Kafka consumer - 消费者组
上一篇文章学习到kafka消费者、消费者组之间处理消息的差异,总结起来就是:
- 同一个消费组的不同消费实例 共同消费topiic的消息, 一个消息只会消费一次; 也叫做集群消费
- 同一个消息被不同的消费组同时消费,一个消息会消费多次; 也叫做广播消费
今天以实际代码案例来学习一下,二者之间的区别。在开始之前,先创建一个分区为2的topic
./bin/kafka-topics.sh --create --topic topic_t40 --bootstrap-server localhost:9092 --partitions 2
创建完成后,查看topic信息
./bin/kafka-topics.sh --describe --topic topic_t40 --bootstrap-server localhost:9092
Topic: topic_t40 TopicId: 4-8Xi003Te6i0lEV4YwDHQ PartitionCount: 2 ReplicationFactor: 1 Configs:
Topic: topic_t40 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: topic_t40 Partition: 1 Leader: 0 Replicas: 0 Isr: 0
集群消费
生产者代码
public static void main(String[] args) throws Exception{
String topicName = "topic_t40";
Properties props = new Properties();
//指定kafka 服务器连接地址
props.put("bootstrap.servers", "localhost:9092");
// 序列化方式
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topicName ,"key" + i,"message : " + i);
Future<RecordMetadata> send = producer.send(record);
RecordMetadata metadata = send.get();
System.out.println(String.format("sent record(key=%s value=%s) 分区数: %d, 偏移量: %d, 时间戳: %d",
record.key(), record.value(),
metadata.partition(),metadata.offset(), metadata.timestamp()
));
TimeUnit.SECONDS.sleep(1);
}
System.out.println("Message sent successfully");
producer.close();
}
消费者代码
-
第一个消费者 - ConsumerExample.java
public class ConsumerExample { public static void main(String[] args){ String topicName = "topic_t40"; Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put(ConsumerConfig.GROUP_ID_CONFIG, "app_c"); props.put("client.id", "client_01"); props.put("enable.auto.commit", true); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest"); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topicName)); try { while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); records.forEach(record -> { System.out.println("Message received " + record.value() + ", partition " + record.partition()); }); } }finally { consumer.close(); } } } -
第二个消费者 - ConsumerExample02.java
// 其他代码 一致 只需要替换下面一行代码即可 props.put("client.id", "client_02");
验证测试
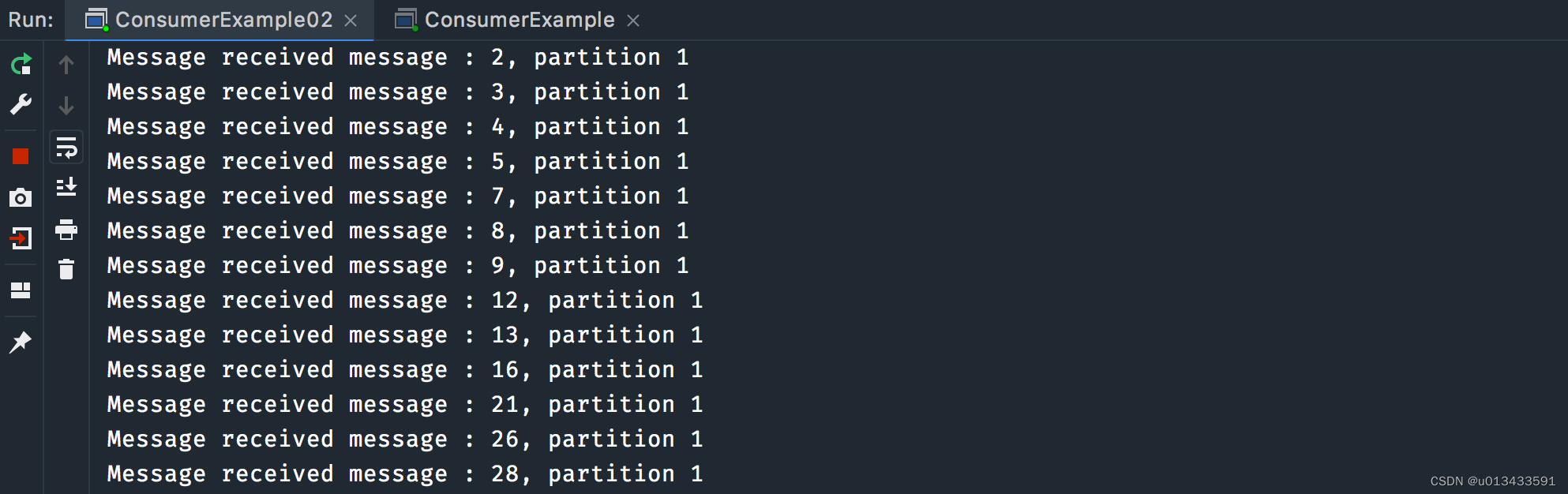
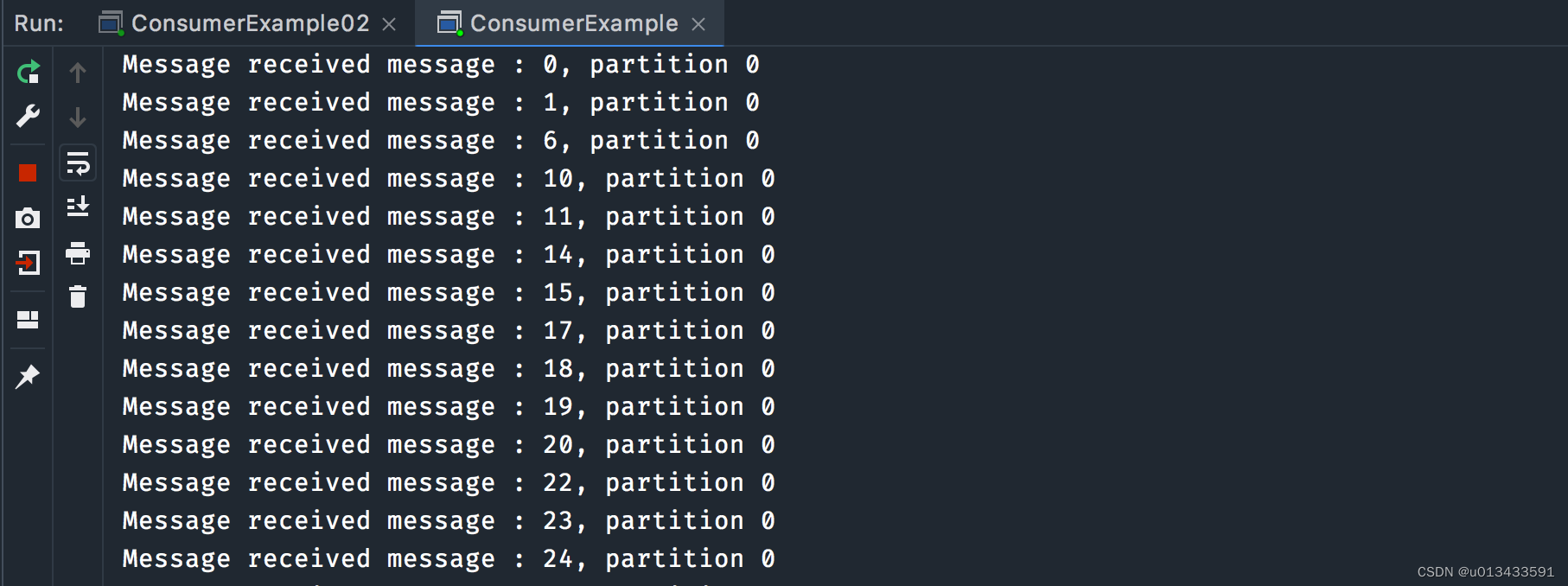
先启动两个消费者程序,然后启动生产者,两个消费者控制台打印输出截图如下
总结
从上面的日志可以分析出,kafka是以分区为维度来进行多进程消费的,topic 两个分区,两个消费者。即每一个消费者实例分担topic一个或者多个分区数据,从而最终合力达成集群消费的目的。
广播消费
消费者代码
广播消费的代码跟集群消费差不多,唯一需要更改的是将 group.id 改成不一样即可
-
第一个消费者 - ConsumerExample.java
//... props.put(ConsumerConfig.GROUP_ID_CONFIG, "app_h"); props.put("client.id", "client_01"); //... -
第二个消费者 - ConsumerExample02.java
//... props.put(ConsumerConfig.GROUP_ID_CONFIG, "app_g"); props.put("client.id", "client_01"); //...
验证测试
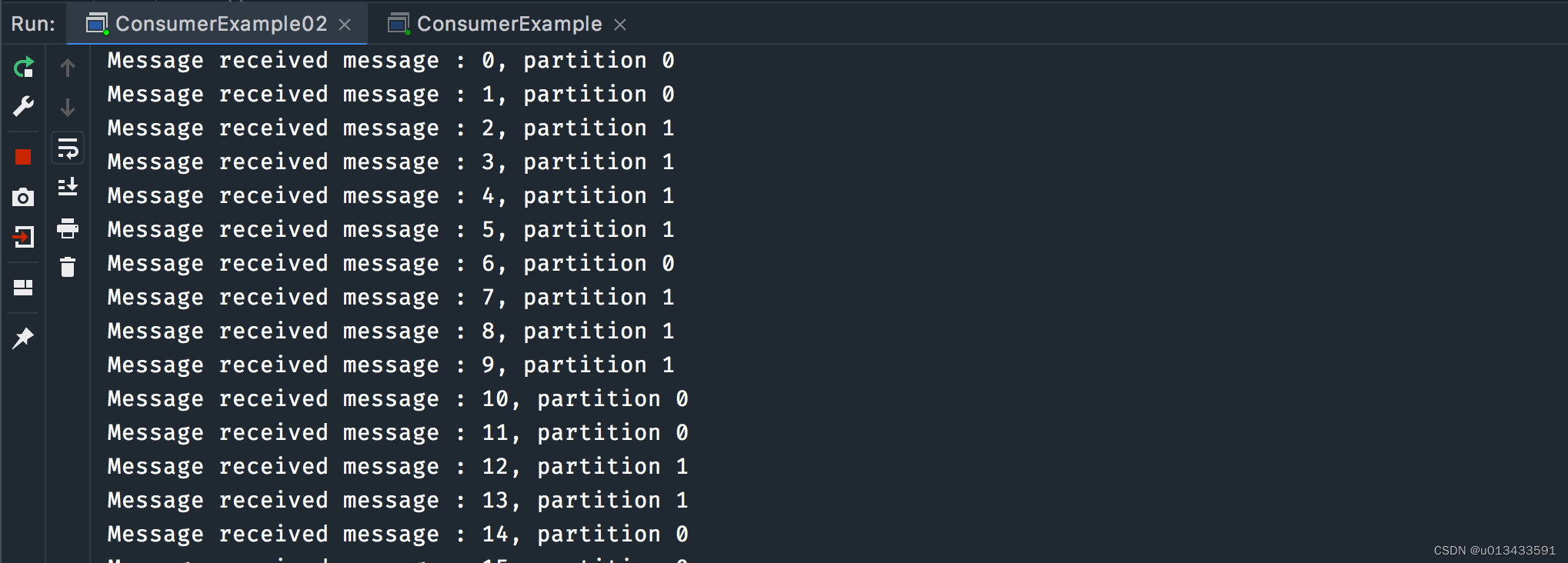
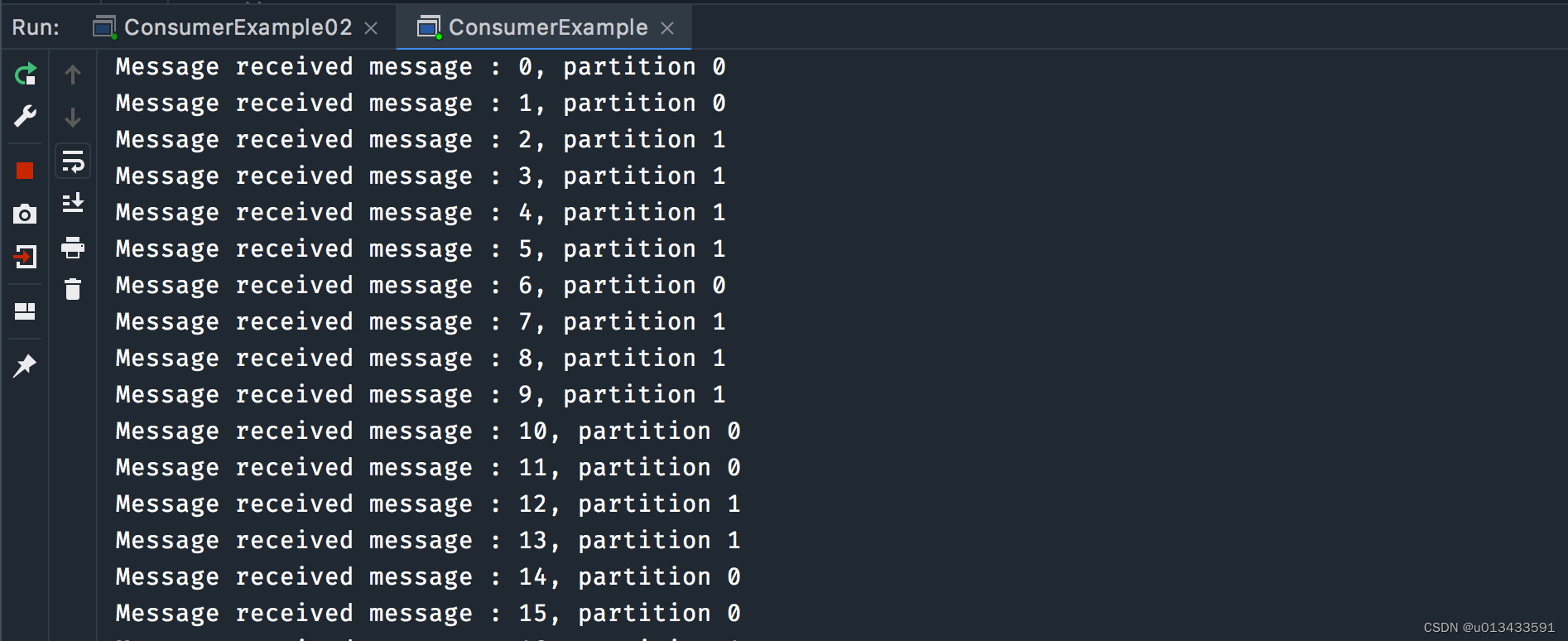
生产者代码跟之前一致,无需做任何更改。先启动两个消费者程序,然后启动生产者,两个消费者控制台打印输出截图如下
Rebalance 重平衡
kafka 消费者组 rebalance 重平衡本质上是一组协议,该协议主要确定消费者组多个实例时间如何分配订阅topic所有分区数据。
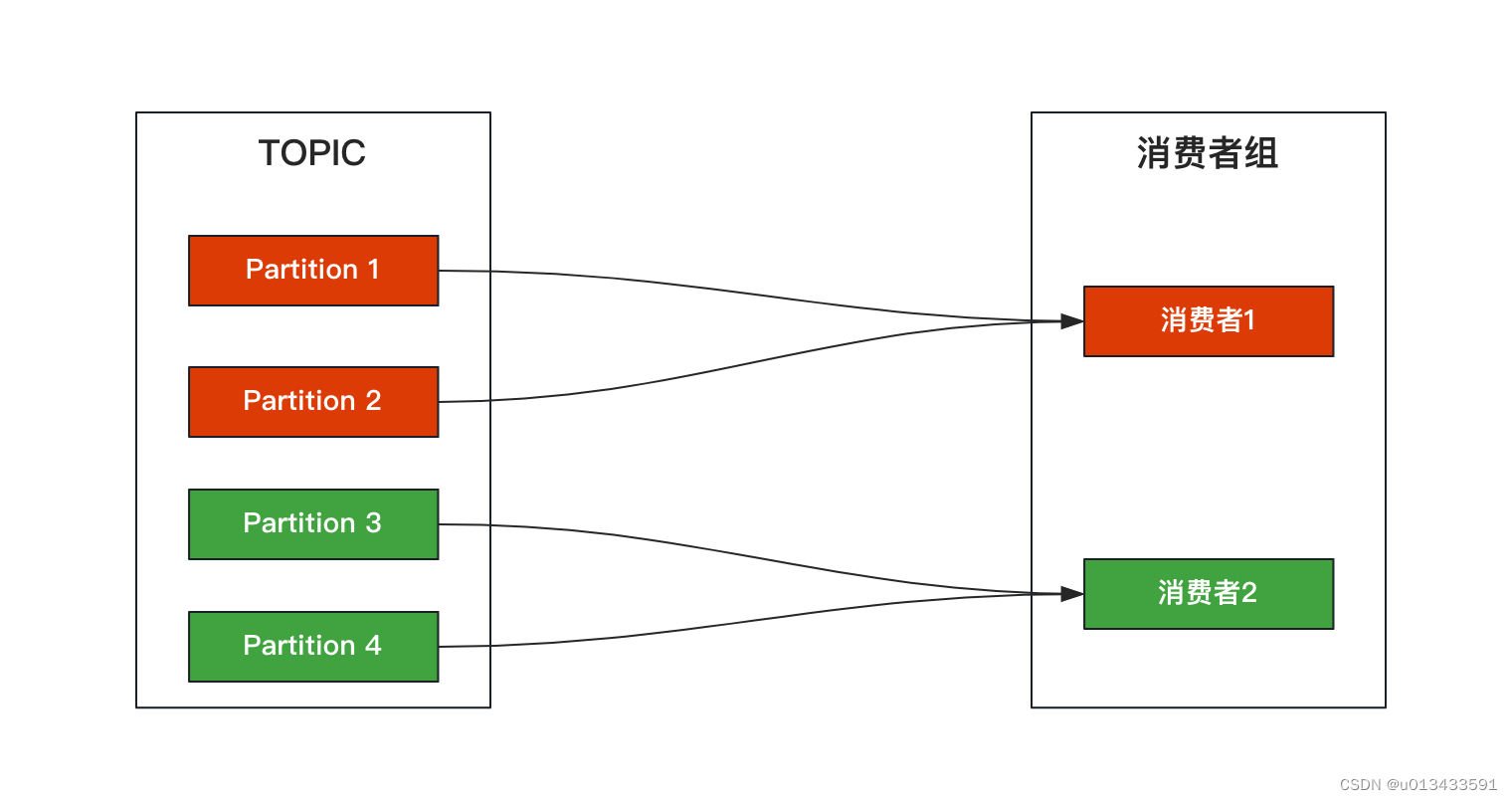
如上图,topic下面有4个分区,一个消费者组下面有两个消费者,那么正常情况下每个消费者消费2个分区。但是当某个消费者意外宕机的情况下,kafka会感知到消费这的下线情况,此时,存活的消费者组将消费topic所有分区的数据。简单地理解,这就是Rebalance重平衡做的事情。
触发条件
- 消费者组发生变更 - 如加入新的消费者实例;消费者实例崩溃等
- 订阅关系发生变化 - 如使用基于正则表达式的订阅,当匹配新topic时 触发重平衡
- topic 分区数发生变化 - 对已有topic集群进行动态扩容 触发重平衡
重平衡日志
手动关闭其中任何一个消费者,等待一会儿(45秒),观察kafka服务器日志,显示已经发生重平衡。集群模式下,此时存在的消费者实例将消费topic所有分区数据。

Preparing to rebalance group app_g in state PreparingRebalance with old generation 1 (__consumer_offsets-9) (reason: removing member client_01-ecec69f7-b72d-4184-a4ec-5e57d26a85f1 on heartbeat expiration) (kafka.coordinator.group.GroupCoordinator)
session.timeout.ms
kafka消费者管理者用于检测客户端故障的时间间隔。一般而言客户端发送周期性心跳给服务端,表示其存活状态。如果在会话超时到期之前服务端没有收到心跳,则服务端将从消费者组中删除该客户端,并重新启动重平衡。默认值 45秒
重平衡监听器
kafka提供接口对重平衡进行监听,rebalance监听器有一个主要的接口回调类 - ConsumerRebalanceListener,该类定义了两个方法
public interface ConsumerRebalanceListener {
/**
* 用户可以实现的回调方法,以提供对自定义存储的偏移提交的处理。当消费者必须放弃某些分区时,将在重新平衡操作期间调用此方法。
*/
void onPartitionsRevoked(Collection<TopicPartition> partitions);
/**
* 用户可以实现一种回调方法,以在分区重新分配成功后提供自定义偏移量的处理。此方法将在分区重新分配完成后、使用者开始获取数据之前调用,并且仅作为轮询(长)调用的结果。
*/
void onPartitionsAssigned(Collection<TopicPartition> partitions);
/**
* 可以实现一个回调方法,为已经重新分配给其他使用者的分区提供清理资源的处理。在正常执行期间不会调用此方法,因为所拥有的分区将首先通过调用onPartitionsRevoked来撤销,然后在重新平衡事件期间重新分配给其他使用者。然而,在例外情况下,当消费者意识到不再拥有此分区时,即不会通过正常的重新平衡事件撤销,则会调用此方法。
*/
default void onPartitionsLost(Collection<TopicPartition> partitions) {
onPartitionsRevoked(partitions);
}
}
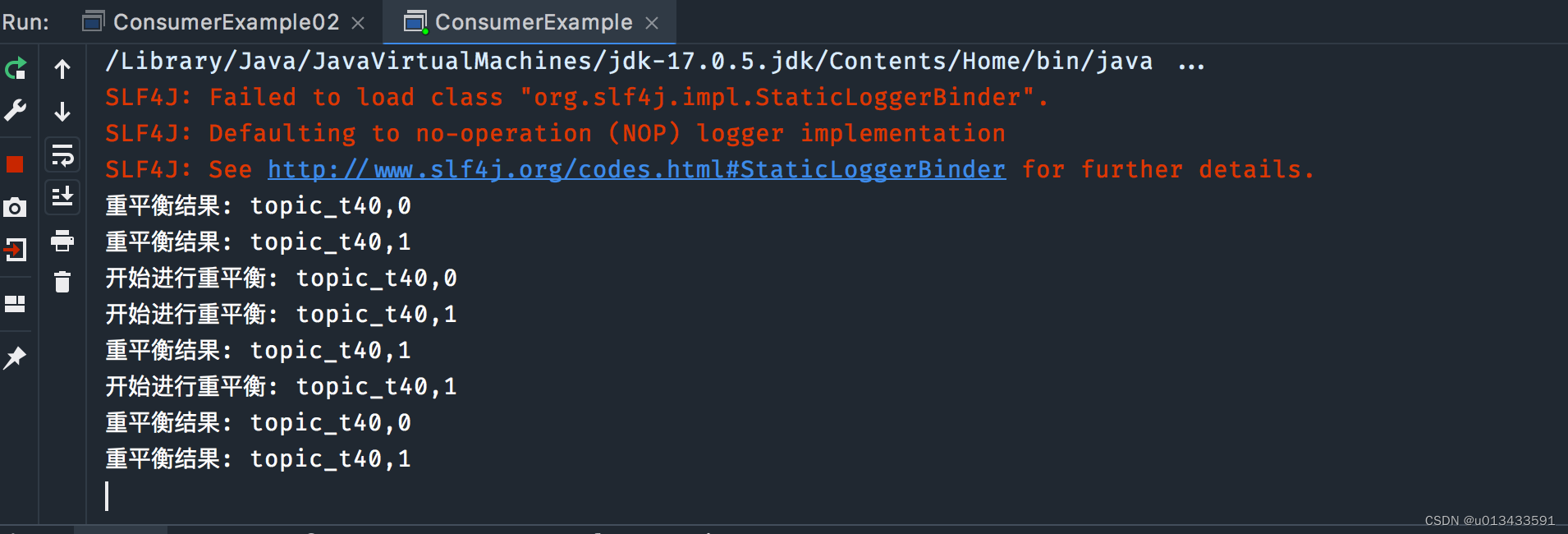
代码测试 - 使用集群消费模式,修改订阅代码,然后一次启动两个消费者
consumer.subscribe(Arrays.asList(topicName),new ConsumerRebalanceListener(){
/**
* 开启新一轮重平衡前调用
*/
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
partitions.stream().forEach(p -> {
System.out.println("开始进行重平衡: " + p.topic() + "," + p.partition());
});
}
// 重平衡结束后调用
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
partitions.stream().forEach(p -> {
System.out.println("重平衡结果: " + p.topic() + "," + p.partition());
});
}
});
测试场景:
- 分别启动消费者实例 - 中间间隔1分钟
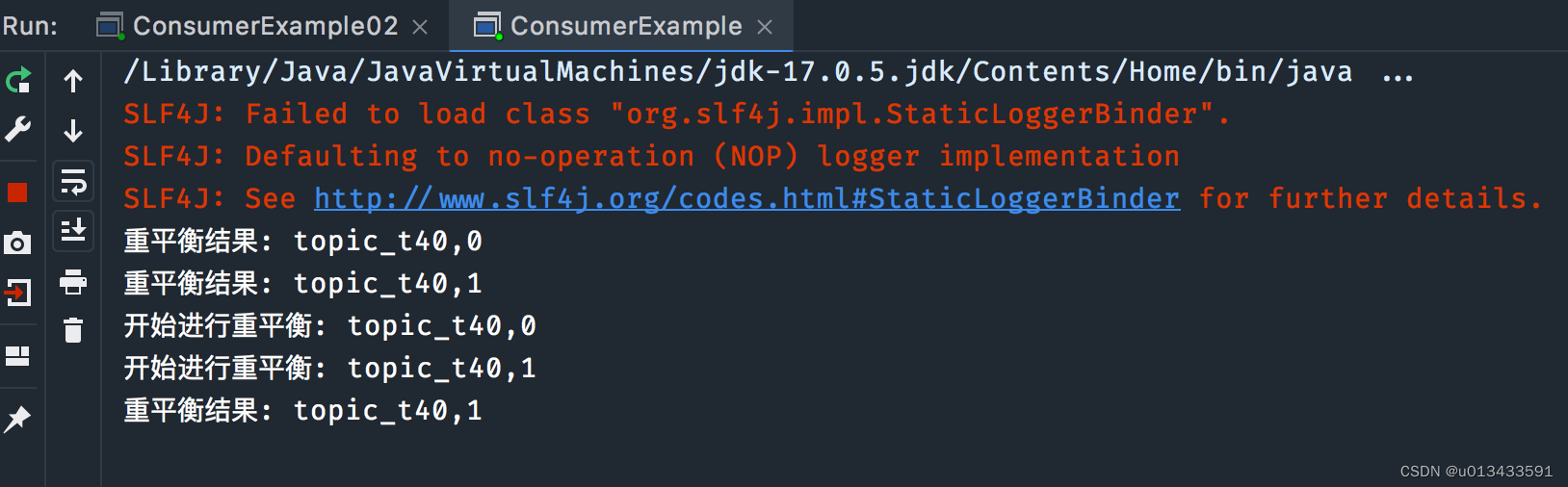
- 关闭一个消费者实例 - 等待一分钟