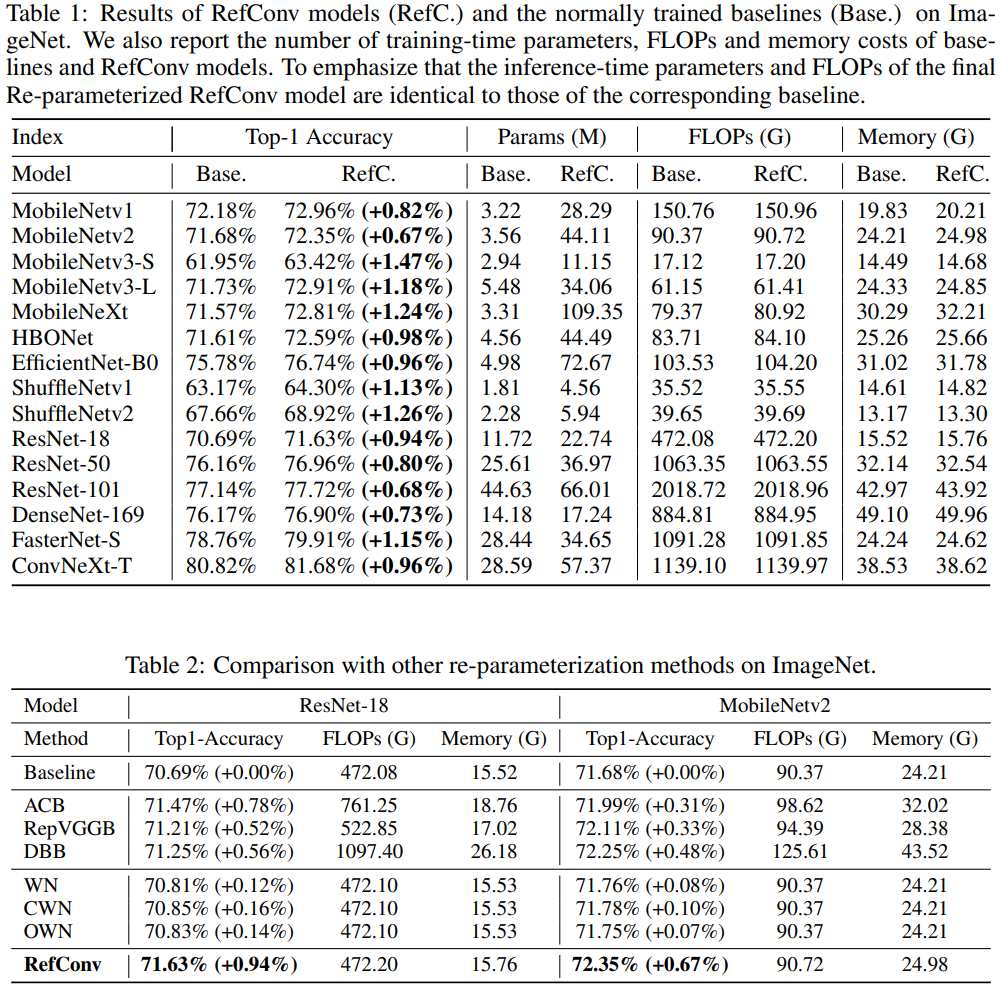
训练时FLOPs和内存成本。为了衡量RefConv在训练过程中带来的额外计算所带来的额外训练成本,我们在表1中展示了基准和RefConv模型的总训练时间FLOPs和内存成本,这些模型在四个RTX 3090 GPU上进行测试,总批量大小为256,使用全精度(fp32)。如图表所示,与基准相比,RefConv引入的额外FLOPs和内存可以忽略不计,符合第3.2节中的讨论,即由于Refocusing Transformation是在核而不是特征图上进行的,因此其计算成本是微不足道的。值得注意的是,仅训练时的RefConv需要额外的计算来生成 W t W_t Wt,而重参数化的RefConv模型在权重转换后将与基准在结构上完全相同(因为在推理时根本不会有Refocusing Transformation),在推理时完全不引入任何额外的内存或计算成本。
4.2、与其他重参数化方法的比较
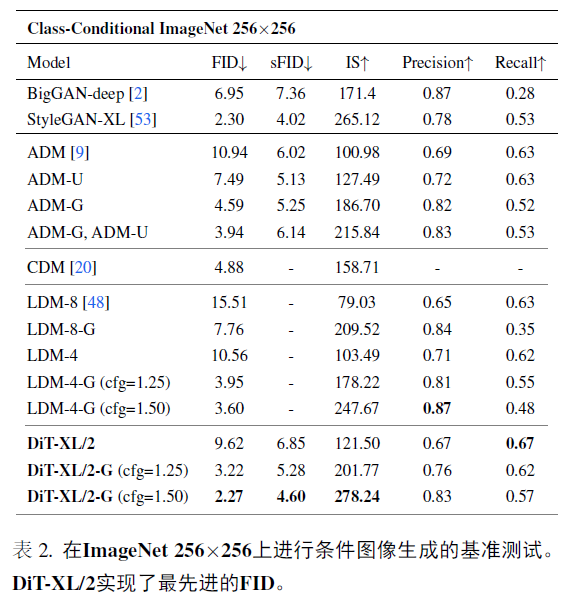
我们在ImageNet上将RefConv与其他数据无关的重参数化方法进行比较,即结构重参数化(SR,包括ACB [9],RepVGGB [13]和DBB [11])和权重重参数化(WR,包括WN [41],CWN [25]和OWN [24])。基准模型为ResNet-18和MobileNetv2。请注意,所有这些方法的推理模型都与基准相同。如表2所示,WR带来的改进微不足道,因为WR旨在加速和稳定训练。虽然SR比WR带来的性能提升更为显著,但SR由于在特征图上执行额外分支而带来了巨大的额外训练成本。此外,RefConv带来了最高的提升,同时几乎没有额外成本,这表明它优于其他数据无关的重参数化方法。
4.3、目标检测和语义分割
我们进一步将ImageNet训练的backbones转移到带有SSD [35]的Pascal VOC检测任务,并按照[55]中的配置进行,同时将它们转移到带有DeepLabv3+ [2]的Cityscapes分割任务,并按照[12]中的配置进行。表3显示,RefConv可以明显提高各种ConvNets的性能,这验证了RefConv的迁移能力。
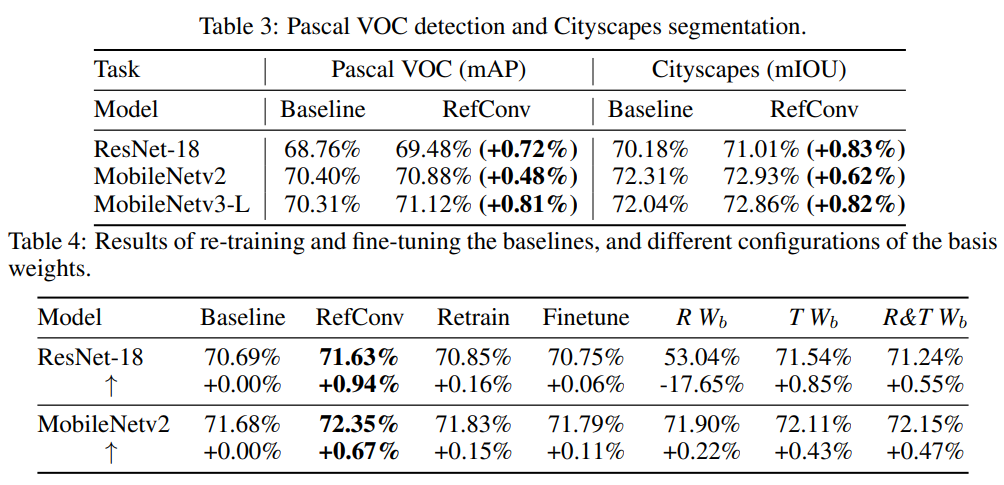
4.4、消融实验
Refocusing Learning优于简单地重新训练基准模型。为了展示Refocusing Learning相对于最简单的做法(即使用相同的训练配置再次训练模型)的优越性,我们在ImageNet上使用相同的训练配置对预先训练过的基准模型进行了第二次训练。如表4所示,重新训练模型一次几乎无法提高性能,这是意料之中的结果,因为重新训练时特定的核参数仍然无法关注其他通道(以MobileNet中的DW conv为例)或空间位置(以ResNet-18中的普通conv为例)的其他参数,因此无法学习新的表示。
Refocusing Learning也优于简单地微调基准模型。我们还对预先训练过的基准模型使用较小的学习率 1 0 − 4 10^{-4} 10−4进行了100个epoch的微调,这是一种常见的做法。如表4所示,与RefConv相比,微调仍然带来了微不足道的好处。与重新训练模型一样,简单地微调已经收敛的模型也无法学习任何新的表示。
预训练的基础权重是重要的先验知识。 W b W_b Wb是基准模型的学习权重,在重聚焦学习中保持固定。为了验证,我们随机初始化 W b W_b Wb并在重聚焦学习过程中冻结它(表4中的 R W b R W_b RWb列)。这样做仅对MobileNetv2带来了微小的改进,甚至导致ResNet-18的性能显著下降,这是预期的结果,因为预训练的基础权重可以视为引入RefConv模型的先验知识,为学习新的表示提供了良好的基础。ResNet-18退化得更加严重的现象可以解释为,它的重聚焦转换是DW 卷积(如第3.2节中讨论的),它在随机初始化的基础权重上操作。由于基础权重根本没有包含先验,因此DW conv仅通过空间聚合提取有用的表示的期望是合理的。相比之下,MobileNetv2中的DW RefConv的重聚焦转换是密集conv,即使没有先验,它也有很大的参数空间来自己学习表示。
然后我们尝试使预训练的 W b W_b Wb可训练,以便在重聚焦学习过程中同时更新 W b W_b Wb和 W r W_r Wr。表4中的TWb列显示,与标准RefConv相比没有改进,这表明维持重聚焦转换的先验知识是有利的。最后,我们将 W b W_b Wb随机初始化和可训练。表4中的R&T W b W_b Wb列显示性能低于标准RefConv。总之,我们得出结论,预训练的基础权重 W b W_b Wb是学习过程中重要的先验知识。
重聚焦权重不同的初始化。卷积神经网络的权重通常在从零开始训练模型时随机初始化。然而,对于RefConv,
W
r
W_r
Wr可以被初始化为零,使得
W
t
W_t
Wt的初始值与
W
b
W_b
Wb相同(通过式1),使初始RefConv模型等效于预训练模型。表5中的RefConv-ZI列显示了这种零初始化的结果,表明其比基线有所改进,比常规随机初始化(标记为RefConv-RI)略差。
验证RefConv中的恒等映射。我们还发现RefConv中的恒等映射是关键。表5中RefConv w/o shortcut列显示了没有捷径的RefConv的结果,其明显优于基线但不如标准RefConv。
RefConv连接独立卷积核。为了验证DW RefConv使每个独立卷积核通道的
W
t
W_t
Wt关注
W
b
W_b
Wb的其它通道,我们计算了第i通道
W
t
W_t
Wt和第j通道
W
b
W_b
Wb之间的连接程度,对于所有(i,j)对,形成一个相关矩阵。当然,由于这种通道间连接是通过滤波器
W
r
(
i
,
j
)
W_r^{(i,j)}
Wr(i,j)建立的,它是一个k x k矩阵,对应于第j个输入通道和第i个输出通道的
W
r
W_r
Wr,我们将滤波器
W
r
(
i
,
j
)
W_r^{(i,j)}
Wr(i,j)的幅度(即绝对值的总和)作为连接程度的数值度量,这是一种常见的做法[18;8;32;15;9]。简而言之,较大的幅度值表示较强的连接。我们使用
W
t
W_t
Wt和
W
b
W_b
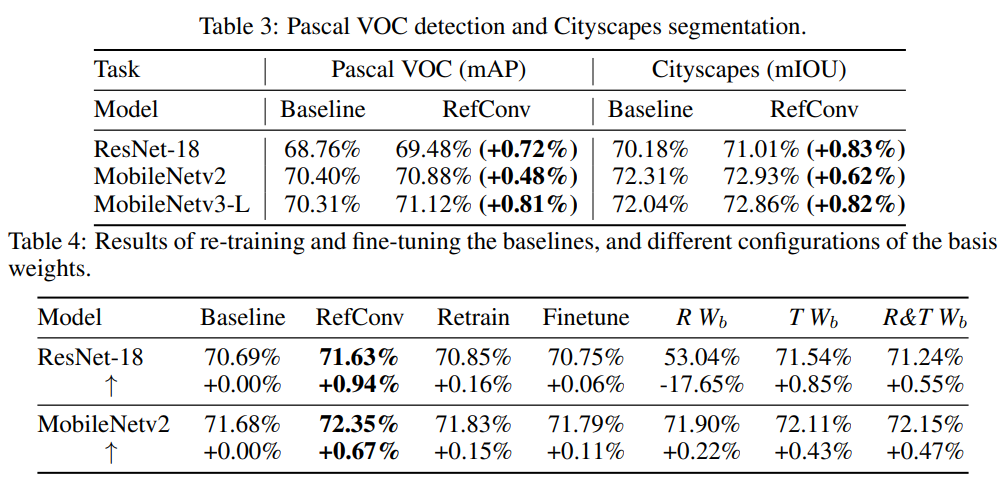
Wb的前64个通道,并计算每对通道之间的连接程度,以获得64 x 64连接程度矩阵。如图3所示,
W
t
W_t
Wt中的第i个通道不仅关注
W
b
W_b
Wb中相应的第i个通道,还关注
W
b
W_b
Wb中的多个其他通道,但幅度不同,这表明DW RefConv可以关注所有通道以学习现有表示的各种组合。
4.5、REFCONV减少通道冗余
为了探索基础权重
W
b
W_b
Wb和变换后的权重
W
t
W_t
Wt之间的差异,我们比较了
W
b
W_b
Wb和
W
t
W_t
Wt的通道冗余。作为一个常见的做法,我们利用Kullback-Leibler(KL)发散来衡量不同通道对之间的相似性[56;46],因此KL发散越大表明相似性越低,通道冗余程度也就越低。具体来说,我们从训练过的MobileNetv1中采样一个DW RefConv层,并对每个K x K核通道应用softmax,然后采样前64个通道来计算每对通道之间的KL发散。通过这种方式,我们获得了采样层的64 x 64相似性矩阵。图4显示了多个层的相似性矩阵。可以看到,
W
b
W_b
Wb的通道之间存在很高的冗余,因为大多数通道之间的KL发散很低。相比之下,
W
t
W_t
Wt的通道之间的KL发散明显更高,这意味着核通道与其他通道有显著的不同。基于这样的观察,我们得出结论,RefConv可以一致且有效地减少冗余。我们解释了RefConv可以明确使每个通道能够关注预训练核的其他通道,这重聚焦于预训练核通道中编码的已学表示来学习多种新颖表示。因此,通道冗余减少,表示多样性增强,导致更高的表示能力。

4.6、RefConv 平滑损失景观
为了探索重聚焦学习如何影响训练动态,我们用滤镜归一化可视化来可视化了基础模型和RefConv的对应模型的损失景观[33]。我们使用在CIFAR-10上训练的MobileNetv1和MobileNetv2作为主干模型。图5表明,与基准相比,RefConv的损失景观具有更宽、更稀疏的轮廓,这表明RefConv的损失曲率要平坦得多[33],表明其具有更好的泛化能力。这种现象表明重聚焦学习具有更好的训练特性,这在一定程度上解释了其性能的提升。
5、结论
本文提出了重参数化的重聚焦卷积(RefConv),这是第一种重参数化方法,通过在内核参数之间建立额外的连接来增强现有模型结构的先验。作为可替换常规卷积层的即插即用模块,RefConv可以在不改变原始模型结构或引入额外推理成本的情况下,显着提高各种CNN在多个任务上的性能。此外,我们通过展示RefConv减少通道冗余和平滑损失景观的能力来解释其有效性,这可能会激发对训练动态的进一步理论研究。在我们的未来工作中,我们将探索更有效的重聚焦变换设计,例如通过引入非线性和更先进的操作。
“Loss landscape” 是一个术语,指的是机器学习中目标函数(或损失函数)随模型参数变化的图像或景观。在机器学习中,目标函数通常用于衡量模型预测结果与实际结果之间的差异,而“loss landscape”则可以形象地展示这个差异在不同模型参数值下的分布情况。
在训练机器学习模型时,通常会使用梯度下降等优化算法来最小化目标函数,从而使得模型的预测结果更加准确。而“loss landscape”则可以帮助我们更好地理解目标函数的性质,以及优化算法在训练过程中的行为。
Appendix A: RefCONV强化了核心骨架
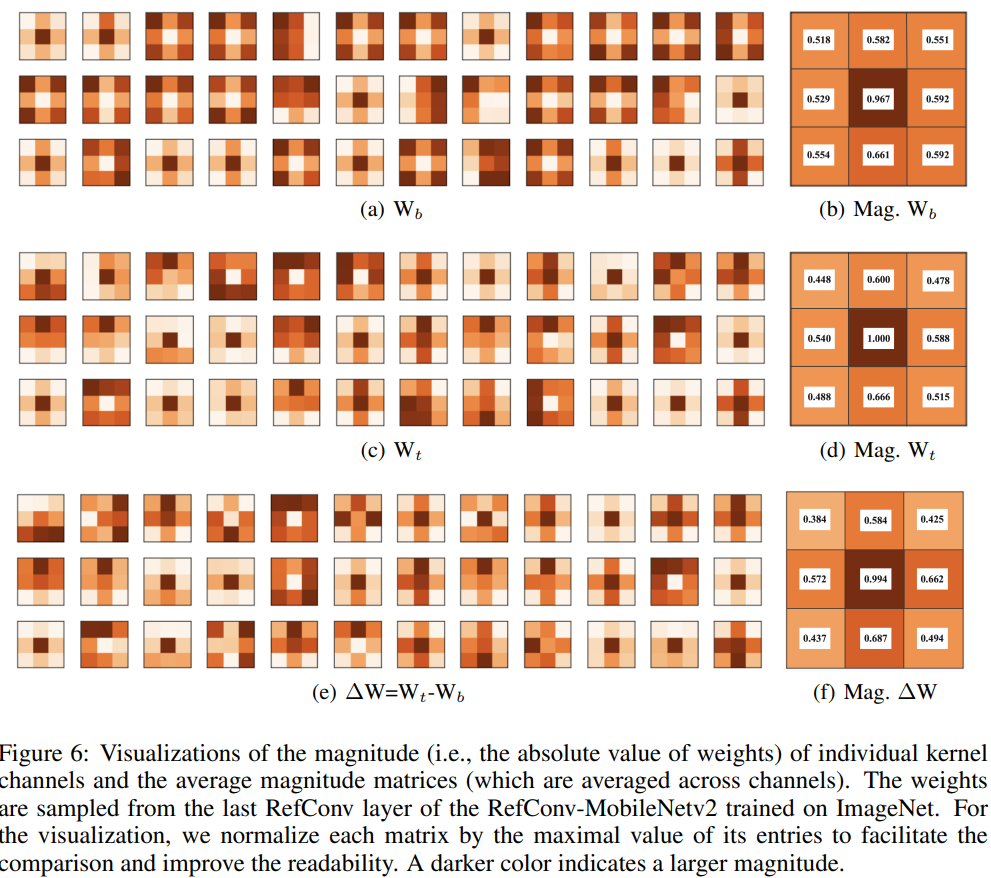
为了探索基础核与转换核之间的其他差异,我们对RefConv-MobileNetV2最后卷积层的基础核Wb、转换核Wt以及相对于基础权重的增量ΔW=Wb-Wt进行了可视化,这在图6的左侧列中展示。我们发现大多数ΔW呈现出更强的骨架模式[9],这表明主要差异在于核的中心行和列。因此,可以明显观察到,与Wb相比,Wt呈现出更强的骨架模式,特别是在中心点。此外,我们还计算并可视化这三组权重的平均核幅度矩阵[9; 8; 15; 18; 17],这在图6的右侧列中展示。同样,ΔW的幅度呈现出强烈的骨架模式和角落的小影响因子,这表明与Wb相比,Wt的骨架模式得到了加强,而角落被削弱。值得注意的是,对于Wt,中心点的值为1.000,这意味着在每个3×3层中该位置具有持续的主导重要性。根据[9],增强骨架可以提高性能,这从另一个角度解释了RefConv的有效性。
附录B:在其他数据集上对RefConv的性能评估
我们在CIFAR-10、CIFAR-100和Tiny-ImageNet-200数据集上测试了RefConv的有效性。我们将图像大小调整为224×224,训练策略与在ImageNet上的实验一致。我们对一系列具有代表性的CNN架构进行测试,包括Cifar-quick[29]、SqueezeNet[26]、VGGNet[43]、ResNet[19]、ShuffleNetv1,v2[53;38]、ResNeXt[48]、RegNet[39]、ResNeSt[51]、FasterNet[1]、MobileNetv1,v2,v3[21;42;20]、MobileNeXt[55]、HBONet[31]和EfficientNetv1,v2[44;45]。
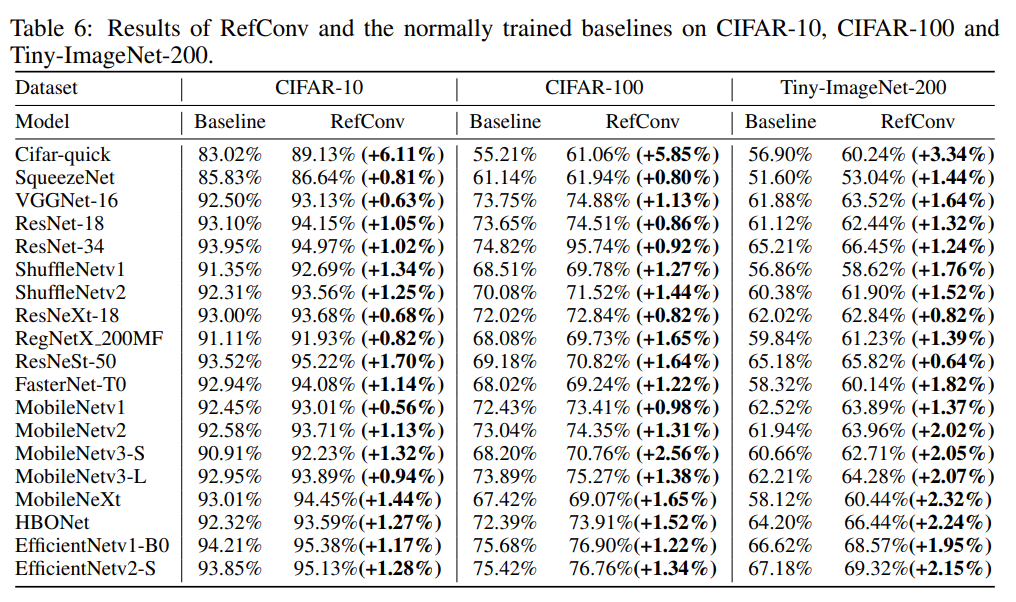
表6显示了结果。可以看出,所有模型的性能都得到了明显的提升。例如,RefConv通过密集卷积显著提高了Cifar-quick(具有密集卷积)在CIFAR-10、CIFAR-100和TinyImageNet-200上的性能分别提高了6.11%、5.85%和3.34%。此外,RefConv通过组卷积显著提高了ShuffleNetv1(具有组卷积)在CIFAR-10、CIFAR-100和Tiny-ImageNet-200上的性能分别提高了1.34%、1.27%和1.76%。对于DW卷积,RefConv将MobileNetv3-S的top-1准确率提高了分别提高了1.32%、2.56%和2.05%。总之,结果表明,RefConv可以增强具有不同类型卷积层的各种模型的表示能力,包括密集卷积、组卷积和DW卷积。
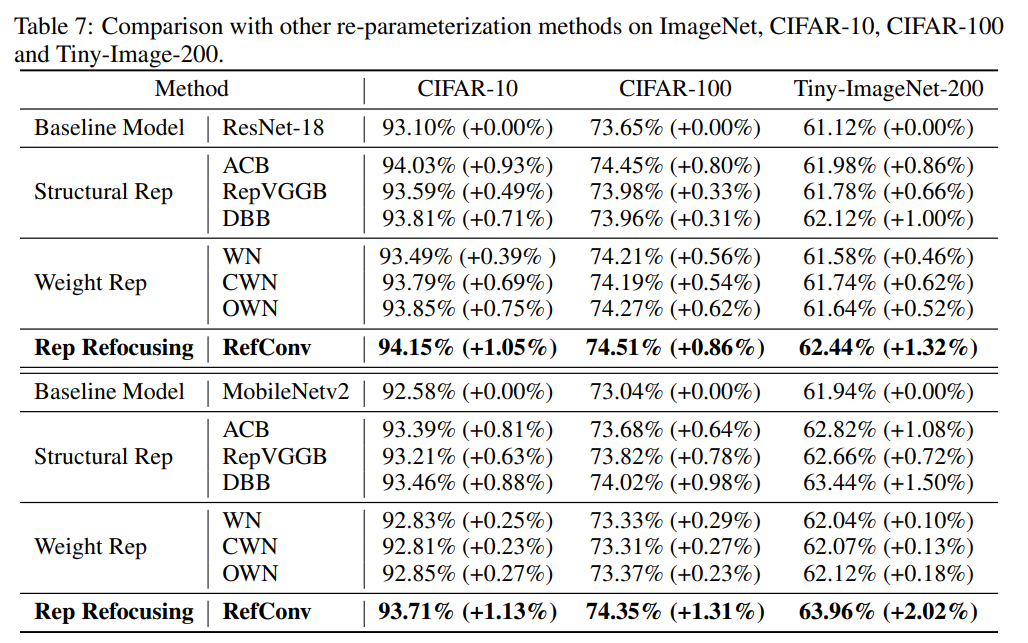
与其他数据集上的其他重参数化方法的比较。我们进一步将RefConv与其他数据无关的重参数化方法在CIFAR-10、CIFAR-100和Tiny-ImageNet-200上进行比较。我们还将图像大小调整为224×224,并遵循ImageNet上的训练策略。基准模型是ResNet-18和MobileNetV2。测试的结构重参数化方法是ACB [9]、RepVGG Block [13]和DBB [11]。测试的数据无关权重重参数化方法是Weight Normalization (WN) [41]、Centered Weight Normalization (CWN) [25]和OWN [24]。如表7所示,Refocusing Learning带来了最高的提升,表明RefConv优于其他重参数化方法。
附录C:RefConv的训练动态
图7显示了基线、重新训练(如论文中定义)和MobileNetv2的RefConv对等模型在ImageNet上训练100个epochs,其中包含5个epoch的预热的训练和验证集上的损失和准确率曲线。将RefConv与基线进行比较,我们观察到RefConv模型的训练比基线更快地收敛。此外,在优化过程中,具有RefConv的模型具有比基线更高的训练/验证准确率和更低的训练/验证损失。如论文中所报道的,MobileNetv2与RefConv最终收敛到比基线更好的状态,这表明RefConv具有更高的验证准确率。此外,我们发现基线从低准确率开始并迅速上升约15个epoch,然后相对平稳地上升。相比之下,RefConv模型以相对较高的准确率开始(这是由于RefConv在预训练模型的基础上进行),并在开始时略有下降,然后平稳上升。对于损失曲线,我们发现基线从高值开始并在前约15个epoch迅速下降,然后相对平稳地下降。相比之下,RefConv模型的损失从相对较低的值开始并在开始时略有上升,然后持续平稳下降。这些观察表明RefConv模型具有与基线完全不同的训练动态。
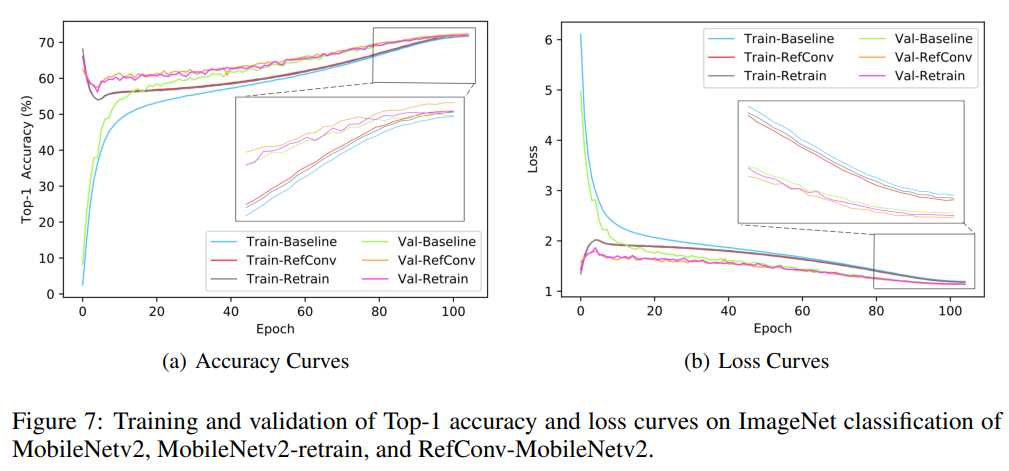
由于我们使用了从基线模型继承权重的重新训练模型(标记为Retrain)进行另一组比较,因此我们将RefConv模型与重新训练模型进行比较。我们观察到RefConv模型和重新训练模型的准确率/损失曲线具有相似的外观。然而,我们发现RefConv模型的准确率从较低的值开始,损失从较高的值开始。这是预期的,因为RefConv引入了一组额外的随机初始化的可学习参数,学习在基本参数之间建立新的连接并生成新的核。相比之下,重新训练模型的优化精确地从基线模型优化的结束点开始。因此,重新训练模型的起点准确率更高,损失更低,但由于没有建立新的连接,其性能不如RefConv模型。
附录D:仅使用部分训练数据重聚焦学习
我们想知道重聚焦学习是否仍然有效,当它只能访问部分训练数据而不是整个训练集时。因此,我们使用CIFAR-10和Tiny-ImageNet-200的一半训练集训练RefConv,并在整个测试集上进行评估。我们遵循上述ImageNet的优化策略,但我们将批量大小从256减半到128以保持迭代次数。由于重聚焦学习只能访问一半的训练数据,因此总训练成本也减半。表8中的Half-RefConv列显示,在这种设置下,RefConv仍然可以获得令人满意的性能。
附录E:PyTorch中的代码
在主流的CNN框架(如PyTorch)上实现RefConv很简单。我们在Algorithm 1中提供了类似于PyTorch的RefConv代码。当在CNN模型中实现时,我们只需要将模型中的非点积卷积层替换为RefConv即可。在PyTorch中,RefConv在CNN上的实现代码可从以下链接获取:https://github.com/Aiolus-X/RefConv。
class RepConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding=None, groups=1,
map_k=3):
super(RepConv, self).__init__()
assert map_k <= kernel_size
self.origin_kernel_shape = (out_channels, in_channels // groups, kernel_size, kernel_size)
self.register_buffer('weight', torch.zeros(*self.origin_kernel_shape))
G = in_channels * out_channels // (groups ** 2)
self.num_2d_kernels = out_channels * in_channels // groups
self.kernel_size = kernel_size
self.convmap = nn.Conv2d(in_channels=self.num_2d_kernels,
out_channels=self.num_2d_kernels, kernel_size=map_k, stride=1, padding=map_k // 2,
groups=G, bias=False)
#nn.init.zeros_(self.convmap.weight)
self.bias = None#nn.Parameter(torch.zeros(out_channels), requires_grad=True) # must have a bias for identical initialization
self.stride = stride
self.groups = groups
if padding is None:
padding = kernel_size // 2
self.padding = padding
def forward(self, inputs):
origin_weight = self.weight.view(1, self.num_2d_kernels, self.kernel_size, self.kernel_size)
kernel = self.weight + self.convmap(origin_weight).view(*self.origin_kernel_shape)
return F.conv2d(inputs, kernel, stride=self.stride, padding=self.padding, dilation=1, groups=self.groups, bias=self.bias)
def conv_bn(inp, oup, stride, conv_layer=nn.Conv2d, norm_layer=nn.BatchNorm2d, nlin_layer=nn.ReLU):
return nn.Sequential(
RepConv(inp, oup, kernel_size=3, stride=stride, padding=None, groups=1, map_k=3),
#conv_layer(inp, oup, 3, stride, 1, bias=False),
norm_layer(oup),
nlin_layer(inplace=True)
)
具体来说,“loss landscape”可以提供以下信息:
目标函数的形状和趋势:通过观察“loss landscape”,我们可以了解目标函数在不同模型参数值下的变化趋势,从而判断是否存在多个局部最小值点,以及最小值点的位置和大小等信息。
梯度的方向和大小:在“loss landscape”中,梯度的方向通常与目标函数变化最快的方向一致,而梯度的大小则可以反映目标函数在某个参数维度上的变化速度。因此,“loss landscape”可以帮助我们更好地理解梯度下降等优化算法在训练过程中的行为。
模型的鲁棒性:通过观察“loss landscape”,我们可以了解目标函数在不同模型参数值下的变化情况,从而评估模型的鲁棒性。例如,如果“loss landscape”中的最小值点非常尖锐且高度很高,那么模型可能会对输入数据的微小变化非常敏感,导致预测结果不稳定。